github 主页面:
基于微内核架构(EventBus + DI + BaseTool),支持任意 OpenAI 兼容 API
核心设计:决策环(Control Loop)驱动的自学习 Agent,通过贝叶斯 Bandit 实现自适应决策优化。
| 特性 | 说明 |
|---|---|
| Agent 运行时自感知 | 实时感知运行状态(进度、停滞、循环、饱和度),动态调整决策 |
| 决策环架构 | 每轮决策 - 执行 - 反馈 - 学习的闭环控制 |
| 自学习系统 | 基于贝叶斯 Bandit 的 Action 选择,持续优化决策策略 |
| 三层记忆系统 | 人格记忆 + 会话记忆 + 长期记忆(FTS5全文检索 + 96维LSH向量混合召回) |
| 启发式决策引擎 | 规则提取特征 + Bandit 做 tie-break,兼顾可解释性与学习能力 |
| 工具使用控制 | 动态禁止/推荐工具切换,避免重复调用同一工具陷入循环 |
| 组件热插拔 | app/components/ 下文件 3 秒自动加载生效 |
| 事件驱动架构 | 基于 EventBus 的发布-订阅模式,组件松耦合 |
| Flash 模式 | 跳过记忆注入,加速简单任务 |
| 多通道接入 | 支持 QQ 等外部平台(目前只支持qqbot),通过 ChannelManager 统一管理消息路由、文件传输与注入 |
决策环(Control Loop)工作流程
每轮循环包含 5 个阶段:
-
特征提取(Feature Extraction)
- 启发式引擎提取当前状态特征
- 包括:停滞迭代数、进展趋势、重复分数、上下文饱和度等
-
规则评估(Rule Evaluation)
- 硬规则给出 action 候选集合
- 例如:检测到循环时候选 [redirect, compress]
-
Bandit Tie-break(Action 选择)
- 当候选 action 多于 1 个时,Bandit 介入
- 使用 Thompson Sampling + Heuristic Bias 选择最优 action
-
执行与反馈(Execute & Feedback)
- 执行选中的 action(continue/retry/redirect/compress/terminate)
- FeedbackEvaluator 分段式评估本轮表现
-
学习与更新(Learning & Update)
- 使用 n-step return 累积 reward
- 更新 Bandit 的 Beta 分布参数
