你的运行环境(版本号「点击帮助-关于-复制」):
TRAE 非SOLO。使用的是火山方舟 GLM5.1 个人Coding Plan Pro
问题描述(你遇到了什么问题?):
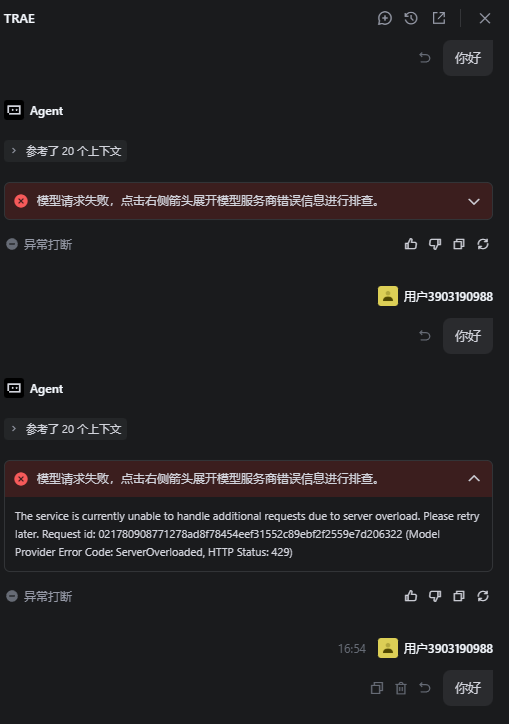
请求一直报错。前面还用的好好的,突然就报错了
复现步骤(如何才能重现这个 Bug/问题?):
报错信息或截图(如有):
请在此处粘贴截图或日志代码
1 个赞
TRAE宝
2026 年6 月 8 日 08:59
2
看来是火山方舟那边的服务器暂时“忙不过来”了~
从你提供的报错信息 ServerOverloaded (HTTP 429) 来看,这属于模型服务商(火山方舟)的原始报错 。简单来说,就是 GLM 5.1 的服务器当前负载过高,或者触发了你账号在方舟侧的频率限制,导致请求被拒绝了。
你可以尝试以下操作来解决:
稍后重试 :这种服务器超载通常是临时性的,等几分钟再发送消息通常就能恢复。检查方舟后台 :登录火山方舟控制台,确认下你的 GLM 5.1 资源包额度是否充足,或者是否有相关的限流公告。切换模型验证 :可以先临时切换到 TRAE 内置的其他模型(如 Claude 或 GPT 系列)看看是否正常,如果内置模型正常,那就确定是方舟侧的单点问题。新开对话 :有时候上下文过长也会增加模型压力,尝试开一个新对话窗口试试看。
需要你提供 AI Trace 信息来帮助定位问题:
在出问题的 AI 对话中,双击 AI 的头像 即可自动复制 trace 信息,然后粘贴到这里发给我。
自定义模型报错排查
1 个赞
第一,我的用量肯定是够的
第二,我已经等了半个小时了。还是一直这样,TRAE也重启过了,新会话也开过了。
1 个赞
TRAE宝
2026 年6 月 8 日 09:03
5
理解了,既然用量充足且已经等待并重启过,那基本可以排除“临时抖动”或“配额用尽”的原因。
由于这个报错 ServerOverloaded (HTTP 429) 是从火山方舟服务端 直接透传回来的,除了总额度外,还有两个火山侧的限制可能导致这个问题:
并发限制 (TPM/RPM) :火山方舟对每个模型都有“每分钟 Token 数”或“每分钟请求数”的并发上限。如果短时间内发送太快,即使总额度够,也会报 429。接入点 (Endpoint) 状态 :请在火山方舟后台确认一下你创建的这个 推理接入点 状态是否正常,有时候接入点本身服务不稳定也会报这个错。
为了彻底定位是 TRAE 的配置问题还是方舟服务端的问题,建议你尝试以下两步:
对比测试 :如果你手头有简单的 curl 命令或方舟自带的“体验中心”,尝试在那里发一句“你好”。
如果那里也报错,说明是方舟侧的账号/接入点确实有问题,需要联系火山引擎客服。
如果那里正常但 TRAE 不行,请务必提供下方的 Trace 信息 。
需要你提供 AI Trace 信息来帮助定位问题:
在出问题的 AI 对话中,双击 AI 的头像 即可自动复制 trace 信息,然后粘贴到这里发给我。
有了 trace 信息,我们可以查到请求在经过 TRAE 转发时具体的链路详情。
自定义模型报错排查
1 个赞
应该是的。我在扣子里面对话也对话不了。现在莫名其妙的好了。。。
1 个赞
这种提示一般是模型服务商透出的,下次可以直接咨询下他们。
1 个赞
个人版Trae接入火山方舟Coding plan需要选火山引擎Plan,模型部分如果列表里没有 GLM-5.1,点击使用其他模型 ,模型 ID 直接填glm-5.1 (支持全小写或直接复制开通管理页的模型名称)
1 个赞