1. 摘要
我用 TRAE SOLO 从零搭建了一套 RAG 智能知识库系统——上传 PDF 学习资料就能自动解析、分块、生成子问题和摘要,支持向量检索 + 全文检索混合召回 + Rerank 精排。原本预估 2-3 周的工作量,3 天搞定,代码已开源。
2. 背景
我是一名大学生,日常最大的痛苦就是——资料太多,笔记太散,想找的时候永远找不到。各门课的课件、PDF 论文、网上收藏的学习笔记散落在各个文件夹里,每次复习都要翻半天。
市面上有现成的知识库方案,但我有两个想法:一是想借这个项目系统学习 RAG 技术,从向量数据库到检索链路搞懂整个原理;二是觉得用 AI Coding 来"为爱发电",自己从零搭一个,比直接用别人的产品有意思多了。于是决定用 SOLO 来干这件事。
3. 实践过程
3.1 我是怎么拆解任务的
我没有一上来就让 SOLO “帮我写一个 RAG 系统”,而是用 /plan 先把项目拆成了 5 个阶段,每个阶段独立验证后再推进:
| 阶段 | 目标 | 怎么验证 |
|---|---|---|
| ① 架构设计 | 确定技术栈和项目结构 | SOLO 输出项目骨架,我确认 OK |
| ② 文档处理管线 | PDF → 分块 → 子问题/摘要 | 上传 PDF 能正确输出 Chunk |
| ③ 向量存储与检索 | Milvus + ES 双路索引 | API 能检索到相关内容 |
| ④ 混合检索 + Rerank | RRF 融合 + 精排 | 混合检索结果明显优于单路 |
