【标题】生活娱乐 · 记忆罐头 — 用语音记录每一天,AI 帮你整理成人生故事书
============================================================
【正文】
============================================================
一、Demo 简介
“记忆罐头"是一款基于微信小程序的语音日记应用。灵感来源于"把记忆像罐头一样封装保存”——你只需开口说话,AI 会自动将语音转成文字、整理润色、识别心情并提取标签,每一天的记录最终自动编织成一本属于你的"人生故事书"。
====================

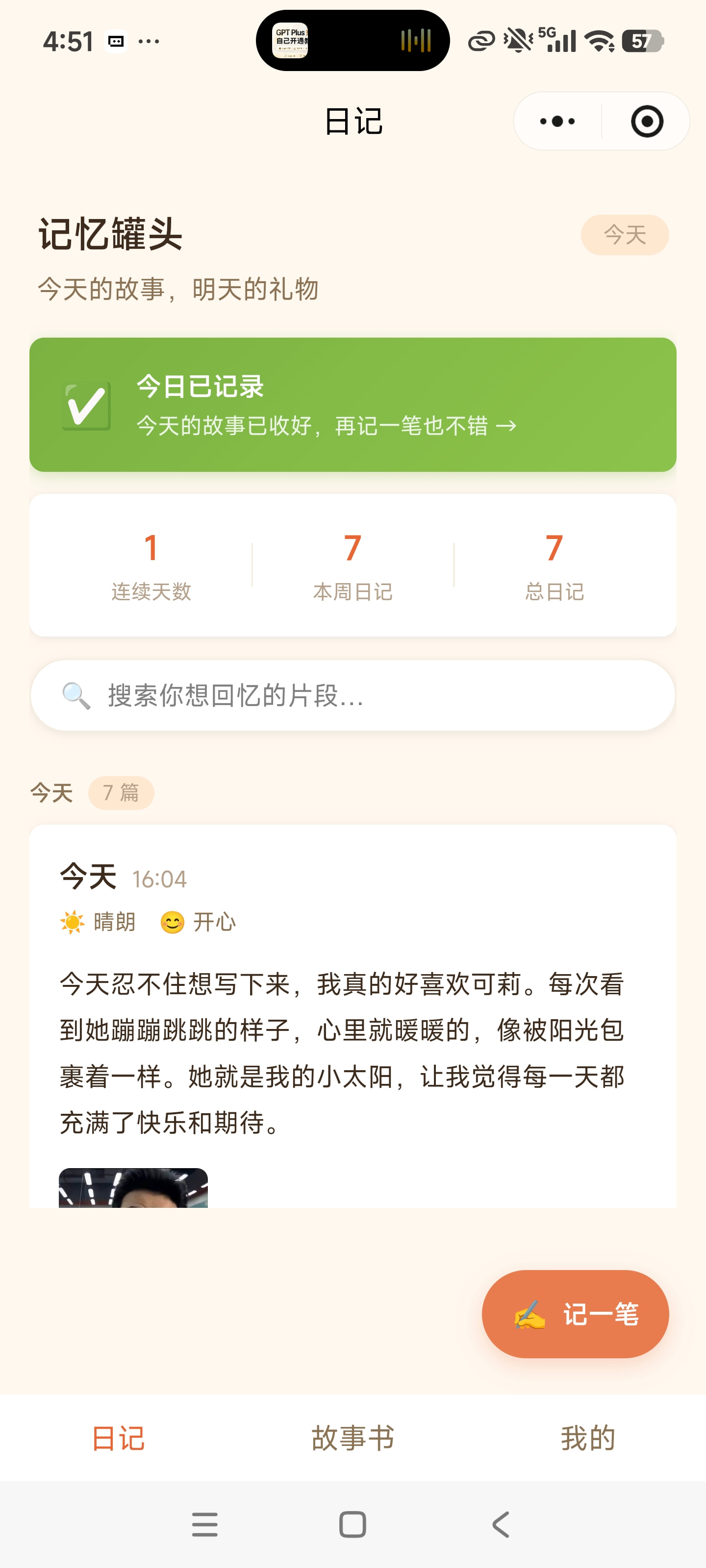
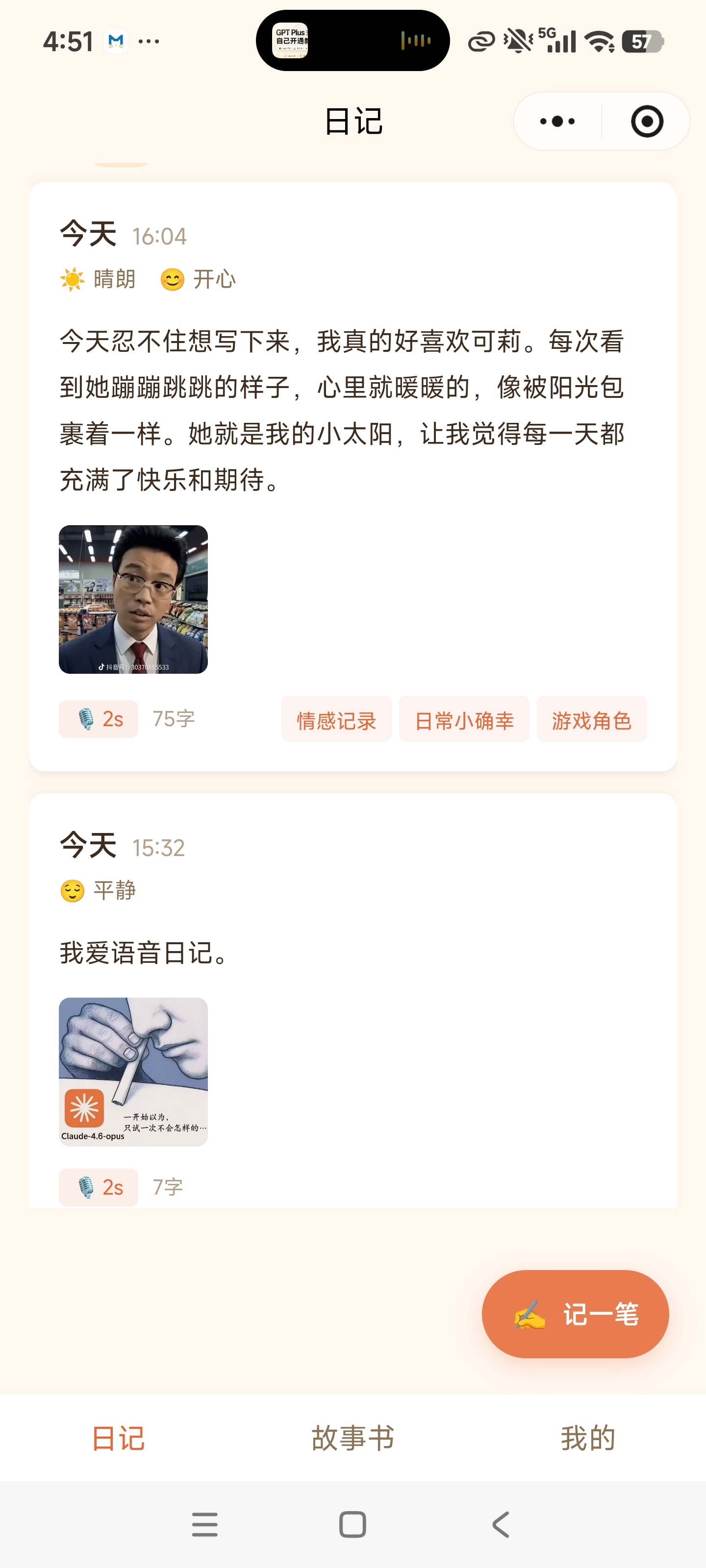
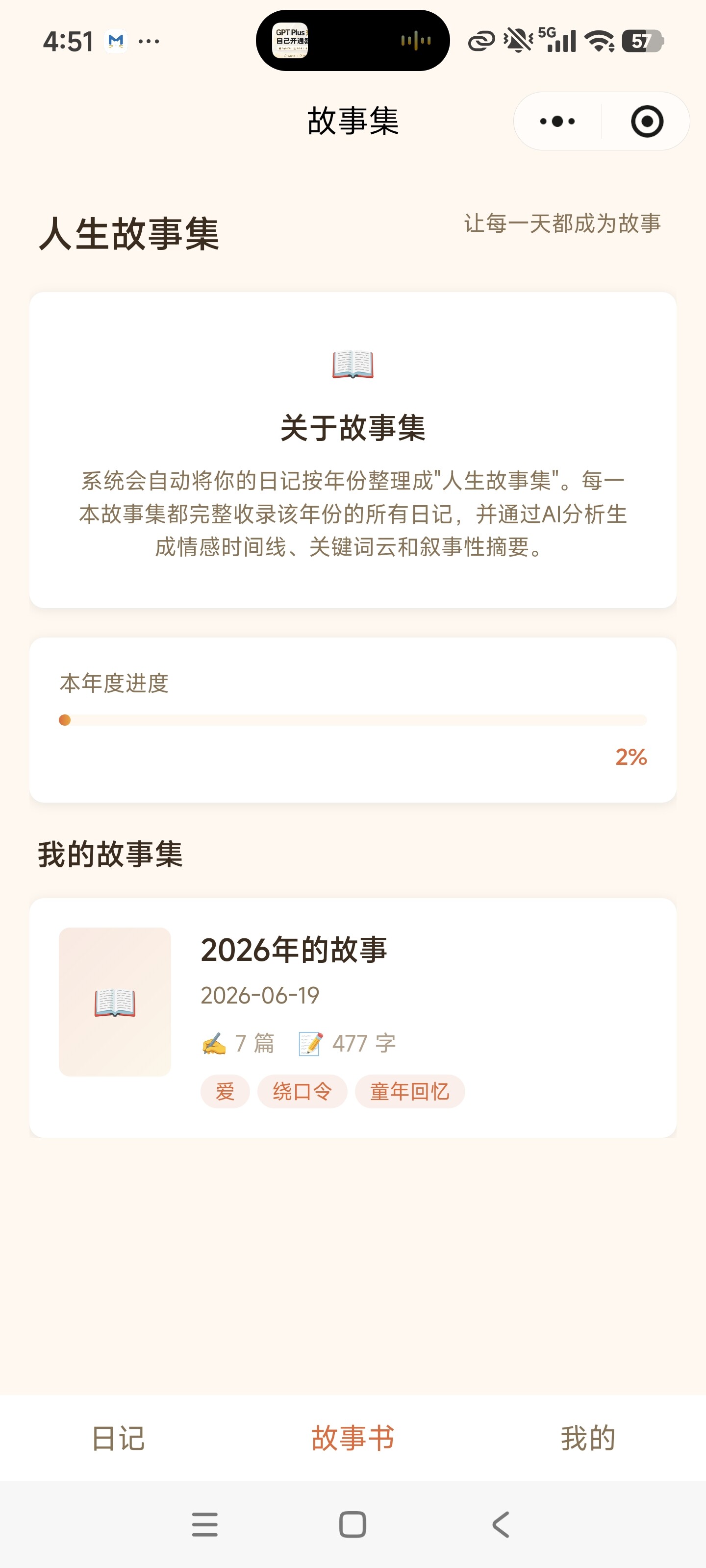
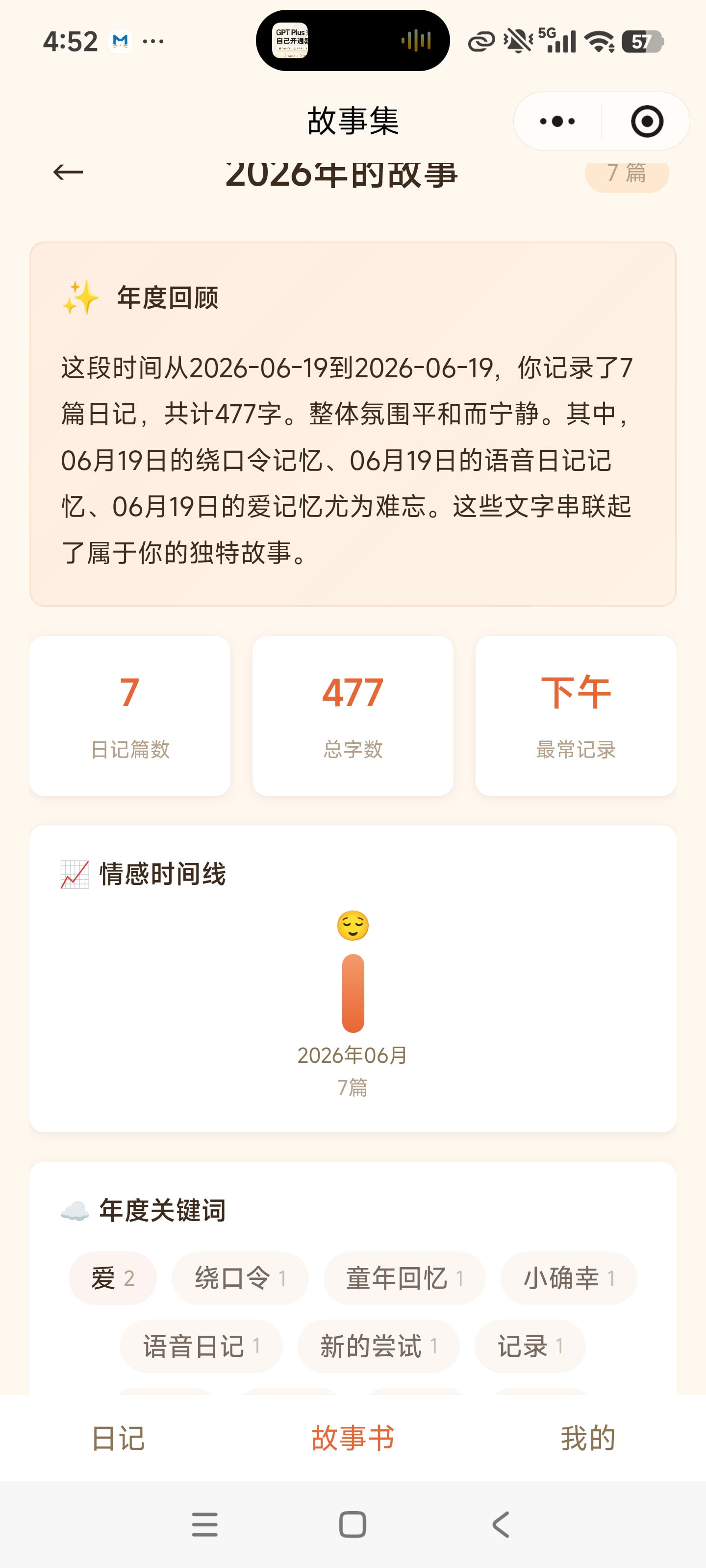
