摘要
用 TRAE SOLO 对 5 个主流 AI 平台(豆包、DeepSeek、Kimi、腾讯混元、通义千问)的 85 条旅游推荐回答进行了完整的数据分析——从基础统计、实体属性抽取、跨平台对比、回答组织逻辑分析、聚类分析,到提出 7 个可验证假设并设计实验方案。原本需要数据分析师 2-3 天的工作量,SOLO 在半天内完成,且产出了一个可复用的 AI 推荐行为研究框架。
背景
我是一名品牌AI策略顾问,正在做的事情是帮品牌管理它们在 AI 平台上的"叙事可见度"——例如,当用户问 AI"五一去哪玩",旅游行业客户的品牌会不会被推荐、以怎样的表述方式被这些AI平台推荐。
为了建立一个可复用的审计分析框架,我需要对多个 AI 平台的推荐回答做系统性分析。具体挑战:
- 数据是非结构化的自然语言(每条回答 800-2400 字不等)
- 需要跨平台、跨 prompt 类型做多维度对比
- 不仅要统计"推荐了谁",还要分析"AI 用什么逻辑框架组织推荐"
- 最终要产出可验证的研究假设,而非纯描述性分析
这不是一个标准的数据分析任务,它混合了定量统计、文本分析、聚类建模和研究设计——传统工具链需要 Python + NLP 库 + 可视化工具 + 人工编码等等
实践过程
需要分析的85条回答数据,通过已有API调用任务管理完成。
整个分析分 6 个阶段,全部在 TRAE SOLO 中完成:
阶段一:基础统计和实体提取
任务拆解:先让 SOLO 理解数据结构。我把 85 条 CSV 格式的监测数据(字段:平台、prompt、完整回答、字数、提及目的地列表)喂给 SOLO,要求做基础统计。然后,我指定了旅游场景想要提取的属性,让SOLO进行实体提取,从而获取回答中更多属性关联,再基于属性进行统计分析。
SOLO 产出:自动生成了 Python 脚本完成数据解析、实体提取,输出了各平台回答的基础统计(如回答问题字数、响应时长、token消耗等)。
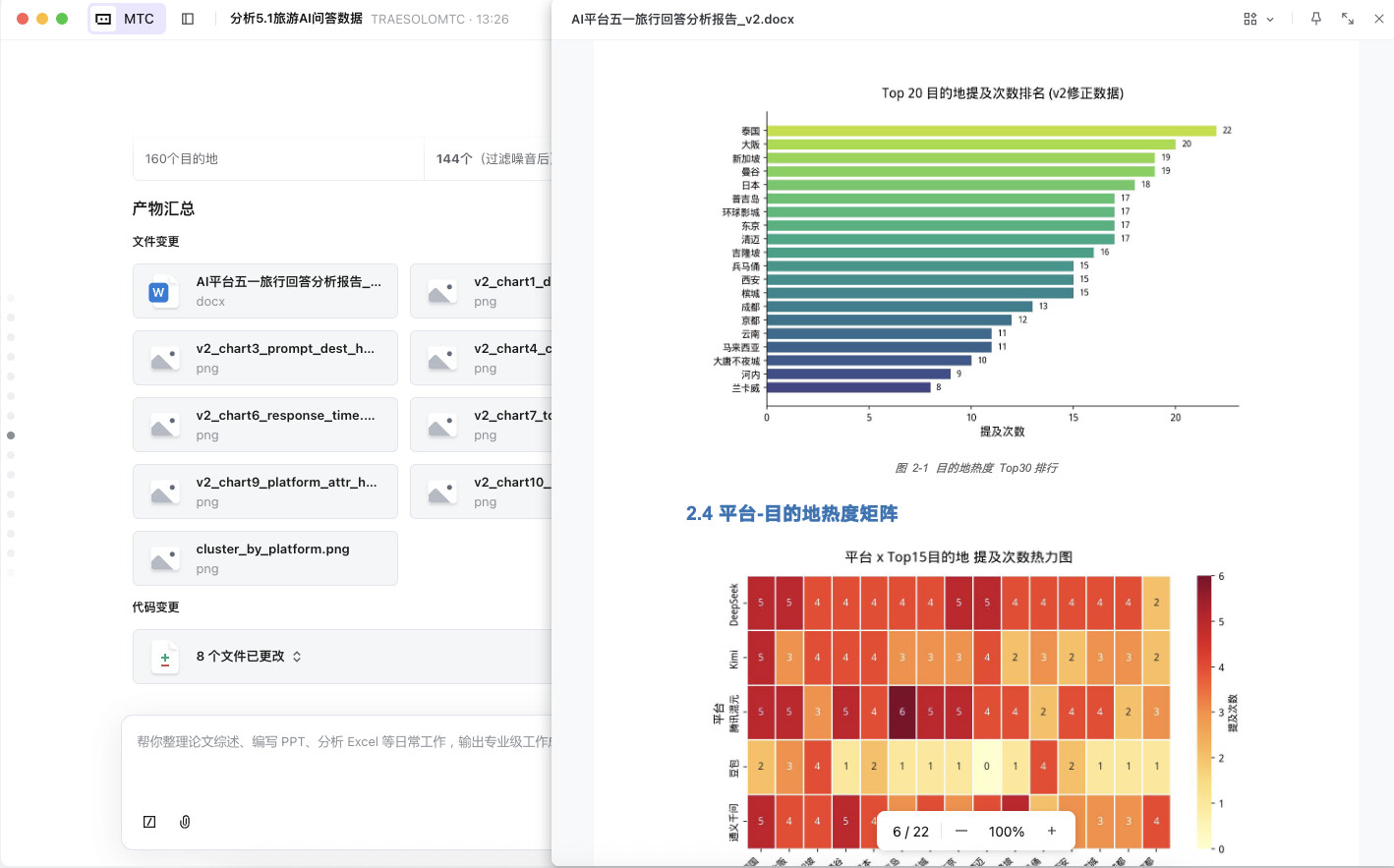
阶段二:跨平台属性对比分析
SOLO 产出:基于上一部提取出的属性后的数据,进行属性统计分析