| ⑤ 前端界面 | 知识库管理 + 搜索交互 | 完整可用的 Web 界面 |
3.2 技术栈(SOLO 帮我选的)
后端 FastAPI + Milvus(向量库)+ Elasticsearch(全文检索)+ PostgreSQL + LangChain前端原生 HTML/CSS/JS,轻量无框架依赖
3.3 核心:文档处理管线
这是整个系统最核心的部分。
PDF 解析方案怎么选的?
一开始我不知道用什么工具把 PDF 转成 Markdown,于是直接问 SOLO:"市面上有哪些免费的开源项目可以把 PDF 解析成 Markdown?"SOLO 给我列了几个方案,我对比后选择了 MinerU——免费、效果好、支持复杂排版。
分块策略的进化过程:
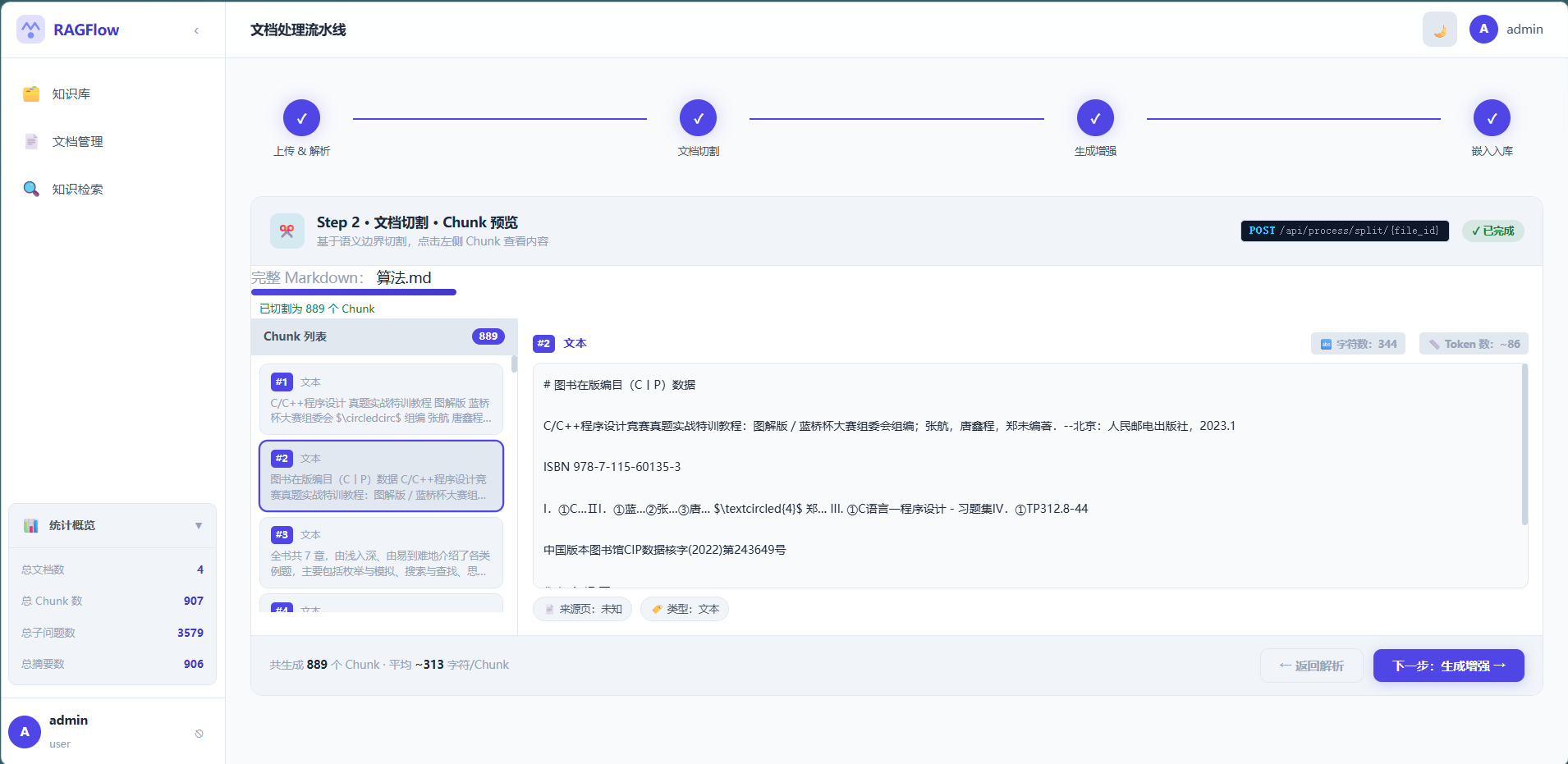
分块这块走了个"迭代优化"的路子:
- 第一版:滑动窗口切割 — 最基础的方案,按固定字数切,简单但经常把一个完整知识点切成两半
- 第二版:我引导 SOLO 用 LangChain 标题切块 — 我了解到 LangChain 有按 Markdown 标题层级切分的功能,就让 SOLO 去用。效果明显好很多,至少不会把一个章节拆散了
- 第三版:继续追问 SOLO 优化 — 我又问 SOLO:"有没有更专业、更企业化的分块方案?"SOLO 在此基础上加了短文本自动合并(<100 字)、长文本递归切割(>800 字)、overlap 控制,最终形成了一套智能分块策略
