【标签】 学习工作
【标题】 学习工作 + TorchBlox:可视化深度学习模型设计器
0. 先和大家打个招呼 
我是一名深度学习方向的学习者,平时经常要搭各种网络结构做实验。
我和 TRAE 的故事
说实话,在遇到 TRAE 之前,「自己做一个完整的可视化工具」这种事我想都不敢想。脑子里有想法,但前端画布交互、形状推断、代码生成这些事情,每一件单独拎出来都够我啃半个月文档。
开始用 TRAE 之后,我发现了一件神奇的事——
原来把需求"说人话"给它听,它真的能听懂。
比如我最开始就是这样跟它说的:
“我想做一个可视化拖拽的 PyTorch 模型设计器,左边是模块库,中间是画布,拖拽连线,右边显示参数和形状,底部实时生成代码”
就这么一段话,TRAE 就帮我搭起了整个项目的骨架:SVG+DOM 混合画布、节点渲染、端口连线、拓扑排序、形状推断、代码生成,一气呵成。
哪一步让我觉得「原来这么简单」?
当我想给工具加上"自定义模块"功能(把几个节点打包成一个可复用模块)时,我以为要重构很多东西。结果我只是跟它说:
“加入自定义模块,可以把画布中的数个模块打包成一个自定义模块,可复用,可自定义参数,自动处理维度”
它就把多选交互、打包弹窗、子图持久化、子类代码生成、形状推断传播全部做好了,而且自动注册到侧边栏的"自定义模块"分类里。
它帮我跨过的那个坎
最让我头疼的是代码生成里的变量命名策略。残差连接、跳连这些场景,如果简单复用 x 变量,分支点会被覆盖导致结果错误。我把问题贴给 TRAE,它不仅帮我设计了"主链复用 x、分支点用命名变量"的策略,还解释了为什么要统计每个节点的消费者数量来决定是否复用。后来我再遇到类似问题,就知道该怎么描述了。
真实感受
用 TRAE 做开发,就像请了一个 24 小时在线的全栈技术助手。不需要记 API、不需要翻文档,把需求说清楚就行。
当然它也不是万能的,有时候生成的代码需要微调,但比起自己从零写,有问题能随时问、随时改,这个体验已经完全超出我的预期了。
1. Demo 简介
是什么
TorchBlox 是一个可视化拖拽式深度学习模型设计器,纯前端 Web 应用(单页 HTML + 原生 JS),零依赖、零构建、零部署成本。用户像搭积木一样拖拽 PyTorch 模块、连线构建网络,工具自动推断张量形状并实时生成可运行的 PyTorch 代码。
面向谁
-
深度学习初学者(直观理解网络结构如何影响输出尺寸)
-
研究人员/算法工程师(快速搭建原型、复用自定义模块)
-
教学场景(课堂演示 CNN/RNN/Transformer 结构)
主要功能 & 界面展示
① 71 个 PyTorch 模块 + 拖拽连线设计
左侧模块库按分类组织(卷积、池化、归一化、激活、注意力、RNN 等),拖拽到画布,端口连线即可构建网络。覆盖 PyTorch torch.nn 主要模块。
② 自动形状推断 + 实时代码生成
连线后自动运行拓扑排序 + 形状推断,每个节点显示输出张量形状(如 [1, 64, 56, 56])。底部代码栏实时生成完整的 nn.Module 类代码,支持残差连接、多输入、多输出。
③ 自定义模块打包复用
Shift+点击多选节点 → 打包为自定义模块,自动处理维度推断和子类代码生成。打包后的模块出现在侧边栏"自定义模块"分类,可拖拽复用。
④ AI 代码导入(DeepSeek 集成)
导入 .py 文件或粘贴 PyTorch 代码,AI 分析结构后自动转换为积木图。逆向工程现有模型的利器。
⑤ 模板系统 + 多格式导出
内置 LeNet-5、ResNet 残差块、Transformer Encoder 三个模板。支持保存当前设计为用户模板。一键导出 Python 脚本 / Jupyter Notebook / ONNX 导出脚本 / TorchScript 脚本。
网页截图:

2. Demo 创作思路
灵感来源
学习深度学习时,我经常对着论文里的网络结构图发呆——那些方块和箭头看起来很直观,但要变成可运行代码,就得手动查每个层的参数、计算输出尺寸、处理维度匹配。我想:为什么不能反过来?先画图,再生成代码?
