#TRAE 技巧便利店
扣扣嗖嗖的我,有时间写了,真tmd费脑细胞
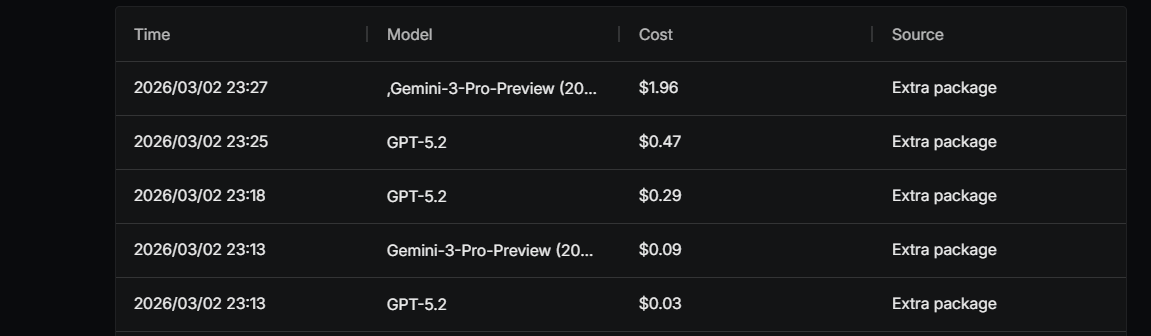
从2月13号看到trae官方公告token开始计费,我就在想这下肯定要拉高成本了,赚钱不行,但是我抠啊,富裕仗没打过,打的都是逆风局,现在国际上各大模型厂都在推计费,不管出于什么原因,既然开始计费,改变不了规则就要适应规则啊。
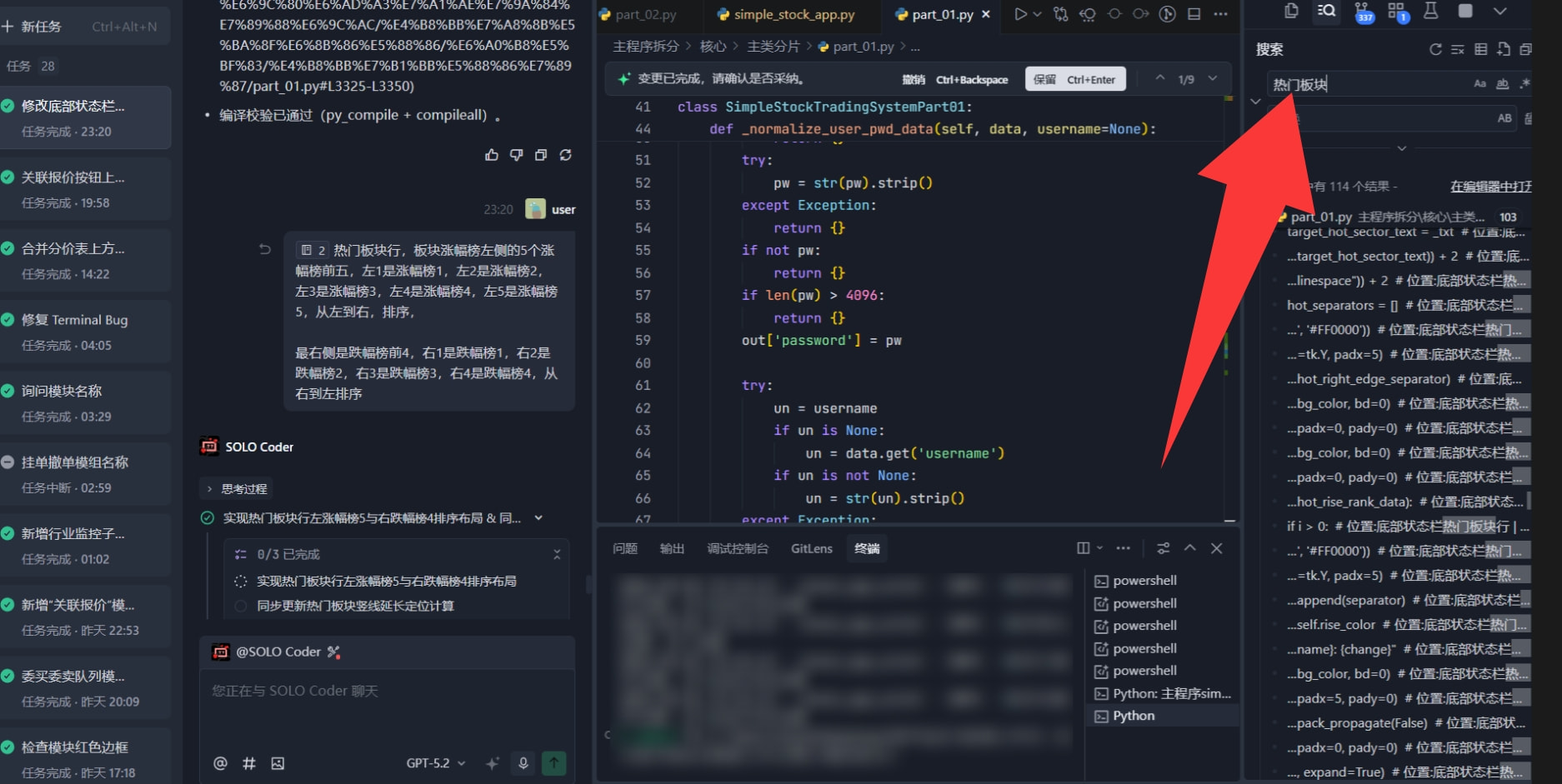
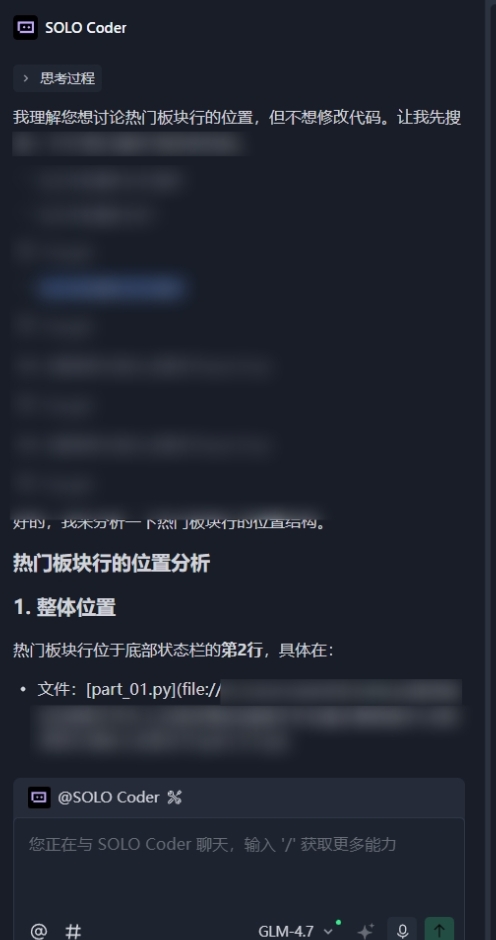
从24号开始,我就陆陆续续动手改造我的项目。我那个26G的小项目,被我拆成了几十个文件,每个文件后面都做了详细的注释。现在我跟trae对话,不会上来就让它找问题,我现在用得最多的是搜索功能——因为每个功能都有注释,通过搜索能精准定位到对应的文件,然后把对应的文件添加到对话框里,再在对话框里把所有的功能想好啊。
我用 TRAE 做了一个有意思的Agent 「SOLO Coder」。 点击 https://s.trae.ai/a/9519f3?region=sg 立即复刻,一起来玩吧!