- 定期衰减旧数据防止过拟合
自学习机制
Policy - Bandit - Action 三层架构:
┌─────────────────────────────────────────┐
│ Policy Templates │
│ ┌─────────┬───────────┬─────────────┐ │
│ │ default │ efficient │ aggressive │ │
│ │ 平衡策略 │ 高效策略 │ 激进策略 │ │
│ │(stuck=3)│ (stuck=2) │ (stuck=5) │ │
│ └────┬────┴─────┬─────┴──────┬──────┘ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌─────────────────────────────────┐ │
│ │ Bayesian Bandit │ │
│ │ Thompson Sampling 选择最优 Policy │ │
│ │ - 从 Beta 分布采样 │ │
│ │ - 选择期望收益最高的 Policy │ │
│ └─────────────┬───────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────┐ │
│ │ Action Bandit │ │
│ │ 在候选 action 内做 tie-break │ │
│ │ - Heuristic 提供 bias │ │
│ │ - 动态调整阈值参数 │ │
│ └─────────────────────────────────┘ │
└─────────────────────────────────────────┘
学习过程:
- Policy 选择:会话开始时,Bayesian Bandit 从多个 Policy(default/efficient/aggressive)中选择当前最优策略
- 阈值注入:选中的 Policy 参数(如 stuck_iterations=3)注入 HeuristicEngine 和 ActionBandit
- Action 学习:每轮结束后,根据 FeedbackEvaluator 的评分更新 Action 的 Beta 分布
- n-step return:累积最近 n 轮的 reward,支持延迟反馈和序列优化
- 数据衰减:每 50 个会话衰减一次旧数据(衰减因子 0.99),防止过拟合
