【More than Coding】用 SOLO 打造 AI 产品经理个人知识库:从信息爆炸到结构化洞察
一、摘要
作为一名没有开发背景的 AI 产品经理,我在 vibe coding 的背景下工作,需要浅显涉猎架构、流程编排、前后端开发等领域,但缺乏技术深度。传统做法是从自媒体获取 AI 前沿资讯,但容易断章取义、信息爆炸,难以形成体系化的认知。我利用 TRAE SOLO 构建了一套 「信息获取 → 信息解构 → 结构化存储」 的完整知识管理工作流,基于 Andrej Karpathy 的 LLM Wiki 方法论,将每日 AI 动态自动整理为带双向链接的 Obsidian 知识库。原来每天 不定时的信息整理工作,现在 15 分钟完成,且知识可复用、可检索、持续生长。
二、背景
我的角色
没有开发背景的 AI 产品经理,在 vibe coding 的背景下工作,需要浅显涉猎架构、流程编排、前后端开发等领域,但缺乏技术深度。需要获取前沿的 AI 知识(如 harness engineering、Agent 架构、模型能力边界)来支撑产品决策。
核心痛点
- 信息爆炸:从自媒体获取的 AI 资讯碎片化严重,容易断章取义,难以判断真伪
- 知识断层:缺乏技术背景,对前沿概念(如 harness engineering、多 Agent 架构)理解不深,难以形成体系化认知
- 缺乏结构:信息散落在浏览器书签、微信收藏、笔记软件中,无法关联和复用
- 重复劳动:每周写周报时需要重新梳理,效率极低
灵感来源
Andrej Karpathy(OpenAI 创始成员、特斯拉前 AI 负责人)提出了 LLM Wiki 概念——用 LLM 持续维护一个结构化 Markdown 知识库,核心哲学是 “Knowledge as Code”(知识即代码):
- Ingest(摄取):将非结构化信息通过 LLM 预编译为高密度 Markdown
- Query(查询):基于结构化知识进行跨文档逻辑推理,而非临时检索
- Lint(校验/自愈):定期扫描知识库,检查一致性、建立关联、清理过时信息
我决定用 TRAE SOLO 来实现这套方法论,解决信息获取、信息解构、结构化存储三大问题。
三、实践过程
我的完整工作流分为四步:结构设计 → 人工筛选 → 内容拆解 → 知识沉淀
第一步:让 SOLO 基于我的角色和需求设计日报/周报结构
作为没有技术背景的 AI 产品经理,我首先让 SOLO 帮我设计一个适合我的信息追踪框架:
“我是一个没有开发背景的 AI 产品经理,需要追踪 AI 行业动态。帮我设计一个日报结构,每天能快速了解:哪些模型发布了、哪些 Agent 框架更新了、哪些算力/政策变化会影响产品决策。”
SOLO 为我设计了以下结构:
AI 产品经理知识库/
├── 日报/
│ ├── 2026-04-07.html # 每日可视化报告
│ └── ...
├── 周报/
│ └── 第14周-摘要.md # 每周趋势汇总
├── 知识条目/
│ ├── 01-前沿模型/
│ │ ├── GPT-6.md
│ │ ├── Claude-Mythos.md
│ │ └── ...
│ ├── 02-AI-Agent/
│ ├── 03-基础设施/
│ ├── 04-开发工具链/
│ ├── 05-行业政策/
│ └── 06-前沿概念/
│ ├── Harness-Engineering.md
│ ├── 多模型编排.md
│ └── ...
└── templates/
└── event-template.md
每个知识条目都有统一的模板:
---
title: GPT-6
date: 2026-04-05
tags: [大模型, OpenAI, AGI]
related: [[Claude-Mythos]], [[GPT-5.4]]
---
# GPT-6
## 核心信息
- 发布日期、性能参数、关键特性...
## 产品经理视角
> 这个技术对产品路线图的影响是什么?技术边界在哪里?
## 关联知识
- [[相关概念]] — 为什么关联
第二步:阅读日报/周报,人工筛选感兴趣的内容,做深度检索
每天我会用一句话触发 SOLO 生成日报:
“更新 AI 日报”
SOLO 会自动搜索、去重、生成 HTML 报告。然后我会:
- 快速浏览日报:看标题和摘要,筛选出 3-5 条真正感兴趣的内容
- 触发深度检索:对筛选出的内容,让 SOLO 做深入挖掘
例如,看到 GPT-6 架构曝光的新闻后:
“GPT-6 这个新闻帮我深度检索一下,我想知道:为什么 OpenAI 要砍掉 Sora 全力押注 GPT-6?2M 上下文对产品设计意味着什么?和 Claude Mythos 相比有什么差异?”