想解决的问题
-
学习门槛高:初学者难以直观理解 Conv2d 的 kernel_size/stride/padding 如何影响输出尺寸
-
手写代码易错:维度不匹配是深度学习最常见的 bug,调试耗时
-
结构复用难:常用的残差块、注意力模块每次都要重写,没有可视化复用机制
-
逆向分析难:拿到别人的
.py代码,想快速理解网络结构很不直观
为什么做这个方向
深度学习模型设计是学习和研究中的高频刚需场景,痛点明确、流程可标准化。选择纯前端单页应用形式是为了让用户零部署、零成本快速体验——双击 HTML 文件即可完整使用所有功能,数据保存在浏览器 localStorage。
技术取舍:
-
纯原生 JavaScript(无 React/Vue 框架依赖),确保单页可运行、加载快
-
SVG + DOM 混合画布,SVG 画连线、DOM 画节点,兼顾性能和交互
-
Kahn 拓扑排序保证形状推断和代码生成的正确顺序
-
DeepSeek API 采用 OpenAI 兼容格式,
response_format: json_object强制结构化输出
3. Demo 体验地址
torchblox.zip (220.2 KB)
4. TRAE 实践过程
关键开发对话与步骤
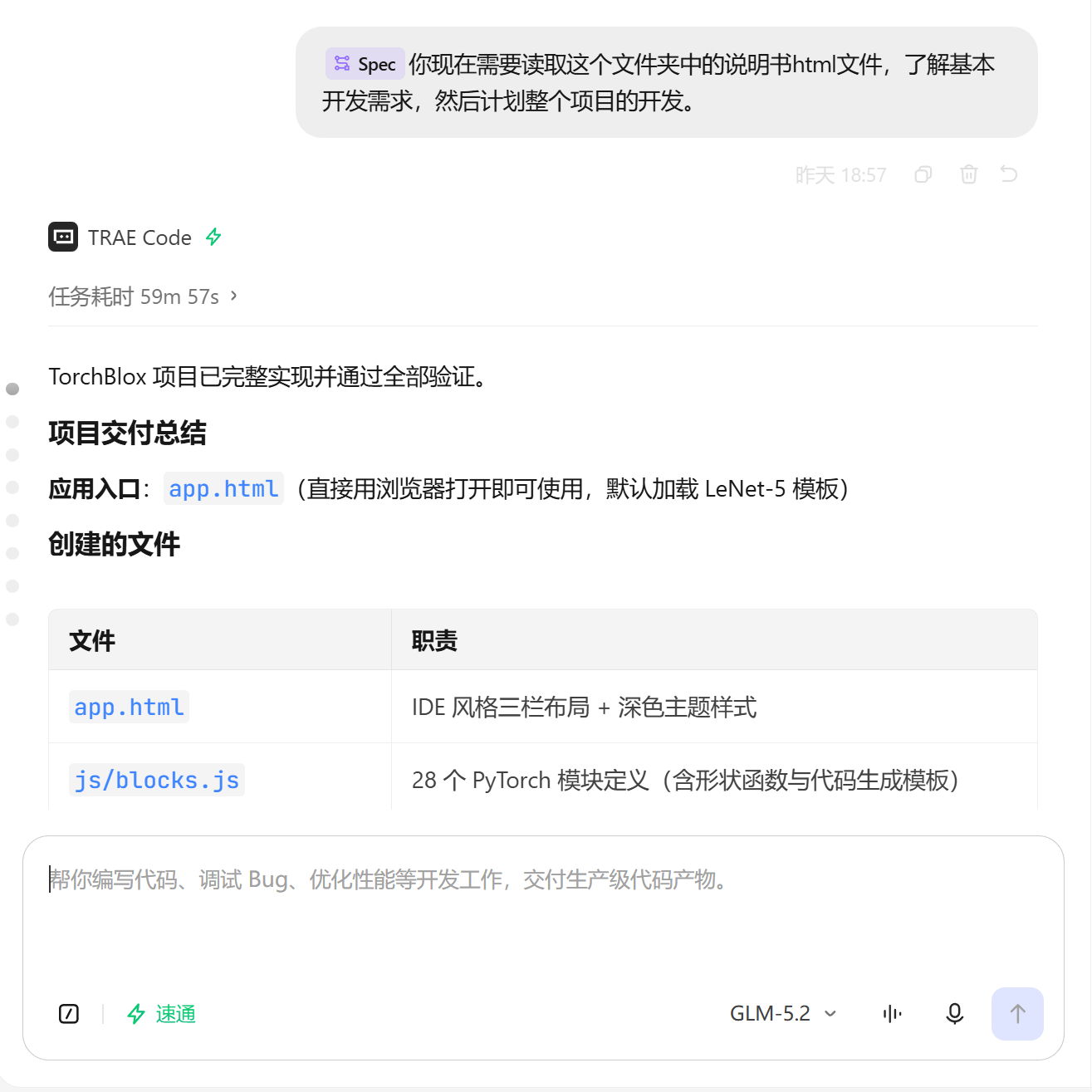
步骤 1:项目规划与架构设计
在 TRAE 中读取说明书 HTML 文件,描述需求:「读取这个文件夹中的说明书 html 文件,了解基本开发需求,然后计划整个项目的开发。」
TRAE 给出的方案要点:
-
单页应用架构(app.html + 7 个 JS 模块)