反馈评估(Feedback Evaluation)
采用分段式设计,先区分成功/失败,再优化细节:
-
成功分支:基础分 1.0,扣除效率和成本
- 迭代惩罚:迭代越少分越高
- Token 惩罚:超出阈值扣分
- 顺畅度奖励:无停滞加分
-
失败分支:基础分 0.0,根据停滞程度扣分
- 停滞迭代越多扣分越多
- 错误类型影响扣分幅度
Agent 运行时自状态感知
Agent 通过 FeatureExtractor 实时感知运行状态,动态调整决策策略:
| 状态维度 | 特征 | 说明 |
|---|---|---|
| 进度状态 | progress_score | 任务完成进度估计 (0-1) |
| stuck_iterations | 连续无进展迭代次数 | |
| is_making_progress | 是否在取得进展 | |
| 趋势状态 | progress_trend | EMA 平滑后的进展趋势 (-1 到 1) |
| convergence_rate | 收敛速度 | |
| is_plateau | 是否进入平台期 | |
| 工具状态 | unique_tools_used | 使用过的不同工具数 |
| tool_diversity_score | 工具多样性分数 | |
| repetition_score | 工具重复调用分数 | |
| pattern_detected | 检测到的循环模式 | |
| 上下文状态 | context_saturation | 上下文饱和度 (0-1) |
| context_saturation_level | 饱和等级: idle/normal/warn/redirect/stop | |
| 结果质量 | error_rate | 工具调用错误率 |
| empty_result_rate | 空结果率 | |
| result_quality_score | 结果质量综合分数 | |
| 输出状态 | exact_repetition_count | LLM 输出完全重复次数 |
| is_output_loop | 是否陷入输出循环 |
自适应调整机制:
-
进展停滞检测:stuck_iterations > threshold 时触发 redirect/retry
-
上下文压力感知:saturation > 0.7 时触发 compress,> 0.95 时触发 stop
-
工具循环检测:repetition_score > 0.5 时触发 redirect 换工具
-
