借助 TRAE SOLO 新的桌面应用,我初步完成一个法律法规的展示小应用
使用的是MTC模式,这个新模式。我让他直接帮我分析了所有法律法规和相关文档涉及到的 公文文种和格式,然后逐步一个种类一个种类完成解析等工作。
从国家法律法规数据库批量下载了现行有效的法律、部门规则、地方法律、司法解释等docx文档。
从docx——md——json——md的一个过程。要中途倒一遍json的原因是还有一些其他的用途。
截图:
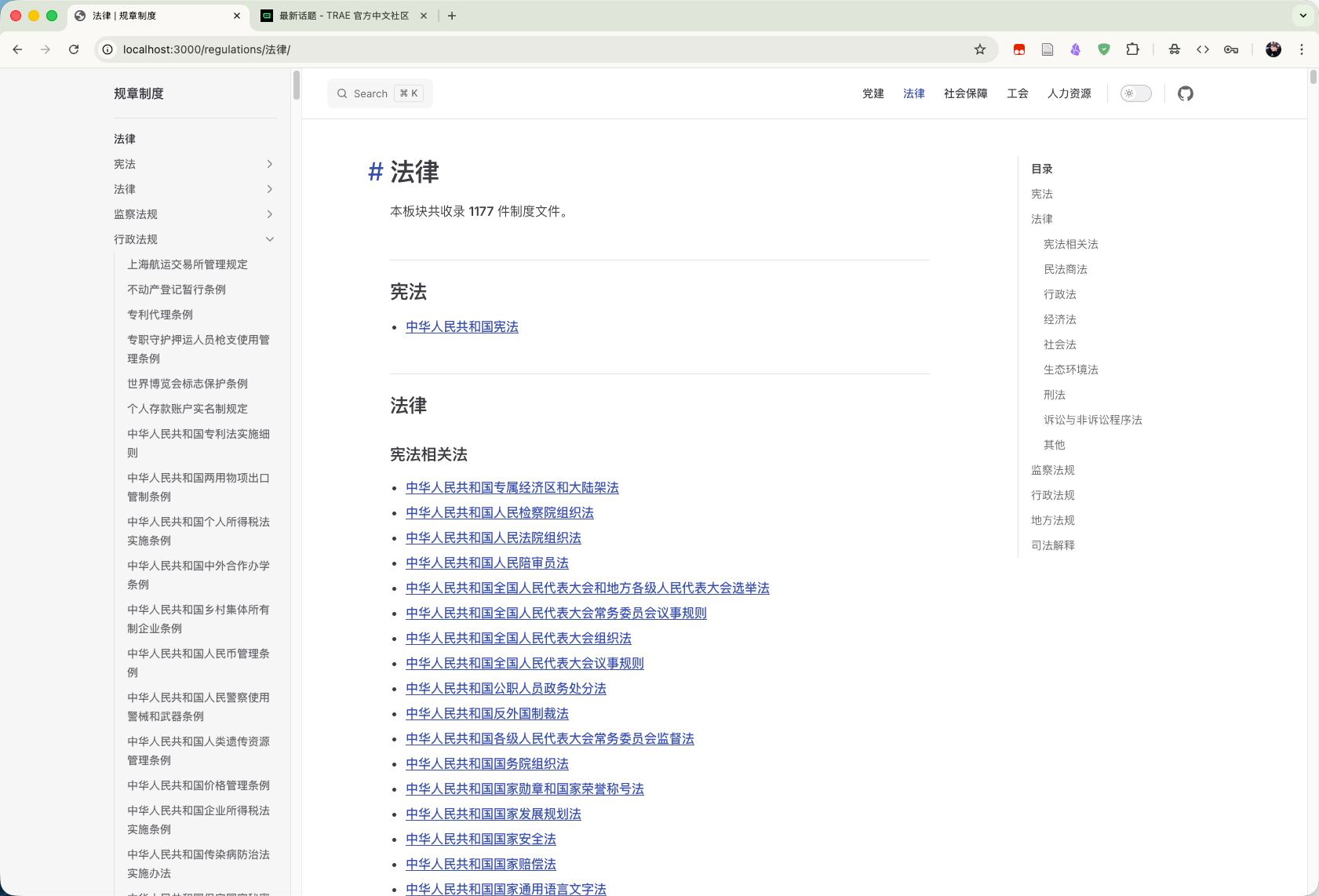
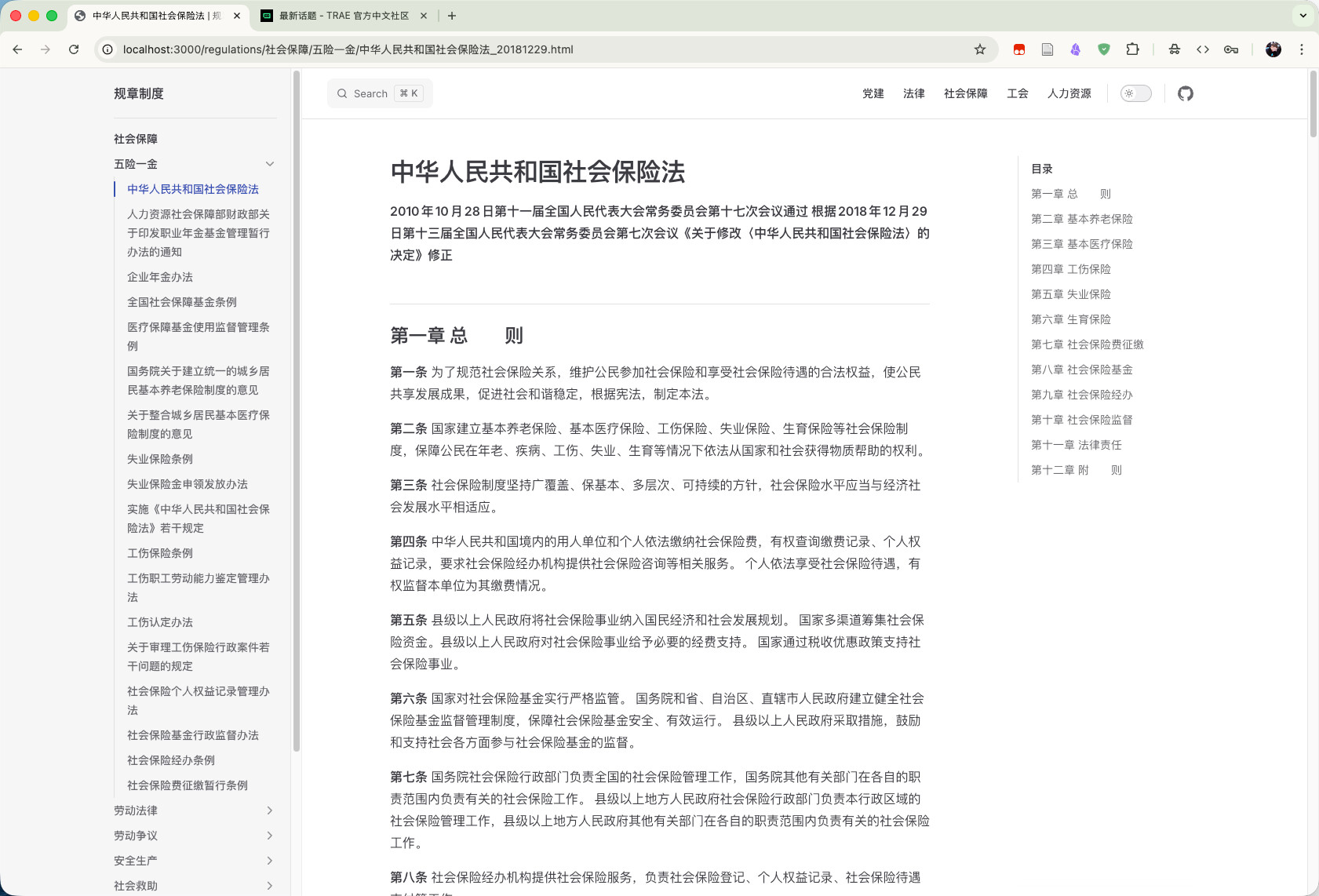
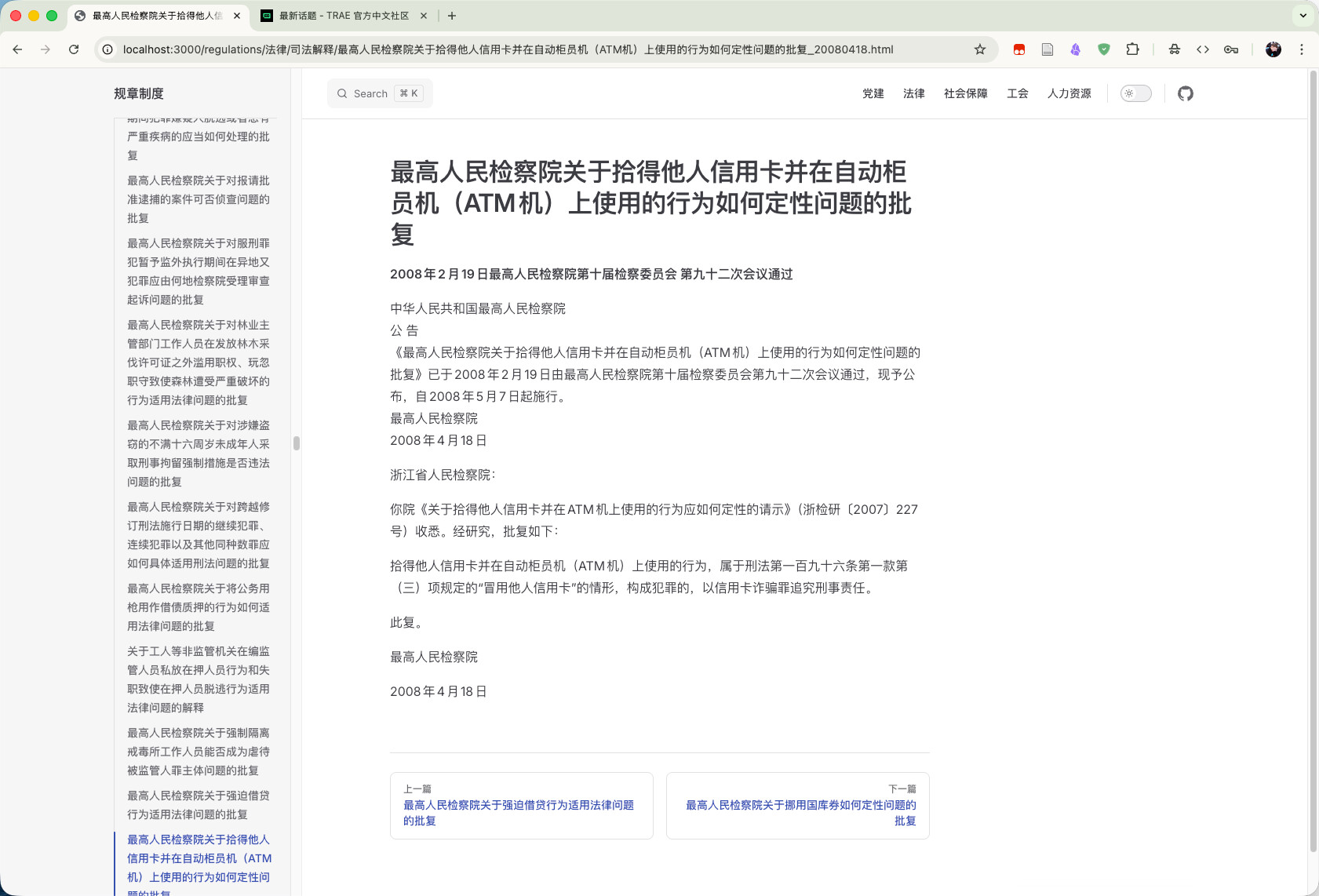