-
SVG + DOM 混合画布方案
-
模块定义表(BLOCK_DEFS)+ 形状推断引擎 + 代码生成器三层分离
-
事件总线 + 状态管理(TB 全局对象)
【截图:
】 【Session ID:1026265556464131:c8cf9a67bbaba59d43bbf8a410da3367_6a33cf2a2af7ad01f1f7a853.6a33cf2a2af7ad01f1f7a856.6a33cf2a2af7ad01f1f7a854:TRAE Work CN.0.1.21.no_sid.no_ppe.T(2026/6/18 18:57:46)】
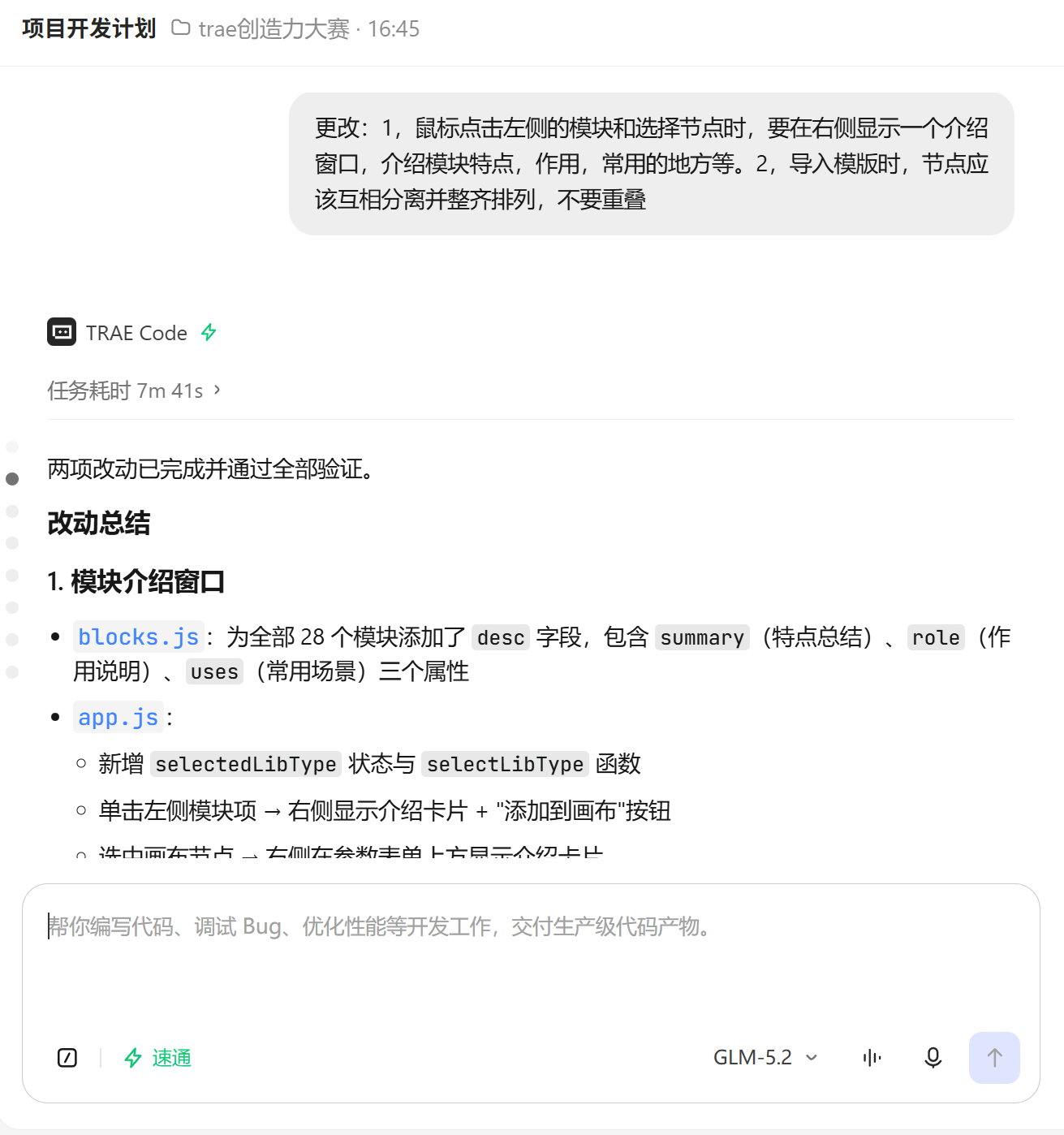
步骤 2:模块介绍窗口 + 模板自动布局
我向 TRAE 提出需求:
“鼠标点击左侧的模块和选择节点时,要在右侧显示一个介绍窗口,介绍模块特点,作用,常用的地方等。导入模版时,节点应该互相分离并整齐排列,不要重叠”
TRAE 一次性完成了两件事:
模块介绍卡片:为每个模块设计了 desc 字段(summary/role/uses 三段式),点击侧边栏模块或选中画布节点时,右侧属性面板优先展示介绍卡片,包含"作用"和"常用场景"两个区块。属性面板渲染逻辑改为优先级判断:多选 > 单选节点 > 侧边栏预览 > 模型设置。
模板自动布局:实现了基于 Kahn 拓扑排序的分层布局算法——先按入度做最长路径分层,再按层分组垂直居中排列。节点宽度 160px + 列间距 80px,行间距 50px,确保任何模板加载后节点都整齐不重叠。加载模板后自动调用 fitView() 适应视图。
