你的运行环境(版本号「点击帮助-关于-复制」):
3.5.50
问题描述(你遇到了什么问题?):
使用trae自建skills,一次请求消耗100w 的token,不是上限是100w,是阿里云百炼的免费token是100w,不敢想象要是接入部门采用后会有多大token消耗量。
复现步骤(如何才能重现这个 Bug/问题?):
1.打开solo模式
2.输入内容
3.执行内容
报错信息或截图(如有):
你的运行环境(版本号「点击帮助-关于-复制」):
3.5.50
问题描述(你遇到了什么问题?):
使用trae自建skills,一次请求消耗100w 的token,不是上限是100w,是阿里云百炼的免费token是100w,不敢想象要是接入部门采用后会有多大token消耗量。
复现步骤(如何才能重现这个 Bug/问题?):
1.打开solo模式
2.输入内容
3.执行内容
报错信息或截图(如有):
我理解了,你在使用自建 Skill 做渐进式代码生成时,单次请求消耗了高达 100 万 Token,这确实会造成很大的成本压力。
这主要是因为 Builder/SOLO 模式在执行多步骤任务时,每一步都会保留完整的上下文历史,加上你需要依次读取多个文件内容,上下文会不断累积,最终导致 Token 消耗激增。
给你几个优化方向试试:
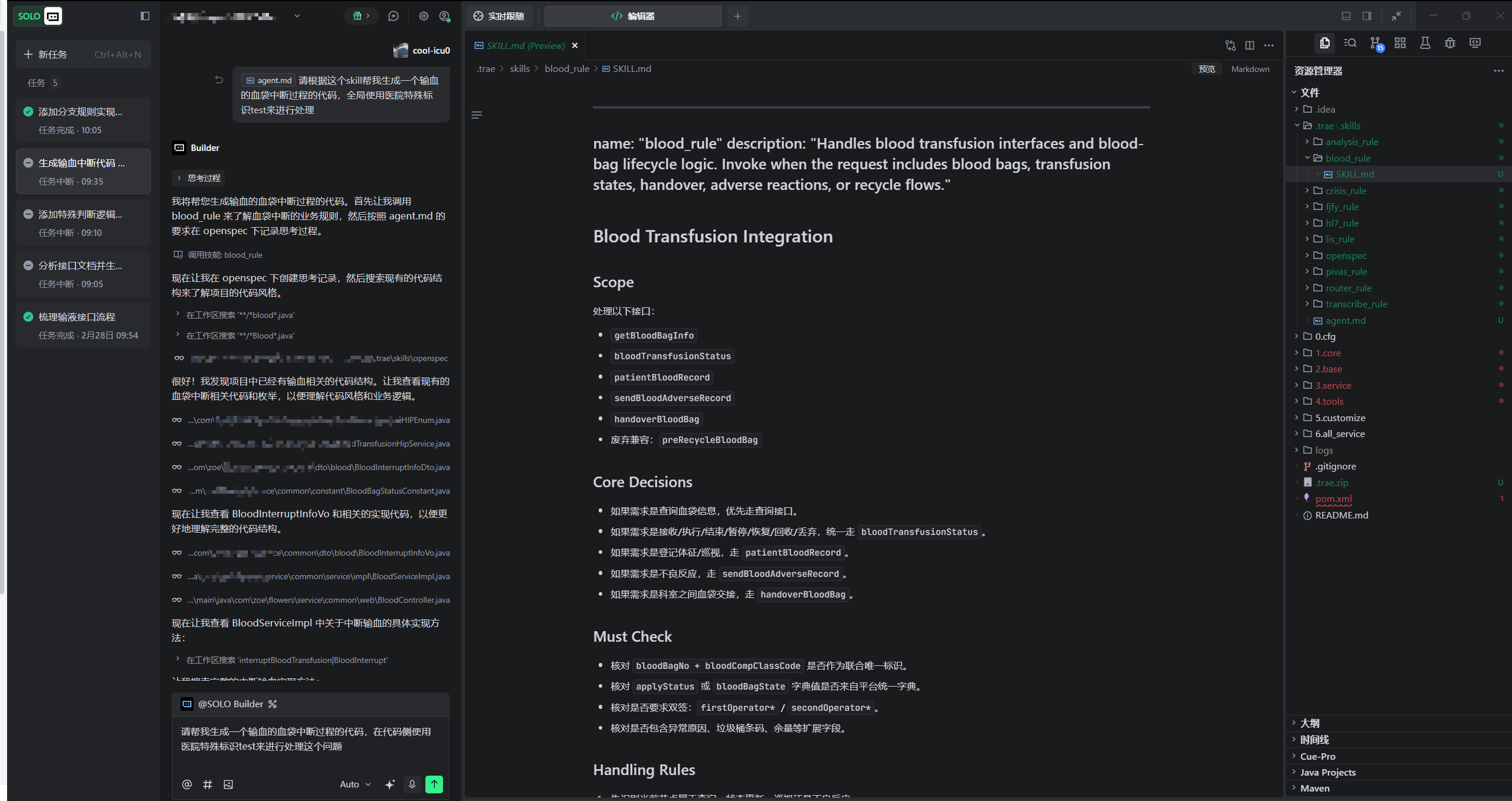
你的 Skill 是渐进式读取文件,有没有尝试过拆分任务分步执行呢?Token 消耗下降了吗?