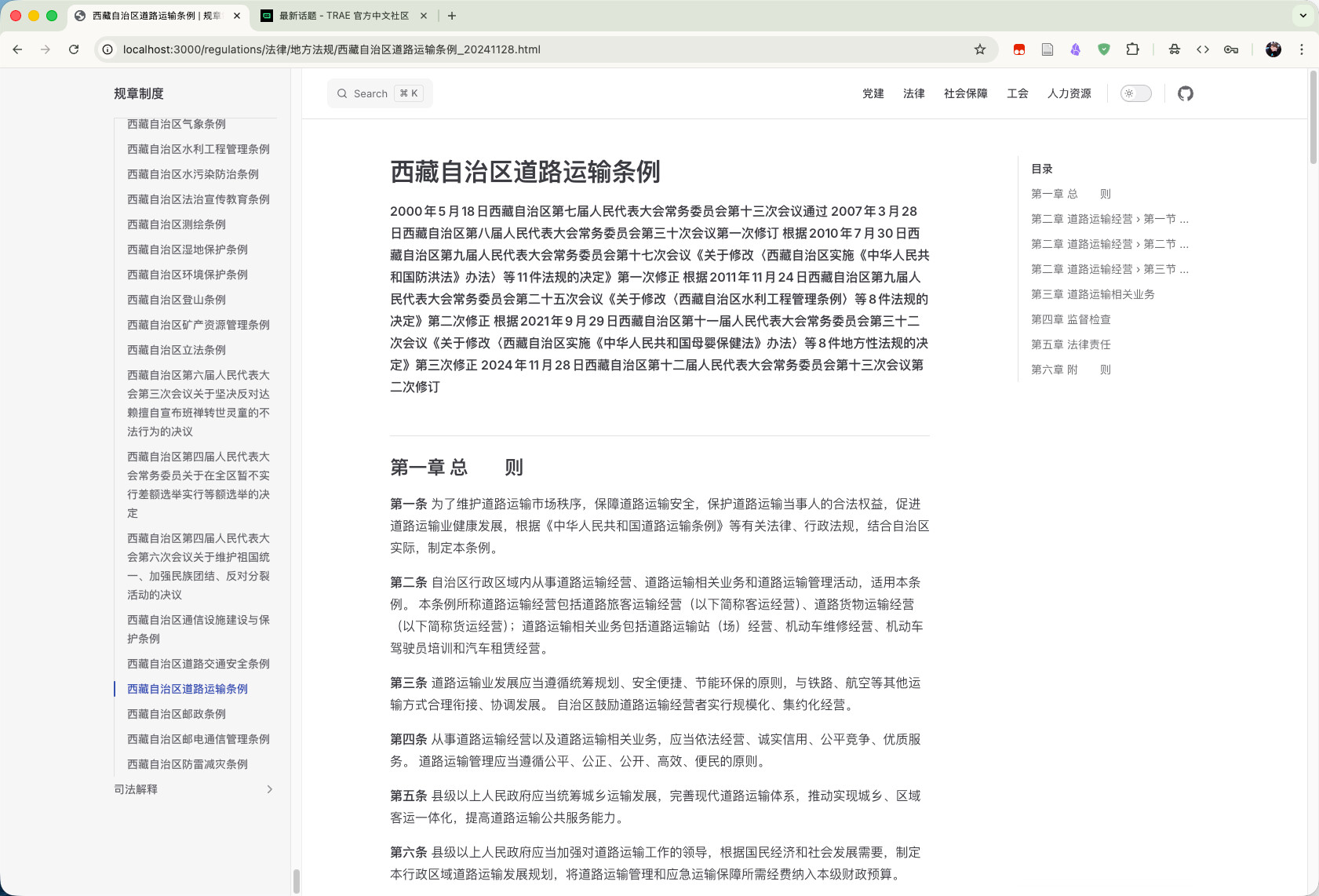
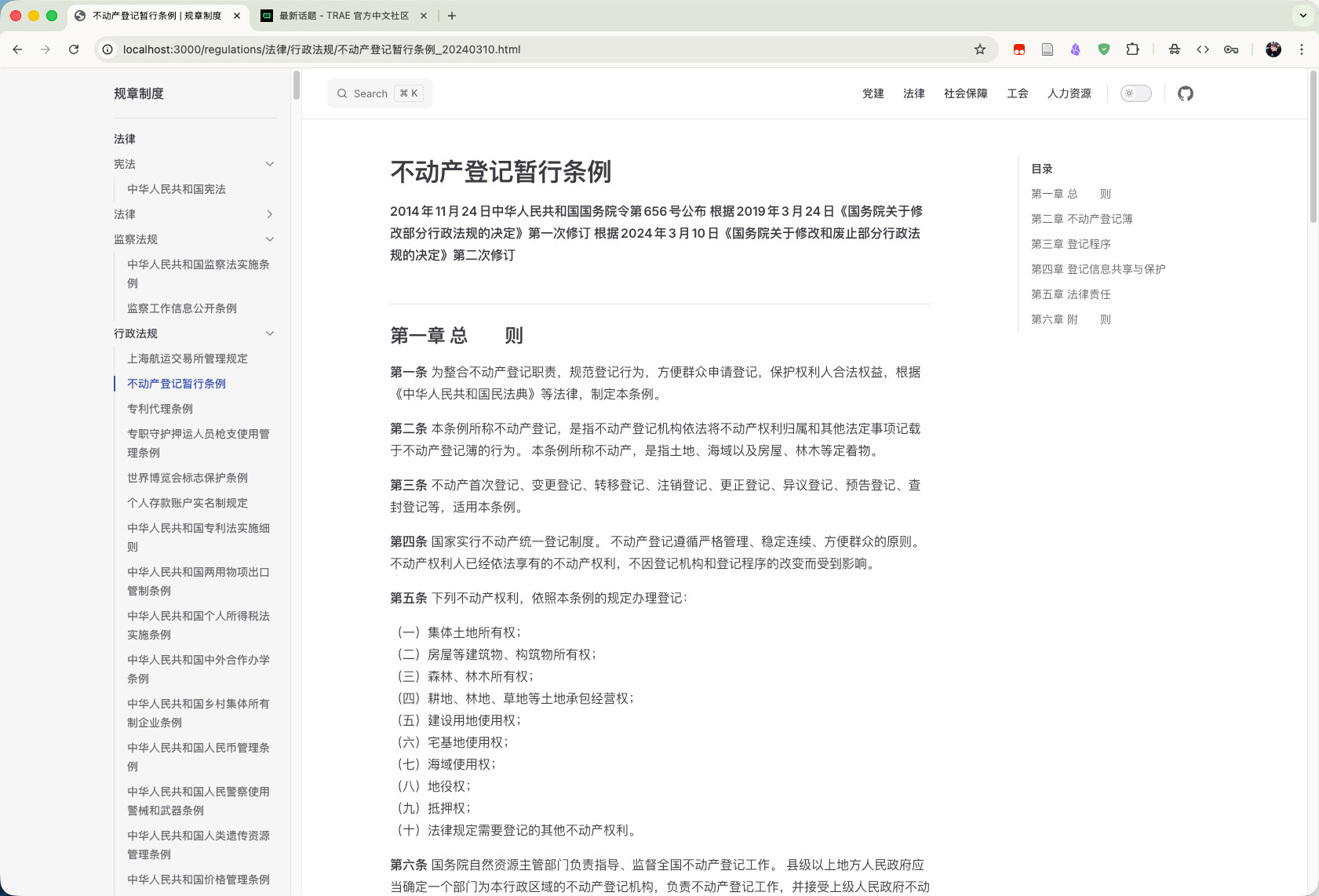
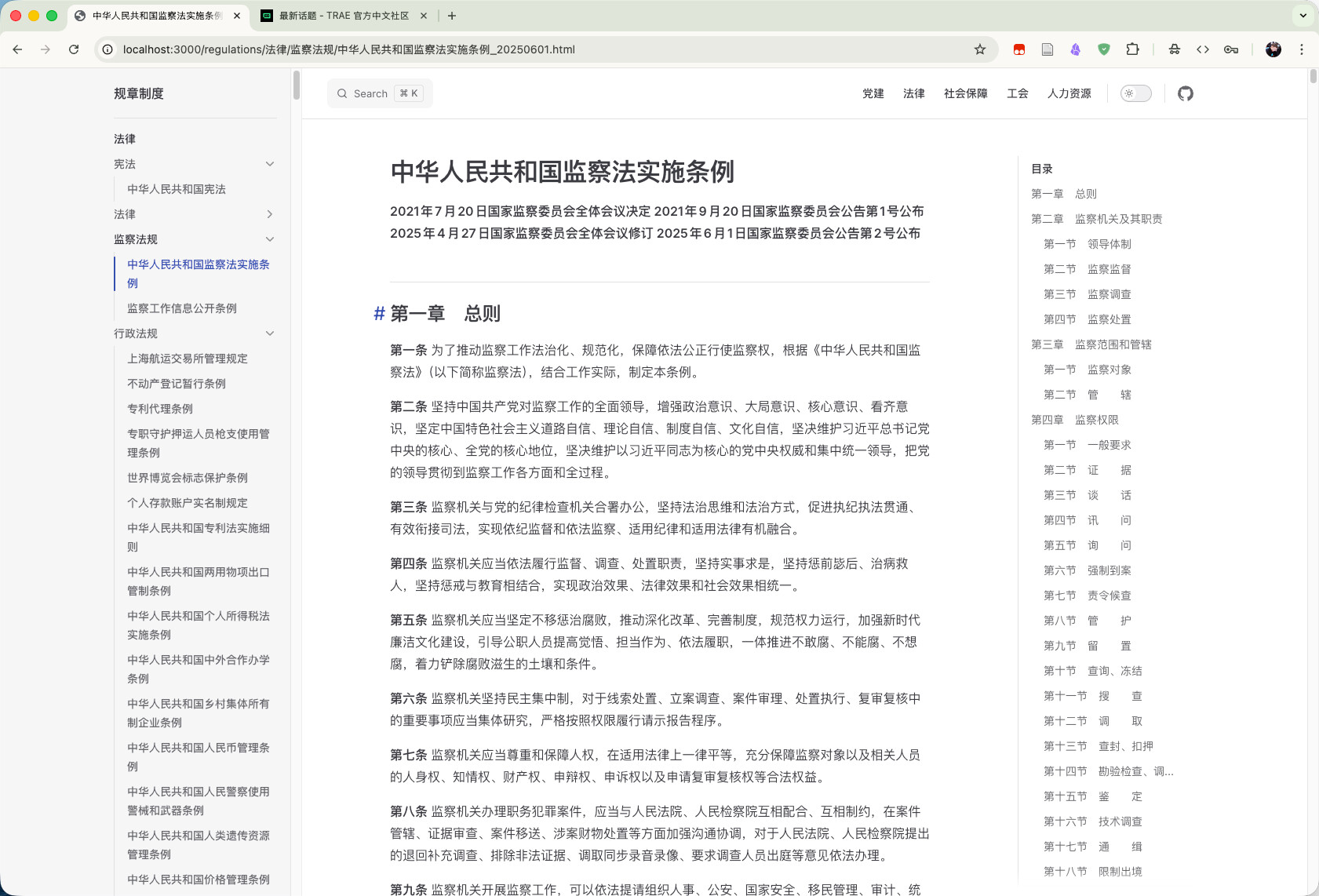
以下这个是AI的总结
从零构建法律法规文档转换流水线:DOCX → MD → JSON → MD 全流程实战
本文记录了在一个实际项目中,如何从零开始构建一套完整的法律法规文档转换系统。该系统将 Word 格式的法律法规文档(.docx)经过 DOCX → Markdown → JSON → Markdown 的四步流水线处理,最终通过 VitePress 构建出一个支持全文搜索的规章制度文档站,收录了超过 1500 件 法律法规文件。
一、项目背景与需求分析
1.1 为什么要做这个?