【截图:
】 【Session ID:1026265556464131:f5b687b099eb506969831d4728606938_6a33cf2a2af7ad01f1f7a853.6a33df522af7ad01f1f7a9be.6a33df522af7ad01f1f7a9bc:TRAE Work CN.0.1.21.no_sid.no_ppe.T(2026/6/18 20:06:42)】
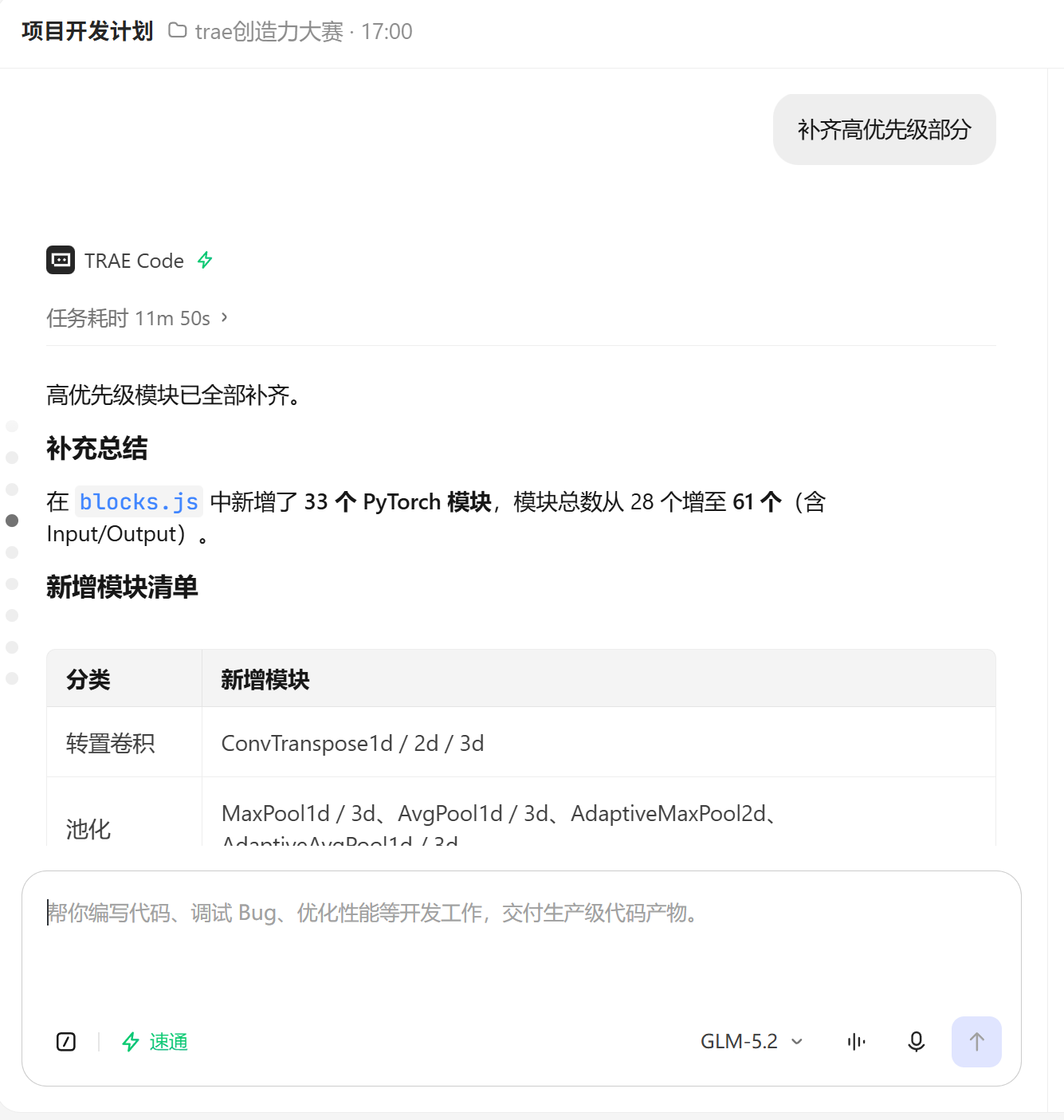
步骤 3:补齐 71 个 PyTorch 模块
我问 TRAE:
“pytorch 中所有模型层都支持吗?检查一下”
TRAE 对比 PyTorch 官方文档,发现当时只实现了约 38 个模块,缺失 33 个高优先级模块。我接着说:
“补齐高优先级部分”
TRAE 一次性补齐了 ConvTranspose1d/2d/3d、MaxPool1d/3d、AvgPool1d/3d、AdaptiveMaxPool2d、AdaptiveAvgPool1d/3d、BatchNorm3d、InstanceNorm1d/2d/3d、SyncBatchNorm、ELU/PReLU/ReLU6/SELU/Hardswish/Hardsigmoid/Hardtanh/LogSoftmax/Softmin、RNN/RNNCell/LSTMCell/GRUCell、TransformerEncoderLayer/DecoderLayer/Encoder/Decoder/Transformer、