一、背景与动机
新 SOLO 开放内测,社区里「新SOLO初体验」标签下瞬间涌入了大量帖子。
作为用户,我很好奇:大家都在聊什么?哪些方向最热门?用户的真实反馈集中在哪些方面?
于是我做了一个决定——用 SOLO 本身来调查 SOLO 的社区讨论情况,算是"以魔法打败魔法"了。整个过程使用 MTC(Manager → Thinker → Coder)模式完成,从数据采集、清洗分析到报告输出,一条龙跑通。
下面把完整流程分享出来,供大家参考。
二、MTC 模式全流程拆解
Step 1:需求定义(Manager 阶段)
打开 SOLO 后,我输入了一段清晰的需求描述:
爬取 TRAE 论坛 使用新SOLO初体验标记的话题 下【新SOLO初体验】标签的所有文章,获取标题、摘要、回复数、浏览量、发布时间等信息,然后对文章进行主题分类统计,最终输出一份结构化的分类统计报告。
要点:需求描述中包含了目标 URL、数据字段要求、分析维度和期望输出,这样 SOLO 可以直接理解并拆解任务。
Step 2:方案规划(Thinker 阶段)
SOLO 收到需求后,自动进行了任务拆解:
- 访问目标页面 → 通过浏览器工具打开论坛标签页
- 发现数据接口 → 识别出论坛基于 Discourse 架构,存在 JSON API(
/tag/46-tag/46.json) - 多页数据抓取 → 通过 API 分页请求,获取全部文章数据(共 2 页,39 篇文章)
- 数据解析与存储 → 提取每篇文章的 title、excerpt、reply_count、views、created_at 等字段
- 主题分类 → 基于标题和摘要内容,对 39 篇文章进行语义分类
- 报告生成 → 输出包含分类统计、文章明细、分类详情的 Excel 报告
这个拆解过程基本符合我作为工程师的思路,尤其是自动发现 Discourse JSON API 这一步,省去了我手动分析页面结构的时间。
Step 3:执行与输出(Coder 阶段)
SOLO 按照规划逐步执行:
数据采集阶段:
- 首先通过浏览器打开目标页面,获取页面快照,分析 DOM 结构
- 识别出 Discourse 论坛架构后,切换到 JSON API 方式获取数据
- 分页请求
/tag/46-tag/46.json?page=0和page=1,共获取 39 篇文章的完整数据
数据分析阶段:
- 对每篇文章的标题和摘要进行关键词匹配和语义分析
- 将 39 篇文章分为 9 个类别(详见下文)
- 统计每个类别的数量、占比、总回复数、总浏览量
报告输出阶段:
