【Code with SOLO】用 TRAE SOLO 30 分钟从零搭建「智能数据清洗 + 自动报表生成器」
![]() 摘要
摘要
用 TRAE SOLO 在 30 分钟内从零搭建了一个自动化数据处理工具,将原本需要 2-3 小时的手工数据清洗和报表生成工作压缩到一键完成,输出格式统一、可直接汇报的分析报告。
![]() 背景
背景
我是一名数据分析师,每周需要处理多个业务线的数据源:
-
数据来源分散(Excel、CSV、数据库导出)
-
数据质量参差不齐(缺失值、异常值、格式不统一)
-
需要重复进行清洗、转换、可视化
-
最终要产出标准化的周报/月报
痛点: 每次都要花大量时间在做重复的脏活累活,真正用于分析的时间反而很少。
![]() 实践过程
实践过程
1. 任务拆解
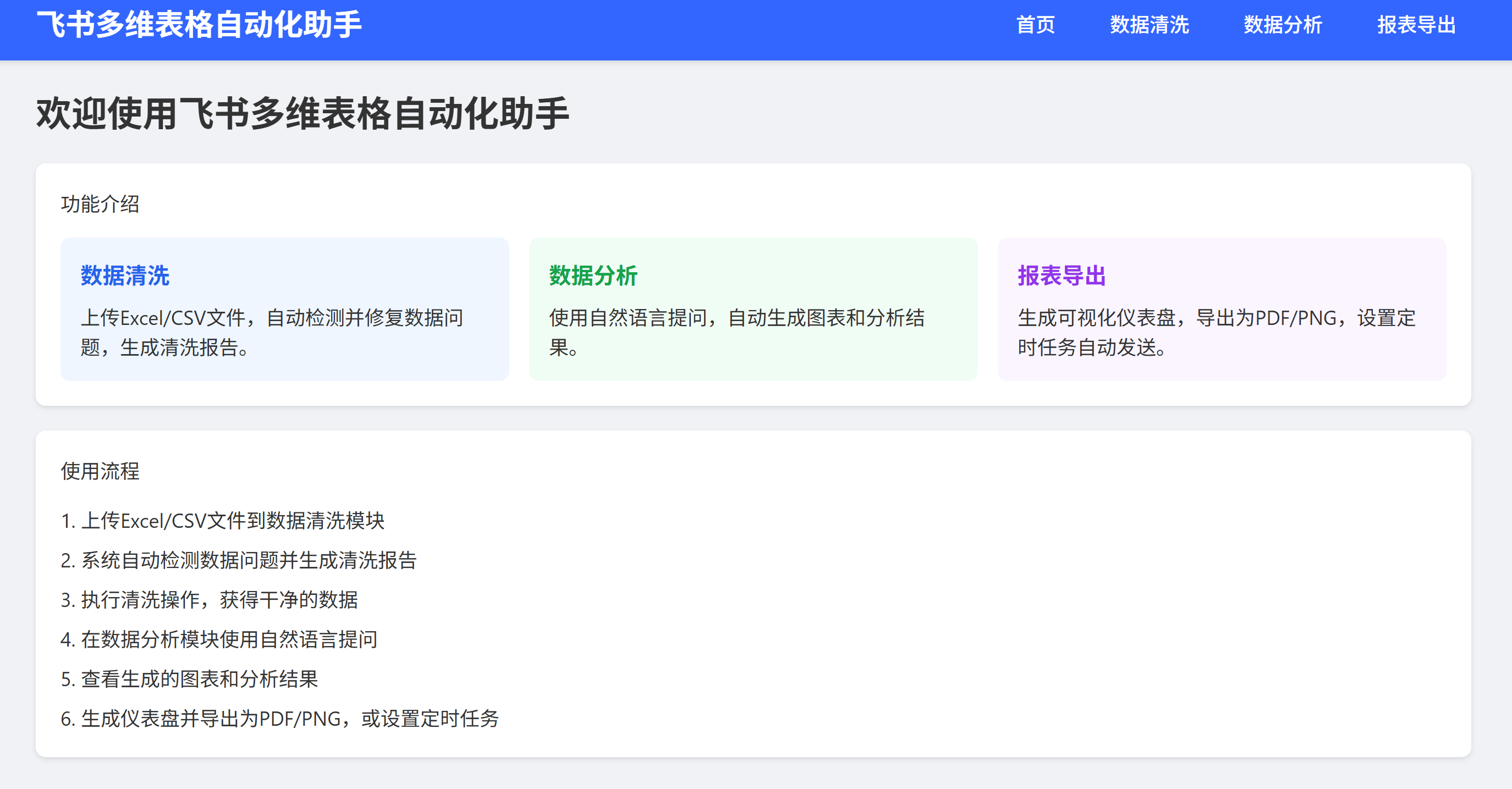
我把整个需求拆成了 4 个模块:
-
数据导入模块:支持多格式文件上传和自动识别
-
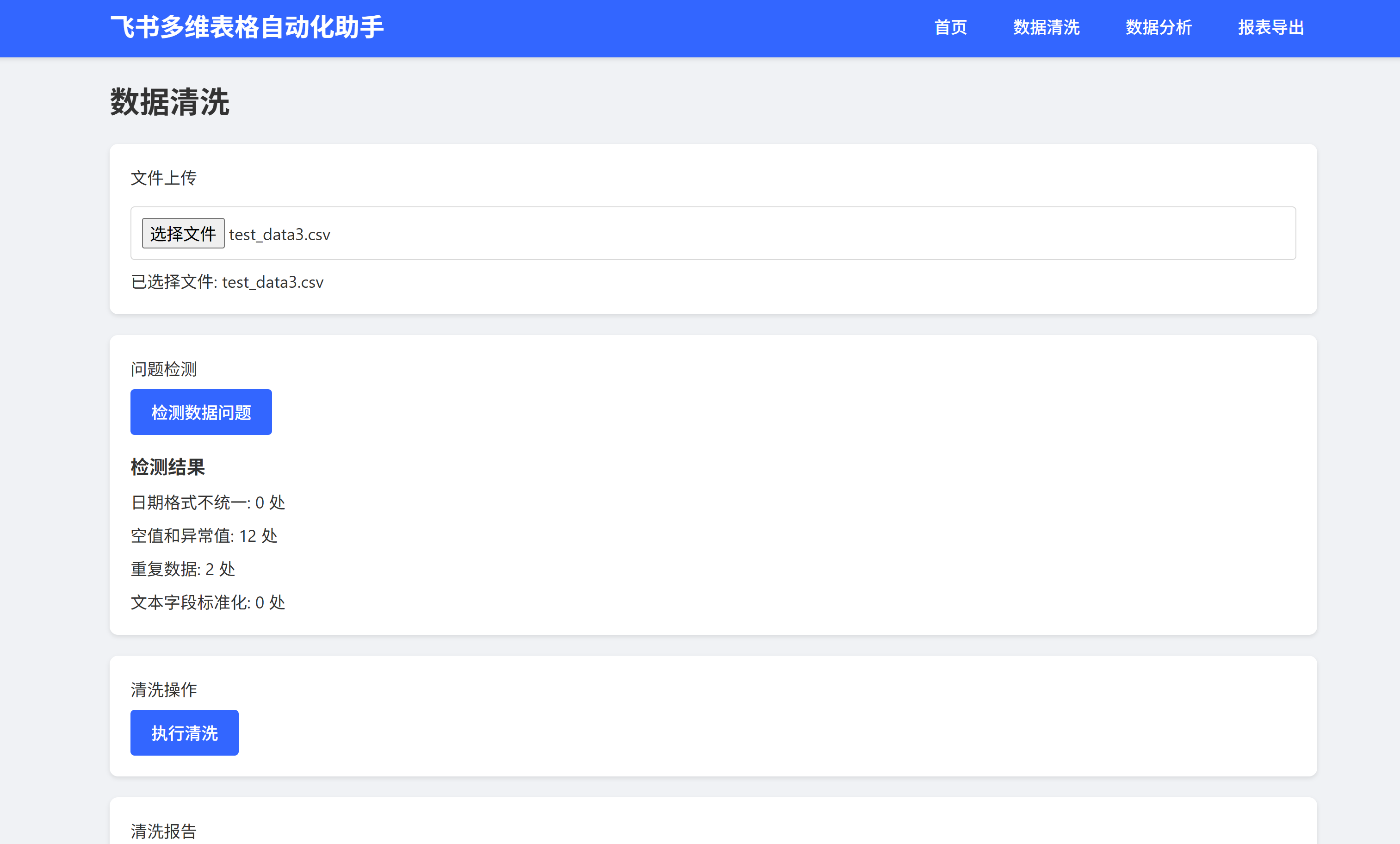
数据清洗模块:自动检测并处理缺失值、异常值、重复值
-
数据分析模块:基础统计 + 自定义指标计算
-
报表生成模块:自动生成可视化图表 + 可下载的 Excel/PDF 报告
2. 使用 SOLO 的能力
