作为一名正在学习医疗数据标准FHIR的开发者,面对全英文、架构复杂的GitHub项目trifolia-on-fhir,我使用TRAE SOLO快速生成了结构清晰、内容完整的中文Code Wiki文档。这份文档让我迅速理解了项目全貌,解决了因技术门槛和语言障碍导致的学习效率低下问题。
1. 我的角色与挑战
我是一名对医疗信息化感兴趣的初级全栈开发者,近期开始学习国际医疗数据交换标准FHIR。为了深入理解,导师建议我研究一个真实的FHIR工具项目——trifolia-on-fhir。然而,我面临三重挑战:
-
技术门槛:该项目技术栈(Angular+NestJS)对我而言较新,目录结构复杂,难以快速把握核心。
-
启动障碍:尝试在本地运行项目时,一直被OAuth2登录模块卡住,无法进入系统实际操作。
-
语言障碍:项目文档和代码注释均为英文,使用机器翻译后技术术语变味,理解成本高。传统“克隆代码-通读README-盲目调试”的方式效率极低,让我一度想放弃。
2. 我的流程
我的核心目标是:在不深入代码细节的情况下,先快速建立对项目的整体认知。我使用TRAE SOLO将这个大任务拆解并自动化完成。
-
拆解任务:将“理解项目”拆解为:了解项目概述、梳理技术架构、弄清核心模块、理清依赖和运行方式。
-
使用的SOLO能力:主要利用了深度分析和结构化文档生成能力。
-
关键Prompt与操作过程:
-
输入信息:我将项目的GitHub仓库主页(链接1)和README等关键信息作为上下文提供给了SOLO。
-
下达核心指令:我向SOLO发出了明确的指令(这也是您提到的提示词):
“分析并理解这个项目仓库,生成结构化的完整的Code Wiki文档(md文件)。这套文档需要包括项目整体架构、主要模块职责、关键类与函数说明、依赖关系以及项目运行方式等关键信息。”
-
一键生成:SOLO在分析后,直接输出了一份非常专业的Markdown文档。
-
-
中间踩过的坑:
-
最初我的Prompt过于宽泛,如“介绍一下这个项目”,得到的是概括性描述,无法解决我的具体问题。