经验:不要满足于第一版方案,多追问 SOLO “有没有更好的/更专业的做法”,往往能迭代出更优解
SOLO 最终给出的处理流程:
PDF 上传 → MinerU 解析为 Markdown → 智能分块 → LLM 生成子问题和摘要 → 向量化 → 存储
几个我觉得 SOLO 处理得很好的细节:
- 智能分块:识别 Markdown 的
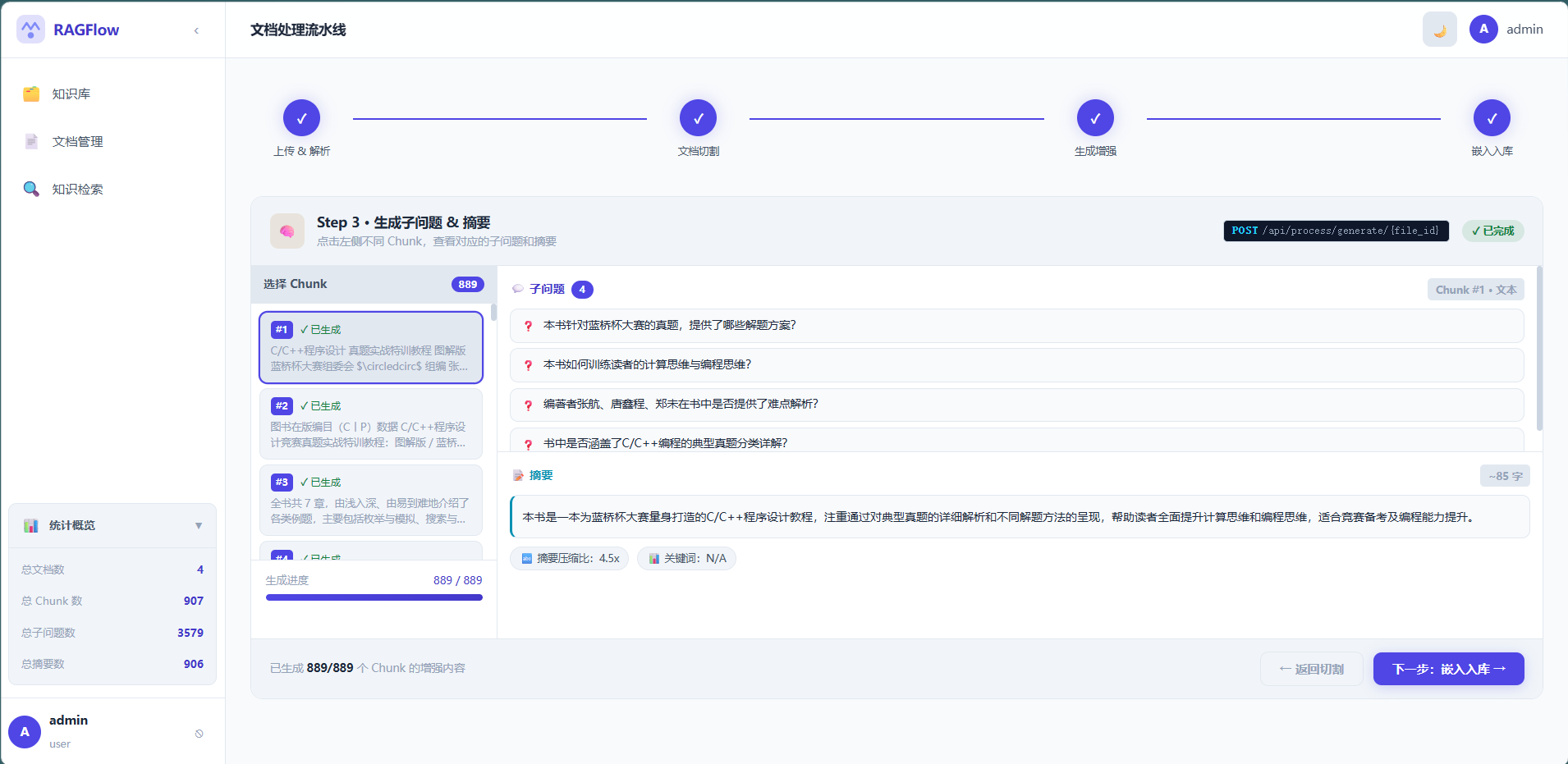
###标题来切分,短于 100 字的自动合并,长于 800 字的递归切割,粒度控制在 400 字左右 - 子问题增强:为每个文档块生成"人们可能会怎么问这个问题",存入向量库后大幅提升语义匹配覆盖面
- 并发优化:用
asyncio.Semaphore控制并发,Embedding 采用双层批处理,几十页的 PDF 几分钟搞定
3.4 前端开发(非前端选手也能搞定)
我不太擅长前端,但用 SOLO 也顺利搞定了,分享几个技巧:
- 先理清后端接口,再让 SOLO 生成前端:我把 API 接口文档贴给 SOLO,让它根据接口自动生成页面
- 用"视觉语言"描述问题:不懂 CSS 没关系,直接说人话:
“overflow 属性怎么设?”→ “给右侧内容区加个滚动条,固定页面高度”
“给右侧内容区加个滚动条,固定页面高度”- “点击按钮后内容应该立刻显示,不要多次点击才行”
- 截图直接问 SOLO:“这个在前端叫什么?”