1、已经阅读过trae社区相同或者相似内容,发现并没有相似的内容
2、已经是新的对话窗口的形式了,你可以从图片可以看出
3、如何拆分子任务执行的任务呢?
我理解了,你想知道在 SOLO 模式下具体怎么拆分大任务来降低 Token 消耗对吧?
拆分任务其实就是把一个大需求拆成多个小步骤依次执行:比如你要重构整个项目,不要一次性让 Trae 处理所有文件,先只处理第一个模块的几个文件,完成确认结果没问题后,再开启新的对话处理下一个模块。
你也可以调整自建 Skill 的逻辑,让它每次只读取和处理一个文件,处理完再进行下一步,而不是一次性把所有目标文件都加载到上下文中。
你现在的自建 Skill 是一次性读取所有需要处理的文件吗?
我需要的是一个话题做一个任务,每次对话就是一个任务,如果拆分后,是否还能自动执行所有任务呢,感觉和cc差别非常大,本人使用cc和codex的cli都消耗量没有trae的一半,是否是系统问题呢
我理解了,你希望在一个对话内能自动完成所有任务,拆分后需要手动触发很不方便,同时对比其他工具发现Trae token消耗明显更高,疑惑是不是系统本身的问题。
确实,目前SOLO模式就是在单个对话内保留完整上下文来自动执行多步骤任务,拆分成多个对话就需要手动依次触发,这是当前设计的限制。
Trae token消耗更高主要是因为默认会加载更多项目上下文来保证代码理解的准确性,会把你需要处理的文件完整内容带入会话,而一些CLI工具默认只会加载最相关的部分。你可以试试通过.traeignore排除更多无关目录(比如node_modules、build等),能有效减少不必要的token消耗。
你项目里需要处理的文件大概有多少呢?
您好,可以关注下TRAE的公众号,里面会有些实践分享。
已经看过了,没有相同或者相似的内容,难道我没声明吗
目前100wtoken就生成了200行代码不到的数据
我理解了,100万Token只生成不到200行代码,这个消耗量确实异常得高了。
这种情况很可能是你的自建 Skill 在逻辑上存在重复加载上下文的问题,比如每次循环都重新读取一遍所有文件,导致 Token 快速累积。你可以检查一下 Skill 的 prompt 逻辑,看看是不是每次执行步骤都重复引入了所有文件内容。
另外,你方便分享一下自建 Skill 的核心配置吗?我帮你看看是不是哪里可以优化一下逻辑来减少不必要的 Token 消耗。
好的,方便的,怎么样加您呢
直接在这里贴出自建 Skill 的核心配置内容就可以啦,我帮你一起看看逻辑上有没有可以优化的地方,看看能不能降低 Token 消耗。你把配置内容发出来一下吧?
skills有点多,这边分享是不是会对外公开呢?
我理解你的顾虑,这确实是个需要注意的问题。
这个论坛是公开社区,如果你分享完整配置确实会对外公开。你可以只把和文件读取、上下文处理相关的核心逻辑部分抽出来分享,或者去掉任何敏感信息、业务相关的内容,只保留通用的Skill流程部分就好。
你看这样可以吗?或者你有没有其他更方便的分享方式?
您看一下飞书、钉钉、企微、微信、QQ,您怎么样比较方便,我这边打包一下skills分享你分析一下
我理解你想打包分享完整技能方便我帮你分析,不过我在这里只能通过论坛和你交流,没法提供私人联系方式哦。
你可以先去掉所有敏感信息和业务相关的私有内容,然后把技能文件打包作为附件上传到论坛,或者只截取和上下文读取、循环逻辑相关的核心代码部分贴出来,我就能帮你看看问题出在哪了。
你看这样操作方便吗?
这个内容很多涉及分析的都是含有敏感信息的,不太方便对外分享,如果可以,可以加我联系方式
我理解了,涉及敏感信息确实不方便公开分享,我也没办法私下添加你的联系方式帮你分析![]()
根据我们的经验,自建Skill导致Token异常偏高通常有几个常见原因,你可以对照自查一下:
你可以先检查一下Skill的逻辑,看看是不是存在这几种情况中的一种?如果还是找不到问题,也可以帮你上报给开发团队进一步定位分析。
我确认skills的格式都已经完善好了,每个地址涉及的内容都有执行地址或者接口名称,但是依旧会产生toekn爆炸的效果,很难绷。最好还是申请一下,看是否能通过其中的方式帮忙排查一下,目前的问题是必现的
我理解了,确实不方便公开分享敏感信息,我已经帮你把这个问题上报给开发团队了。
开发同事会看到你的问题描述,他们会尽快跟进处理这个Token异常消耗的问题。你可以先等待一下,有进展后会在这里回复你。
你还有其他需要补充的信息吗?