在一个人事管理系统中,"规则制度"模块需要提供法律法规的在线查询功能。原始数据来源是大量的 Word 文档(.docx/.doc),这些文档存在以下问题:
- 格式不统一:不同来源的文档使用了不同的标题样式、编号方式
- 结构层次深:法律文件有"编 > 分编 > 章 > 节 > 条 > 款 > 项"多达 7 级的嵌套结构
- 文种多样:涉及法律、条例、规定、意见、通知、司法解释等 17 种 不同文种
- 网页残留:部分文档从网页抓取,包含发布时间、字体标签等残留信息
- 需要在线查询:最终要构建一个可搜索、可浏览的文档站
1.2 整体架构
┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────────┐
│ DOCX │───>│ MD │───>│ JSON │───>│ MD │───>│ VitePress │
│ (原始文档)│ │ (基础转换)│ │ (结构化) │ │ (标准化) │ │ (文档站) │
└──────────┘ └──────────┘ └──────────┘ └──────────┘ └──────────────┘
步骤 0 步骤 1 步骤 2 步骤 3 步骤 4
docx_to_md md_to_json json_to_md distribute_md vitepress build
核心设计思想:为什么不直接 DOCX → MD?因为原始 Markdown 缺乏结构化信息,无法支持:
- 按文种差异化渲染(法律的"条"和意见的"一、"渲染方式完全不同)
- 目录自动生成与导航配置
- 文档结构验证(序号连贯性检查)
- VitePress 的 frontmatter 和 outline 配置
所以中间引入了 JSON 作为结构化的中间表示,实现了"解析"与"渲染"的解耦。
二、技术选型
| 环节 | 技术选择 | 理由 |
|---|---|---|
| DOCX 解析 | Python python-docx |
原生支持 .docx 格式,可精确控制段落样式和格式提取 |
| .doc 格式 | pandoc |
通用格式转换工具,支持旧版 .doc 格式 |
| 文本处理 | Python re 正则 |
中文法律法规的编号模式复杂,正则是最灵活的工具 |
| 并发处理 | concurrent.futures.ThreadPoolExecutor |
IO 密集型任务,多线程即可高效处理 |
| 文档站 | VitePress | Vue 驱动的静态文档站,内置全文搜索、侧边栏、导航 |
| 部署 | Express 静态文件服务 | 与主应用共用 Nginx,通过 /regulations 路径访问 |
三、步骤 0:DOCX → Markdown(基础转换)
3.1 目标
将 Word 文档转换为"干净的" Markdown,仅保留基础格式信息(加粗、斜体、表格、标题层级),不做任何结构化处理。
3.2 关键实现
# 使用 python-docx 遍历文档元素
for element in doc.element.body.iterchildren():
if isinstance(element, CT_P): # 段落
para = Paragraph(element, doc)
style = get_paragraph_style(para) # 识别标题样式
formatted_text = process_runs(para) # 保留加粗/斜体
elif isinstance(element, CT_Tbl): # 表格
table = Table(element, doc)
md_table = _convert_table_to_md(table)
3.3 关键注意事项
① 合并单元格的去重处理
python-docx 对合并单元格的处理会导致 row.cells 返回重复引用。必须使用 _tc 的 XML id 去重:
seen_tc_ids = set()
for cell in row.cells:
tc_id = id(cell._tc)
if tc_id in seen_tc_ids:
continue # 跳过合并单元格的重复引用
seen_tc_ids.add(tc_id)
② 段落样式识别
Word 文档的样式名不统一(如 Heading 1、heading1、标题 1),需要做模糊匹配:
def get_paragraph_style(para) -> str:
style_name = para.style.name if para.style else "Normal"
if "title" in style_name.lower():
return "title"
elif "heading 1" in style_name.lower():
return "heading1"
# ... 更多匹配规则
③ .doc 格式的兼容
旧版 .doc 文件无法用 python-docx 处理,需要通过 pandoc 转换:
subprocess.run([
"pandoc", "-s", doc_file, "-o", output_file,
"--wrap=none", "--markdown-headings=atx"
])
④ 批量多线程处理
1500+ 文件逐个转换太慢,使用线程池加速:
with ThreadPoolExecutor(max_workers=8) as executor:
futures = {executor.submit(convert, f): f for f in docx_files}
for future in as_completed(futures):
# 统计成功/失败数
四、步骤 1:Markdown → JSON(按文种解析)
4.1 目标
将"扁平"的 Markdown 文本解析为结构化的 JSON,提取元数据、识别文种、解析层级结构。
4.2 处理流程
原始 MD → 清理网页残留 → 合并断行 → 提取元数据 → 检测文种 → 选择解析器 → 结构化解析 → 输出 JSON
4.3 预处理:清理网页残留
从网页抓取的文档常包含各种残留信息,必须在解析前清理:
def clean_web_artifacts(content: str) -> str:
# 清理零宽空格等不可见字符
content = re.sub(r"[\u200b-\u200f\u202a-\u202e\ufeff]", "", content)
# 清理"发布时间: XXXX年XX月XX日"
content = re.sub(r"\n*发布时间:\s*\d{4}年\d{1,2}月\d{1,2}日\s*\n*", "\n", content)
# 清理"字体:[ 大 中 小 ]"
content = re.sub(r"字体:\s*\[.*?\]", "", content)
# 清理标题行末尾紧跟的文号
content = re.sub(r"(#[^\n]*?\*{0,2})\s*((?:国发|人社部发)[^〕」\n]*[号〕」」])\s*$",
