1. 摘要
用 TRAE SOLO 从零搭建了一个基于飞书 CLI 的 AI Agent Skill——lark-wechat-collector,实现「一句话收藏微信文章到飞书知识库」。自动提取文章内容、下载图片(绕过防盗链)、按原文图文顺序完美还原到飞书文档,并支持 AI 语义检索和总结分析。整个项目从需求拆分到代码实现、测试验证、GitHub 开源,全程由 SOLO 自主完成。
2. 背景
最近老板老是为难我,让我去收集一些公众号的竞品内容,我试过自动化采集和其他的一些工具,但是内容完整度啥的都不理想,然后手动的话。。。
- 复制粘贴 → 排版全乱了,图片一张张保存太麻烦
- 微信收藏 → 找不到、没法搜索、没法和团队共享
- 发到群里 → 过几天就淹没了,再也搜不到
恰好前几天看到 飞书CLI也开源了,于是想到 Trae+飞书文档,肯定能满足我的需求
3. 实践过程
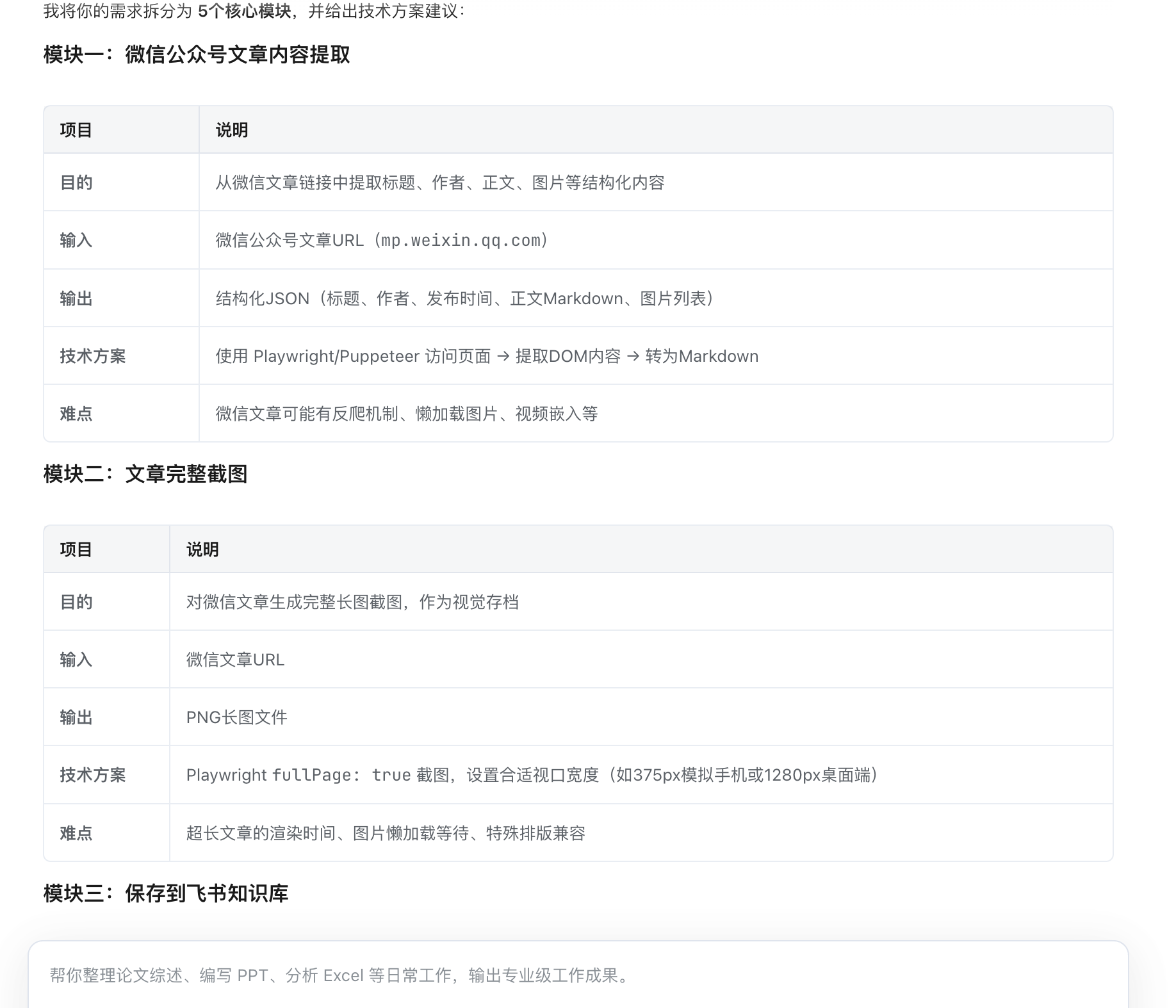
3.1 任务拆解
首先让 SOLO 帮我进行需求拆分和优化,将整个项目拆为 5 个核心模块:
| 模块 | 功能 | 技术 |
|---|---|---|
| 内容提取 | 从微信文章 URL 提取标题、正文、图片 | curl + cheerio |
| 页面截图 | 生成完整长图截图 | Playwright |
| 图片下载 | 绕过微信防盗链下载图片到本地 | Node.js https + Referer |
| 知识库保存 | 按原文图文顺序保存到飞书 | lark-cli wiki/doc/drive |
| 检索分析 | 知识库文章搜索 + AI 总结 | lark-cli wiki/doc + AI Agent |
3.2 技术调研
让 SOLO 研究飞书 CLI 的 Skill 开发标准结构,包括:
skill-template模板格式- 现有 Skill(lark-wiki、lark-doc、lark-drive)的 SKILL.md 写法
- references 参考文档的规范
- Skill 之间的依赖声明方式
3.3 核心代码编写
SOLO 帮我编写了 3 个核心脚本:
① wechat-article-extractor.js — 微信文章提取器
- 使用 cheerio 解析 HTML,深度递归转换 Markdown
- 处理微信文章复杂的 DOM 嵌套(图片在
<a>、<p><span>、多层<section>中)
② feishu-wiki-saver.js — 飞书知识库保存工具(最核心)
- 创建知识库节点
- 下载微信图片(带 Referer 头绕过防盗链)
- 按原文顺序交替写入文字段和图片
- 保存后自动验证图片数量和文档完整性
③ feishu-wiki-searcher.js — 知识库文章检索工具
- 递归搜索知识库节点
- 关键词匹配评分
- 可选读取全文

3.4 踩坑与解决(重点!)
