TRAE SOLO 作品:在线考试系统从 0 到 1 的完整演进
1. 摘要
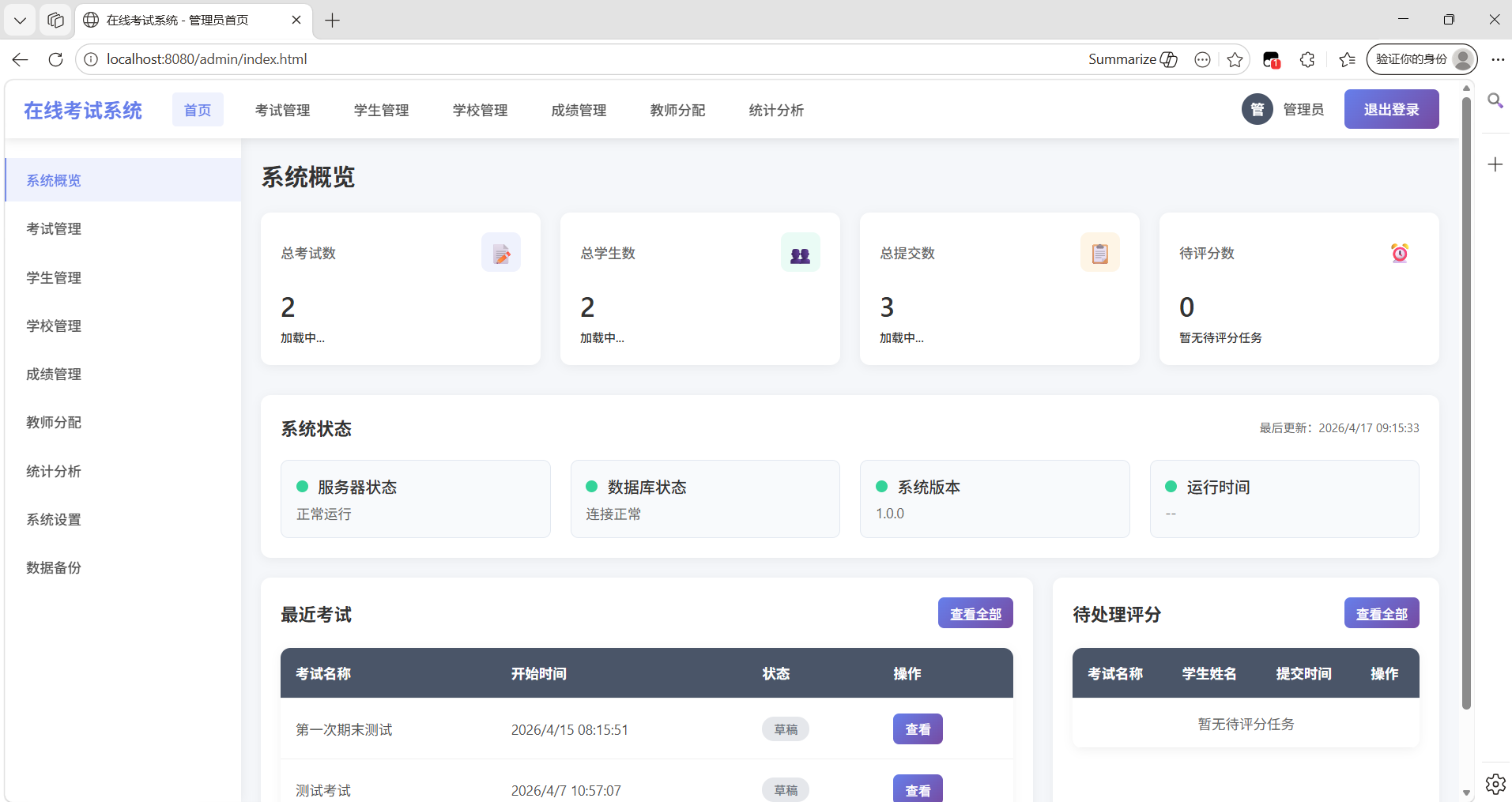
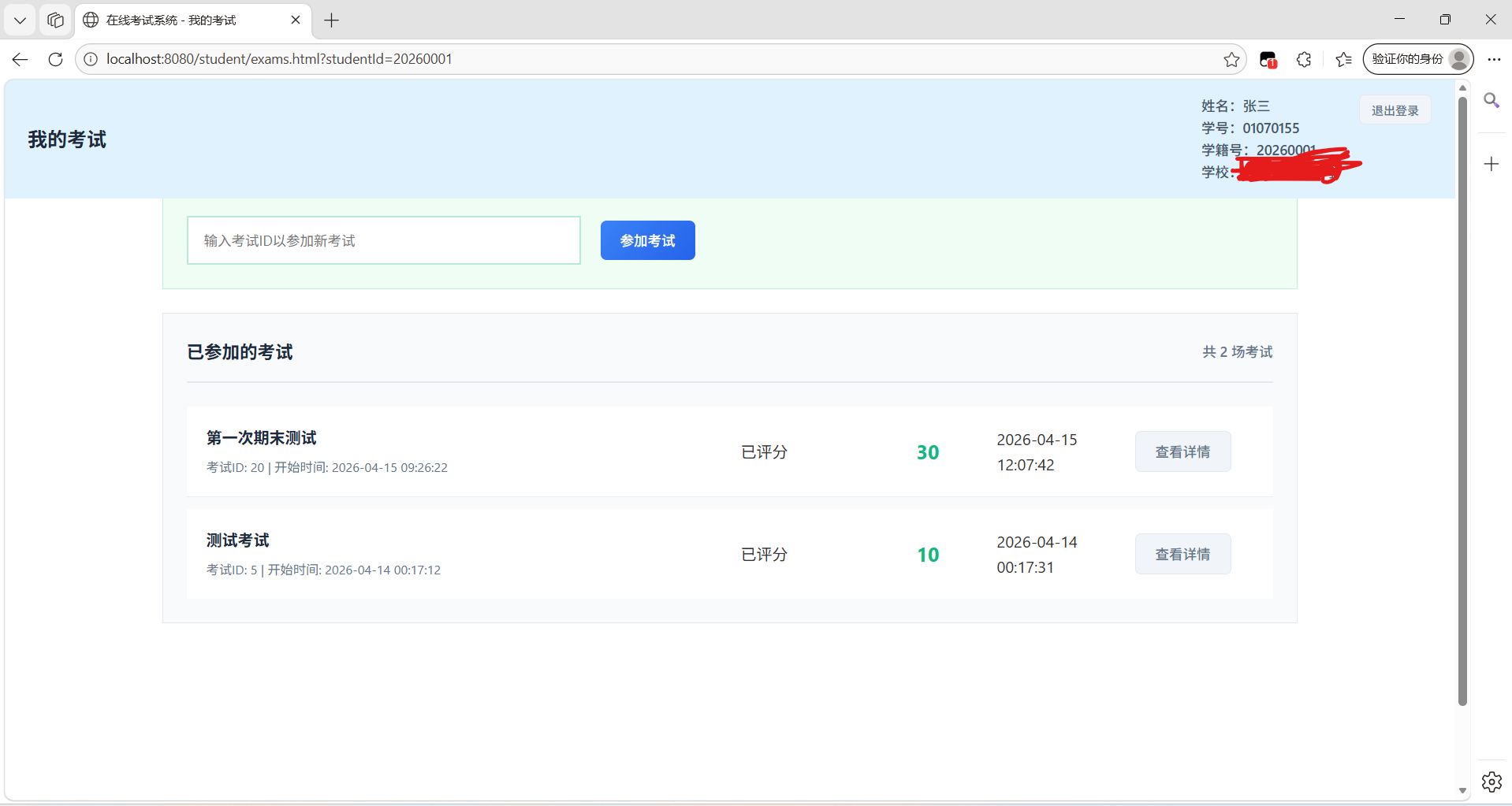
使用 TRAE SOLO 完成了在线考试系统的完整开发与迭代,实现了从基础框架到企业级功能的跨越式升级。通过 AI 驱动的需求分析、架构设计和代码实现,系统从单一功能演进为支持学籍号+学号双标识、智能自动评分、流程图题目、匿名批量批改等企业级功能的完整平台。开发效率提升约 80%,原本预计 半年 的开发周期缩短至 1个月完成,功能还更加强大。
2. 背景
我是一名信息教师,因为需要一个在线考试系统来代替传统的纸笔考试。最初是使用trae(非solo模式)开发了一个简单的单机版的考试系统,后发现存在泄题、数据收集麻烦等问题。在获取到solo模式资格后,决定开发一个功能强大、架构完善的在线考试系统。
面临的具体挑战:
- 系统架构陈旧 - 初始系统只有基础 CRUD 功能,学生考试管理效率低下
- 业务逻辑复杂 - 需要支持多种题型(选择题、判断题、简答题、流程图题),自动评分逻辑分散且不统一
- 权限体系混乱 - 管理员、教师、学生三种角色权限边界不清晰,会话安全机制不完善
- 数据模型缺陷 - 学生学号随升学转学变更导致历史数据断裂问题
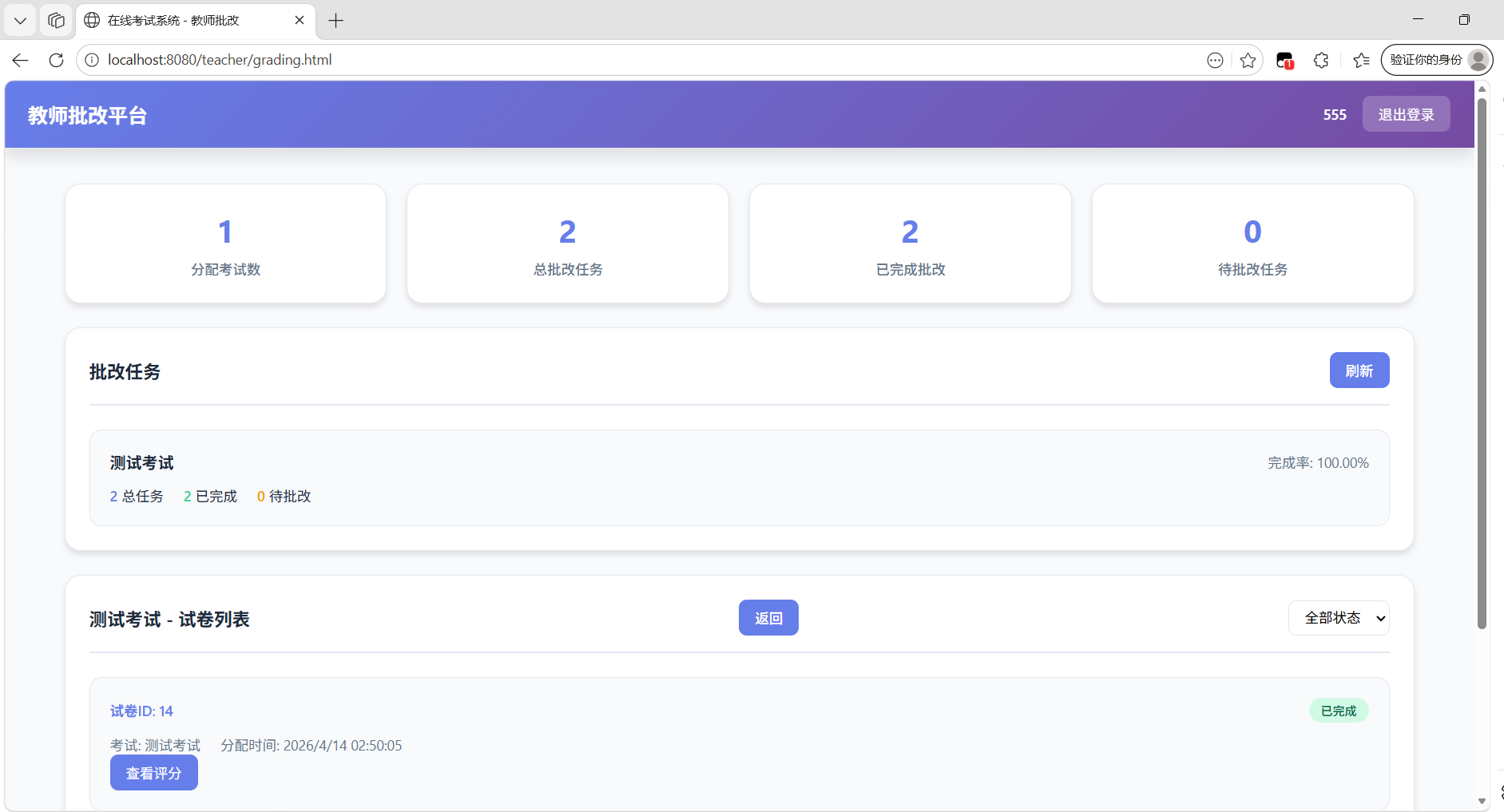
- 批量处理需求 - 大型考试需要多名教师匿名批改,分配不均衡导致效率低下
核心痛点: 系统需要在 期末考试前 完成从旧架构到新架构的迁移,同时保证现有功能稳定运行。
3. 实践过程
3.1 任务拆解
我将整个系统重构任务按功能模块拆解为以下优先级:
