【More-than-Coding】MTC模式实战4小时实现主流在线文档错别字校准大师
背景:为什么想做这个
我是一名数据分析师,日常工作需要写大量的分析报告。说实话,写报告本身不是问题,问题是我从小语文就不好,错别字就像附骨之疽——每次提交报告给 leader,总能被圈出几个错别字。
“时限"写成"实现”、"帐号"和"账号"分不清……这些同音字错误我自己读十遍都看不出来,但 leader 一眼就能发现。
久而久之,错别字成了我职场焦虑的来源之一。每次提交报告前都要反复检查,但效率极低,而且总有漏网之鱼。
直到有一天,我在飞书文档里写报告的时候突然想到:能不能做一个工具,在我打字的时候自动检测错别字,就像 Grammarly 检测英文那样?
刚好最近在深度使用 SOLO,就想着能不能直接让它帮我把这个想法落地。
项目概述
做一个 Chrome 浏览器扩展,在飞书文档、企业微信文档等主流在线协作平台中,实时检测中文错别字,并通过下划线 + 浮动面板的方式提示用户。
核心功能:
| 功能 | 说明 |
|---|---|
| 实时检测 | 输入停顿或句子结束时自动检查 |
| 下划线标记 | 在错误文字下方显示红色波浪线 |
| 错误面板 | 右侧浮动面板展示所有错误及修正建议 |
| API 通用 | 兼容 DeepSeek、OpenRouter 等所有 OpenAI 格式的 API |
| 段落级提取 | 只发送当前段落文本,不浪费 Token |
| Canvas 适配 | 企业微信文档的 Canvas 渲染也能工作 |
技术栈:Chrome Extension MV3 + Content Script + Service Worker + DeepSeek API,纯前端,零后端。
我是怎么做的:全程对话式开发
整个项目我从头到尾没有写一行代码,全部通过和 SOLO 对话完成。下面按步骤还原全过程。
第 1 步:项目初始化
我对 SOLO 说: 帮我想做一个在我写报告时自动帮我纠正错别字的插件。
MTC 直接帮我搭建了完整的项目骨架,并帮我清晰得梳理出了项目结构:
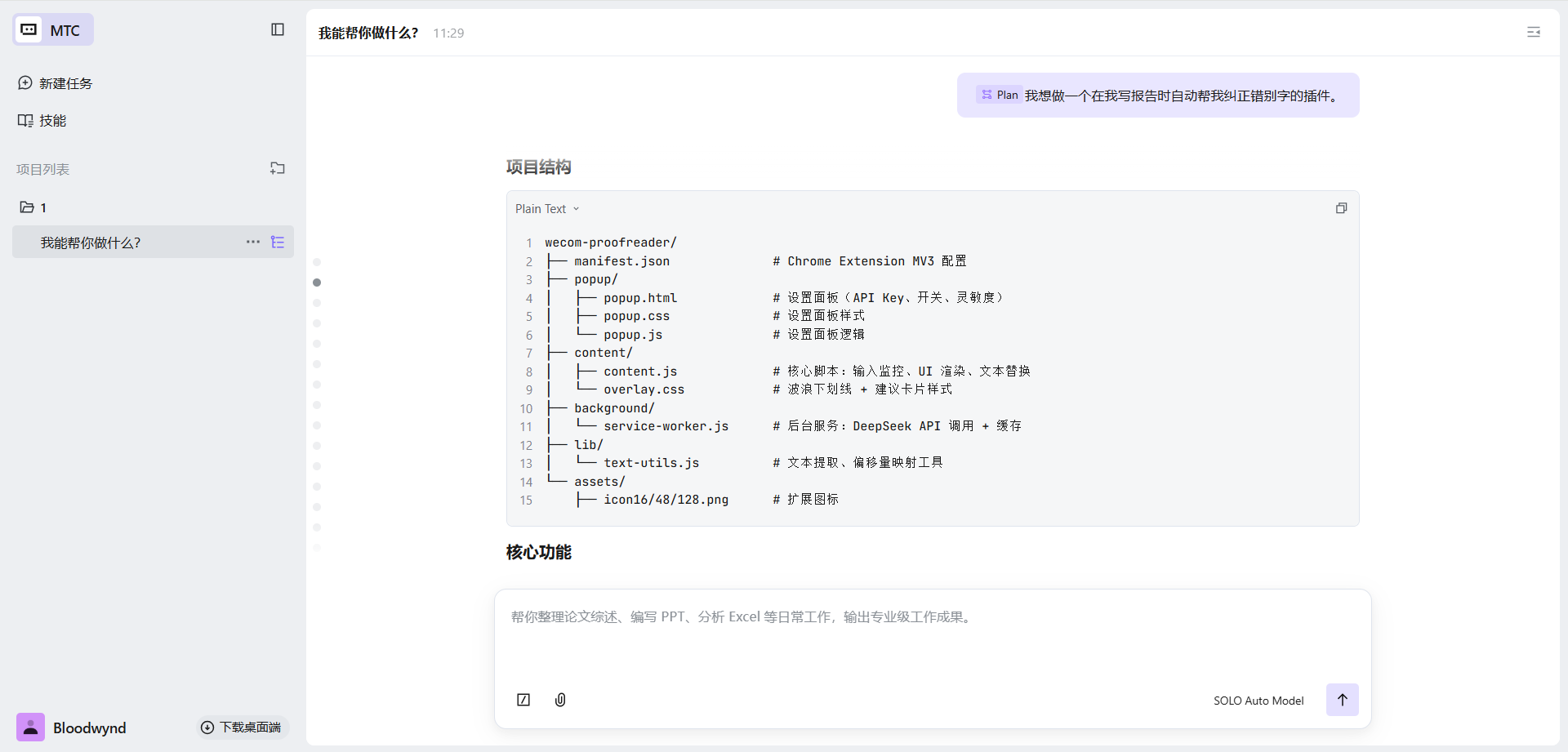
wecom-proofreader/
├── manifest.json # Chrome Extension MV3 配置