r"\1\n\n**\2**", content, flags=re.MULTILINE)
4.4 预处理:合并断行
这是整个流水线中最棘手的问题之一。网页抓取或 OCR 产生的 Markdown 常出现标题和段落被不自然断行的情况:
# 中华人民共和国
劳动合同法
(2012年修正)
第一条 为了完善劳动合同制度,明确劳动合同双方当事人的权利和义务,保护劳动者的合法权益,
构建和发展和谐稳定的劳动关系,制定本法。
合并策略需要考虑多种场景:
def merge_broken_lines(paragraphs: list) -> list:
# 1. 标题续行:# 开头的行 + 不以句号/括号结尾的短文本
if current.startswith("#") and not next_p.endswith("。"):
should_merge = True
# 2. 短文本续行:长度 < 50 且不以句号结尾
elif len(current) < 50 and not current.endswith("。"):
should_merge = True
# 3. 日期信息续行:(2023年修订 + 根据XXX规定)
elif re.match(r"^[((]\d{4}年", current):
should_merge = True
# 4. 但要排除:颁布信息行、结构行(第X章/节/条)、极短独立行
关键注意事项:
- 颁布信息行(含"发布"“通过”"施行"关键词)不能与正文合并
- 结构行(第X章、第X条)不能合并
- 极短行(≤10字符)视为独立标题,不合并
4.5 文种自动检测
系统定义了 17 种文种,每种有独立的解析器和渲染器:
| 编号 | 文种 | 代码 | 典型结构 |
|---|---|---|---|
| 1 | 法律 | law | 编 > 分编 > 章 > 节 > 条 > 款 > 项 |
| 2 | 条例 | regulation | 章 > 节 > 条 > 款 > 项 |
| 3 | 规定 | regulation_rule | 章 > 条 > 款 > 项 或 无结构 |
| 4 | 细则/规则 | detailed_rule | 章 > 条 > 款 > 项 |
| 5 | 意见 | opinion | 一、二、三 > (一)(二)> 正文 |
| 6 | 通知 | notice | 一、二、三 / 第X条 / 纯段落 |
| 7 | 公告/通告 | announcement | 公告头 + 条款结构 |
| 8 | 司法解释 | judicial_interpretation | 条 > 款 > 项 |
| 9 | 决定/决议 | decision | 章 > 条 / 一、二、三 |
| 10 | 命令/令 | command | 第X条 / 一、二、三 |
| 11 | 批复/复函 | reply | 第X条 / 一、二、三 |
| 12 | 安排 | arrangement | 第X条 / 一、二、三 |
| 13 | 修正案 | amendment | 一、二、三 > 修改内容 |
| 14 | 方案 | plan | 一、二、三 / 第X条 |
| 15 | 守则/工作规则 | rules | 一、二、三 / 纯段落 |
| 16 | 法典 | code | 编 > 分编 > 章 > 节 > 条 |
| 17 | 其他 | other | 自动检测 |
检测逻辑按优先级排列:
DOCUMENT_TYPE_RULES = [
(DocumentType.CIVIL_CODE, ["民法典"], []), # 民法典优先
(DocumentType.CRIMINAL_LAW, ["刑法"], ["刑事诉讼法"]), # 刑法(排除刑诉法)
(DocumentType.JUDICIAL_INTERPRETATION, ["解释"], []), # 司法解释
# ... 更多规则
]
关键注意事项:
- 民法典和法典优先级最高,因为标题中包含"法"字,容易被误判为普通法律
- 刑法需要排除"刑事诉讼法"等包含"刑法"二字的其他法律
- 司法解释需要特殊处理:标题中可能不包含"解释"二字,但发布机关是"最高人民法院"或"最高人民检察院"
- 公告只有当"公告"作为独立行标题出现时才判定,避免正文中出现"公告"二字被误判
4.6 结构化解析
以最复杂的"法律"类型为例,使用 StructureParser 提取层级结构:
class UnifiedLawParser(BaseParser):
def parse(self, paragraphs: List[str]) -> Dict[str, Any]:
structure = self.structure_parser.extract_hierarchy(paragraphs, flat=True)
return {"chapters": structure["chapters"], "preamble": structure.get("preamble", "")}
输出的 JSON 结构示例:
{
"metadata": {
"title": "中华人民共和国宪法",
"doc_classification": "law",
"passage_info": "1982年12月4日第五届全国人民代表大会第五次会议通过...",
"publish_date": "1982年12月4日",
"document_number": "",
"source_path": "/path/to/temp/md/laws/宪法/中华人民共和国宪法_20180311.md"
},
"content": {
"preamble": "中国是世界上历史最悠久的国家之一...",
"chapters": [
{
"title": "第一章 总纲",
"articles": [
{"title": "第一条", "content": "中华人民共和国是工人阶级领导的..."},
{"title": "第二条", "content": "中华人民共和国的一切权力属于人民。", "sub_items": ["人民行使国家权力的机关是..."]}
]
}
]
},
"validation": {
"is_valid": true,
"has_issues": false,
"errors": [],
"warnings": []
}
}
4.7 文档验证
每个文档解析后都会进行结构验证:
- 必要要素检查:标题是否存在
- 序号连贯性检查:编、章、节、条的编号是否连续(如"第三章"后面不应直接跳到"第五章")
- 目录准确率评估:自动提取的目录与实际结构的匹配度
class ValidationResult:
errors: List[str] # 严重问题(如缺失标题)
warnings: List[str] # 警告(如序号不连贯)
info: List[str] # 信息提示
五、步骤 2:JSON → Markdown(按文种渲染)