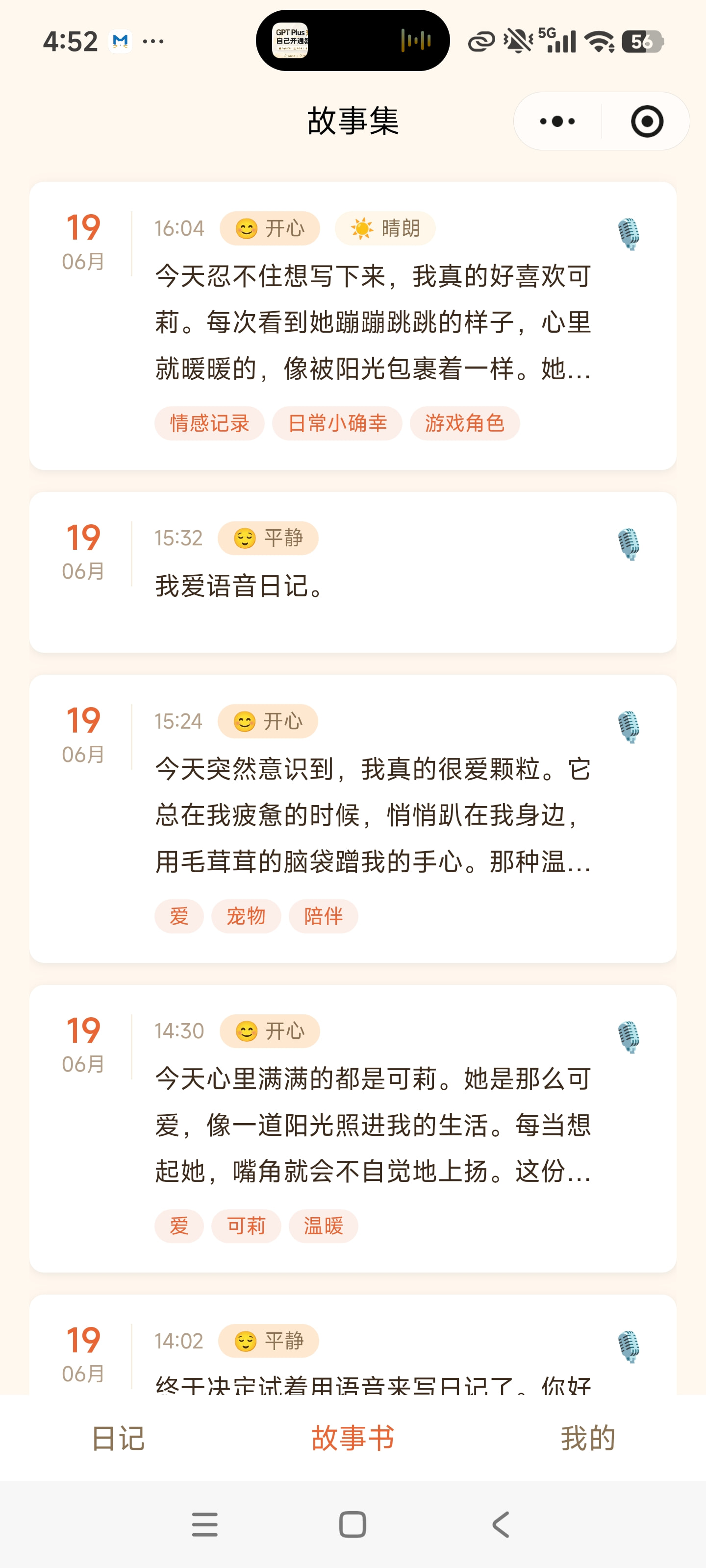
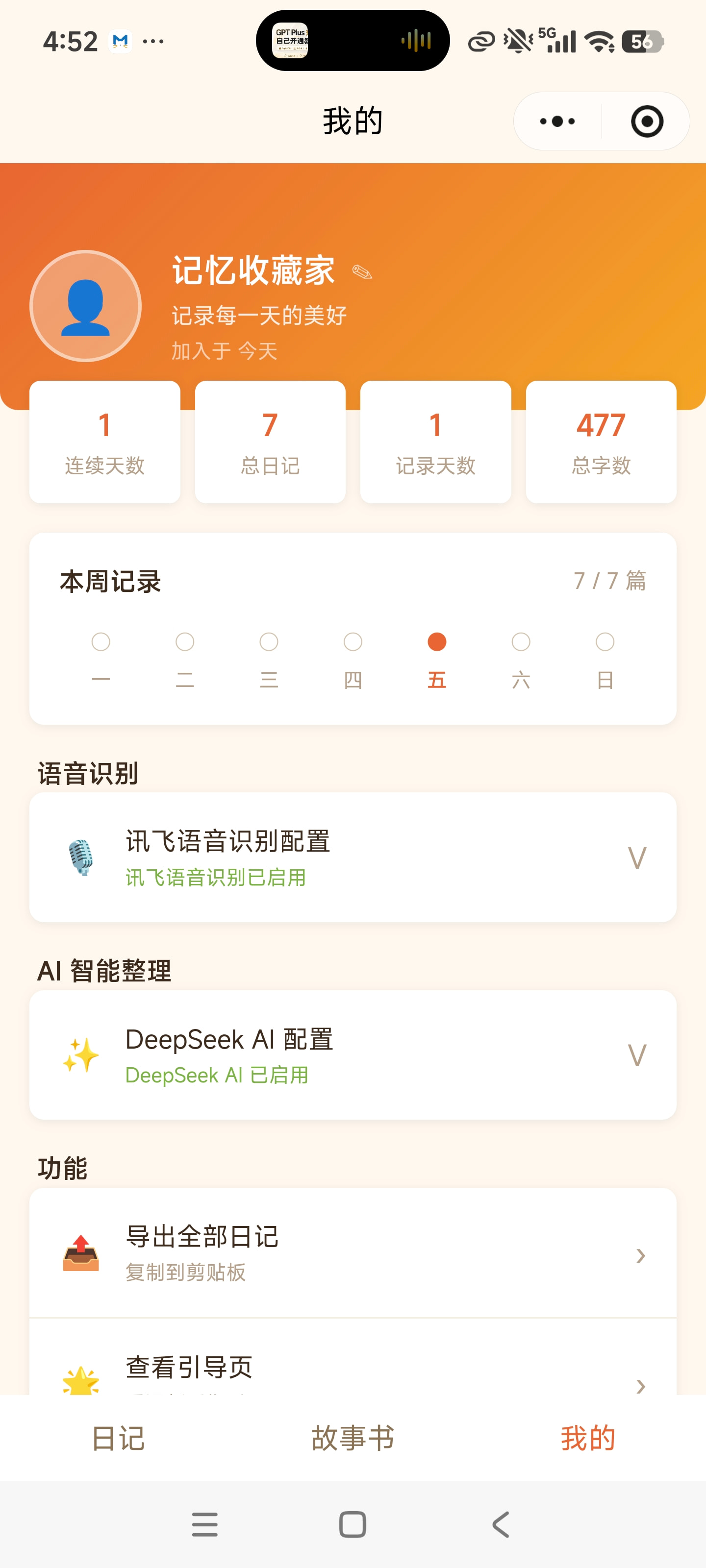
图注:记忆罐头核心界面——首页日记时间线(左)| 语音录制与心情标记(中)| 人生故事书(右)
【目标用户】
核心用户是想记录生活但觉得"写日记太麻烦"的年轻人——尤其适合那些每天有想法、有感悟,却因为打字慢、不知从何写起而放弃记录的人。他们需要的不是另一个笔记工具,而是一个足够轻量、足够智能、还能带来仪式感的记录方式。
【主要功能】
-
语音日记 · 自动转文字
长按录音按钮说话,说完即停。语音自动转成文字,还支持添加心情、天气和照片,让每篇日记都立体饱满。 -
AI 智能整理(DeepSeek)
一键调用 DeepSeek 大模型,自动润色段落、生成标题、识别心情、提取标签。即使语音转文字有口误,AI 也能帮你修润通顺。 -
人生故事书 · 自动编纂
日记按年份自动整理成"故事集"。系统生成情感时间线、关键词云、叙事性摘要和年度统计——让回顾成为一场温暖的旅程。 -
时光回忆 · 今日闪回
每次打开首页,系统会推送"X年前的今天你写过什么"。那些几乎遗忘的瞬间,在一行文字中重新变得鲜活。

二、Demo 创作思路
【灵感来源】
朋友跟我说:“我知道记录生活很重要,但我每天回家累得话都不想说,哪还有精力打字写日记?” 这个场景特别触动我。从前的日记是"纸+笔",今天的日记应该是"声音+AI"才对——既然语音输入已经这么成熟,为什么日记不能只用"说"的?
