Hi,这里是AI领域知识补全百科计划,主要是因为最近在回补AI领域相关的知识点,在此也分享给大家~
本栏目将以AI的不同领域进行分类分篇,下一篇什么时候更新随心情~ ![]()
注意:本文中涉及的知识内容旨在用通俗的语言解释名词,但并不保证全面,如果想要深入学习可自行搜索,本系列只适合了解入门~
LLM(Large Language Model,大语言模型)
核心定义
-
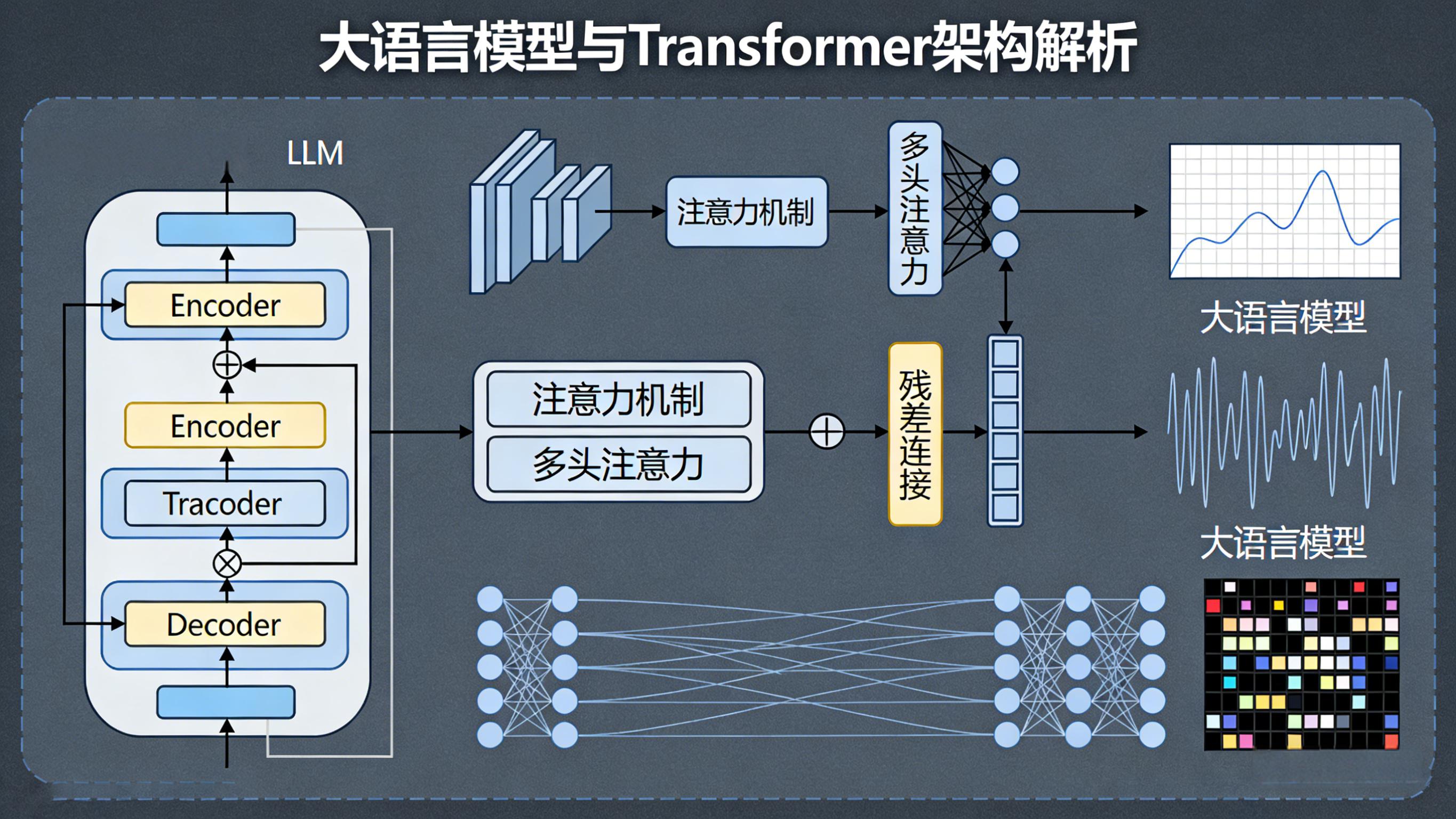
专业定义:以Transformer 架构为核心,在海量人类文本数据上进行大规模预训练,具备自然语言理解、生成、翻译、推理、问答、对话等能力的超大规模深度学习模型,参数量级通常达到百亿、千亿级别。
-
通俗理解:它是一个 “读过海量人类书籍、网页、文章” 的 AI 语言大脑,通过学习语言的语法、逻辑、常识和知识规律,能像人一样听懂、说人话,还能写文章、解问题、编代码,本质是用数学模型拟合了人类语言的使用规则。
起源与发展脉络
-
早期阶段(早期~2017):传统 NLP,无 “大模型” 早期靠人工写语言规则、简单统计词频,比如早期翻译软件、客服机器人,只会固定话术,完全不理解语义,和现代 LLM 天差地别。
-
技术基石诞生(2017年) Google 发布Transformer 模型,提出自注意力机制,解决了长文本理解、高效并行训练的核心难题,这是所有 LLM 的底层技术根基,没有它就没有后续大语言模型。
-
预训练模型时代(2018~2019) Google BERT、OpenAI GPT-1/2 相继出现,属于 “小 / 中型语言模型”,首次实现通用语言理解,但能力有限,还未被称作 LLM。
-
LLM 正式诞生(2020年:关键阶段) OpenAI 发布GPT-3(1750 亿参数),凭借超大参数 + 海量训练数据,首次展现出零样本 / 少样本学习能力 —— 不用专门训练,就能做翻译、写文案、解数学题,标志着真正意义上的大语言模型(LLM)时代开启,“LLM” 这一概念也随之普及。
-
爆发期(2022~至今) ChatGPT、Gemini、Claude Opus等,以及国内通义千问、豆包、Kimi、GLM、MiniMax等,开源的 Llama、Mistral 等相继推出,LLM 从实验室走向全民应用,能力覆盖推理、多模态、工具调用等。
LLM 的核心特征
- 规模大 训练数据以 TB 计(互联网文本、书籍、论文等),模型参数百亿~千亿,算力需求极高。
- 通用语言能力 不局限于单一任务,能同时做对话、写作、翻译、总结、代码编写。
- 涌现能力 模型规模突破临界值后,突然具备逻辑推理、常识理解等原本没有的能力。
- 无真正意识 关键误区:LLM 只是拟合语言规律,并非真的 “思考、理解、有自我意识”,输出依赖训练数据中的统计模式。