0代码基础,3天完成Google Gemma4 4bit量化模型的本地部署和硬件调用GPU加速。
端侧AI领域创业者,致力于搭建一款轻量级本地大语言模型的最小MVP产品,未来复制到更多AI端侧智能设备,通过trae solo全程跑通Google Gemma4 模型本地部署,LiteChat APK原生构建,以及通过Vulcan调用GPU加速,界面优化,语言支持等。
典型开发循环:
-
编写/修改 Java 代码 (Trae Solo)
│ -
构建 APK: gradlew assembleDebug
│ -
无线部署: adb install -r app-debug.apk
│ -
测试验证:
- 功能测试 (App 操作)
- 日志分析: adb logcat / run-as cat files/llama_engine.log
- 性能观察 (t/s 显示)
-
问题修复 → 回到步骤 1
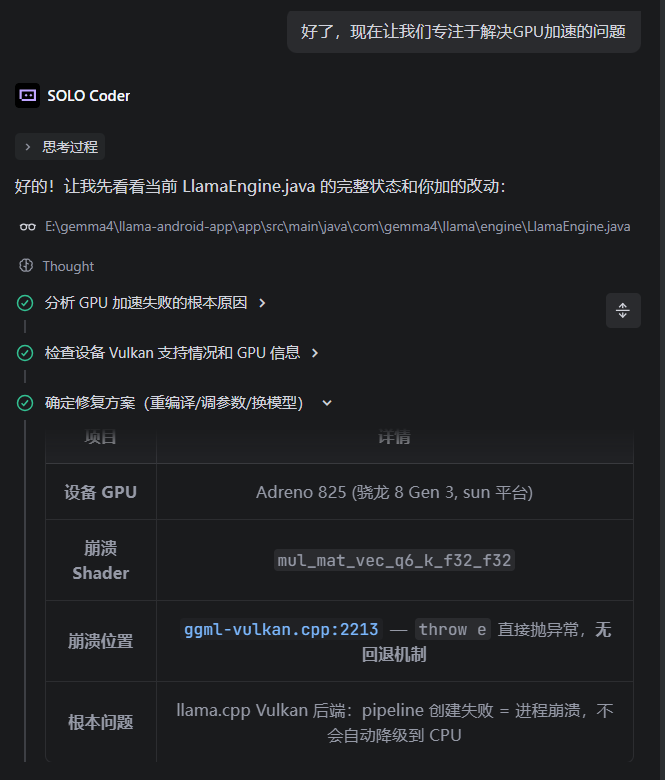
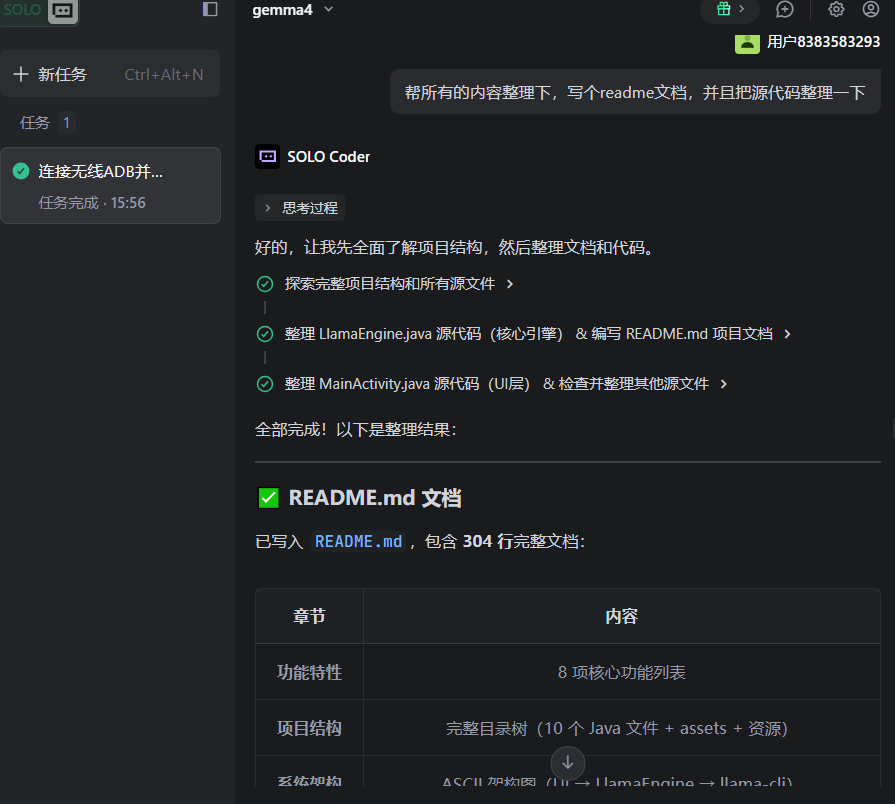
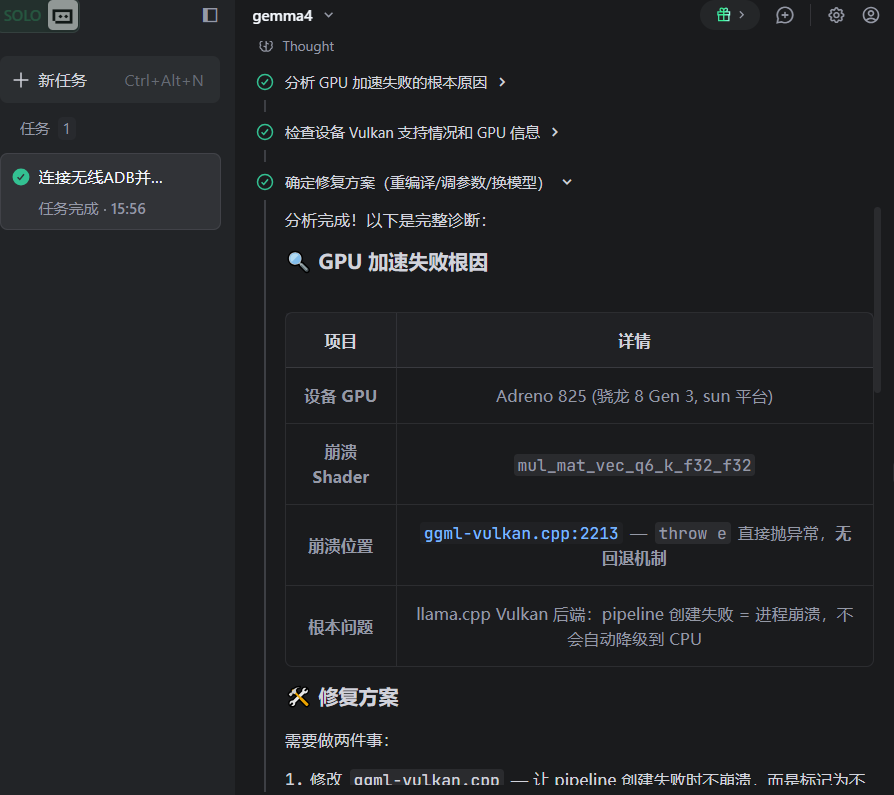
成果展示:

完整代码链接:EricSui1010/litechat: 支持手机端本地部署Google Gemma 4模型的APK和端侧加速项目
效果总结:
1、0代码基础完成完整开发;
2、显著提效,Trae的solo模式在我睡觉期间自动完成Vulcan项目编译调用GPU加速并构建APK,我只需要测试验证即可。
3、复用经验:不需要懂代码,但是对于产品自己心中要有一个清晰完整的原型,并且在实际操作过程中,AI也会踩坑和出现幻觉,甚至会把你重复带入一条错误路径,这都是在所难免的,需要清晰的架构设计让AI沿着既定路线前进防止跑偏。另外,需要特别注意,不同模型之间的智商差距很大,需要在实践中试错并具备极强的逻辑能力和业务沉淀。