【想解决的问题】
传统日记 App 有三大痛点:
- 记录成本高:打字慢、难坚持
- 整理困难:日记越写越多,翻看却无从下手
- 缺乏回顾体验:记了就忘,没有情感连接
记忆罐头试图用"语音输入 + AI 整理 + 故事书自动编排"的组合,一次性解决这三个问题。
【为什么做这个方向】
市面上做日记的产品很多,但要么太复杂(Notion、飞书),要么太简陋(纯粹的文字备忘录)。我们判断:AI 时代,日记产品的核心不再是"记录",而是"回顾"。用户说几句话交给 AI,自动变成可读的日记;日积月累后,AI 还能帮你把散落的记忆编织成有温度的人生故事书——这才是差异化的价值点。
====================

图注:"人生故事书"功能的核心理念——每天的零散记录,自动变成一本有组织、有情感、有数据洞察的年度故事集
三、Demo 体验地址
微信小程序体验版
打开微信 → 发现 → 小程序 → 搜索"记忆罐头"(或扫描下方二维码)即可体验。

开发版本地体验
使用微信开发者工具,导入项目,即可在模拟器或真机上运行。
四、TRAE 实践过程
整个"记忆罐头"使用 TRAE Work 开发完成,从原型构思到代码落地,全部在 TRAE 的对话式协作中完成。以下是完整的开发流程和关键节点记录。
====================
【技术架构】
框架:Taro 4.x + React 18 —— 跨端框架,一套代码编译到微信小程序
语言:TypeScript —— 全量类型覆盖,编译期捕获多数错误
样式:Sass (SCSS Modules) —— 模块化样式隔离
AI 引擎:DeepSeek API —— 日记润色、标题生成、情感识别、标签提取
语音识别:讯飞 iFlytek API —— 语音转文字(WebSocket 实时识别)
数据存储:微信本地存储 —— 所有数据仅存于用户手机,无服务器依赖
状态管理:Zustand —— 轻量级状态管理
====================
【开发流程】
Phase 1:需求梳理与项目初始化
在 TRAE 中描述应用构想:语音日记 + AI 整理 + 人生故事书。TRAE 辅助梳理出完整的页面结构(首页/记录页/故事书/个人中心/详情页/引导页)和技术选型建议(Taro + React + TypeScript + 本地存储)。
Phase 2:数据层与核心功能开发