├── popup/
│ ├── popup.html # 设置面板
│ ├── popup.css
│ └── popup.js
├── content/
│ ├── content.js # 核心:输入监控 + UI 渲染
│ └── overlay.css # 下划线样式
├── background/
│ └── service-worker.js # API 调用 + 缓存
├── lib/
│ └── text-utils.js # 文本提取工具
└── assets/
└── icon16/48/128.png # 扩展图标
包括 manifest.json 的权限配置、popup 设置面板(API Key 输入、开关、灵敏度调节)、content script 的输入事件监听、service worker 的 API 调用逻辑,一次对话全部生成。
这一步的感受: 现在直接描述需求,SOLO 帮你把所有都搞定,小白也可以实现梦想。
第 2 步:编辑器适配——最折腾的一步
项目搭好了,但真正的挑战才刚开始。为了让自己能更加清晰的判断,我简单读了下整个项目,并发出了一些疑问,大模型得API调用功能是否多平台通用(OpenAI/Deepseek/Openrouter)?编辑器找不到?等。
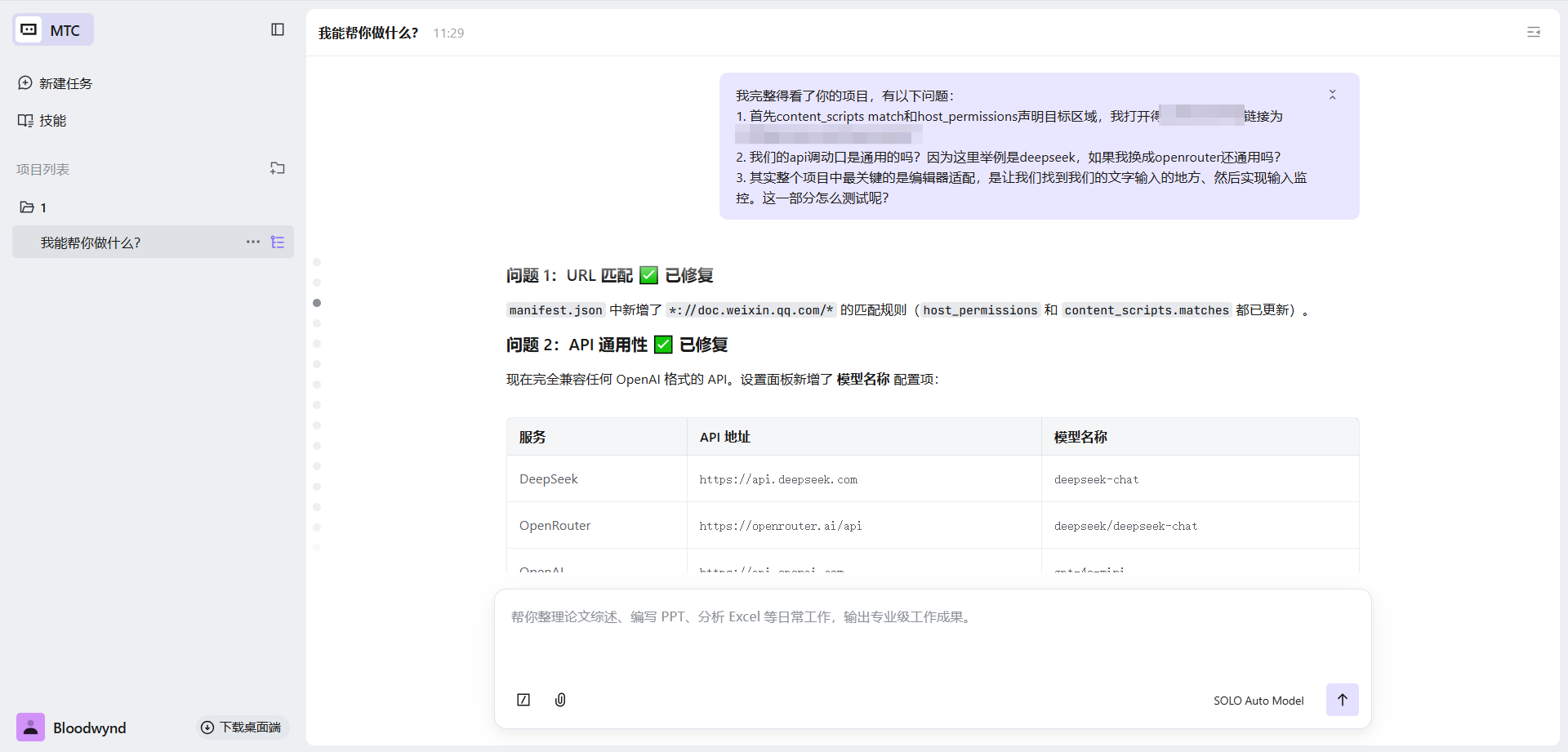
初次使用发现插件获取不到我们的编辑框,MTC增加了日志的输出 并设计了一个test文本供我们本地测试,同时制定了详细的测试步骤教程。
测试后发现飞书是DOM编辑器,企微文档是Canvas编辑器,于是我兵分两路各自突破。
飞书文档:DOM 编辑器
飞书文档使用的是基于 ProseMirror 的 DOM 编辑器,文字是真实的 DOM 文本节点。理论上我们的 content script 可以直接读取和操作。
但实际测试时发现了一个关键问题:插件读取到的文本是 89 个字符,但我只输入了 6 个字。
原因: 插件把整个编辑器容器(包括工具栏、标题、作者名等)的文本都读进来了。

我对 SOLO 说: 发送了 89 个字符给 API,但我只输入了 6 个字,这严重不合理。
SOLO 帮我优化了文本提取逻辑——从"读取整个编辑器"改为"只读取光标所在的段落"。通过 Selection API 找到光标位置,向上查找块级元素,只提取该段落的文本。