- 高级模型做前端效果更好:GLM-5.1 等模型生成的前端样式质量明显更高
3.5 前后端联调(最容易忽略但最关键的环节)
后端和前端分别开发完之后,联调才是真正发现问题的时候。这一步我踩了不少坑,分享一些经验:
- 先搞清楚后端返回了什么数据:用浏览器或 Postman 调一下 API,看看返回的 JSON 结构、字段名是什么
- 前端需求的字段 vs 后端返回的字段:这是联调最常见的问题——前端想展示"文档标题",但后端返回的字段叫
doc_name而不是title;或者前端需要某个字段,后端根本没返回。一定要逐个字段对齐 - 遇到问题解决问题,别慌:联调过程中会发现一大堆小问题,一个一个修就行。SOLO 官网好像有测试相关的 Agent 可以添加(虽然我没试过),也可以直接问 SOLO 怎么调试
- 后端测试一般没什么问题,重点在前端对数据的处理——拿到后端数据后怎么渲染、怎么处理异常情况
3.6 踩过的坑
| 坑 | 解决方式 |
|---|---|
| Milvus 连接失败 | localhost 解析为 IPv6,改用 127.0.0.1 |
| Embedding 批量超时 | 改用分层批处理 |
| LLM 生成的 JSON 偶尔格式错误 | SOLO 建议加了 OutputFixingParser 自动修复 |
| Chunk 展示问题卡了 3 个模型 | DeepSeek-V3.2、GLM-5.1、MiniMax-2.7 都没解决,最后 Kimi 2.5 搞定了 |
| 前后端字段对不上 | 联调时逐个字段比对,让 SOLO 统一命名 |
3.7 项目结构(适时重构很重要)
随着项目迭代,有些文件越来越臃肿。我适时让 SOLO 做了重构——比如把 app.py 里的所有路由拆分到 api/ 目录下的 7 个独立模块。保持结构清晰,SOLO 后续修改也更精准。
rag-for-qw/
├── backend/
│ ├── api/ # 7 个独立 API 模块
│ ├── services/ # 核心服务(reranker、milvus_client 等)
│ ├── app.py # 应用入口(精简后)
│ └── config.py
├── frontend/
│ ├── css/ js/pages/ # 页面模块
│ └── index.html
└── README.md
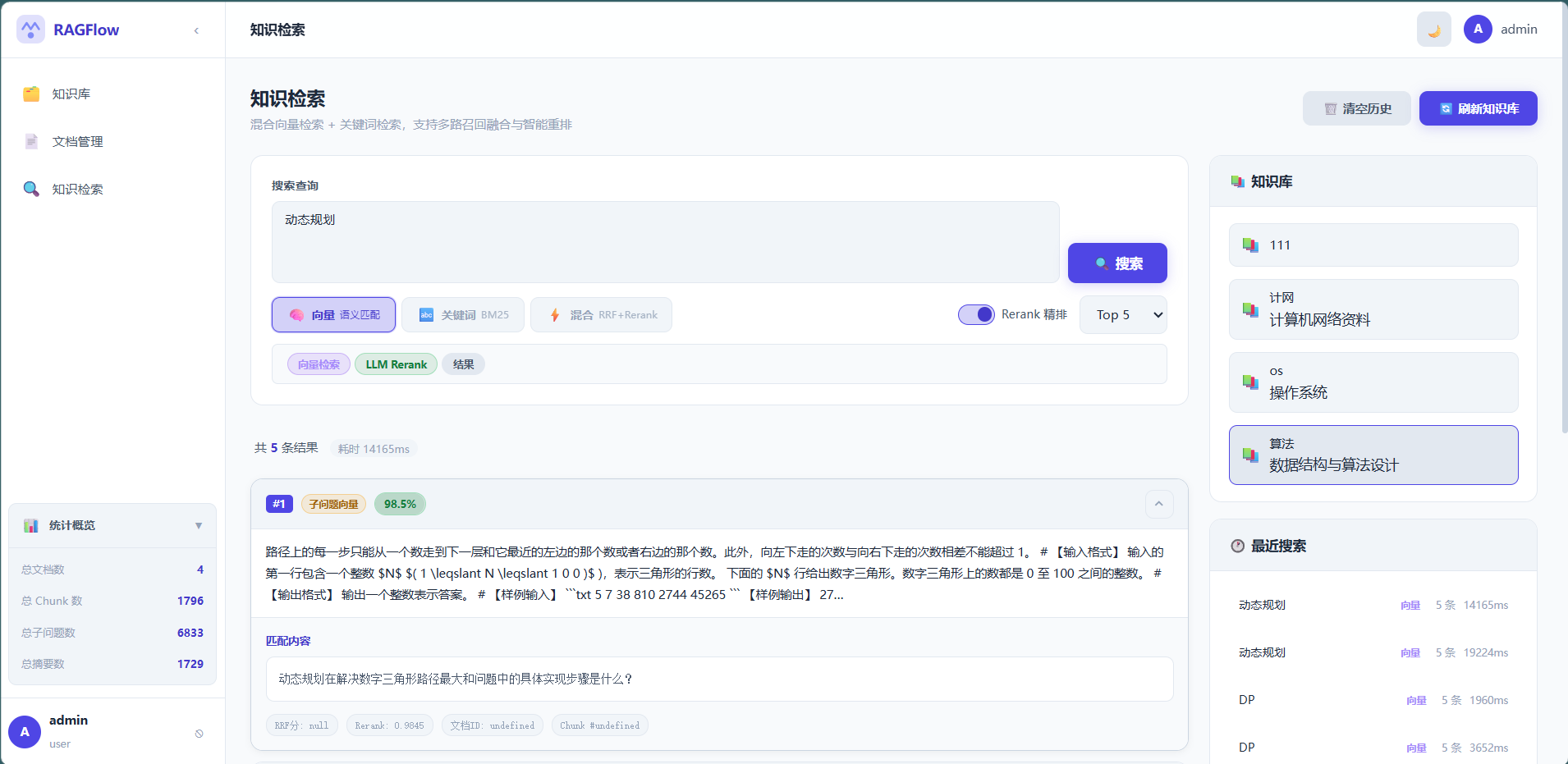