实现日记 CRUD(增删改查)、用户信息管理、标签系统、心情/天气枚举。TRAE 生成了完整的 storage.ts 模块,包括数据校验、错误处理和 18 个工具函数(搜索、筛选、统计、导出等)。
Phase 3:AI 能力集成
分两步接入:第一步,DeepSeek API 集成——日记智能润色、标题生成、情感识别、自动标签;第二步,讯飞语音识别——长按录音、实时转文字、本地音频保存。TRAE 自动处理了 API 调用、错误降级和本地兜底逻辑。
Phase 4:故事书与回顾功能
实现按年份自动编纂"人生故事书",含叙事性摘要、情感时间线、关键词云、高频标签和年度统计。同时实现"X年前的今天"时光回忆推送。TRAE 在数据分组、排序和 AI 摘要生成上给出了高效的实现方案。
Phase 5:UI 打磨与体验优化
优化首页日记列表的日期分组展示、录音按钮的动画反馈、下拉刷新、统计卡片、Loading 骨架屏、空状态引导。TRAE 协助编写了所有 SCSS 样式,实现了温暖复古的视觉风格(#FFF8F0 奶油色 + #E86633 陶土橙)。
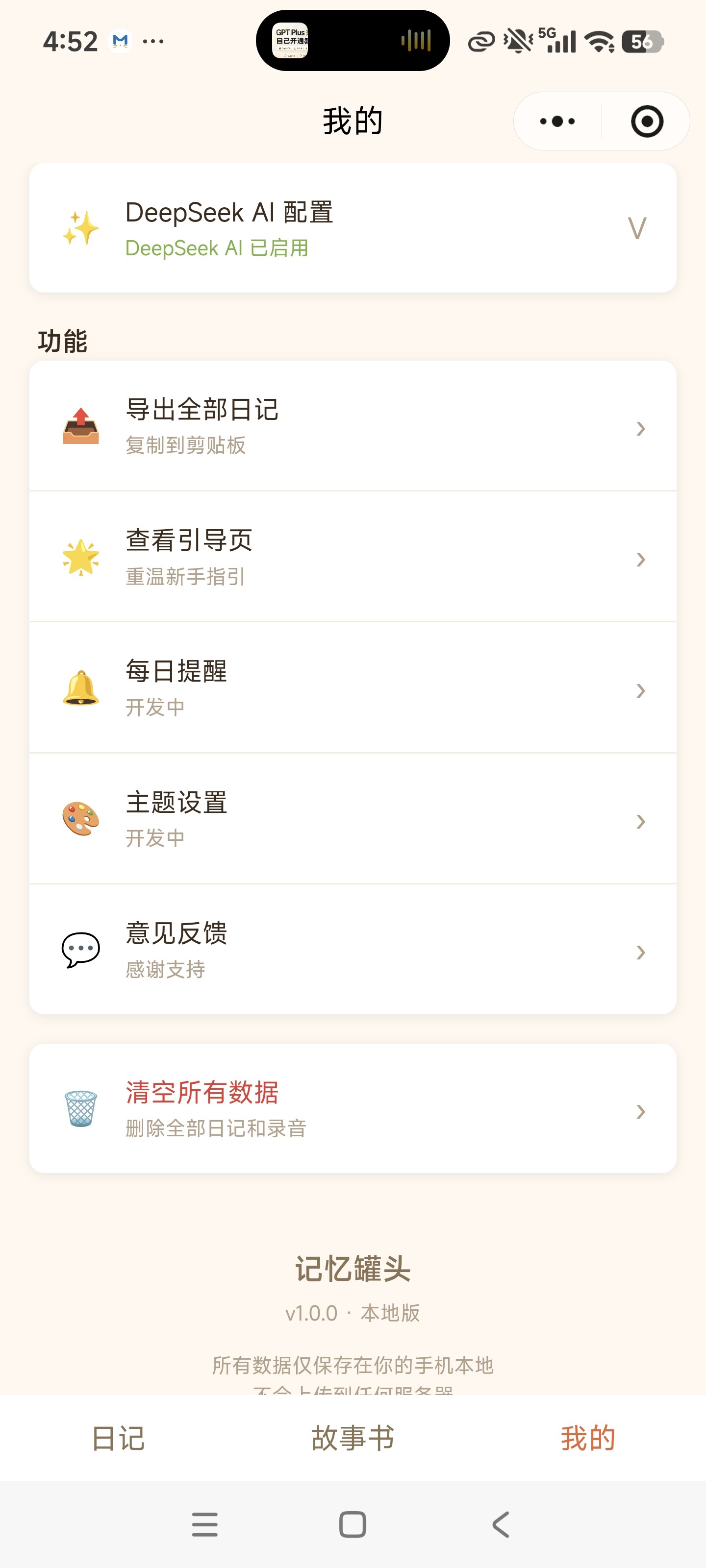
Phase 6:备份恢复与配置管理
实现本地数据备份/恢复、语音识别和 AI 的自定义 API 配置面板、数据导出(文本)、一键清空。TRAE 设计了完善的数据校验和类型安全方案。
====================

图注:语音日记创作流程——点击录音 → 说话 → 语音自动转文字 → AI 润色整理 → 保存
====================
【关键任务 Session ID】
以下 Session ID 是 TRAE 各阶段关键对话的唯一标识,可在 TRAE 中双击对话记录复制验证。请根据实际开发记录填入对应的 Session ID。
对话 1 —— 在 TRAE Work 中描述需求,AI 生成完整项目脚手架
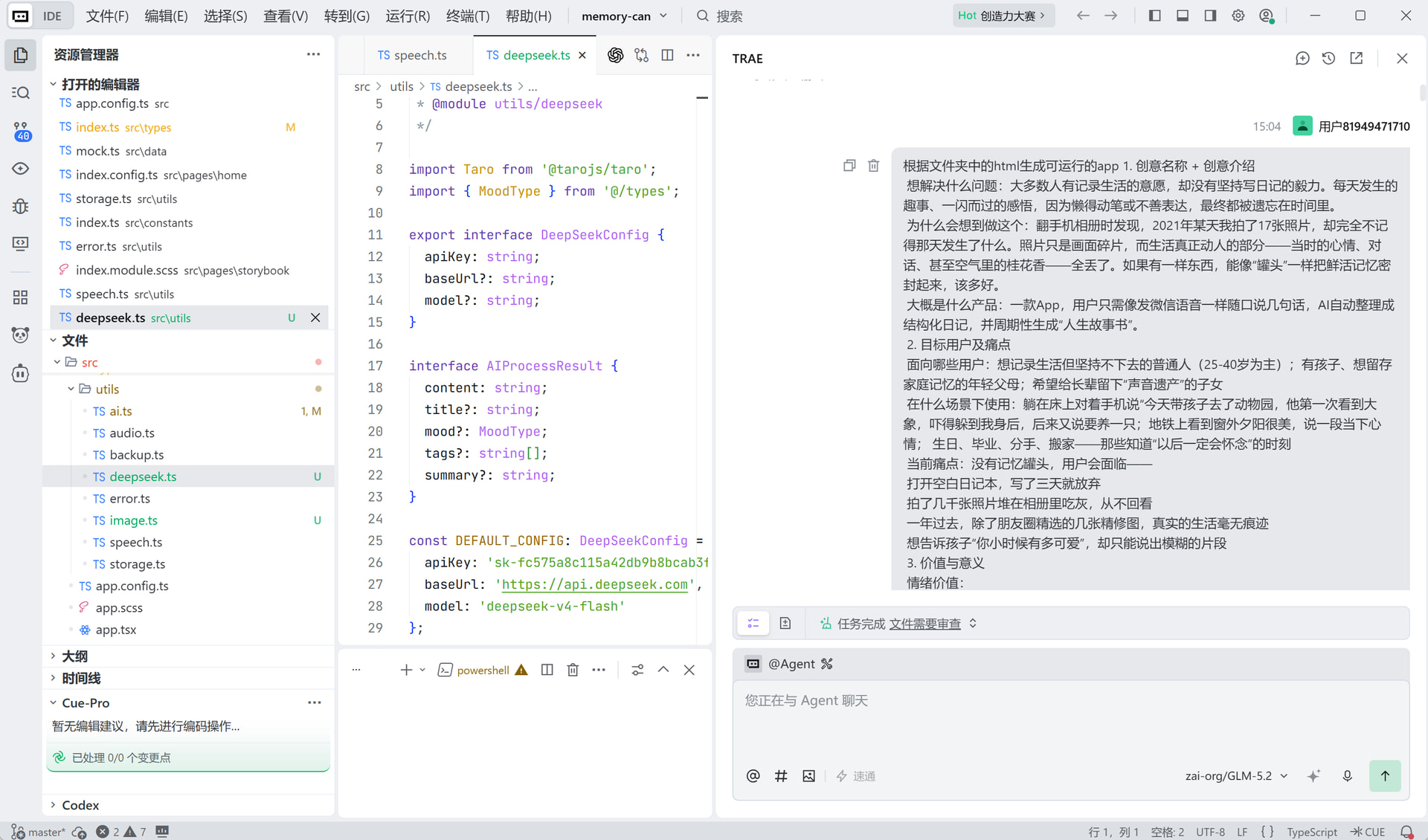
Session ID:.2842694649652364:3852f007c9e84f08cc31afe72a5ac367_6a34e9f452d5d5c22b1e4d21.6a34e9f452d5d5c22b1e4d27.6a34e9f452d5d5c22b1e4d26:Trae CN.T(2026/6/19 15:04:20)
对话 2 —— DeepSeek AI 集成