输出循环检测:exact_repetition_count >= 5 时强制 terminate
-
动态 HardConstraint:根据状态实时生成控制指令(如 REDIRECT/COMPRESS/RETRY)
设置介绍
1. 模型设置
功能说明
配置与大型语言模型(LLM)的连接参数,支持多模型管理和快速切换。
配置项详解
当前使用模型
-
作用:选择当前激活的模型配置
-
说明:从已添加的模型列表中选择一个作为默认模型
流式输出
-
作用:控制是否启用 SSE 流式响应
-
开启:实时接收模型生成的内容
-
关闭:等待完整响应后一次性返回

2. Agent 行为
功能说明
控制 Agent 执行任务的策略和行为模式。
Flash 模式说明
-
开启:不注入历史上下文到提示词,适合单次问答场景
-
关闭:正常注入上下文,保持对话连贯性
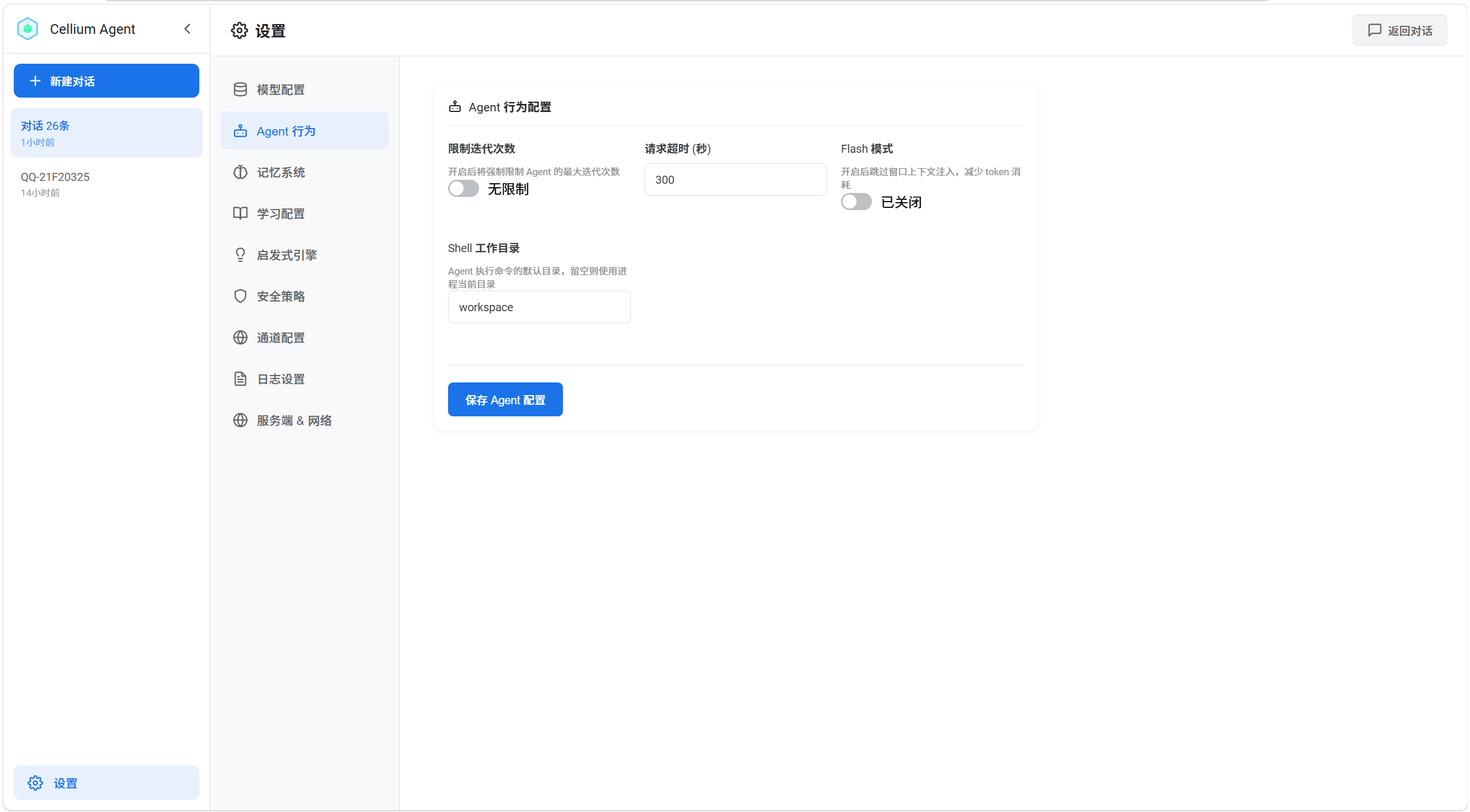
3. 记忆系统
功能说明
配置 Agent 的记忆存储和召回机制,包括短期记忆和长期记忆。
3.1 短期记忆(对话上下文)
| 配置项 | 说明 | 默认值 |
|---|---|---|
| 最大消息数 | 保留的最大对话消息数量 | 50 |
| 自动压缩阈值 | 超过此字节数自动压缩工具结果 | 10000 |
| 保留工具结果数 | 保留最近 N 次完整工具结果 | 10 |
| 结果截断长度 | 过期结果截断后的字符长度 | 500 |
3.2 会话笔记压缩
当对话 Token 数或工具调用次数达到阈值时,自动将历史对话压缩为结构化笔记。
| 配置项 | 说明 | 默认值 |
|---|---|---|
| Token 阈值 | 超过此 Token 数触发压缩 | 2000 |
| 工具调用阈值 | 达到此次数触发压缩 | 3 |
| 保留最近消息数 | 保留最近 N 条原文消息 | 10 |
| 笔记最大长度 | 生成笔记的最大字符长度 | 2000 |
3.3 长期记忆(混合召回)
| 配置项 | 说明 | 默认值 |
|---|---|---|
| 索引数据库路径 | 记忆索引的存储位置 | memory/memory_index.db |
| 记忆存储目录 | 记忆文件的根目录 | memory |
| Hybrid Recall | 启用 FTS5 + Embedding 混合召回 | 开启 |
| Embedding 维度 | 向量嵌入的维度 | 96 |
| 默认 Schema | 记忆的默认分类模式 | general |