Embedding/EmbeddingBag、Upsample/PixelShuffle/PixelUnshuffle、Dropout2d/AlphaDropout、Bilinear/Identity/LazyLinear 等模块。
每个模块都包含完整的 shapeFn(形状推断)、codegenInit(实例化代码)、codegenForward(前向调用代码)和中文介绍(summary/role/uses)。最终模块库覆盖 71 个 PyTorch torch.nn 主要模块。
【截图:
】 【1026265556464131:c18df04109181443bbba665ef0cc1b2c_6a33cf2a2af7ad01f1f7a853.6a33e2262af7ad01f1f7aa48.6a33e2262af7ad01f1f7aa46:TRAE Work CN.0.1.21.no_sid.no_ppe.T(2026/6/18 20:18:46)】
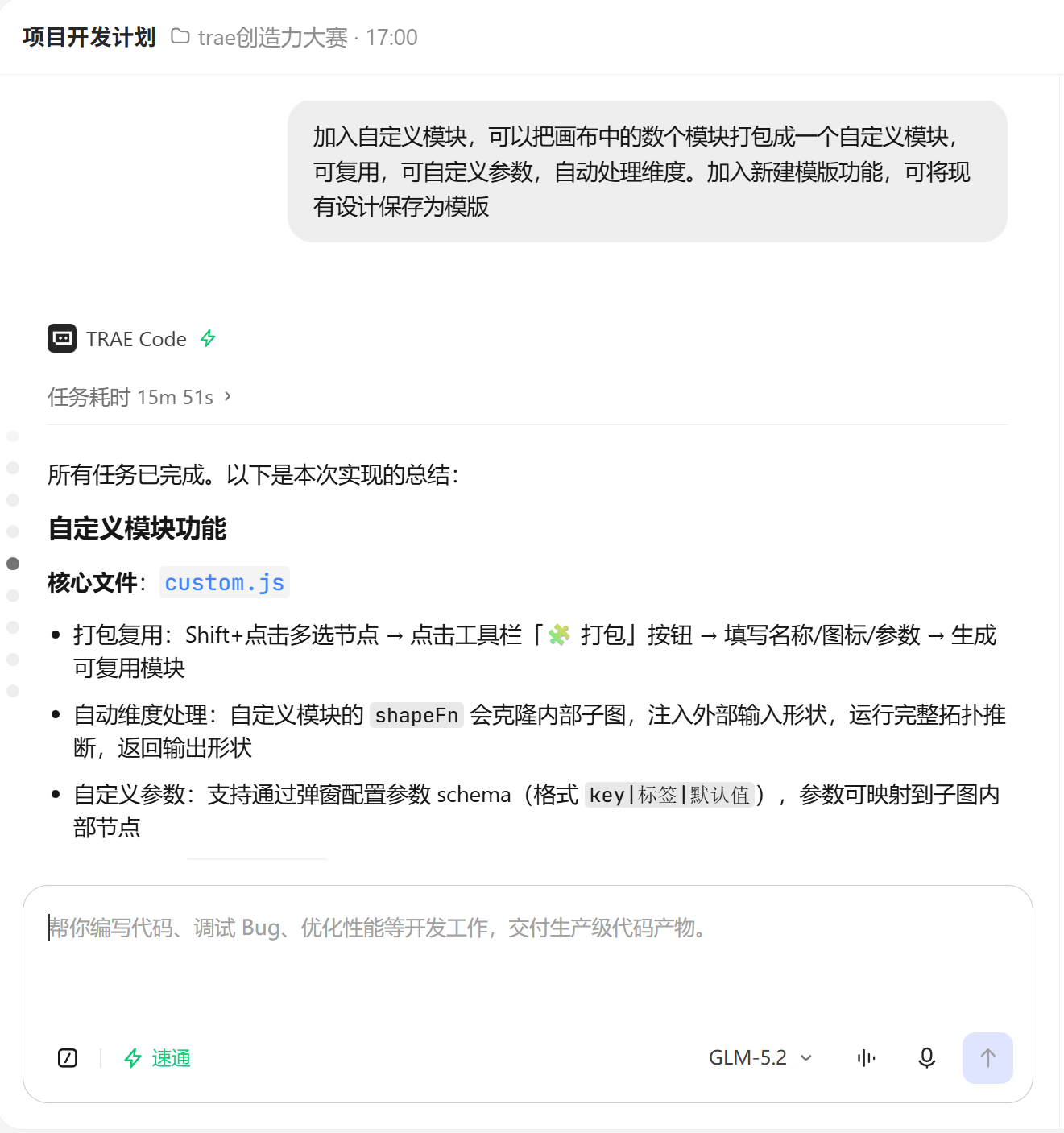
步骤 4:自定义模块打包 + 模板保存功能
我向 TRAE 提出需求:
“加入自定义模块,可以把画布中的数个模块打包成一个自定义模块,可复用,可自定义参数,自动处理维度。加入新建模版功能,可将现有设计保存为模版”
TRAE 实现了完整的自定义模块系统:
多选交互:Shift+点击切换多选,橙色边框高亮,右侧属性面板切换为"多选模式"显示打包按钮。