Session ID:.2842694649652364:53972bab5cf6856951123211f9418fdc_6a34e9f452d5d5c22b1e4d21.6a34e9f452d5d5c22b1e4d6f.6a34e9f452d5d5c22b1e4d6e:Trae CN.T(2026/6/19 15:04:20)
对话 3 —— 语音识别
Session ID:.2842694649652364:3fb3a2ea37105c4acf4dbbbfed754126_6a34e9f452d5d5c22b1e4d21.6a34e9f452d5d5c22b1e4d4b.6a34e9f452d5d5c22b1e4d4a:Trae CN.T(2026/6/19 15:04:20)
对话 4 —— 图片插入
Session ID:.2842694649652364:20f736dba485b547fbfeb8176a1e0938_6a34e9f452d5d5c22b1e4d21.6a34ec0052d5d5c22b1e502e.6a34ec006b692a1c28a81c34:Trae CN.T(2026/6/19 15:13:04)
对话 5 —— Bug 修复优化
Session ID:.2842694649652364:e15719fcae42e5a2d8df0ac553caecd0_6a34e9f452d5d5c22b1e4d21.6a34f0e952d5d5c22b1e512b.6a34f0e96b692a1c28a81c37:Trae CN.T(2026/6/19 15:34:01)
【开发心得】
使用 TRAE 最大的感受:传统的开发流程是"想清楚再写",TRAE 的模式更像是"边聊边做"。你不需要提前想好所有技术细节,把想法描述清楚,TRAE 会帮你落地成可运行的代码,而且可以在对话中不断调整和迭代。这个流程特别适合从 0 到 1 的创意验证——两天时间,从一个想法到一个完整可体验的 Demo,这在传统开发流程中几乎是不可能的。
踩过的坑:微信小程序的语音识别需要配置 WebSocket 域名(wss://iat-api.xfyun.cn),而 DeepSeek 需要配置 request 域名(https://api.deepseek.com),两者都要在微信公众平台手动添加。TRAE 在第一次调用时就给出了完整的域名配置提示,帮我们避免了很多排查时间。
============================================================
附:社区报名帖链接