| 允许存储敏感信息 | 是否允许存储敏感数据 | 关闭 |
记忆管理面板
设置页面集成了记忆管理功能,可以:
-
查看已存储的记忆条目
-
搜索和检索历史记忆
-
编辑或删除特定记忆
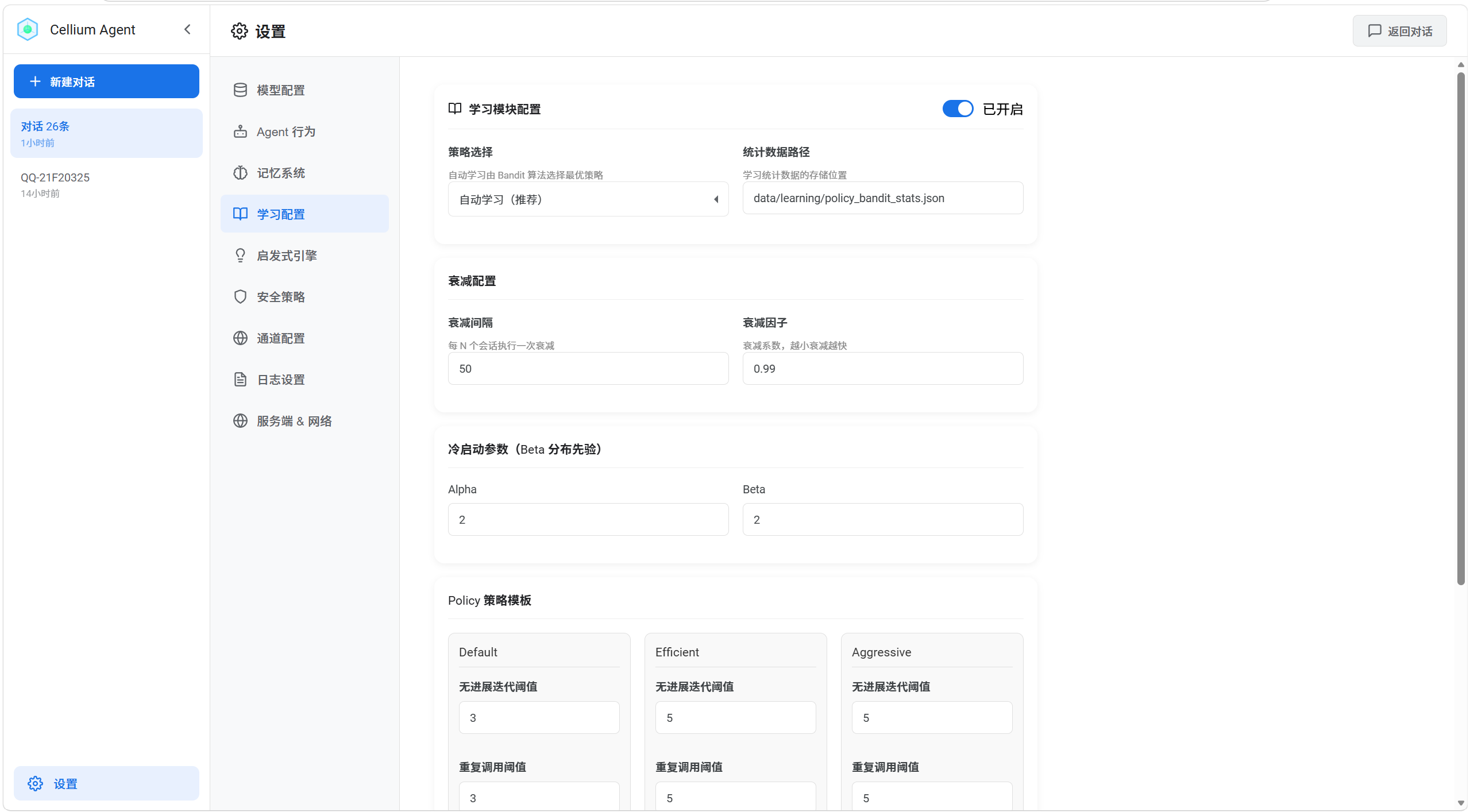
4. 学习配置
功能说明
配置 Agent 的自适应学习系统,通过 Bandit 算法自动选择最优执行策略。
配置项详解
学习模块开关
-
开启:启用自适应学习,根据历史表现自动调整策略
-
关闭:使用固定策略
策略选择
| 选项 | 说明 |
|---|---|
| 自动学习(推荐) | 由 Bandit 算法动态选择最优策略 |
| Default | 平衡策略,适合大多数场景 |
| Efficient | 高效快速,适合简单任务 |
| Aggressive | 激进宽容,给 Agent 更多尝试机会 |
衰减配置
-
衰减间隔:每 N 个会话执行一次分数衰减(默认 50)
-
衰减因子:历史分数的保留比例(默认 0.99)
冷启动参数(Beta 分布)
-
Alpha:成功先验参数(默认 2.0)
-
Beta:失败先验参数(默认 2.0)
Policy 策略模板
为不同策略配置具体的阈值参数:
-
无进展迭代阈值
-
重复调用阈值
-
趋势恶化阈值
-
终止确认置信度
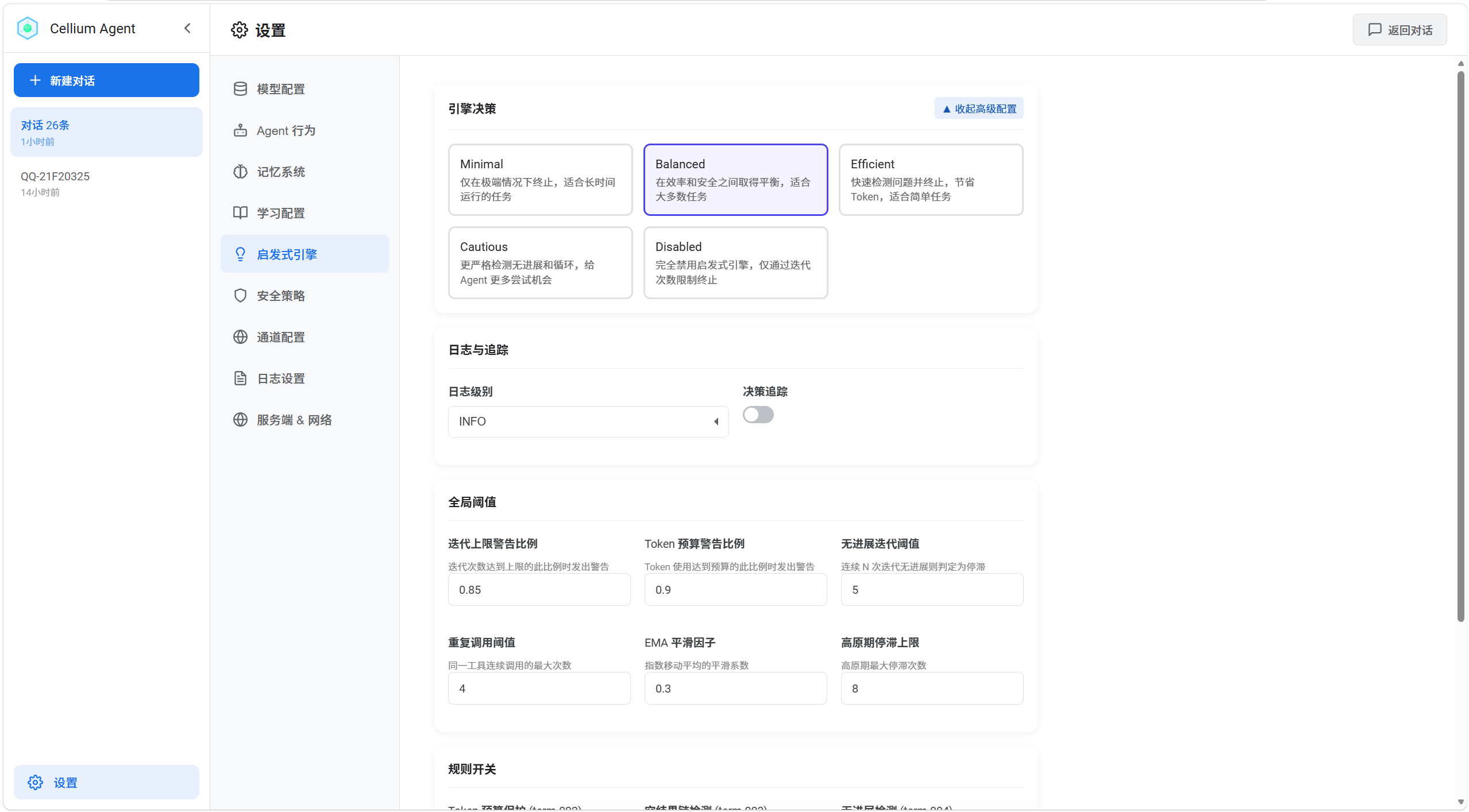
5. 启发式引擎
功能说明
配置任务终止条件和循环检测规则,防止 Agent 陷入无限循环或无意义执行。
预设模式
| 模式 | 描述 | 适用场景 |
|---|---|---|
| Minimal | 仅在极端情况下终止 | 长时间运行的复杂任务 |
| Balanced | 效率和安全平衡 | 大多数任务(推荐) |
| Efficient | 快速检测并终止 | 简单任务,节省 Token |
| Cautious | 更严格检测,更多尝试机会 | 探索性任务 |
| Disabled | 完全禁用启发式引擎 | 仅通过迭代次数限制 |
高级配置
日志与追踪
-
日志级别:DEBUG / INFO / WARNING / ERROR
-
决策追踪:记录每次决策的详细过程
全局阈值
| 阈值 | 说明 | 默认值 |
|---|---|---|
| 迭代上限警告比例 | 达到上限的此比例时警告 | 0.85 |
| Token 预算警告比例 | 达到预算的此比例时警告 | 0.9 |
| 无进展迭代阈值 | 连续 N 次无进展判定停滞 | 5 |