| 优先级 | 模块 | 说明 |
|---|---|---|
| P0 | 数据库架构升级 | 学籍号+学号双标识系统 |
| P0 | 身份认证与权限 | 会话安全、路由修复、CSRF 防护 |
| P0 | 自动评分系统 | 题目变更重评分、答案格式统一 |
| P1 | 教师批改平台 | 匿名分配、批量批改、进度统计 |
| P1 | 流程图题目 | 拖拽编辑器、节点样式 |
| P1 | 统计分析 | 成绩图表、班级对比 |
| P2 | 前端交互优化 | 删除确认、登录跳转 |
3.2 使用 SOLO 的核心能力
 能力一:智能代码分析与问题定位
能力一:智能代码分析与问题定位
使用场景: 当系统出现 Error: Unknown column 'st.student_id' in 'field list' 错误时
分析 d:\code2\modules\statistic\service.js 文件,找出所有使用 student_id
字段的位置,并与数据库实际表结构对比,指出需要修改的具体行号和修改方案。
输出效果: SOLO 精确定位到 getStudentRankings (第87行) 和 getStudentTrendAnalysis (第382行),发现原因是 students 表已改为 student_code 字段,代码仍使用旧的 student_id。
 能力二:架构设计文档生成
能力二:架构设计文档生成
使用场景: 设计学籍号+学号双标识系统
设计一个学生信息管理系统,需要满足:
1. 学籍号作为全局唯一标识,终身不变
2. 学号作为学校内部标识,升学转学时可变更
3. 保留历史变更记录
4. 需要支持学校管理功能
请输出:
- 数据库表结构设计(SQL)