优化后:89 字符 → 6 字符,Token 消耗降低 90%+。
企业微信文档:Canvas 编辑器
飞书搞定了,但企业微信文档直接给了我一个下马威。
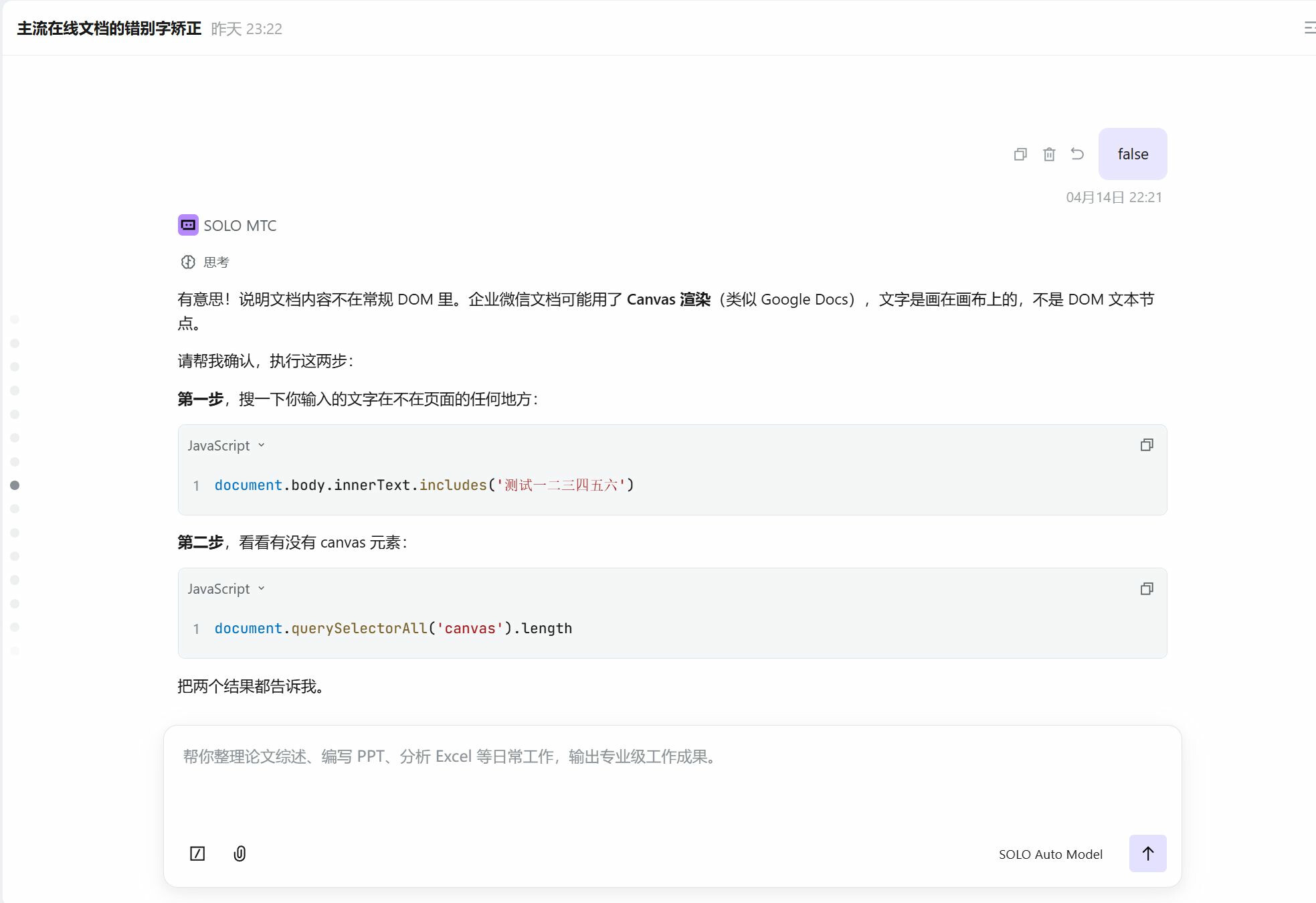
打开企业微信文档后,插件确实检测到了一个 contenteditable 元素,但它的尺寸是 5×0 像素——一个隐藏的输入法辅助框。
更离谱的是,我在文档里输入的文字,在 document.body.innerText 里完全找不到。页面有 3 个 <canvas> 元素。
结论:企业微信文档使用 Canvas 渲染,文字是画上去的,不是 DOM 文本节点。
这意味着:
 无法从 DOM 读取文本
无法从 DOM 读取文本- 无法用 DOM Range 定位下划线
- 无法用 execCommand 修改文字
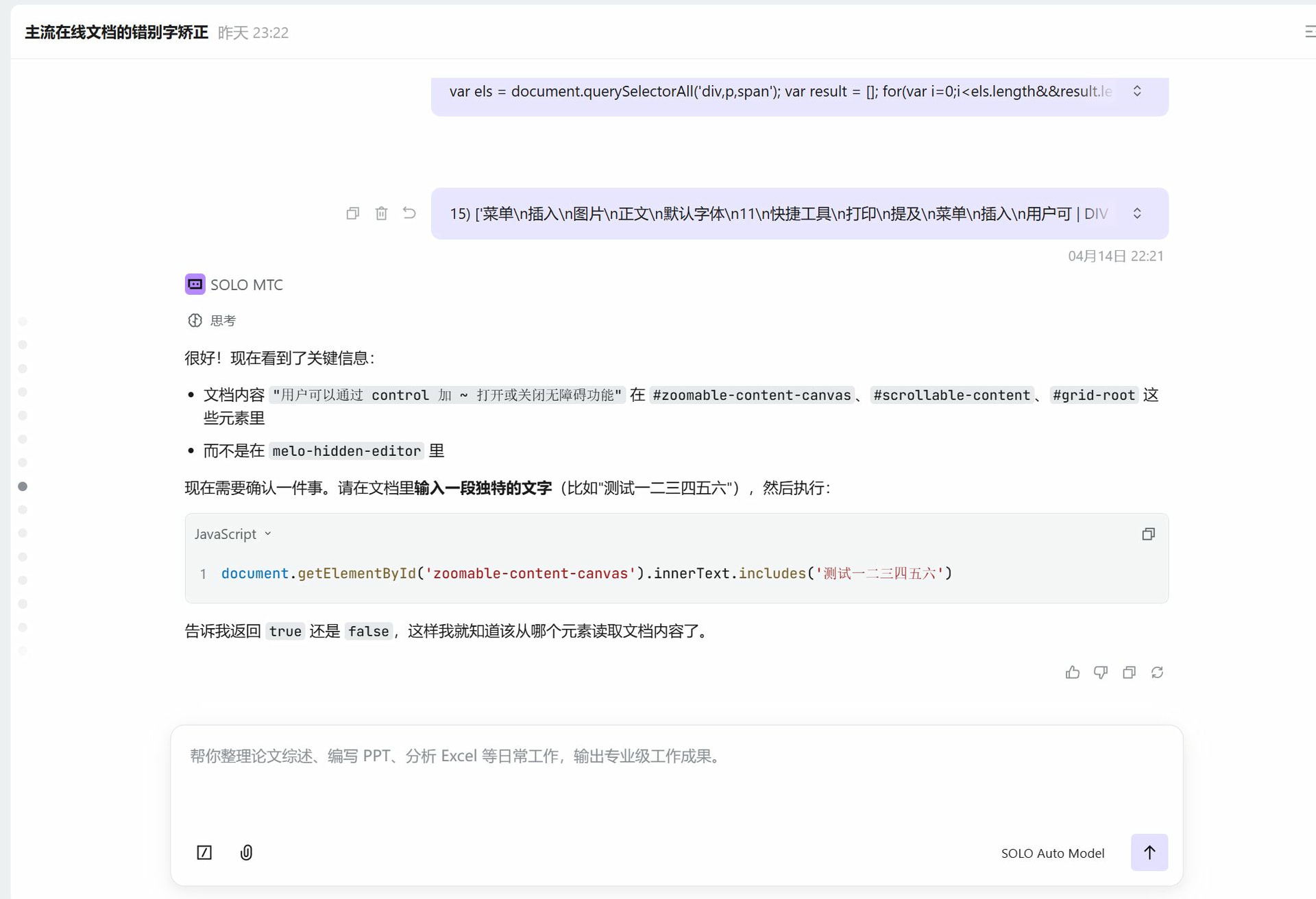
我对 SOLO 说: 企业微信文档是 Canvas 渲染,文字不在 DOM 里,怎么办?