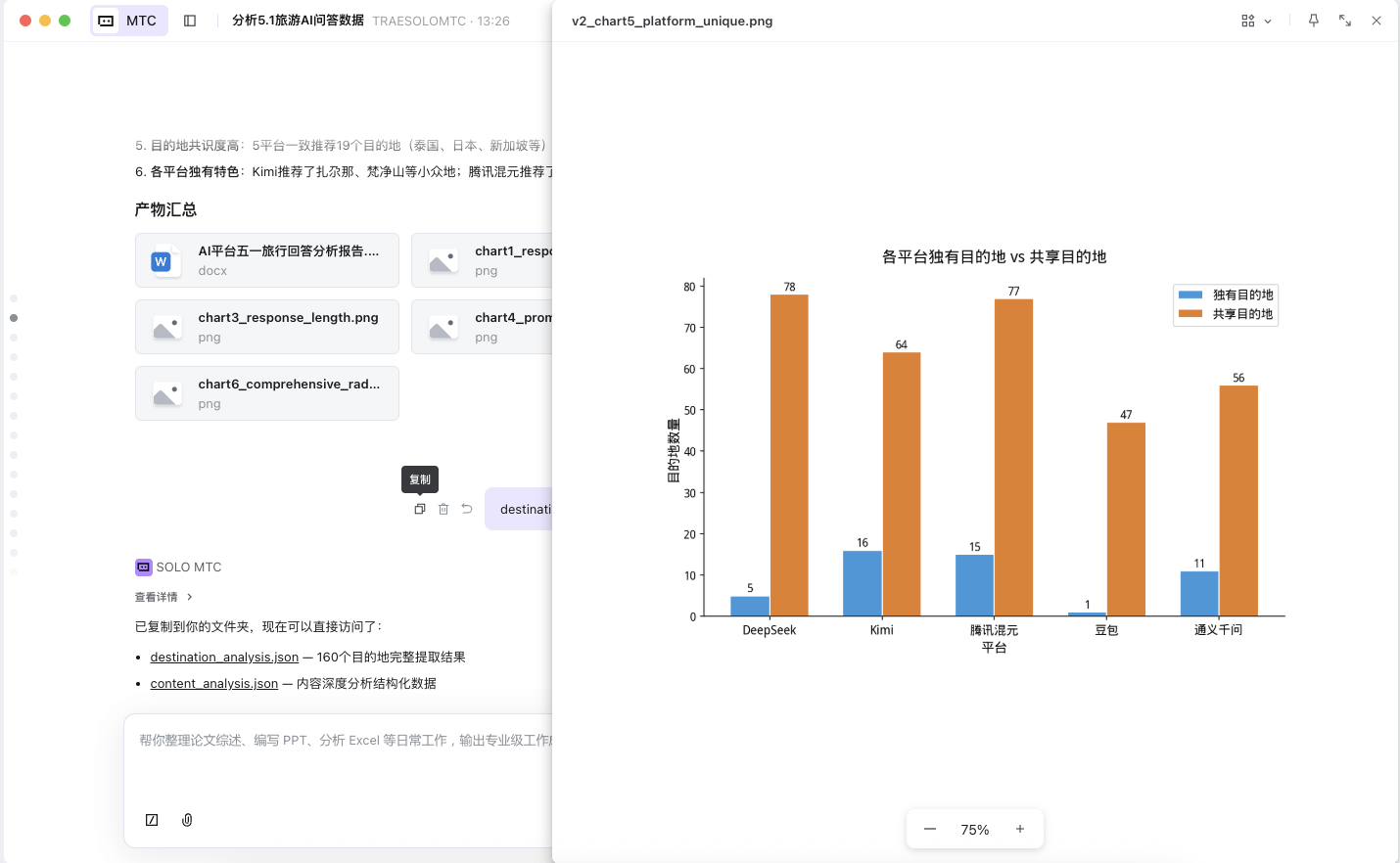
阶段三:AI 回答组织逻辑分析
这是最关键的一步——不只看"推荐了谁",而是分析"AI 用什么结构组织推荐"。
关键 Prompt:不同Prompt触发的组织逻辑不同,这个有这个特点么?跨prompt对比分析:例如,1。 同一个目的地在不同prompt中的排位变化; 2。AI的分类逻辑变化**:普通推荐按预算分,亲子推荐按场景分——AI是否会根据用户画像切换推荐框架;3。目的地出现的一致性**:哪些目的地在所有prompt中都出现?(泰国、日本几乎每条都有)哪些只在特定场景出现?
SOLO 产出:识别出 Prompt类型强烈影响组织逻辑,但影响方式分两个层次:第一层:Prompt类型决定"大模式切换"; 第二层:Prompt中的关键词触发"微调";
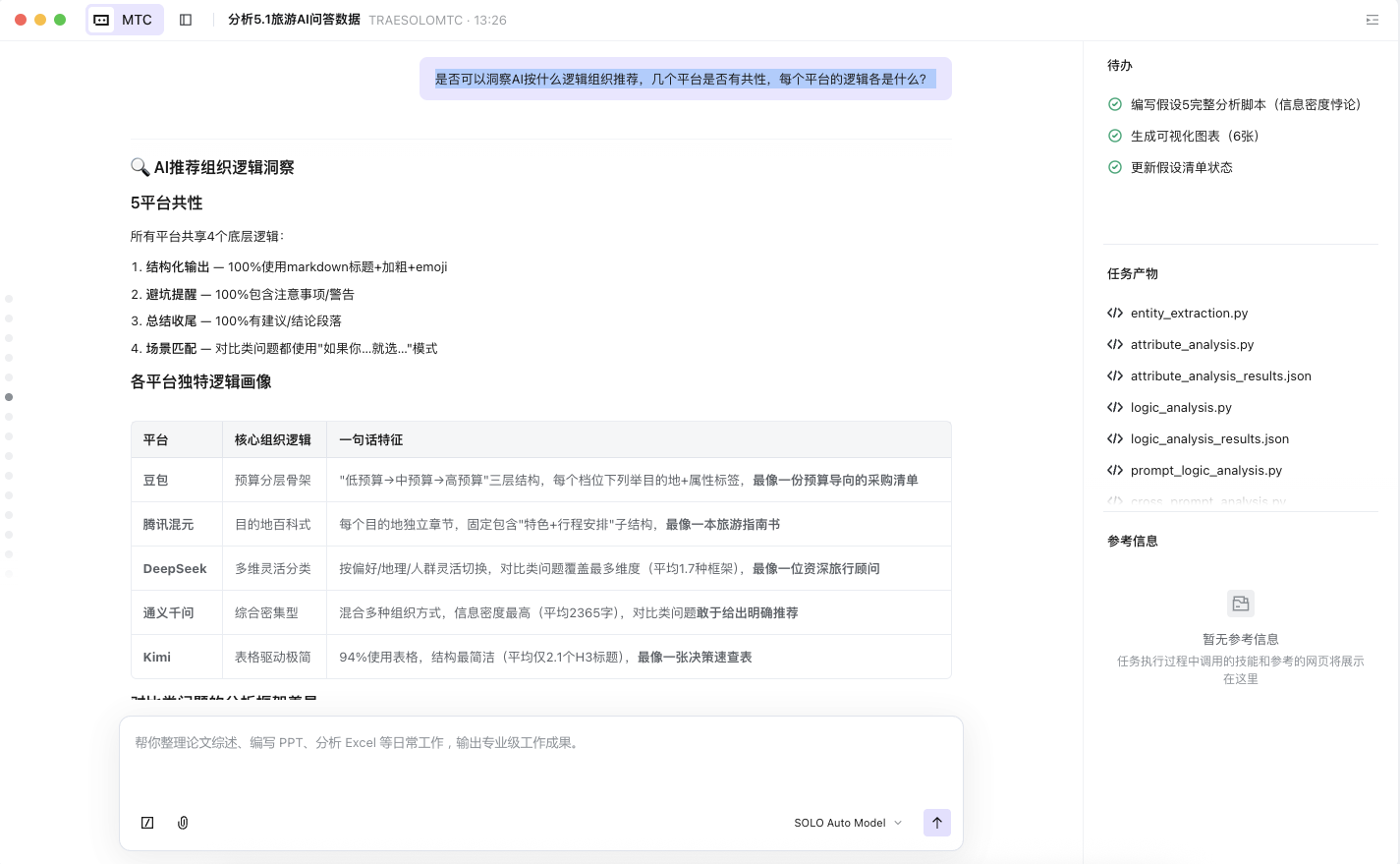
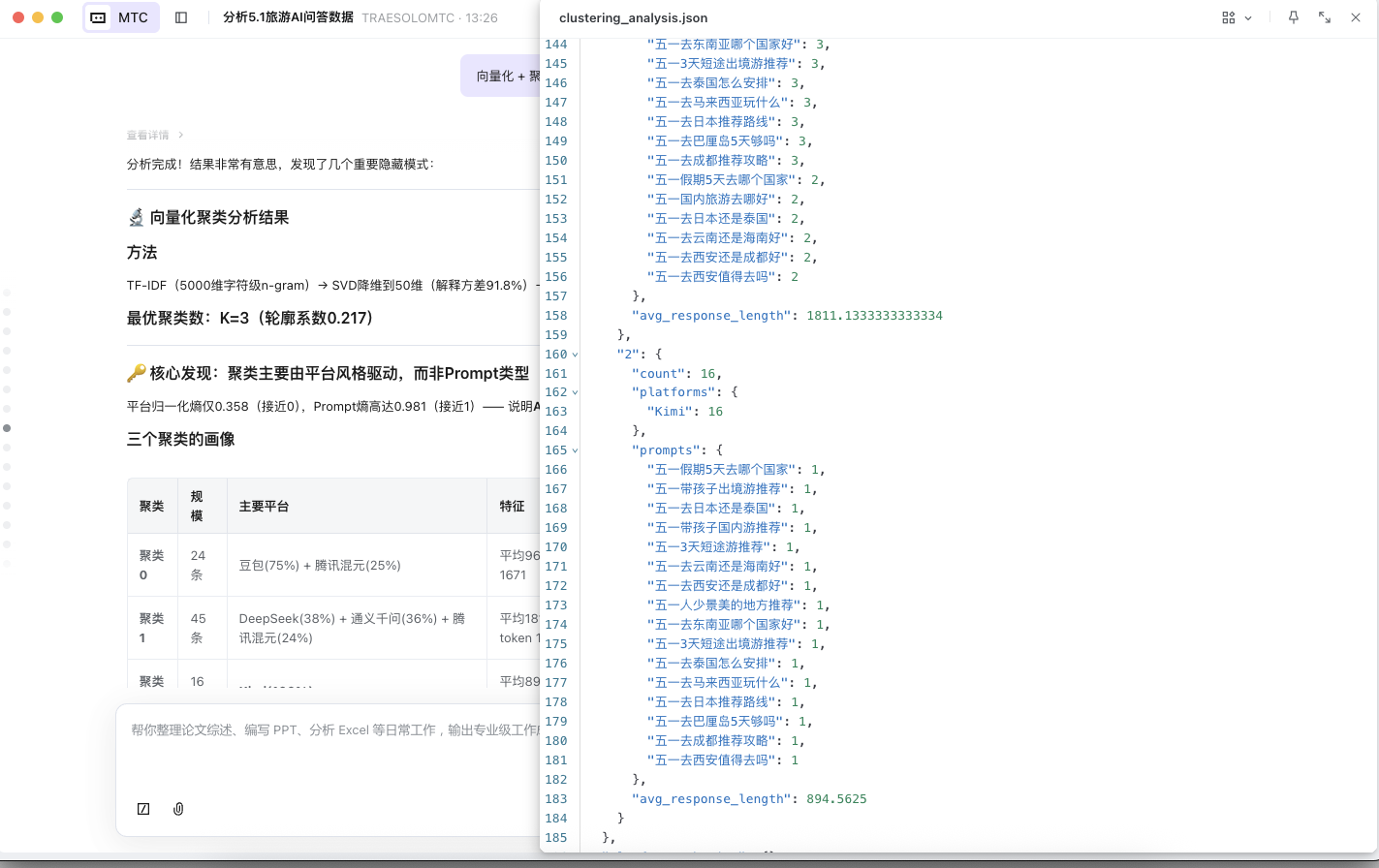
阶段四:聚类分析