4. 成果展示
![]() GitHub 开源:https://github.com/jerry-166/rag-for-qw
GitHub 开源:https://github.com/jerry-166/rag-for-qw
核心功能一览
| 功能 | 说明 |
|---|---|
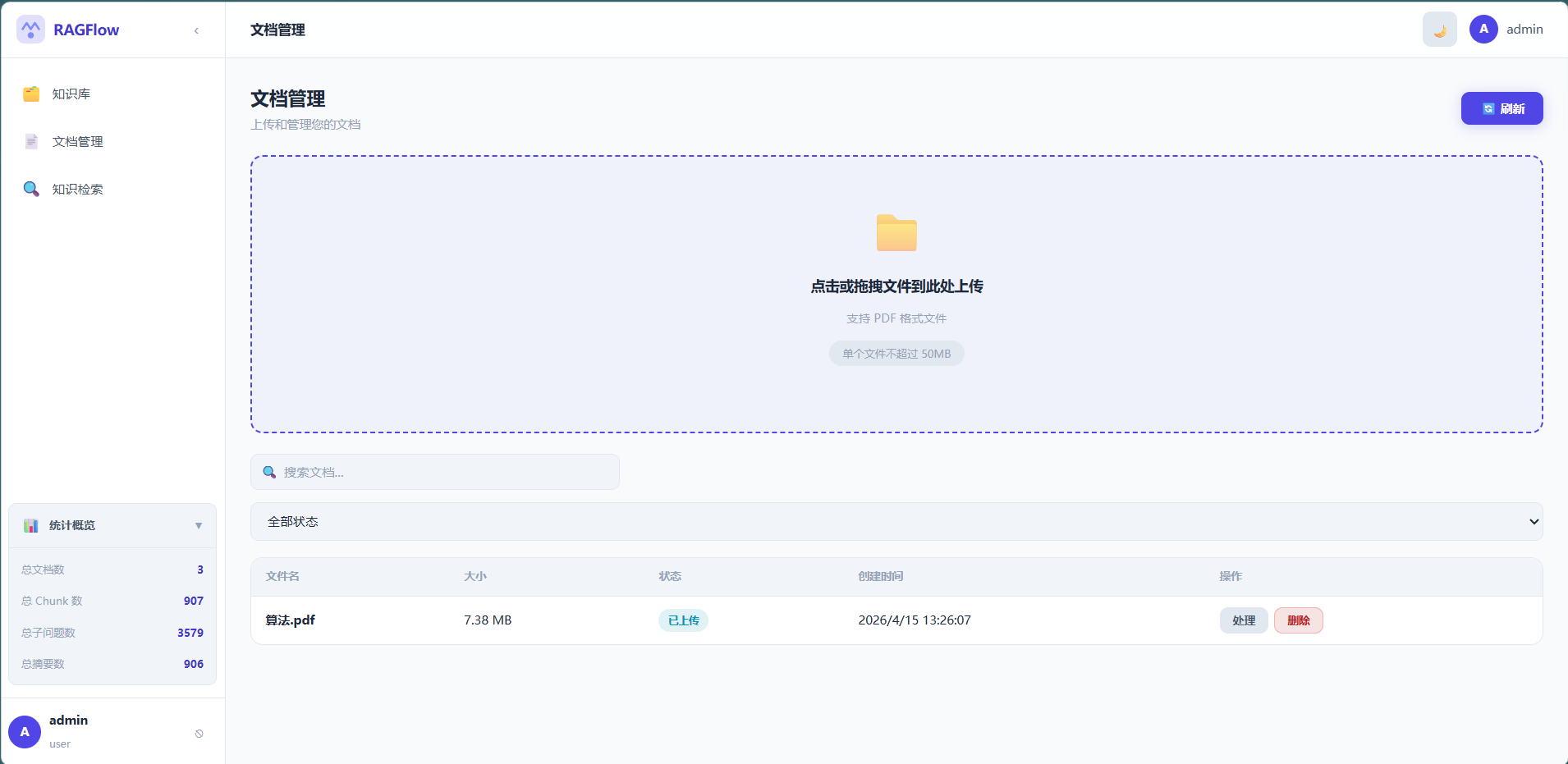
| 知识库管理 | 创建/编辑/删除,文档分类存储 |
| PDF 全流程处理 | 上传 → 解析 → 分块 → 子问题/摘要 → 向量化,全自动 |
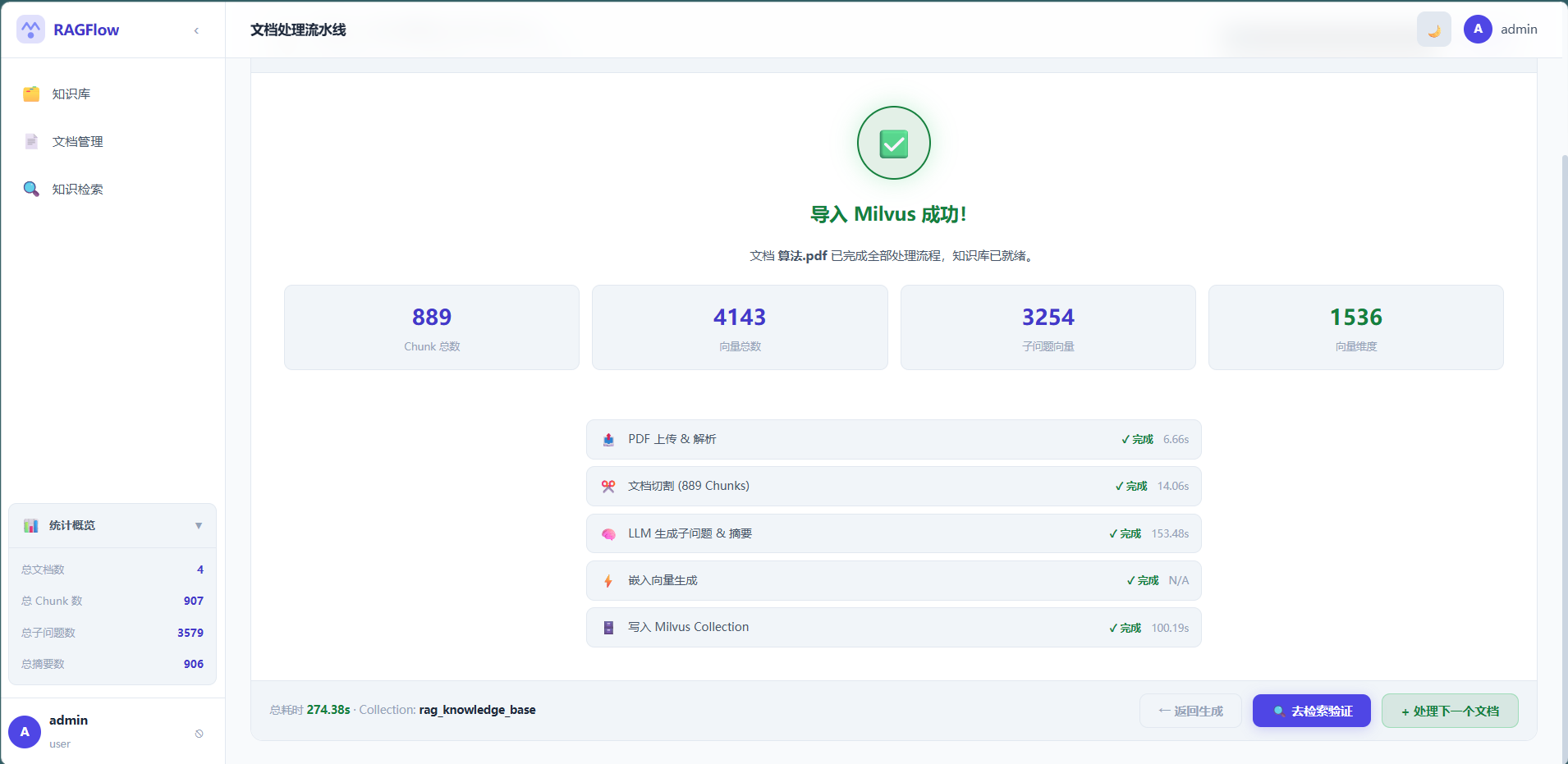
| 三种检索模式 | 纯向量 / 纯全文 / 混合检索(推荐) |
| Rerank 精排 | Cross-Encoder / LLM 策略一键切换 |
| 响应式前端 | 暗色模式、移动端适配 |

5. 效果与总结
提效数据
| 对比项 | 传统方式 | 用 SOLO 后 |
|---|---|---|
| 项目搭建周期 | 2-3 周 | 3-4 天 |