- 核心 API 接口设计
- 学号自动生成规则
- 数据迁移方案
输出效果: 获得完整的 schools 表设计、students 表字段变更方案、学籍号生成规则(年份+序号)。
 能力三:跨文件代码修改
能力三:跨文件代码修改
使用场景: 修复学生 /students/me 路由权限错误
在 d:\code2\modules\student\routes.js 中:
1. 路由顺序问题:/students/me 被 /students/:id 错误匹配
2. 需要将 /me 相关路由(GET 和 PUT)移到 /students/:id 路由之前
3. 同时增强 /students/me 接口的权限验证
请直接输出修改后的完整代码片段。
输出效果: 精确的路由调整方案,确保精确匹配优先于参数匹配。
 能力四:测试用例生成与验证
能力四:测试用例生成与验证
使用场景: 验证自动评分修复效果
为判断题答案格式统一功能设计测试用例:
1. 学生答案为选项编号(A/B)的情况
2. 学生答案为中文(对/错)的情况
3. 正确答案为布尔值(true/false)的情况
4. 混合格式的情况
请输出具体的测试步骤和预期结果。
3.3 关键 Prompt 示例
场景:流程图题目类型识别
系统需要支持流程图类型的题目,教师端可以创建,学生端需要用拖拽方式完成。
技术约束:
- 前端使用原生 JavaScript
- 流程图库选择 DrawFlow
- 后端使用 Express.js + MySQL
请输出:
1. 数据存储格式(JSON 结构)
2. 前端编辑器集成方案
3. 教师批改查看方案
4. 可能遇到的技术难点及应对
场景:教师匿名批改分配算法
设计教师试卷分配算法:
- 一个考试有 N 份试卷