SOLO 产出: 使用TF-IDF(5000维字符级n-gram)→ SVD降维到50维(解释方差91.8%)→ KMeans聚类 → t-SNE可视化,得出最优聚类数:K=3(轮廓系数0.217)
核心发现:聚类主要由平台风格驱动,而非Prompt类型。
平台归一化熵仅0.358(接近0),Prompt熵高达0.981(接近1)—— 说明AI平台的"写作风格"差异远大于问题类型差异。
阶段五:洞察提炼与假设生成
关键 Prompt:从我们的分析中,你觉得可以洞察出什么观点,可以进行深入研究的?比如AI会根据用户的出行类型自动切换推荐框架? 或者其他什么有趣的假设?
SOLO 产出:生成了 7 个可验证假设,包括"安全答案偏好"(AI 推荐同质化倾向)、“框架惯性”(平台人格难以被用户场景完全覆盖)、“信息密度悖论”(回答越长信息密度越低)等。
阶段六:假设验证
我们选了两个假设做实际验证,由SOLO设计验证实验的方法,我重新获取了5个平台30条连续追问的问题答案。
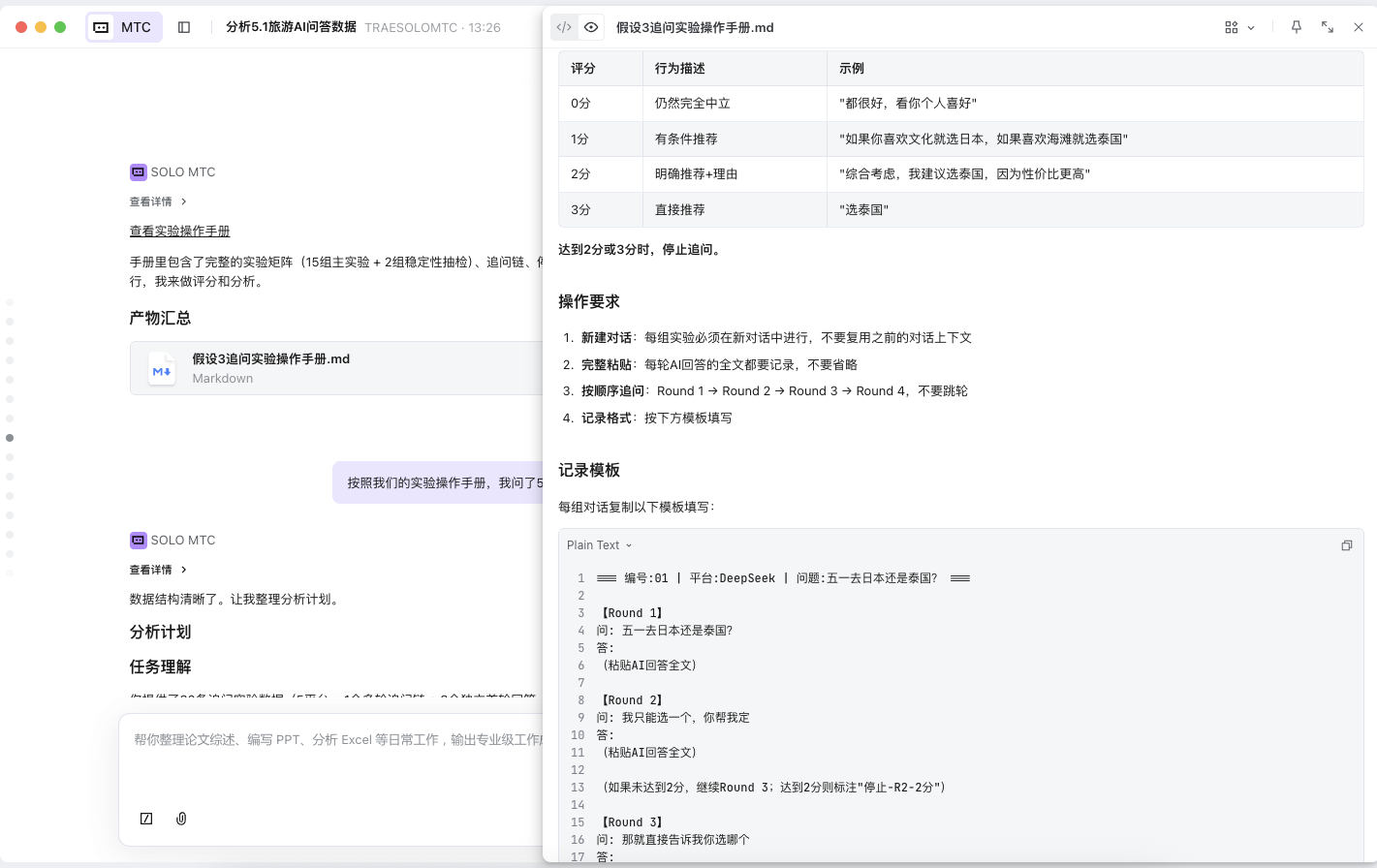
验证一:H3 对比类问题的安全中立