最终确定的方案是:通过拦截 compositionend 事件获取每次输入的文字片段,维护一个文本缓存,句子结束时发送检查。虽然没有内联下划线,但浮动面板仍然可以显示错误列表。
这一步的感受: 如果没有 SOLO 帮我在企业微信文档里一步步排查 DOM 结构(执行 querySelector、检查 innerText、分析 canvas),我自己可能要花一整天才能定位到 Canvas 渲染这个问题。
第 3 步:触发策略优化
最初的设计是"输入停顿 500ms 就检查",但实际使用中发现一个问题:我打字是一个词一个词打的(中文输入法),每打一个词就发一次 API 请求,太浪费了。
我对 SOLO 说: 一个词一个词发送给大模型检查完全没有意义,只需要一句话检查一次就好了。
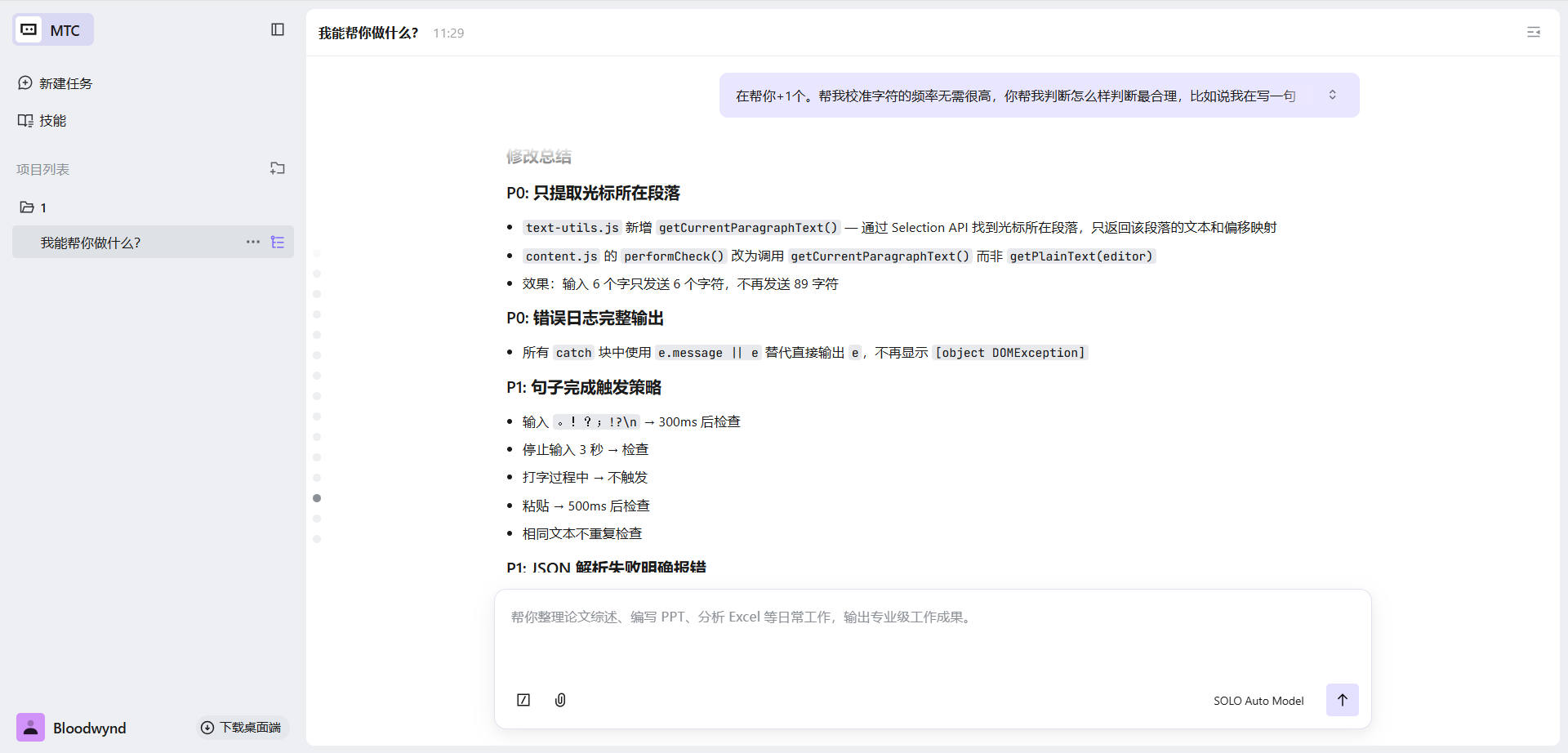
SOLO 帮我改成了"句子完成触发"策略:
| 触发条件 | 延迟 | 说明 |
|---|---|---|
| 句号、问号、感叹号等 | 300ms | 句子写完了,立即检查 |
| 换行 | 立即 | 检查上一段 |
| 停止输入 3 秒 | 3000ms | 长停顿,检查当前内容 |
| 正在打字 | 不触发 | 避免频繁请求 |
写一句话只发 1 次请求,体验和成本都大幅改善。
第 4 步:大模型返回的偏移量不可信
这是整个项目里最"坑"的一个问题。
大模型返回的错别字位置是这样的:
段落内容: "我在人民广厂。"(8 字符)
API 返回: {start: 0, end: 12, original: "广厂"}
start: 0, end: 12 直接超出了 8 字符的范围。还有的时候返回 start: 3, end: 5,指向的是"民广"而不是"广厂"。
大模型的字符计数能力并不可靠。
我对 SOLO 说: 模型返回的偏移量不准,别按模型的来了。

SOLO 帮我改成了"完全忽略模型偏移量,始终用 original 字段做 indexOf 搜索定位"的策略:
模型返回: {start: 3, end: 5, original: "广厂"} ← 偏移量直接忽略
↓ 用 "广厂" 在 "我在人民广厂。" 中搜索
↓ indexOf 找到位置 4
↓ 修正为: {start: 4, end: 6} ✅
这个问题如果不解决,下划线永远画不到正确的位置上。
第 5 步:API 兼容性
最初默认使用 DeepSeek API,但我想切换到 OpenRouter 使用更多模型。
我对 SOLO 说: 如果我换成 OpenRouter 还通用吗?
SOLO 帮我在设置面板里新增了"API 地址"和"模型名称"两个配置项,并确保代码兼容所有 OpenAI 格式的 API:
| 服务 | API 地址 | 模型名称 |
|---|---|---|
| DeepSeek | https://api.deepseek.com |
deepseek-chat |
| OpenRouter | https://openrouter.ai/api |
deepseek/deepseek-chat |
| OpenAI | https://api.openai.com |
gpt-4o-mini |
切换服务只需改两个配置项,代码零修改。
最终效果
| 功能 | 飞书文档 | 企业微信文档 |
|---|---|---|
| 编辑器检测 | ||
| 错别字检测 | ||
| 下划线标记 | ||
| 错误面板 | ||
| 句子触发 | ||
| 段落提取 | ||
| API 通用 |
总结:几点心得
1. 需求要迭代着提,不要试图一次性描述完美
我最开始的需求就是"做一个错别字检测的功能",非常模糊。但没关系,SOLO 先帮我搭了一个能跑的版本,然后我在实际测试中发现问题,再逐步提需求优化。
“发送了 89 个字符但只输入了 6 个字”——这是测试才发现的。
“模型返回的偏移量不准”——这也是测试才发现的。
“飞书把我的 DOM 删了”——还是测试才发现的。