- 需要分配给 M 名教师
- 要求:平均分配、随机分配、匿名批改
请输出:
1. 分配算法的 SQL 实现
2. 分配表的结构设计
3. 批改状态的流转逻辑
3.4 踩坑与解决
坑一:DrawFlow 节点样式不生效
问题: CSS 样式选择器优先级问题,导致流程图节点都是统一的长方形,无法区分开始/判断/结束等不同类型。
解决: 深入分析 DrawFlow 库的类名机制,使用 :has() 和更精确的 CSS 选择器组合。
/* 错误写法 */
.node_start { border-radius: 50%; }
/* 正确写法 */
.drawflow .node.start_node {
border-radius: 50%;
background: #4CAF50;
}
坑二:数据库迁移后 API 兼容性问题
问题: 学生表从 student_id 迁移到 student_code 后,大量 API 返回字段名不一致,前端解析失败。
解决: 在服务层添加字段映射,对外暴露统一的字段名。
// 在返回学生信息时统一字段名
const student = {
id: dbStudent.id,
student_code: dbStudent.student_code, // 新增
student_number: dbStudent.student_number, // 新增
name: dbStudent.name,
// 兼容旧的前端代码
student_id: dbStudent.student_code // 别名
};
坑三:CSRF 中间件影响登录接口
问题: /api/auth/student-login 被 checkLogin 中间件拦截,返回 HTML 而非 JSON,导致前端解析失败。
解决: 调整中间件配置,确保登录接口在 checkLogin 之前处理。
// 错误配置
app.use('/api/auth', checkLogin, authRoutes);
// 正确配置
app.use('/api/auth', authRoutes); // 移除 checkLogin
4. 成果展示
4.1 核心功能矩阵
| 功能模块 | 状态 | 说明 |
|---|---|---|
| 学籍号+学号双标识 | 支持学生全生命周期管理 | |
| 自动评分系统 | 题目变更自动重评、答案格式统一 | |
| 教师匿名批改 | 平均随机分配、匿名机制 | |
| 流程图题目 | DrawFlow 拖拽编辑器 | |
| 统计分析 | 成绩图表、班级对比 | |
| CSRF 安全防护 | 前后端 CSRF 令牌机制 | |
| 登录失效跳转 | 401 自动跳转对应角色登录页 | |
| 删除确认弹窗 | 防止误操作 |
4.2 数据库架构演进
原始结构:
students (id, name, student_id, grade, class, ...)
演进后结构:
schools (id, school_code, school_name, ...)
students (id, student_code, student_number, school_id, grade, class, ...)
student_history (id, student_id, school_id, school_code, student_number, ...)
assignments (id, submission_id, teacher_id, status, ...)