打包流程:收集选中节点和内部边 → 识别 input/output 节点作为端口绑定 → 若无 input 节点自动添加并连接到子图入口 → 若无 output 节点取子图末端节点 → 保存到 localStorage → 注册到 BLOCK_DEFS 的"自定义模块"分类。
自动处理维度:自定义模块的 shapeFn 会克隆内部子图,把外部输入形状注入到内部 input 节点,运行完整的拓扑排序和形状推断,返回 outputBindings 节点的输出形状。
子类代码生成:codegenInit 返回类名(如 CustomConvRelu)并注册到 _pendingCustomClasses,主类生成时在前面插入子类定义(class CustomConvRelu(nn.Module)),内部 input 节点映射为 forward 参数,output 绑定映射为 return。
模板保存:模板下拉菜单新增"![]() 保存为模板…",用户模板持久化到 localStorage,可一键加载或删除。
保存为模板…",用户模板持久化到 localStorage,可一键加载或删除。
【截图:
】 【Session ID:1026265556464131:aa9d5445f67e4a71dcb14c0500c7377d_6a33cf2a2af7ad01f1f7a853.6a33e67c2af7ad01f1f7aa8a.6a33e67c2af7ad01f1f7aa88:TRAE Work CN.0.1.21.no_sid.no_ppe.T(2026/6/18 20:37:16)】
步骤 5:AI 代码导入功能
用户需求:「加入 ai 功能,接入 deepseek 的 api,用户可以导入 py 程序,发给 ai 分析结构,返回成积木格式」