| 重复调用阈值 | 同一工具最大连续调用次数 | 4 |
| EMA 平滑因子 | 指数移动平均平滑系数 | 0.3 |
| 高原期停滞上限 | 高原期最大停滞次数 | 8 |
规则开关
| 规则 | 功能 | 默认 |
|---|---|---|
| term-002 | Token 预算保护 | 开启 |
| term-003 | 空结果链检测 | 开启 |
| term-004 | 无进展检测 | 开启 |
| loop-001 | 重复工具调用检测 | 开启 |
| loop-002 | 模式循环检测 | 开启 |
外部通道适配
原生览器操作组件 (web_fetch)
基于 DrissionPage 的无头浏览器组件,支持网页自动化操作:
| 命令 | 功能 | 示例 |
|---|---|---|
navigate |
访问指定 URL | {"url": "https://example.com"} |
get_screenshot |
截图(支持元素级截图) | {"full_page": false, "selector": "#content"} |
find_qrcode |
查找页面二维码 | {} |
find_button |
查找按钮并点击 | {"text": "登录", "selector": "button"} |
get_page_info |
获取页面信息 | {} |
scroll |
滚动页面 | {"direction": "down", "amount": 500} |
save_cookies / load_cookies |
Cookie 持久化 | {"path": "cookies.json"} |
使用场景:
-
网页内容抓取与分析
-
自动化登录流程(支持二维码识别)
-
网页截图与视觉验证
-
表单自动填写与提交
截图保存路径:workspace/web_fetch_screenshots/域名_时间戳.png
核心机制:
-
_cell_registry: cell_name → ICell 实例 -
get_all_tools(): AgentLoop 运行时动态读取组件工具 -
get_tool_definitions(): 返回 LLM 格式的工具定义
工具操作可见性:
-
所有工具调用都会生成用户友好的操作描述
-
支持
_intent参数自定义描述(最高优先级) -
示例:
{"command": "read", "path": "test.py", "_intent": "正在读取配置文件"}