开发过程中遇到了 8 个坑,每个都是 SOLO 帮我排查和修复的:
坑1:微信图片在飞书文档中全部丢失
- 原因:微信图片有防盗链,直接写入飞书文档被忽略
- 解决:先下载图片到本地(带
Referer: https://mp.weixin.qq.com/),再上传到飞书
坑2:图片全部堆在文末,顺序乱了
- 原因:第一版是「先写文字 → 再追加图片」
- 解决:将 Markdown 按
拆分为交替片段,按原文顺序依次写入
坑3:部分图片在提取时丢失
- 原因:
<p>标签用了.text()取纯文本,丢弃了内嵌的<img> - 解决:所有容器标签改为递归调用
htmlToMarkdown($el)
坑4:<a> 标签内的图片丢失
- 原因:微信文章中有些图片被
<a>包裹(跳转小程序) - 解决:
<a>标签递归处理,内部只有图片时只保留图片
坑5:lark-cli 的 @文件路径 必须是相对路径
- 解决:在文件所在目录执行命令,
@后只用文件名
坑6:wiki nodes create 参数格式
- 解决:
space_id用--params,title/node_type/obj_type用--data
坑7:图片格式自动识别
- 解决:根据 HTTP 响应的
Content-Type头判断 png/jpg/gif
坑8:HTTP 302 重定向
- 解决:递归跟随
Location头
3.5 实际测试验证
SOLO 帮我在真实环境中执行了完整流程,用 3 篇真实的微信公众号文章测试:
| 文章 | 字数 | 图片数 | 结果 |
|---|---|---|---|
| 东方乐城|20-01地块顺利开工 | 826 | 5 张 | |
| 【至高加100GB流量】春日流量彩蛋 | 1494 | 11 张 | |
| 华为畅享90系列 | 2031 | 13 张(含 GIF) |
每篇文章都验证了:图片数量匹配、文档字数正常、图文顺序正确。
4. 成果展示
GitHub 仓库
项目结构
lark-wechat-collector/
├── README.md ← 中文 README
├── README_EN.md ← 英文 README
├── LICENSE ← MIT 许可证
├── setup.sh ← 一键安装脚本
├── skills/lark-wechat-collector/
│ ├── SKILL.md ← Skill 主文档(AI Agent 入口)
│ └── references/ ← 详细参考文档(3篇)
├── scripts/ ← 核心脚本(3个)
├── examples/sample-output.md ← 示例输出
└── docs/dev-story.md ← 开发踩坑记录(8个坑)
使用效果
保存文章(一句话触发):
用户: 帮我收藏这篇微信文章:https://mp.weixin.qq.com/s/xxxxx
Agent: ✅ 文章已保存到知识库
标题: 东方乐城|20-01地块顺利开工
字数: 826 字 | 图片: 5 张(全部按原文顺序还原)

搜索文章:
用户: 在知识库中搜索关于"度假区"的文章
Agent: 找到 2 篇相关文章(按匹配度排序)
总结分析:
用户: 总结一下最近保存的那篇关于 RAG 的文章
Agent: [生成结构化总结报告]
飞书知识库实际效果
文章保存到飞书知识库后,图文按原文顺序完美排列,图片清晰显示,排版整洁。
5. 效果与总结
提效数据
| 维度 | 手动收藏 | 使用本 Skill |
|---|---|---|
| 保存一篇文章 | 5-10 分钟 | 30 秒 |
| 图片处理 | 逐张右键保存 | 自动下载上传 |
| 排版还原 | 需手动调整 | 自动按原文顺序 |
| 后续查找 | 翻聊天记录 | AI 语义检索 |
SOLO 在流程中的角色
整个项目从零到上线,SOLO 参与了每个环节:
- 需求拆分 — 帮我理清功能模块和优先级
- 技术调研 — 研究飞书 CLI Skill 标准结构和 API 用法
- 代码编写 — 生成 3 个核心脚本 + SKILL.md + 参考文档
- 调试修复 — 8 个坑的排查和修复,每个都通过实际执行验证
- 文档完善 — README、开发踩坑记录、示例输出
- GitHub 上线 — 参照优秀项目结构,完善仓库配置
可复用的方法
- Skill 开发模式:SKILL.md(AI 入口)+ references(详细文档)+ scripts(辅助脚本)
- 图文顺序还原方案:Markdown 拆分 → 交替写入 → media-insert
- 微信防盗链绕过:Referer 头 + 本地下载 + 重新上传
- HTML 深度递归解析:所有容器标签递归处理,确保零图片丢失
一句话总结
从需求到上线,SOLO 帮我十几分钟就完成了一个完整的功能,解决了微信文章收藏到飞书知识库的痛点,图片不丢、顺序不乱、支持检索和 AI 分析。