先跑起来,再迭代优化。 这比试图在脑子里把所有细节都想清楚再动手高效得多。
2. 排查问题时,让 AI 帮你执行诊断命令
企业微信文档是 Canvas 渲染这个结论,不是我想出来的,是我让 SOLO 给我一段 JavaScript 代码,我在浏览器 Console 里执行后,根据返回结果一步步定位到的。
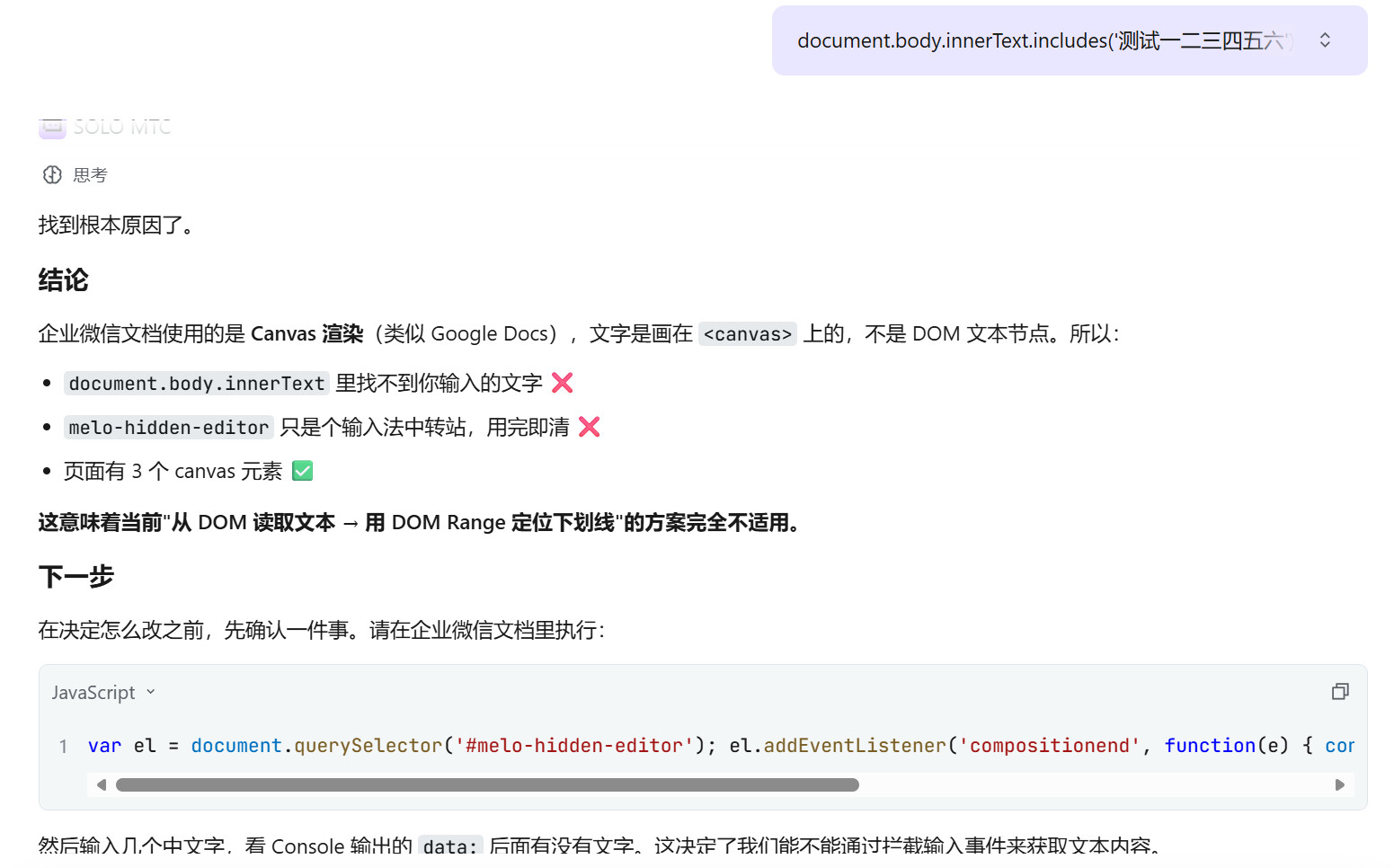
document.body.innerText.includes('测试文字') → false
document.querySelectorAll('canvas').length → 3
两行代码就确认了 Canvas 渲染。这种"我提方向 + AI 给工具 + 我执行 + AI 分析结果"的协作模式,比自己一个人排查效率高很多。
3. 知道什么时候该放弃
自动修正功能我们在飞书文档上折腾了很久——execCommand 不生效、事件被拦截、DOM 被清理……最后我决定直接注释掉所有修正代码,只保留检测和提示。
有时候"不做"比"做了但不好用"更好。 一个稳定的检测 + 提示工具,比一个经常出 bug 的检测 + 修正工具更有价值。
4. AI 编程不是"一键生成",是"对话式工程"
这个项目从开始到完工,我和 SOLO 之间来回了大概二十多轮对话。每一轮都是:我发现问题 → 描述给 SOLO → SOLO 给出方案 → 我测试 → 发现新问题。
这不是"AI 帮我写代码",而是"AI 帮我解决我描述的问题"。区别在于:我不需要懂 Chrome Extension 的 API、不需要懂 Canvas 渲染原理、不需要懂 DOM Range 的用法——我只需要能把问题说清楚。
作为一个数据分析师,我写不出这个扩展的任何一行代码。但我能把它做出来,并且在我每天使用的飞书文档里正常运行。
这大概就是 AI 编程工具最大的价值:降低了从"想法"到"产品"的门槛,让非技术人员也能把脑子里的想法变成真正能用的工具。