| 核心模块 | — | 7 个 Service + 7 个 API |
| 检索精度 | 仅关键词 | 混合检索 + Rerank,显著提升 |
SOLO 在流程中做了什么
SOLO 参与了每一个环节:选型推荐(MinerU)→ 架构设计 → 核心代码 → 问题排查 → 架构优化 → 前端页面 → 联调修复 → 文档撰写。特别是 /plan 搭骨架、/spec 做审查这个组合,形成了"规划 → 实现 → 审查"的闭环,非常高效。
几条可复用的经验
/plan开头,/spec收尾 — 形成规划-实现-审查闭环- 拆阶段推进,不要一口吃成胖子 — 每次聚焦一个模块,独立验证
- 别满足于第一版,多追问"有没有更好的方案" — 分块策略从滑动窗口迭代到智能分块,就是不断追问的结果
- 卡住了换模型问 — 不同模型擅长领域不同,别死磕
- 前端不懂没关系,说人话就行 — 用视觉感受描述,SOLO 能理解
- 联调是必经之路 — 前后端字段对齐是重点,遇到问题解决问题,慢慢就跑起来了
- 适时重构 — 文件膨胀了就拆,结构清晰对 SOLO 和自己都友好
项目地址:https://github.com/jerry-166/rag-for-qw欢迎大家 Star
交流讨论!