-
自然语言描述需求 → SOLO 自动生成代码框架
-
迭代式调试 → 遇到问题直接描述,SOLO 帮我定位和修复
-
代码解释 → 让 SOLO 解释生成的代码逻辑,便于后续维护
-
功能扩展 → 在基础版本上逐步添加新特性
3. 关键 Prompt 示例
"帮我创建一个 Python 脚本,能够:
1. 读取 Excel/CSV 文件
2. 自动检测缺失值并用适当方法填充
3. 识别异常值(使用 IQR 方法)
4. 生成基础统计报告
5. 输出清洗后的数据和可视化图表"
“现在添加一个功能:根据用户选择的列,自动生成柱状图、折线图、箱线图等可视化图表,并保存到指定文件夹”
4. 踩过的坑
-
编码问题:CSV 文件编码不统一导致读取失败 → SOLO 帮我添加了自动编码检测
-
依赖冲突:某些库版本不兼容 → SOLO 生成了 requirements.txt 并指定了版本号
-
性能问题:大数据量时处理慢 → SOLO 建议用 pandas 的优化方法 + 分块处理
![]() 成果展示
成果展示
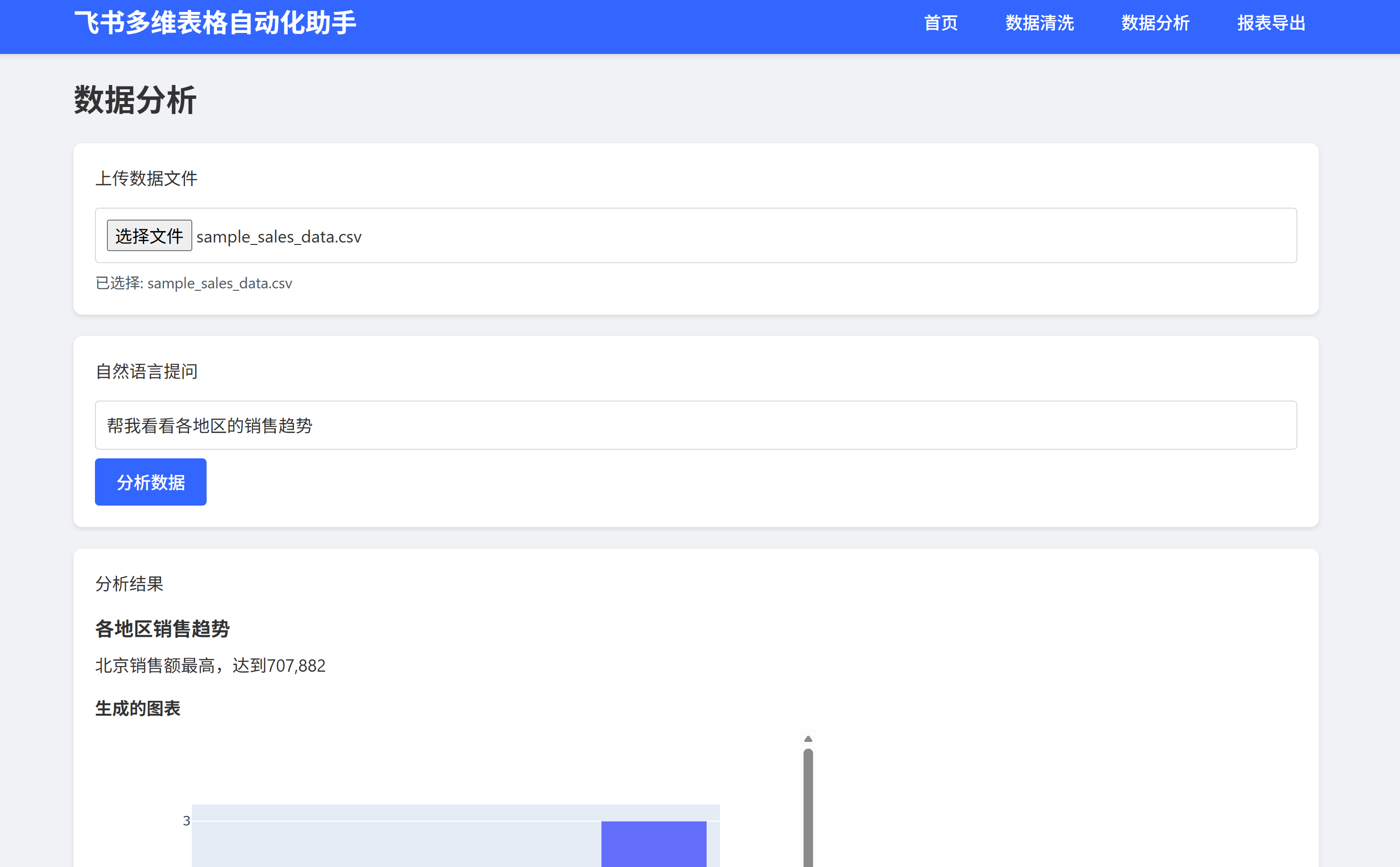
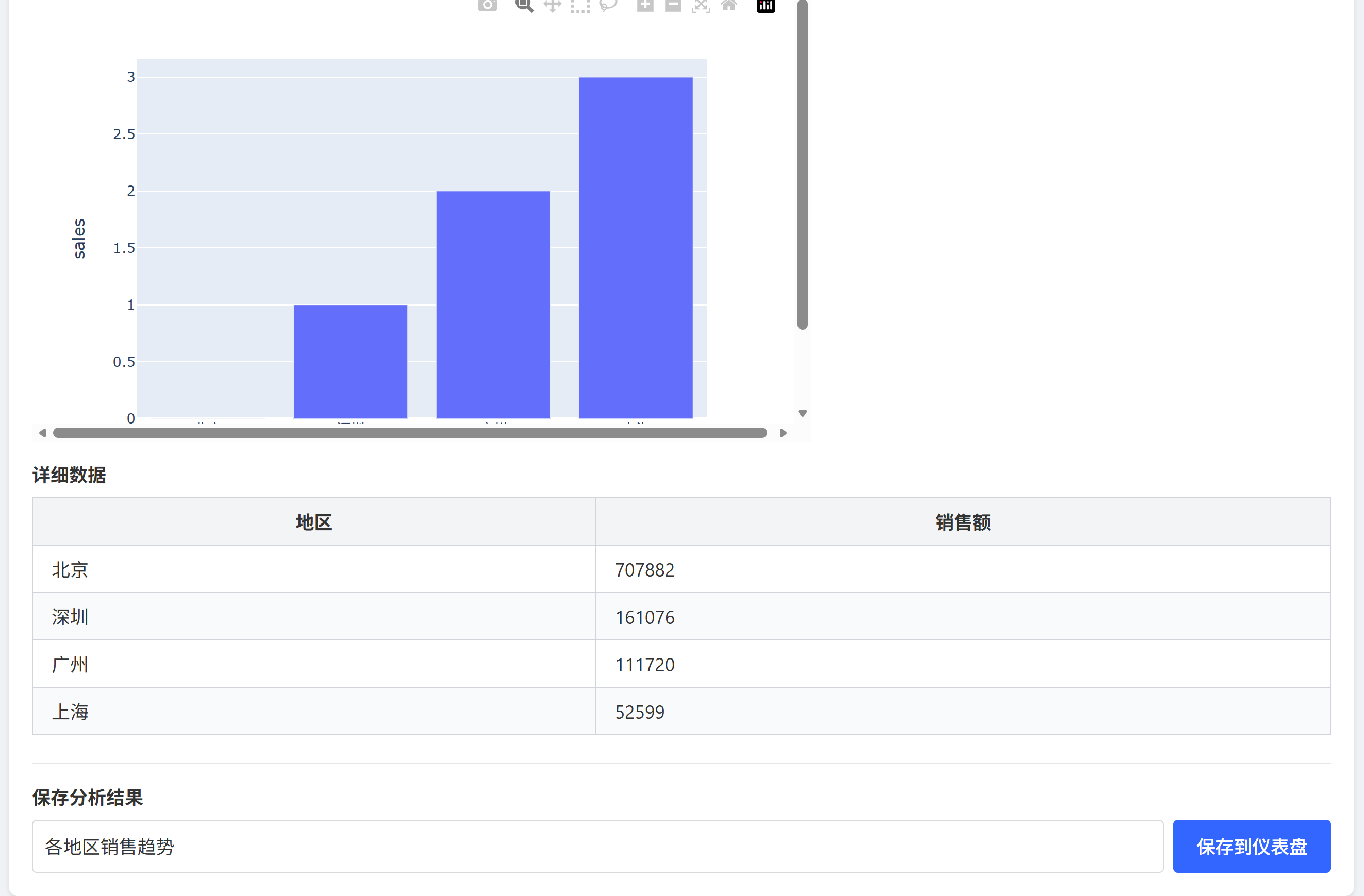
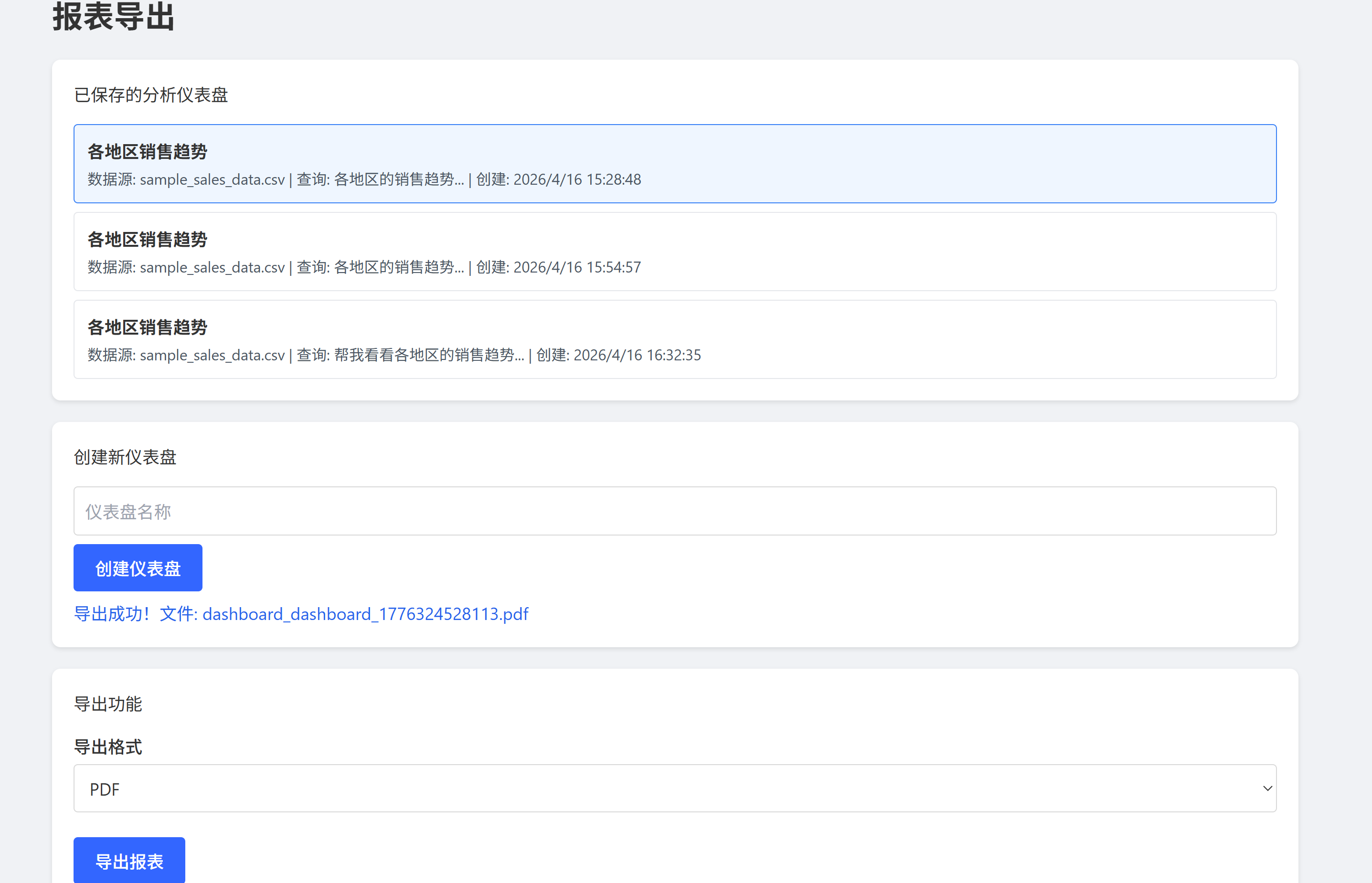