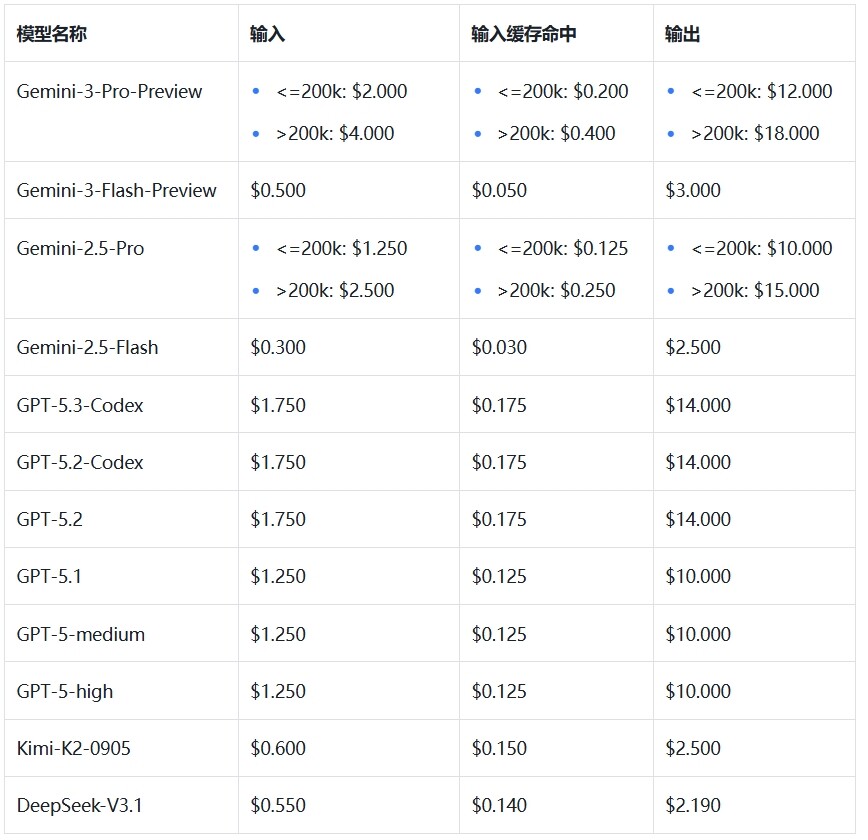
模型选择上我也精打细算:先用最早的模型去解决问题,因为更早的模型token费用更低,能用5.2解决的问题绝不上5.2codex。
从我的项目写到9月24号到2月24号刚好5个月,一直在总结一直在试错。我现在把之前一大堆规则都砍了,map也砍了,上下文的记忆也关了,现在只剩agent与2个规则。规则写得很简单:
规则一:不要写脚本,不要批量处理。
规则二:所写或改动的“每行行尾注释”都要注释,这一行的功能是干嘛的、管理的是哪个功能。写上功能名称,这样搜索的时候可以被精准搜索到,防止ai乱改链路。
还有个技巧:每次读取对话时,读取的md文件以及个人及项目规则,不能超过上下文5k。如果用户给了参考文件,要先在用户提供的文件里进行关键字搜索,搜索后再去读上下文。
现在ai的流程变成这样:第一步先读懂理解用户提问的问题,根据问题制定任务,制定任务要符合用户提出的问题。找出用户提问里的关键词,关联所有代码以及关联代码的子关联,全方位检索,发散思维全方位考虑,要考虑整体项目功能,改动不能损害现有功能。有时候用户问句不够细,ai要根据大范围去检索可能造成问题的原因,不能忽略任何细节,根据原因详细分析缺少或需要补充的条件。改动的每一个字符代码必须充分考虑可能造成的后果,不能让现有功能缺失或遗漏。

现在也双持了,改每个小功能,我让trae cn,只读不改,讨论问题,讨论完后再去国际让5.2改,我是穷人,每一个字符的token都要花在刀刃上,