一、摘要
我们通过 TRAE SOLO 开发了一套excel自动匹配脚本,将原本需要 3 个工作日的手工检索工作压缩至约 10 分钟,自动匹配成功率达到人工最优水平的 84.2%。整个过程中,SOLO 不仅帮助我快速完成了代码编写,更重要的是通过多轮对话不断迭代优化了匹配策略,从 V1.0 到 V1.4 经历了 5 次版本迭代,匹配成功数从基础版本持续提升至 1,716 行。
二、背景
在日常工作中,我需要将实际清单excel中的信息与标准清单excel进行逐行比对匹配,确认每项数据对应的标准编码、名称及规格描述。
实际清单及标准清单样式
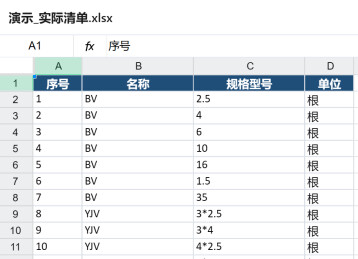
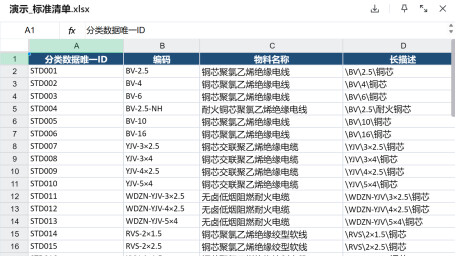
这是一项典型的重复性劳动:
• 单次任务通常涉及 2,000~3,000 行数据,每行都需手动搜索、比对、确认
• 处理 2,769 行数据需要 3 个工作日,剩余未匹配项还需额外 1 天
• 长时间重复操作导致疑劳度下降,匹配准确率难以保证
我希望用 TRAE SOLO 来自动化这个过程,释放人力去处理更有价值的工作。
三、实践过程
3.1 任务拆解
我将整个任务拆解为 4 个步骤:
• 数据预处理:将实际清单的名称、规格字段转换为可检索的格式
• 严格匹配:用转换后的关键词在标准清单中进行两级筛选
• 宽松匹配:对未匹配项用简化格式再次检索
• 结果输出:将匹配结果写回 Excel,保存前 3 条候选
我没有一次性把所有需求告诉 SOLO,而是分步描述,让它先理解核心逻辑,再逐步优化。这种“先跑通、再优化”的策略非常关键。
3.2 使用的 SOLO 能力
• 代码生成:根据自然语言描述生成 Python 脚本,包含 pandas 数据处理和 openpyxl 文件操作
• 增量修改:每次提出新需求时,SOLO 能精准定位到需要修改的函数和行,而不是重写整个脚本
• 错误诊断:我把运行报错信息贴给 SOLO,它能快速定位问题并给出修复方案
• 文档生成:最终用 SOLO 生成了完整的成果总结报告(Word 格式)
3.3 关键 Prompt 与迭代过程
以下是我与 SOLO 交互的关键节点:
【第一轮】初始需求描述
“我需要写一个处理excel表格的脚本。主要功能是根据实际清单(表A)中的内容,去标准清单(表B)中匹配,并找到对应的项…”
→ SOLO 生成了完整的基础版本,包含列转换和单轮匹配逻辑。
【第二轮】解决复合规格问题
“列C的数字处理规则要改变一下,如果列C内容只有数字就转换成\1×数字m,如果内容中有字符如7*1.5,就改成\7×1.5m”
→ SOLO 精准修改了 convert_col_f 函数,支持乘号自动替换。
【第三轮】启用两轮匹配
“在现在脚本的基础上再增加一条规则。转换时新增一个G列,匹配后的结果改为HIJ三列保存…”
→ 新增 G 列和第二轮匹配,第二轮补充匹配了 45 行。
【第四轮】修复运行错误
“报错了:SyntaxWarning: invalid escape sequence ‘\B’ … IndexError: iloc cannot enlarge its target object”
→ SOLO 快速定位了两个问题:文档字符串转义和列索引越界,一次性修复。
【第五轮】优化 G 列策略 + 多候选输出
“修改数据预处理中G列的转换逻辑,把G的数据来源改为F列…”
“在第一轮检索的时候,需要保存前三条命中的编码…”
→ G 列改为基于 F 列调整数字顺序,第二轮匹配从 45 行提升到 62 行;输出前 3 条候选结果。
3.4 踩过的坑
• 初始需求描述不够精确:第一次提问时没有明确列的对应关系,导致生成的脚本无法直接运行。教训:提前确认表结构和列映射关系。
• 全角半角字符不一致:实际数据中存在全角括号()和半角括号()混用的情况,导致部分匹配失败。教训:数据预处理时要统一字符格式。
• pandas 列操作边界情况:iloc 不能向不存在的列写入数据,需要先创建列再赋值。教训:处理动态列时要注意边界检查。
四、成果展示
• Python 自动匹配脚本(match_items.py):包含完整的数据预处理、两轮匹配、多候选输出逻辑
• 成果总结报告(Word 格式):包含背景、技术方案、迭代记录、价值总结
• Dify 节点版本:已适配 Dify 平台的代码节点调用格式
五、效果与总结
5.1 提效数据
• 匹配时间:从 3 天压缩至约 10 分钟,效率提升约 400 倍
• 匹配覆盖:自动匹配 1,716 行,达到人工最优水平的 84.2%
• 人力释放:物资人员可以将精力集中在未匹配的差异数据处理上
5.2 SOLO 在我的工作流中做了什么
SOLO 不仅是一个代码生成工具,更像是一个可以持续对话的技术合作伙伴。在整个过程中,它承担了以下角色:
• 需求理解与明确:当我的描述不够清晰时,SOLO 会主动提问确认关键细节
• 代码实现:快速生成可运行的完整脚本,而不是片段
• 增量迭代:每次修改都基于上一版本,不会破坏已有逻辑
• 错误诊断:贴入报错信息后能快速定位并修复
• 文档生成:自动生成专业的成果报告
5.3 可复用的方法
通过这次实践,我总结出以下可复用的工作方法:
• “先跑通,再优化”:不要一次性描述所有需求,先让 AI 实现基础版本,用实际数据测试后再逐步优化
• “数据驱动迭代”:每次优化都基于实际运行结果的分析,而不是凭空想象
• “梯度匹配策略”:对于数据匹配类任务,先严格后宽松的多轮策略可以显著提升覆盖率
• “多候选输出”:输出多个候选结果而非唯一结果,可以大幅提高人工审核效率