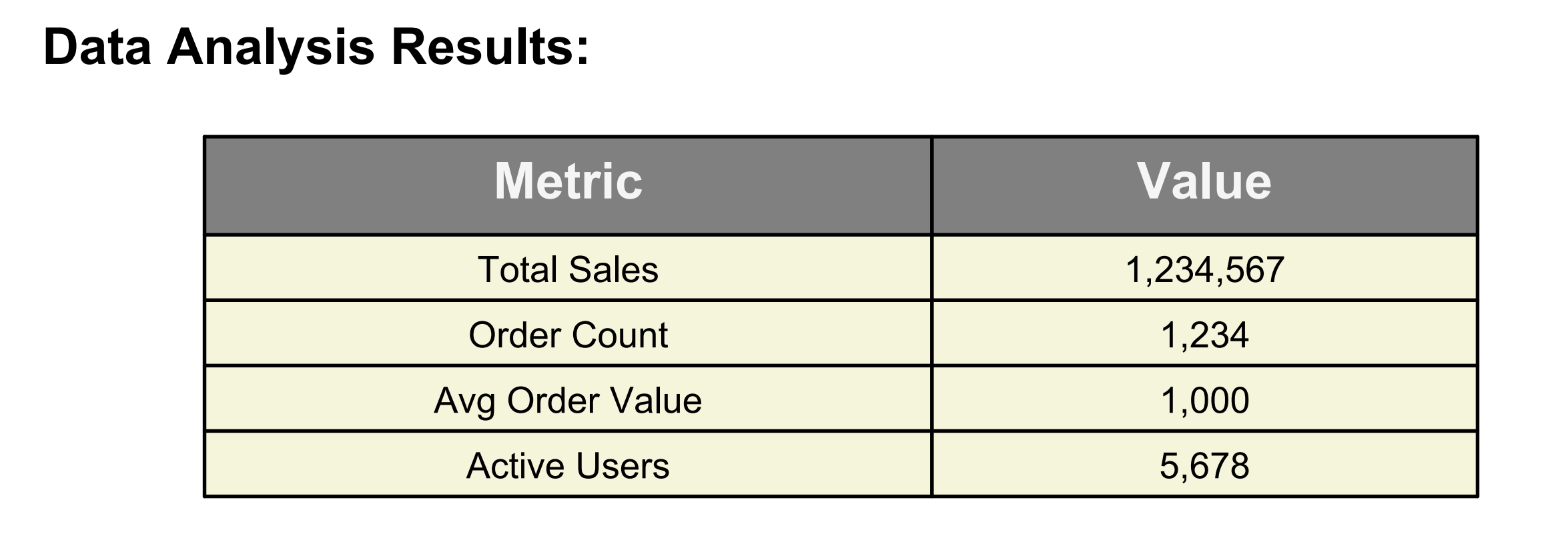
功能清单
![]() 支持 Excel/CSV 多种格式导入
支持 Excel/CSV 多种格式导入
![]() 自动数据质量检测报告
自动数据质量检测报告
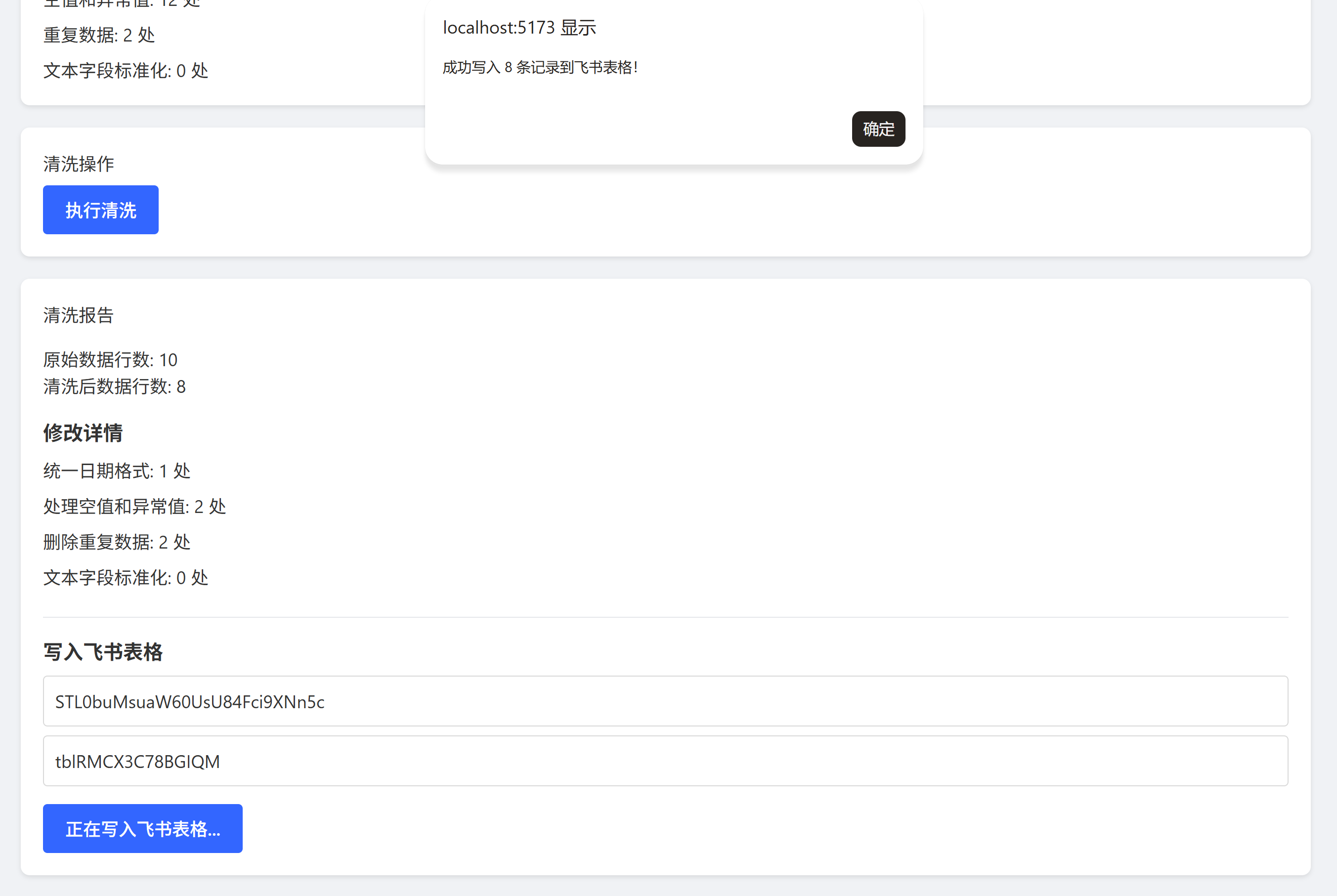
![]() 一键清洗(缺失值/异常值/重复值)
一键清洗(缺失值/异常值/重复值)
![]() 10+ 种可视化图表自动生成
10+ 种可视化图表自动生成
![]() 可自定义分析指标
可自定义分析指标