5.1 目标
将结构化的 JSON 数据渲染为标准化的 VitePress Markdown 文档,不同文种使用不同的渲染策略。
5.2 渲染流程
class UnifiedLawRenderer(BaseRenderer):
def render(self, data: Dict[str, Any]) -> str:
# 1. 生成 frontmatter(VitePress 配置)
md_lines.append(self.render_frontmatter(metadata))
# 2. 渲染标题
md_lines.append(self.render_title(metadata.get("title", "")))
# 3. 渲染颁布信息
md_lines.append(self.render_passage_info(metadata.get("passage_info", "")))
# 4. 渲染序言(宪法、法典特有)
md_lines.append(self.render_preamble(preamble))
# 5. 渲染章节(动态层级)
md_lines.extend(self.render_chapters(chapters))
# 6. 渲染附录
md_lines.append(self.render_appendix(appendix))
5.3 动态 Heading 级别分配
这是渲染器最精妙的设计。不同法律的层级深度不同,需要动态分配 Markdown heading 级别:
民法典 (5层): 编(h2) > 分编(h3) > 章(h4) > 节(h5) > 条
刑法 (4层): 编(h2) > 章(h3) > 节(h4) > 条
宪法 (3层): 章(h2) > 节(h3) > 条
普通法律(2层): 章(h2) > 条
实现方式:用 › 分隔符编码层级路径,渲染时动态计算 heading 级别:
def _get_heading_level(self, parts: List[str], index: int) -> int:
level = 2 + index # 从 h2 开始
return min(level, 5) # 最高到 h5
5.4 不同文种的渲染差异
法律/条例:条号加粗,首行缩进 2em
**第一条** 为了持续优化营商环境,制定本条例。
意见:中文序号作为 h2 标题,不加粗
## 一、总体要求
### (一)指导思想
司法解释:条号加粗,无缩进(与法律的区别)
**第一条** 为正确审理...
修正案:中文序号加粗
## **一、** 将刑法第...
5.5 VitePress Frontmatter
每个文档都生成 frontmatter,用于配置搜索和目录:
---
title: 优化营商环境条例
category: 法规
doc_type: regulation
publish_date: 2019年10月8日
publisher: ""
document_number: 国务院令第722号
outline: [2, 2] # VitePress 目录范围
source_path: /path/to/...
---
5.6 自动目录分发
渲染后的 Markdown 文件根据 source_path 自动分发到对应目录:
source_path: .../temp/md/laws/法律/经济法/中华人民共和国环境保护税法.md
输出路径: docs-regulations/法律/法律/经济法/中华人民共和国环境保护税法.md
目录映射规则:
SOURCE_DIR_MAP = {
"hr": "人力资源",
"party": "党建",
"union": "工会",
"laws": "法律",
"social_security": "社会保障",
}
六、步骤 3:VitePress 配置生成
6.1 自动生成导航配置
distribute_md.py 根据 docs/ 源目录结构自动生成 VitePress 的完整配置:
def generate_vitepress_config(docs_root, reg_dir, output_dir):
# 1. 扫描目录树
tree = scan_docs_tree(docs_root)
# 2. 生成 sidebar、nav、categories
# 3. 写入配置文件
# - sidebar.json(侧边栏)
# - nav.json(导航栏)
# - categories.json(分类信息)
# - config.ts(VitePress 主配置)
# - index.md(首页)
6.2 三级分类排序
法律板块支持三级分类,每级都有固定排序:
法律/
├── 宪法/ # 一级分类
├── 法律/
│ ├── 宪法相关法/ # 二级分类
│ ├── 民法商法/
│ ├── 行政法/
│ ├── 经济法/
│ ├── 社会法/
│ ├── 生态环境法/
│ ├── 刑法/
│ ├── 诉讼与非诉讼程序法/
│ └── 其他/
├── 监察法规/
├── 行政法规/
├── 地方法规/
└── 司法解释/
6.3 全文搜索配置
VitePress 内置的 MiniSearch 配置:
search: {
provider: 'local',
options: {
miniSearch: {
searchOptions: {
boost: { title: 20, titles: 15, text: 1 }, // 标题权重最高
fuzzy: 0.1, // 模糊匹配
prefix: true // 前缀匹配
}
}
}
}
七、流水线编排
7.1 一键执行
所有步骤通过 orchestrate.py 统一编排:
# 完整流程(从 MD → JSON 开始,默认步骤 1-3)
python3 src/scripts/orchestrate.py
# 包含 DOCX → MD(步骤 0)
python3 src/scripts/orchestrate.py --step 0
# 完整流程 + 验证
python3 src/scripts/orchestrate.py --validate
# 仅执行指定步骤
python3 src/scripts/orchestrate.py --step 1
python3 src/scripts/orchestrate.py --step 2
python3 src/scripts/orchestrate.py --step 3
# 指定 16 线程
python3 src/scripts/orchestrate.py -w 16
# 清理临时文件
python3 src/scripts/orchestrate.py --clean
7.2 目录结构
workspace/
├── docs/ # 原始 DOCX 文档(按分类组织)
│ ├── laws/
│ │ ├── 宪法/
│ │ ├── 法律/
│ │ │ ├── 宪法相关法/
│ │ │ ├── 民法商法/
│ │ │ └── ...