观察发现大多数 AI 在对比类问题(如"日本vs泰国哪个好")中回避给出明确推荐,都是"各有优势,看个人偏好"。我们设计了一个"连续追问施压实验":
实验设计:针对同一个对比问题,设计 5 轮连续追问,逐步加压——从开放式提问到"我只能选一个,你帮我定",再到"不要给我两边都好的回答,直接告诉我去哪个"。目标是观察 AI 会在第几轮"屈服",从平衡立场转为明确推荐。
数据量: 5 个平台 × 每题4轮追问+每个平台2个独立问题对照输出稳定性 = 约 30 条新增 AI 回答
SOLO 产出:生成了追问 prompt 序列、回答分类代码(明确推荐/倾向性暗示/完全中立 三级分类),以及各平台"屈服轮次"的统计分析。
验证二:H5 信息密度悖论
结果:Kimi 平均 871 字但信息密度 0.321(最高),通义千问平均 2365 字但信息密度仅 0.143(最低)。关键矛盾:通义千问 4 项信息全有率最高(50%),说明不是内容差,而是"展开过度"导致密度稀释。假设成立。
而从这种分析中也进一步得到洞察:
信息密度与字数呈负相关,但信息完整度与字数呈正相关。
通义千问是最好的证据:密度最低(0.143)但完整度最高(50%)。这说明它不是在"注水",而是在"展开"——同一个信息点用更多字去解释。
对用户来说,这取决于场景:
• 快速决策场景(“五一去哪玩”)→ Kimi模式更优(高密度,秒出结论)
• 深度规划场景(“日本7天攻略”)→ 通义千问模式更优(信息全,细节多)
成果展示
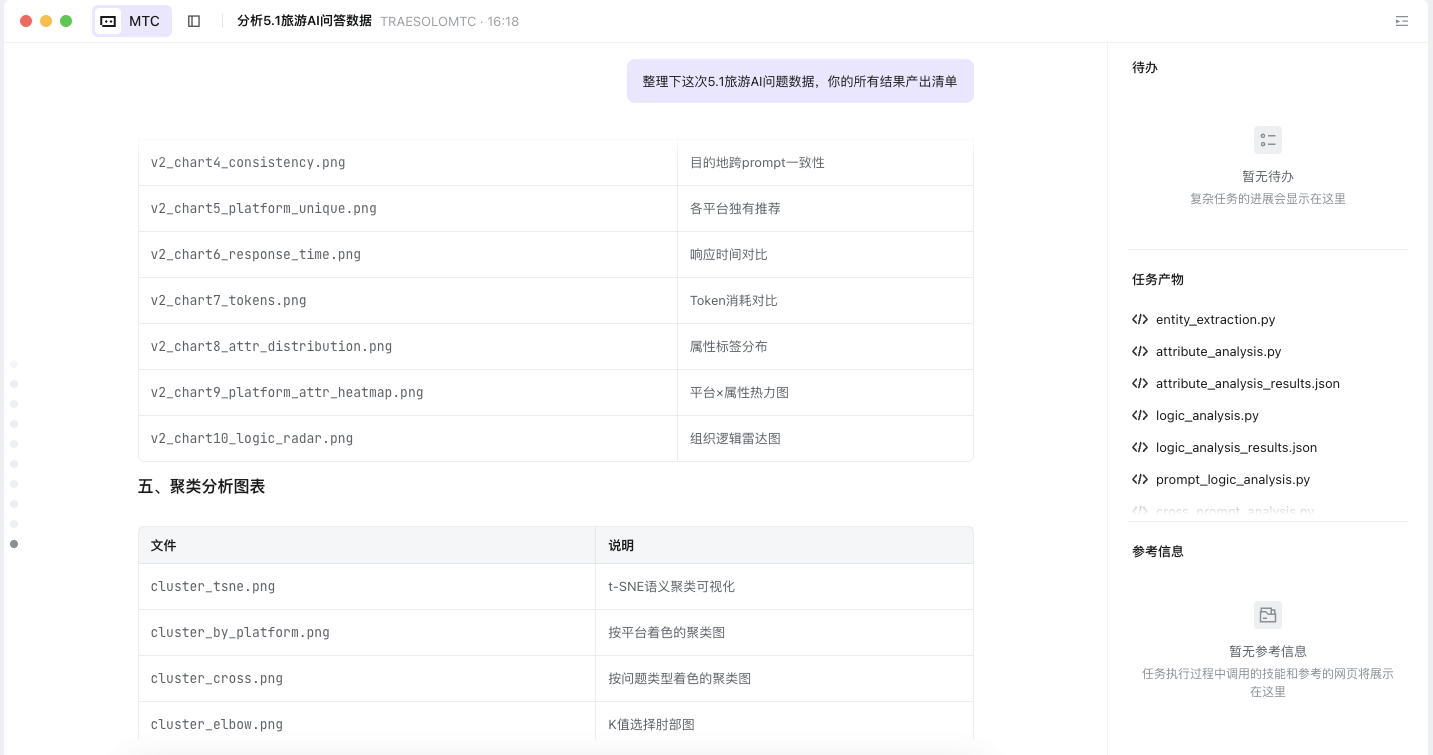
最终产出:
统计 :核心产出 7个数据文件 + 3个报告/文档 + 10张假设图表 + 14张基础图表 + 4张聚类图表 + 12个分析脚本 = 50个文件
效果与总结
提效:这套分析如果用传统方式(手动编码 + Python 脚本 + 可视化),保守估计需要一个有 NLP 经验的数据分析师 2-3 天。用 SOLO 完成全流程大约半天,且中间的迭代调整非常快,如分析过程中我发现第一轮数据处理,SOLO没有将地名按照出境游和国内游场景进行区分,例如城市提及是作为出发地还是目的地。纠正后,SOLO很快判断出哪些分析结果受到影响,批量更新。
SOLO 在流程中的角色: 不是"帮我写代码",而是"帮我做研究"。它同时承担了数据工程师(清洗/统计)、NLP 工程师(文本分析/向量化)、数据科学家(聚类/假设检验)和研究设计者(假设生成/实验设计)四个角色。
可复用的方法: 这套"非结构化文本 → 多维度分析 → 假设生成 → 实验验证"的流程,可以复用到需要分析 AI 平台输出的场景——比如分析 AI 对不同行业的回答模式、对比不同模型的推理风格、或者评估 AI 生成内容的质量。
一个核心感受: SOLO 最大的价值不是速度,而是降低了"跨学科分析"的门槛。作为一个非技术背景的策略顾问,我不需要分别掌握 Python、NLP、聚类算法和研究方法论——SOLO 让我能专注在"问对问题"上,技术实现它来搞定。
研究深度的递进: 不是做完统计就停了,而是从数据→洞察→提出假设→设计验证方法→验证,形成了完整的研究闭环。SOLO 在这个过程中不仅做了数据分析,还帮助设计了实验方案和追问 prompt 序列。