![]() 导出标准化报告(Excel + PNG 图表)
导出标准化报告(Excel + PNG 图表)
技术栈
-
Python + pandas + numpy
-
matplotlib + seaborn 可视化
-
tkinter 简易 GUI(可选)
-
打包成独立可执行文件
演示截图
(此处建议插入 2-3 张截图:工具界面、清洗前后对比、生成的报表样例)
代码仓库
(如果有公开 GitHub 仓库,可在此附上链接)
![]() 效果与总结
效果与总结
提效对比
| 任务 | 原来耗时 | 现在耗时 | 提升 |
|---|---|---|---|
| 数据导入 + 格式统一 | 30 分钟 | 1 分钟 | 97% ↓ |
| 数据清洗 | 60-90 分钟 | 2 分钟 | 98% ↓ |
| 可视化制作 | 40 分钟 | 5 分钟 | 88% ↓ |
| 报告整理 | 30 分钟 | 1 分钟 | 97% ↓ |
| 总计 | 2.5-3 小时 | ~10 分钟 | ~90% ↓ |
SOLO 在我的流程中做了什么?
-
快速原型:从想法到可运行代码,只用了 30 分钟
-
降低门槛:不需要手写所有代码,专注在业务逻辑上
-
加速调试:遇到问题不用到处搜,直接问 SOLO
-
知识沉淀:通过 SOLO 的解释,理解了更多数据处理的最佳实践
可复用的方法
-
先描述整体目标,让 SOLO 生成框架
-
小步迭代,每添加一个功能就测试一次
-
遇到报错直接贴给 SOLO,通常能快速解决
-
让 SOLO 写注释和文档,方便后续维护
![]() 总结
总结
这次实践让我深刻体会到:AI 编程不是要取代开发者,而是让我们从重复劳动中解放出来,把时间花在更有价值的分析和决策上。
TRAE SOLO 就像一个随时在线的编程搭档,帮你把想法快速变成现实。对于数据分析师来说,这种"描述需求 → 自动生成 → 迭代优化"的工作流,真的能释放大量创造力。
推荐给同样被数据处理困扰的朋友们试试!