- 使用 openpyxl 生成 Excel 报告,包含 3 个工作表
- 应用了专业的表格样式(斑马纹、KPI 高亮、分类色标等)
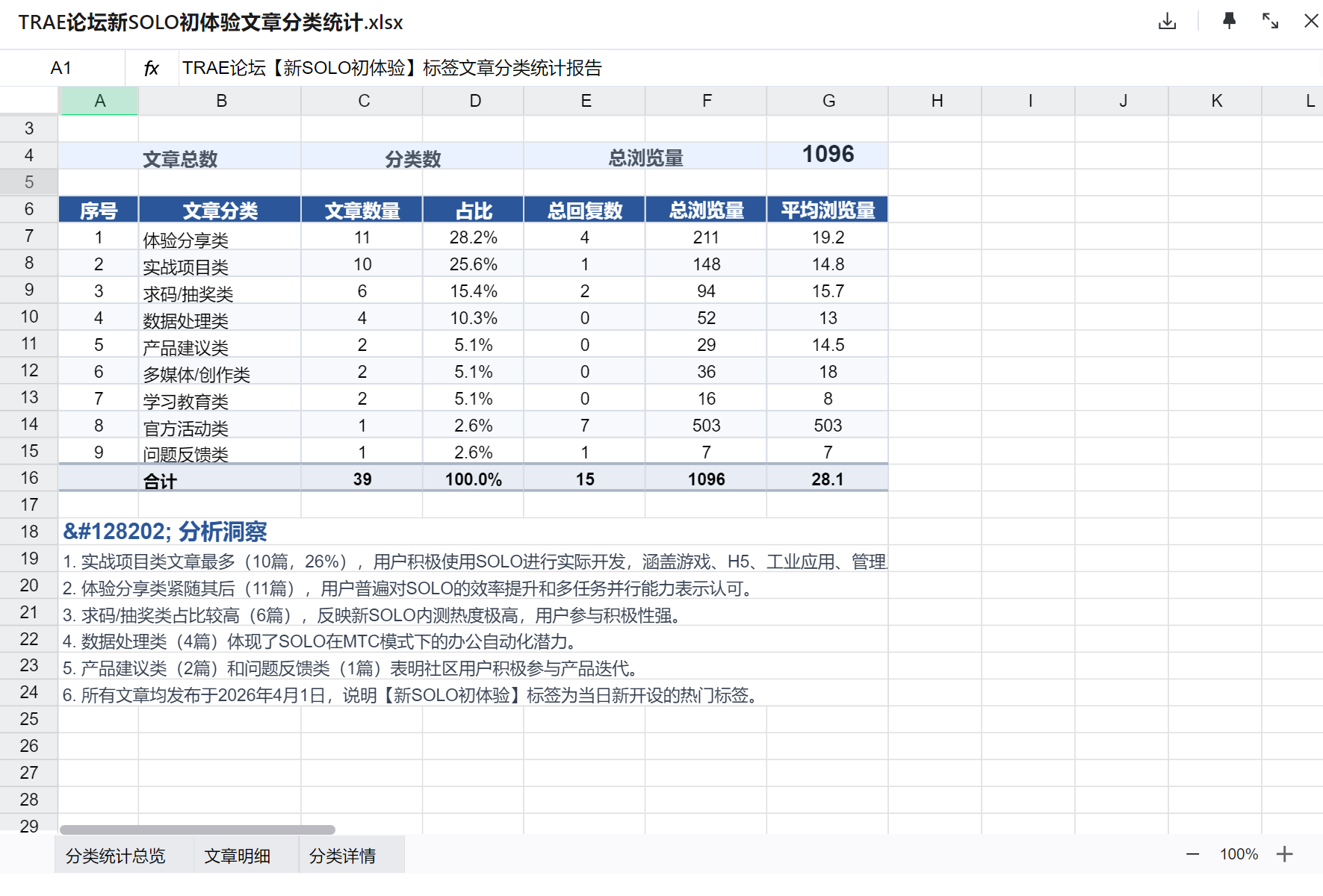
三、调查结果速览
3.1 总体数据
| 指标 | 数值 |
|---|---|
| 文章总数 | 39 篇 |
| 分类数 | 9 个类别 |
| 总浏览量 | 1,096 次 |
| 总回复数 | 17 条 |
| 发布时间范围 | 2026-04-01 当天 |
所有文章均发布于同一天,说明「新SOLO初体验」标签是当天新开设的热门标签,社区参与度非常高。
3.2 分类统计
| 分类 | 数量 | 占比 | 代表性内容 |
|---|---|---|---|
| 体验分享类 | 11篇 | 28.2% | 效率测评、功能对比、使用感受 |
| 实战项目类 | 10篇 | 25.6% | 游戏开发、H5应用、工业标定、管理系统 |
| 求码/抽奖类 | 6篇 | 15.4% | 求邀请码、参与抽奖活动 |
| 数据处理类 | 4篇 | 10.3% | A股复盘、报告生成、表格整理 |
| 产品建议类 | 2篇 | 5.1% | 功能建议、同步问题反馈 |
| 多媒体/创作类 | 2篇 | 5.1% | 短剧关键帧、视频生成 |
| 学习教育类 | 2篇 | 5.1% | C语言学习、课堂大作业 |
| 官方活动类 | 1篇 | 2.6% | 官方抽奖活动帖 |
| 问题反馈类 | 1篇 | 2.6% | Bug 反馈 |
3.3 几个有意思的发现
发现一:实战项目覆盖面广
10 篇实战项目类文章涵盖了非常多样的场景:
- AI 原生视觉小说游戏(MTC 模式开发)
- 儿童字典 H5 应用
- 仿流浪地球 MOSS 浏览器管理系统
- 工业标定应用
- 客流监控告警系统重构
- 护肤品品牌市场调研 + LOGO 设计 + 官网搭建
- 地铁上用手机开发项目
这说明 SOLO 的 MTC 模式确实能处理跨领域、跨技术栈的复杂任务。
发现二:体验分享类评价正面居多
11 篇体验分享中,用户普遍认可的关键点:
- 多任务并行速度显著提升(有用户反馈从 5 分钟缩短到 1.5 分钟)
- 界面布局更简洁,三栏式设计直观
- 自动调用 Skill、自动创建 PRD 等文档
- 遇到问题能自动尝试不同方案
发现三:求码帖占比不低
6 篇求码/抽奖类文章(15.4%),说明新 SOLO 的内测资格非常抢手,社区用户参与热情极高。
四、技术细节补充