│ │ ├── 行政法规/
│ │ └── 司法解释/
│ ├── social_security/
│ ├── party/
│ ├── union/
│ └── hr/
├── temp/
│ ├── md/ # 步骤 0 输出:基础 Markdown
│ ├── json/ # 步骤 1 输出:结构化 JSON
│ └── final_md/ # 步骤 2 输出:标准化 Markdown
├── docs-regulations/ # 最终输出:VitePress 文档站
│ ├── .vitepress/
│ │ ├── config.ts
│ │ ├── nav.json
│ │ ├── sidebar.json
│ │ └── categories.json
│ ├── 法律/
│ ├── 社会保障/
│ ├── 工会/
│ ├── 党建/
│ └── 人力资源/
└── src/scripts/ # 转换脚本
├── orchestrate.py # 流程编排
├── docx_to_md.py # DOCX → MD
├── md_to_json.py # MD → JSON
├── json_to_md.py # JSON → MD
├── distribute_md.py # VitePress 配置生成
├── doc_config.py # 17 种文种配置
├── validator.py # 文档验证器
├── parsers/ # 17 种文种解析器
│ ├── base.py
│ ├── unified_law.py
│ ├── structure_parser.py
│ ├── opinion.py
│ ├── notice.py
│ ├── judicial.py
│ └── ...
└── renderers/ # 17 种文种渲染器
├── base.py
├── unified_law.py
├── opinion.py
├── notice.py
├── judicial.py
└── ...
八、踩坑记录与关键注意事项
8.1 DOCX 解析阶段
| 问题 | 解决方案 |
|---|---|
| 合并单元格导致内容重复 | 使用 id(cell._tc) 去重 |
| 标题样式名不统一 | 模糊匹配("heading 1" in style_name.lower()) |
| .doc 格式不支持 | 回退到 pandoc 转换 |
| 表格嵌套复杂 | 仅保留基础表格,过滤空行 |
| 编码问题 | 统一使用 UTF-8,Windows 下设置 io.TextIOWrapper |
8.2 MD → JSON 解析阶段
| 问题 | 解决方案 |
|---|---|
| 网页残留信息干扰解析 | clean_web_artifacts() 多层正则清理 |
| 标题被不自然断行 | merge_broken_lines() 多规则合并 |
| 文种误判(如"刑法"vs"刑事诉讼法") | 排除词列表 + 优先级排序 |
| 公告类型误判 | 仅当"公告"作为独立行标题时判定 |
| 目录与正文混淆 | 检测目录结束标志(下一行是"第X条"则目录结束) |
| 颁布信息被当作正文 | 前 10 行内匹配标题/颁布信息的行自动跳过 |
8.3 JSON → MD 渲染阶段
| 问题 | 解决方案 |
|---|---|
| 不同法律层级深度不同 | 动态 heading 级别分配(h2-h5) |
| 条号格式不统一 | 统一为 **第X条** 加粗格式 |
| 款项缩进 | CSS text-indent: 2em |
| VitePress outline 范围 | 通过 frontmatter outline: [2, 5] 配置 |
| 文件路径分发 | 从 source_path 解析目标路径,按 SOURCE_DIR_MAP 映射 |
8.4 VitePress 构建阶段
| 问题 | 解决方案 |
|---|---|
| 1500+ 文件构建慢 | 分批构建,增量更新 |
| 搜索索引过大 | 配置 chunkSizeWarningLimit: 1000 |
| 侧边栏过长 | 使用 collapsed: true 折叠子目录 |
| 中文搜索不准确 | 配置 fuzzy: 0.1 + prefix: true |
九、最终效果
9.1 文档统计
| 分类 | 文档数量 |
|---|---|
| 法律 | 1177 件 |
| 社会保障 | 30 件 |
| 工会 | 2 件 |
| 党建 | 若干 |
| 人力资源 | 若干 |
| 合计 | 1500+ 件 |
9.2 渲染效果示例
宪法(法律类型,有序言):
---
title: 中华人民共和国宪法
doc_type: law
outline: [2, 5]
---
# 中华人民共和国宪法
**1982年12月4日第五届全国人民代表大会第五次会议通过...**
(序言内容...)
## 第一章 总纲
**第一条** 中华人民共和国是工人阶级领导的...
**第二条** 中华人民共和国的一切权力属于人民。
优化营商环境条例(条例类型):
---
title: 优化营商环境条例
doc_type: regulation
outline: [2, 2]
document_number: 国务院令第722号
---
# 优化营商环境条例
**2019年10月8日国务院第66次常务会议通过...**
**第一条** 为了持续优化营商环境...
## 第二章 市场主体保护
**第十条** 国家坚持权利平等...
十、总结
这套文档转换流水线的核心设计理念是 “解析与渲染分离”:
- DOCX → MD:只做格式转换,保持"干净"
- MD → JSON:负责"理解"文档——识别文种、提取结构、验证完整性
- JSON → MD:负责"表达"文档——按文种差异化渲染、生成 VitePress 配置
这种设计使得:
- 新增文种只需添加一对解析器/渲染器,不影响其他环节
- 修改渲染样式不需要重新解析文档
- JSON 中间格式可以作为数据源用于其他用途(如全文搜索索引、知识图谱)
整个系统处理 1500+ 件法律法规文档,覆盖 17 种文种,最终构建出一个支持全文搜索、分类浏览、层级导航的规章制度文档站。
本文基于实际项目代码整理,项目使用 Python + VitePress + Express 技术栈。