-
我意识到必须让AI扮演特定角色(如技术文档工程师)并给出非常具体的结构要求,才能得到可直接使用的产出。调整后的Prompt(即上面的核心指令)立竿见影。
-
3. 我的最终产出
SOLO生成的文档完全满足了我的需求,它就是我本次学习的“地图”。文档内容就是您提供的【文档内容】,它包含以下核心部分:
-
项目概述:快速让我知道这是一个用于管理FHIR资源的专业工具。
-
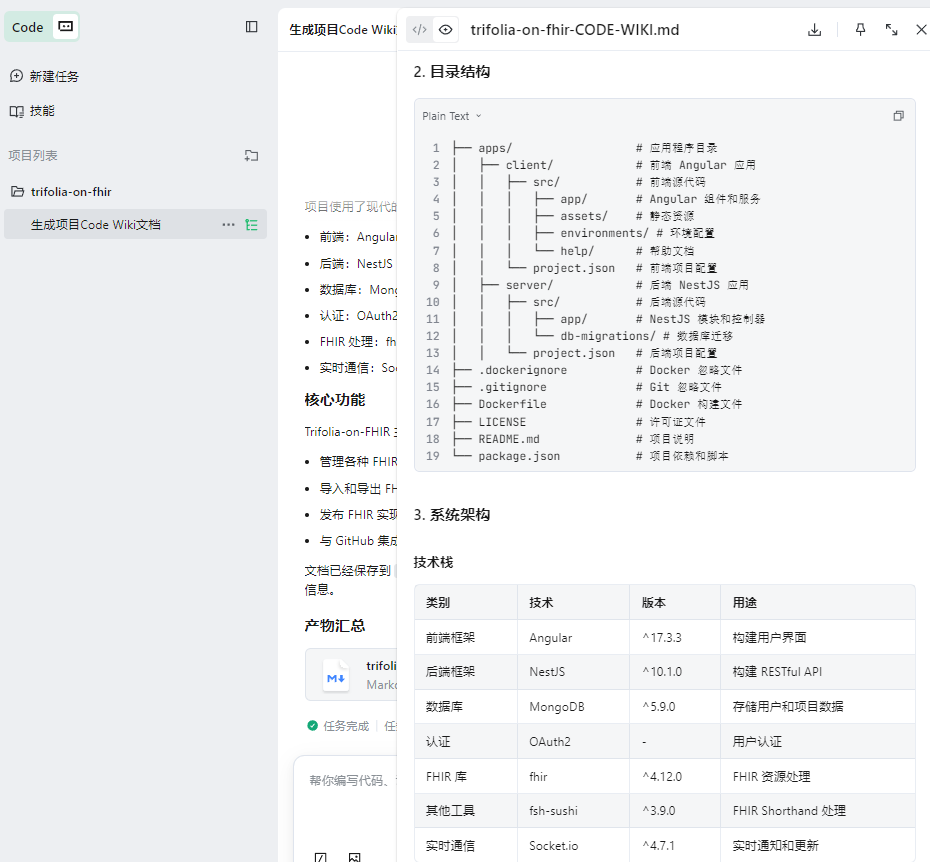
目录结构与技术栈:一目了然地看到前后端如何组织,用了什么技术(下图展示了技术栈表格的部分内容)。
-
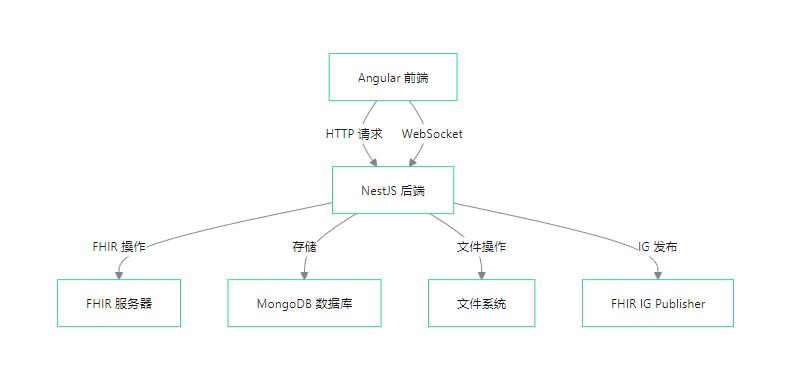
系统架构图:通过Mermaid流程图,清晰展现了前端、后端、数据库、FHIR服务器之间的数据流。(这个之前一直没有这个概念)
-
核心模块与API说明:详细列出了前端和后端分别负责什么,有哪些关键API接口,让我知道如果要二次开发该从何入手。
-
详细的运行与配置指南:包括环境要求、构建命令、以及如何配置NGINX解决我最初遇到的WebSocket问题。
4. 我的心得
-
效能提升:传统方式下,要整理出这样一份详尽的Wiki,我需要花费数小时甚至一天的时间阅读代码、查阅资料、归纳总结。而借助SOLO,整个过程不超过10分钟,我就获得了一份可以直接用于团队分享和后续开发参考的高质量文档。
-
SOLO在流程中的作用:SOLO在此次任务中扮演了 **“超级外脑”和“高效协作者”** 的角色。它替代了我需要进行的“信息收集-阅读理解-归纳重组-格式输出”的全链条工作,让我能直接聚焦于“提出正确问题”和“使用最终成果”。
-
可复用的方法:对于学习任何开源项目或复杂技术,这个模式可以复用:“明确学习目标 → 将目标拆解为具体的信息需求点 → 用精确的Prompt指导AI生成结构化文档 → 基于文档进行针对性实践”。这改变了“先埋头苦读,再抬头看路”的低效模式,转变为“先让AI画地图,再按图索骥”的高效模式。