4.1 为什么选择 JSON API 而不是直接解析 HTML?
论坛基于 Discourse 架构,直接提供了结构化的 JSON 接口。SOLO 在执行过程中自动发现了这一点:
GET /tag/46-tag/46.json → 返回 30 条话题
GET /tag/46-tag/46.json?page=1 → 返回 9 条话题
相比解析 HTML DOM,JSON API 的优势:
- 数据结构清晰,字段语义明确
- 无需处理动态渲染和懒加载
- 分页参数简单直接
4.2 分类策略
分类采用了基于关键词匹配 + 语义理解的混合策略,主要依据标题和摘要中的特征词:
- 含"实战项目"“开发”"实现"→ 实战项目类
- 含"体验心得"“测评”"感受"→ 体验分享类
- 含"邀请码"“求码”"抽奖"→ 求码/抽奖类
- 含"数据"“报告”“复盘”"表格"→ 数据处理类
- 含"建议"“希望”"改进"→ 产品建议类
- 含"视频"“短剧”"关键帧"→ 多媒体/创作类
- 含"学习"“课堂”"大作业"→ 学习教育类
4.3 报告生成
最终输出了一份包含 3 个工作表的 Excel 报告:
- 分类统计总览 — KPI 指标 + 分类汇总表 + 分析洞察
- 文章明细 — 全部 39 篇文章按浏览量排序
- 分类详情 — 按类别分组展示,每组独立色标
五、个人心得
MTC 模式的优势
- 任务拆解能力:只需描述目标,SOLO 会自动规划执行步骤,不需要我逐步下达指令
- 工具选择智能:自动识别 Discourse API、自动选择 openpyxl 生成 Excel,这些决策都不需要人工干预
- 容错与自修复:执行过程中遇到 JSON 解析错误时,能自动调整请求参数重试
一些不足
- 分类精度有限:基于关键词的分类在边界情况下不够精确,比如"体验帖中夹杂产品建议"的情况,需要人工二次校准
- 无法获取文章全文:API 默认只返回摘要,要做更深入的内容分析需要逐篇请求详情接口
- 大数据量场景未验证:39 篇文章规模较小,如果是数千篇的场景,可能需要考虑分批处理和性能优化
总结
用 SOLO MTC 模式做社区话题调查,从需求输入到报告输出,整个过程流畅且高效。MTC 模式最大的价值在于降低了"从想法到执行"的门槛——你只需要说清楚"我要什么",它会帮你规划"怎么做"并自动执行。
对于社区运营、市场调研、竞品分析这类需要"采集→分析→输出"链路的任务,MTC 模式确实是一个值得尝试的生产力工具。

以上调查基于 2026-04-01 当天的社区数据,如需最新数据可随时用相同方法更新。