SOLO 会去抓取原文、搜索相关报道、整理成结构化的深度分析。
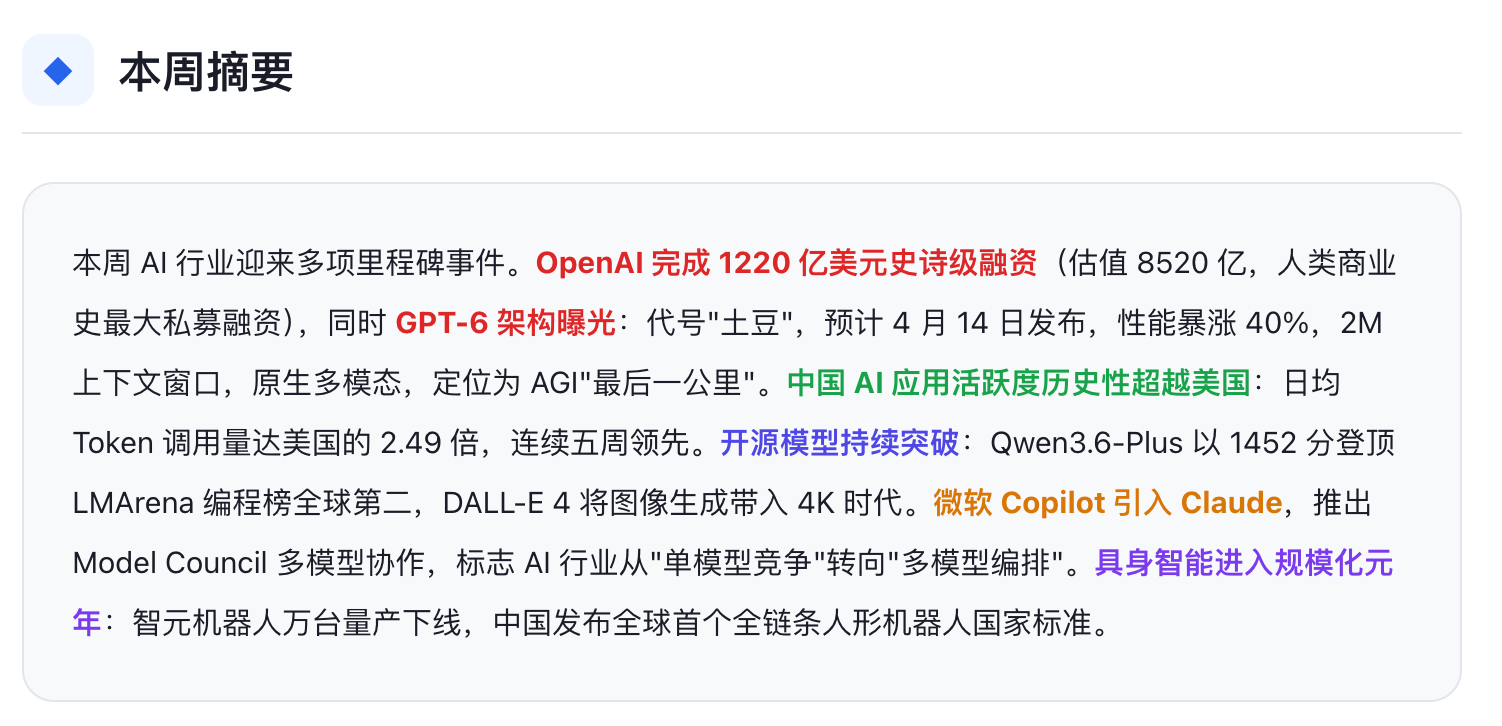

关键判断标准(我筛选内容的原则):
- 是否影响产品路线图(如 GPT-6 的发布时间)
- 是否涉及技术边界变化(如 2M 上下文窗口)
- 是否有竞品对标价值(如 Claude Mythos vs GPT-6)
- 是否涉及前沿概念需要学习(如 harness engineering)
第三步:让 Solo sode按 Karpathy LLM Wiki 方法论对内容做拆解、存档
对深度检索后的内容,我会让 solo code 按照 Karpathy 的 LLM Wiki 方法论处理:
“把 GPT-6 的内容按照知识库模板存档,建立与 Claude-Mythos、算力博弈、Harness-Engineering 的关联”
SOLO 会执行:
- Ingest(摄取):将非结构化信息转化为高密度 Markdown
- 结构化:填充 Frontmatter(日期、标签、关联条目)
- 建立关联:自动生成双向链接如
[[Claude-Mythos]] - 生成产品经理视角:解释技术概念对产品的意义
第四步:Obsidian 自动化沉淀内容


四、踩过的坑
坑 1:一开始让 SOLO 直接写 Obsidian 笔记,结果格式混乱
解决:先定义好模板(Frontmatter + 固定章节),让 SOLO 按模板填充内容,而不是自由发挥。
坑 2:自媒体信息质量参差不齐,容易断章取义
解决:在 Prompt 中明确指定高质量信息源(量子位、InfoQ、36Kr、TechCrunch),并要求 SOLO 用产品经理能理解的语言解释技术概念(如 harness engineering、多 Agent 架构)。
坑 3:去重做得不好,同一事件反复出现
解决:让 SOLO 先列出已有事件清单,再与搜索结果比对。明确要求"已记录的事件不要重复"。
坑 4:前沿概念(如 harness engineering)理解不深,难以建立关联
解决:专门开辟"前沿概念"分类,让 SOLO 对每个新概念生成独立的解释性条目,包含定义、应用场景、与现有知识的关联。
五、成果展示
1. AI 产品经理进展追踪日报(HTML 报告)
累计追踪 25+ 条关键动态,覆盖 2026 年 3 月 17 日至 4 月 7 日。每条动态包含背景、事件、价值评估、行动建议四个维度,技术概念用产品经理能理解的语言解释。
2. Obsidian 知识库结构
- 6 个一级分类(前沿模型、AI Agent、基础设施、开发工具链、行业政策、前沿概念)
- 30+ 个知识条目,每个都有 Frontmatter 元数据和双向链接
- 统一的事件模板,确保信息结构一致
3. 关键洞察示例
通过持续追踪,沉淀出以下产品级判断:
- 模型选型:从"选最好的模型"转向"设计多模型编排方案"(微软 Copilot 引入 Claude 是信号)
- Agent 架构:Google 多 Agent 扩展原则 + MCP/A2A 协议标准化,从野蛮生长进入有章可循
- 算力格局:中国 AI 调用量超美国 2.49 倍,国产模型在实际应用中已被大规模验证
- GPT-6 预判:4/14 发布,性能+40%,2M 上下文,将重新定义顶级模型标准
- 前沿概念理解:harness engineering、LLM Wiki、多模型编排等概念从陌生到可解释
六、效果与总结
提效数据
| 环节 | 之前 | 现在 | 提升 |
|---|---|---|---|
| 每日信息筛选 | 2-3 小时 | 15 分钟 | 10x |
| 周报撰写 | 4 小时 | 已自动积累,30 分钟整理 | 8x |
| 知识检索 | 翻聊天记录/书签 | Obsidian 全文搜索 + 双链跳转 | 质的飞跃 |
| 信息复用 | 几乎不可能 | 每条知识可被多次引用 | 从 0 到 1 |
核心收获
- SOLO 的最大价值不是"生成",而是"工作流编排"。搜索 → 过滤 → 解构 → 结构化 → 入库,这个链条才是提效的关键。
- Karpathy 的 LLM Wiki 方法论确实有效。Markdown + 双向链接 + Frontmatter 是 LLM 最友好的知识格式,AI 可以像操作代码库一样操作知识库。
- "知识即代码"不是比喻。模板就是 Schema,双向链接就是引用,Lint 就是知识库的 CI/CD。
- 从"存信息"到"长知识"。传统笔记越积越多却越来越难用,而这套系统让知识库像代码库一样持续进化。
- 对非技术背景的产品经理友好:SOLO 可以用通俗语言解释技术概念(如 harness engineering),让我在 vibe coding 环境下也能与开发团队有效沟通。
可复用方法
这套方法不限于 AI 产品经理,任何需要持续跟踪行业动态、缺乏技术深度的角色(运营、投资人、产品运营、业务分析师)都可以复用:
- 定义你的知识分类体系(包括"前沿概念"分类)
- 设计统一的信息模板(背景 → 事件 → 价值 → 行动)
- 用 SOLO 编排"搜索 → 过滤 → 解构 → 结构化"的每日流程
- 在 Prompt 中明确要求"用通俗语言解释技术概念"
- 存入 Obsidian(或任何支持 Markdown + 双链的工具)
- 定期执行"知识库自愈"
工具:TRAE SOLO + Obsidian
方法论:Andrej Karpathy LLM Wiki(Knowledge as Code)
知识库规模:25+ 每日动态,30+ 知识条目,6 大分类
适用角色:非技术背景的 AI 产品经理、运营、投资人、业务分析师