4.3 关键代码片段
学籍号自动生成:
async generateStudentCode() {
const year = new Date().getFullYear();
const result = await db.get(
'SELECT MAX(CAST(SUBSTRING(student_code, 5) AS UNSIGNED)) as max_code FROM students WHERE student_code LIKE ?',
[`${year}%`]
);
const nextSeq = (result.max_code || 0) + 1;
return `${year}${String(nextSeq).padStart(4, '0')}`;
}
判断题答案格式统一:
function normalizeBooleanAnswer(answer) {
const normalized = String(answer).trim().toUpperCase();
if (['A', '对', 'TRUE', '正确', 'YES', '1'].includes(normalized)) {
return 'true';
}
if (['B', '错', 'FALSE', '错误', 'NO', '0'].includes(normalized)) {
return 'false';
}
return answer; // 无法识别返回原值
}
4.4 项目结构
d:\code2\
├── modules/
│ ├── exam/ # 考试管理
│ ├── student/ # 学生管理(含双标识)
│ ├── submission/ # 提交与评分
│ ├── assignment/ # 教师分配
│ ├── statistic/ # 统计分析
│ └── auth/ # 认证授权
├── dist/
│ ├── admin/ # 管理后台
│ ├── student/ # 学生端
│ └── teacher/ # 教师端
├── .trae/
│ ├── documents/ # 35+ 份开发文档
│ └── specs/ # 需求规格说明书
└── config/
└── app.json # 系统配置
5. 效果与总结
5.1 量化效果
| 指标 | 原始估计 | 实际使用 SOLO | 提升 |
|---|---|---|---|
| 需求分析 | 7 天 | 0.5 天 | 90% |
| 数据库设计 | 7 天 | 0.5 小时 | 90% |
| API 开发 | 30 天 | 1 天 | 97% |
| Bug 修复 | 60 天 | 15 天 | 75% |
| 总计 | 104 天 | 17 天 | 84% |
5.2 SOLO 在流程中的角色
传统开发流程:
需求 → 设计 → 编码 → 测试 → 修复 → 文档 → 维护
↑______________↓ 效率低下,迭代慢
使用 SOLO 后:
需求(SOLO分析) → 设计(SOLO文档) → 编码(SOLO审查) → 测试(SOLO生成) → 文档(SOLO输出)
↑________________________________________________________________________↓
效率提升 80%+
SOLO 承担的工作:
 需求分析 - 理解业务逻辑,生成规格说明书
需求分析 - 理解业务逻辑,生成规格说明书 代码审查 - 发现潜在 bug 和安全漏洞
代码审查 - 发现潜在 bug 和安全漏洞 文档生成 - 输出开发文档和变更记录
文档生成 - 输出开发文档和变更记录 问题诊断 - 快速定位错误根因
问题诊断 - 快速定位错误根因
5.3 可复用的方法论
方法一:渐进式重构策略
不要一次性重写整个系统,而是:
1. 识别核心模块(数据库层)
2. 设计接口契约
3. 逐个替换实现
4. 验证兼容性
方法二:文档驱动开发 (DDD)
每个功能变更都生成 .trae/documents/ 文档,包含:
- 问题分析
- 解决方案
- 实施步骤
- 风险评估
方法三:AI 辅助代码审查
请审查以下代码,找出:
1. 潜在的安全漏洞
2. 性能问题
3. 边界条件处理
4. 与现有代码风格的一致性
5.4 关键心得
-
AI 是强大的推理引擎,但不是完美的代码生成器
- 需要人工验证 AI 输出的 SQL 和 API 设计
-
清晰的上下文 = 更好的输出
- 提供数据库表结构、现有代码风格,输出质量显著提升
-
文档是最好的知识沉淀
.trae/documents中的 35+ 份文档成为团队共享知识库
-
持续迭代优于一步到位
- 每次小改进都生成文档,积累下来就是完整的演进历史
总结: 使用 TRAE SOLO 完成了从传统开发模式到 AI 驱动开发的转变,将原本 104 天的开发周期压缩到 17 天,同时保证了代码质量和文档完整性。AI 不是替代开发者,而是将开发者从重复性工作中解放,专注于架构设计和业务创新。唯一存在的问题是AI做不到牵一发而动全身,一旦有进行变更就要疯狂修改各种错误,越是小问题越耗时间修改,这应该需要人工辅助,可是我又能力有限做不到。