TRAE 实现了:
-
DeepSeek API 集成(OpenAI 兼容格式)
-
动态构建模块目录作为 system prompt
-
response_format: json_object强制 JSON 输出 -
响应解析 + 图规范化(未知模块替换为 Identity、自动补全 input/output)
【截图:

】 【1026265556464131:57c178faa787bcf9e019c59c418c388c_6a33cf2a2af7ad01f1f7a853.6a34f8523d6a5c62f19b076b.6a34f8523d6a5c62f19b0769:TRAE Work CN.0.1.21.no_sid.no_ppe.T(2026/6/19 16:05:38)】
开发心得总结
1. 描述需求要具体 “加入自定义模块” 比 “加个新功能” 效果好 10 倍。把功能行为、交互方式、预期效果都说清楚,TRAE 一次就能做对。
2. 复杂功能分步推进 71 个模块、AI 集成这种大任务,拆成"先检查缺失 → 再补齐 → 再验证"的小步骤,每步都跑测试确认,避免积压问题。
3. 让 TRAE 解释"为什么" 遇到代码生成变量命名这种设计决策,不只是让它写代码,还要问"为什么这样设计"。它解释的消费者统计思路,让我真正理解了数据流分析。
4. 测试驱动验证 每个核心功能都让 TRAE 写测试脚本(Node.js 环境 mock 浏览器),25 项测试覆盖自定义模块、AI 解析、模板代码生成,确保重构不破坏已有功能。
社区报名帖链接: