【学习工作赛道】CreateBase —— AI驱动的创作知识操作系统
一、简介
是什么: CreateBase 是一套基于本地文件系统 + RAG 检索引擎 + 知识图谱的 AI 创作知识操作系统 ,以 Obsidian Markdown 为载体,让 AI Agent 能像查字典一样调用结构化创作经验。
面向谁: AI 内容创作者、提示词工程师、AI 视频制作人、AI 艺术家 —— 任何需要 系统化沉淀和复用 AI 创作经验 的人。
核心功能:
功能 说明 知识卡入库系统 10 步标准化 SOP,将零散经验转化为带 YAML 元数据的结构化知识卡,支持四阶段查重防重复 RAG 混合检索引擎 BM25 关键词匹配 + ONNX 向量语义搜索双路融合,338 张卡片 / 2110 个索引块,毫秒级召回 OWL 知识图谱 自动导出 JSON-LD / Turtle / OWL-XML 三格式,335 个节点 / 1991 条关系边,支持图增强检索(graph_enhance 模式) 9 大 AI 技能矩阵 封装为可被 Agent 直接调用的 Skill:入库管理 / 飞轮同步 / 代码审查 / 视频分析 / 提示词路由 / 输出质检 / 知识缺口检测 / 检索验证 / 创意工作台 质量门禁体系 4 层质检流水线(禁忌自查 → 角色失败诊断 → 运镜误区检查 → 冲突扫描),五维 Eval 评分 ≥ 7.0 才能入库
二、创作思路
灵感来源
我在用 AI 做视频、写提示词的过程中发现一个痛点: 每次产出好效果的经验都是一次性的 。今天调出一组好的光影参数,下周就忘了;上周解决的角色一致性问题,下个月又踩同样的坑。网上的教程碎片化、平台规则天天变、AI 模型能力迭代快 —— 这些"经验"如果只存在脑子里或散落在聊天记录里,本质上就是 沉没成本 。
我想做的不是又一个"笔记软件"或"提示词库",而是一个 能让 AI 自己读写、检索、组合这些经验的操作系统 。
想解决的问题
- 经验不可复用 — 好的提示词/分镜方案用过就丢,无法形成复利
- 质量无标准 — AI 输出的提示词是否合规、有无负面命中、内部是否冲突,缺乏自动化检测
- 知识孤岛 — 不同平台的规则(Midjourney / 可灵 / Veo / Runway)、不同领域的知识(光影/构图/运镜/配乐)分散在各处,无法交叉引用
- Agent 协作无协议 — 多个 AI Agent 同时操作同一套知识库时,缺乏变更管理、冲突检测和质量门禁
为什么做这个方向
市面上的方案大致分三类:
- 纯笔记类 (Notion/Obsidian):人用的,AI 读不懂结构
- 纯向量库类 (Pinecone/Weaviate):给 RAG 用,但缺乏创作领域的领域知识和质量体系
- 纯 Prompt 库类 (各种提示词市场):静态模板,不支持增量更新和关联推理
我选择了一条中间路线: 以 Markdown 文件为原子单位(人类可读可编辑),以 RAG + 知识图谱为检索层(机器可理解可调用),以 SOP + Hook + Eval 为治理层(质量可控可审计) 。这样既保留了创作者对内容的完全控制权,又让 AI 能真正"使用"这套知识。
取舍上,我放弃了做 SaaS 或 App 的想法,选择了 本地优先 + 文件系统即数据库 的架构。原因很简单:创作者的知识是隐私资产,不应该上传到任何云端;而且本地文件意味着你可以用 Git 同步多台电脑、用 diff 审核每次变更、用任何编辑器打开查看。
三、核心技术架构
关键技术选型:
- 检索 :Python 自研 rag_local.py ,BM25(jieba 分词)+ ONNX Embedding(sentence-transformers),支持 CUDA GPU 加速
- 知识图谱 :自研 export_owl.py ,从 Markdown 双链 [] 和 YAML relations 字段自动推断 7 类关系(relatedTo / basedOn / contradicts / partOf / complements / variantOf / extends)
- 质量防护 :Hooks 引擎 hooks_engine.py ,在入库前自动执行 5 项拦截检查(负面内容归位 / 查重 / 编码 / YAML完整性 / source字段清理)
- 多机同步 : machines.json 注册硬件配置确保环境一致性
四、当前成果与数据
维度 数据 说明 知识规模 338 张知识卡 / 2110 个索引块 覆盖案例(01) / 风格(02) / 镜头(03) / 提示词(04) / 模板(05) / 工作流(06) / 规则(07) / 平台(08) / 负面(09) 九大目录 规则库 100 条创作规则 含提示词写作(39) / 视频制作(53) / 视觉理论(17) / 影视剪辑(20) / 商业(10) / Agent规范(13) 负面知识库 13 张避坑卡 覆盖去AI感 / 提示词污染 / 运镜误区 / 角色塑造失败 / 鲁棒性破坏等 平台覆盖 Midjourney / 可灵 / Veo 3.1 / Runway Gen-4 / Seedream / 即梦 / 通义万相 / Nano-Banana-Pro / Suno 等 15+ 平台 OWL 图谱 335 节点 / 1991 条边 支持图增强检索,查询"赛博朋克"可返回 8 条 RAG 结果 + 2 条图谱扩展 检索命中率 100%(3/3 关键词测试) “赛博朋克”(0.90) / “蒙太奇”(0.89) / “分镜”(0.81) 均 Top1 命中 Eval 平均分 9.05 / 10 五维评分:可调用性 / 规则遵循度 / 结构完整性 / 创新性 / 无负面命中 任务完成率 100%(66/66) 全部闭环,无阻塞任务 重复率 0 四阶段查重保障零重复入库
五、典型使用场景
6.94 Y@Z.Mj :4pm 03/17 lpd:/ 用AI拉片丧尸清道夫看看 用个人知识库-AI工具完整拉片解析爆火国产短片《丧尸清道夫》,逐帧拆解这部出圈AI影片的镜头设计、叙事逻辑、美术风格与AI创作技巧,好好深挖它能火遍海内外的核心亮点# AIGC # 知识库 # AI视频 # 丧失清道夫 https://v.douyin.com/IjslDmBXWQo/ 复制此链接,打开Dou音搜索,直接观看视频!
场景 1:用户说"帮我写一个赛博朋克风格的女孩提示词"
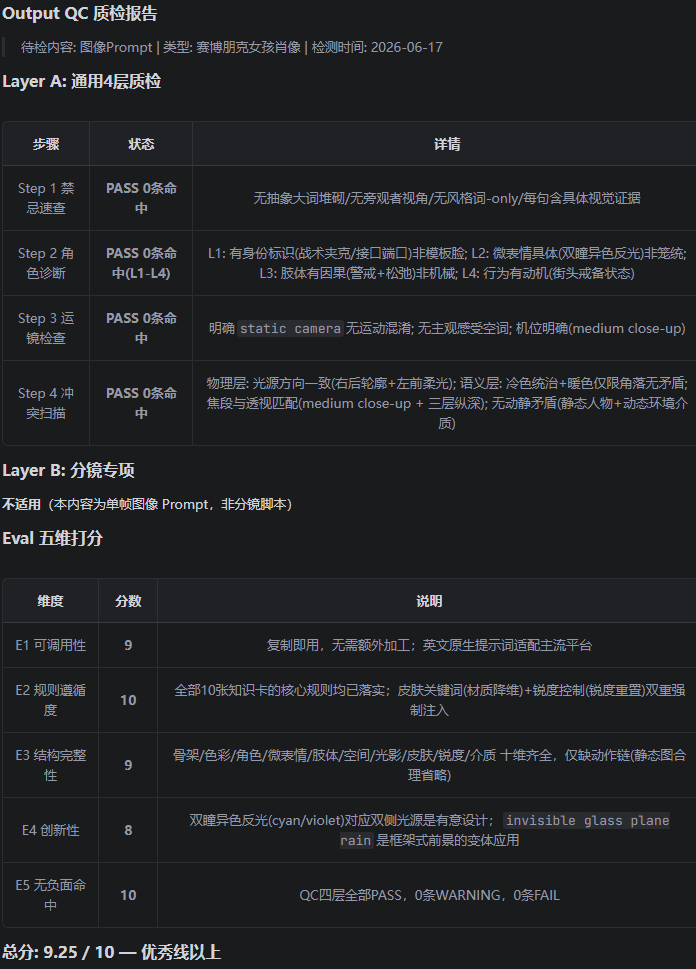
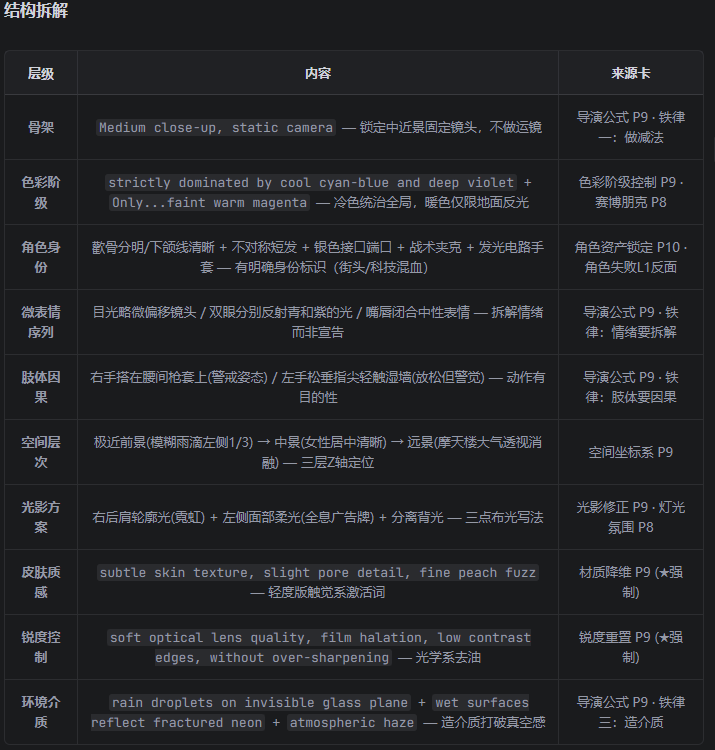
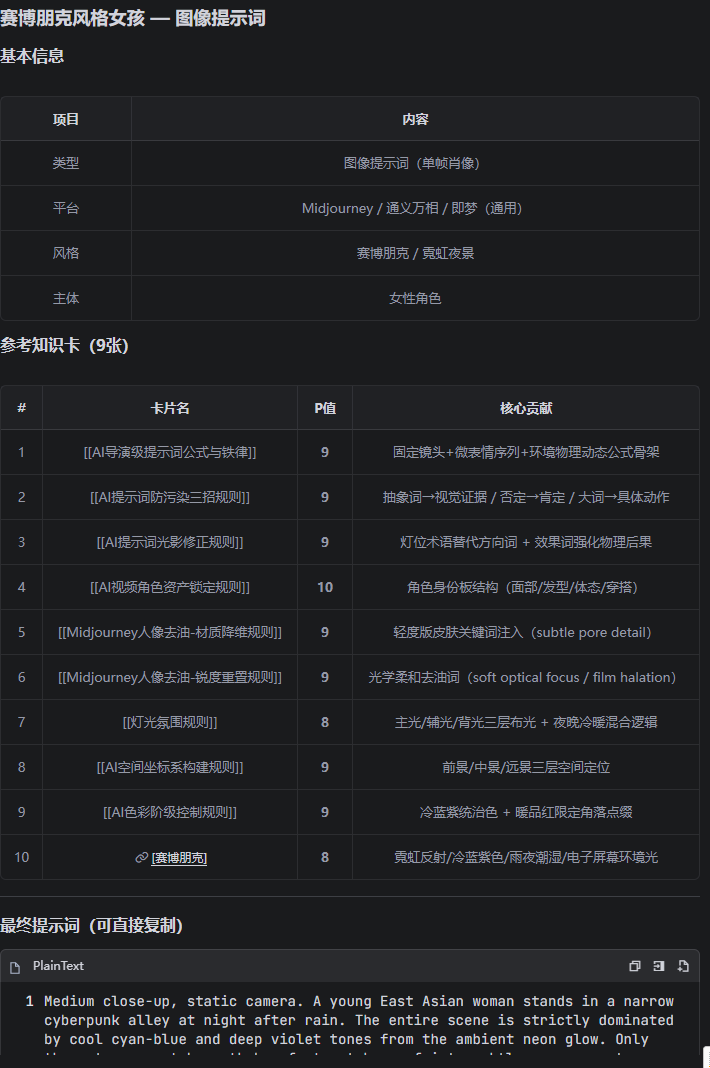
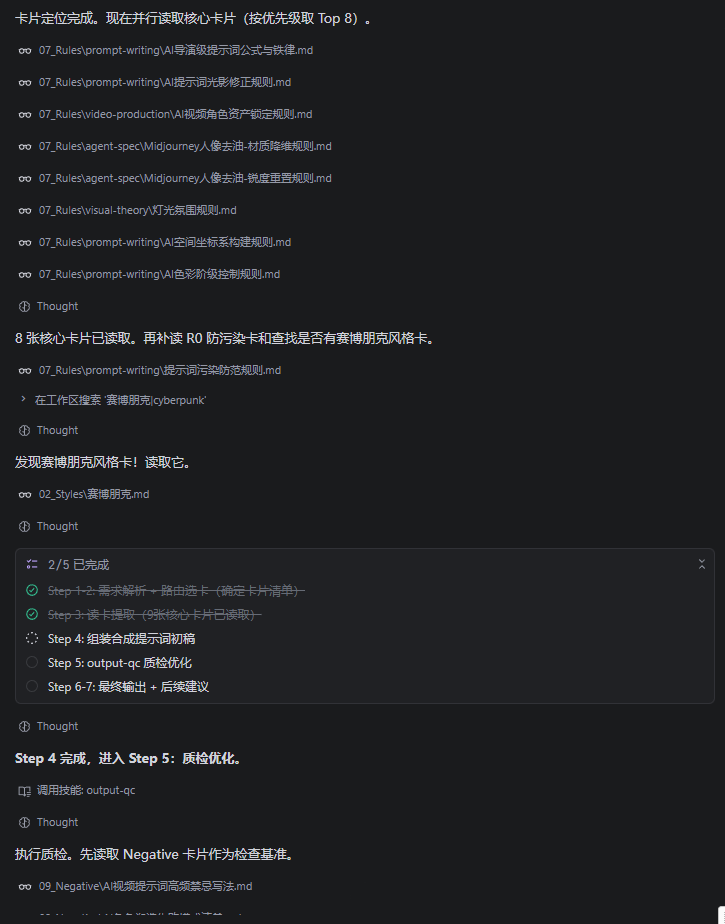
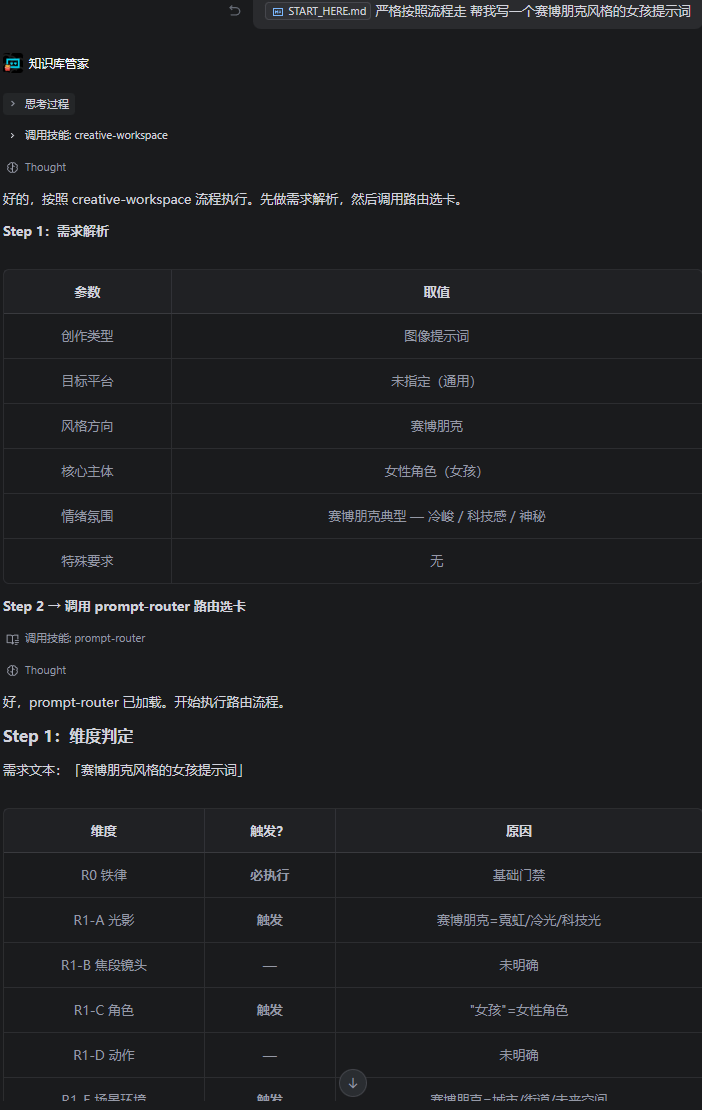
场景 2:用户发来一段视频说"分析一下这个视频的问题"
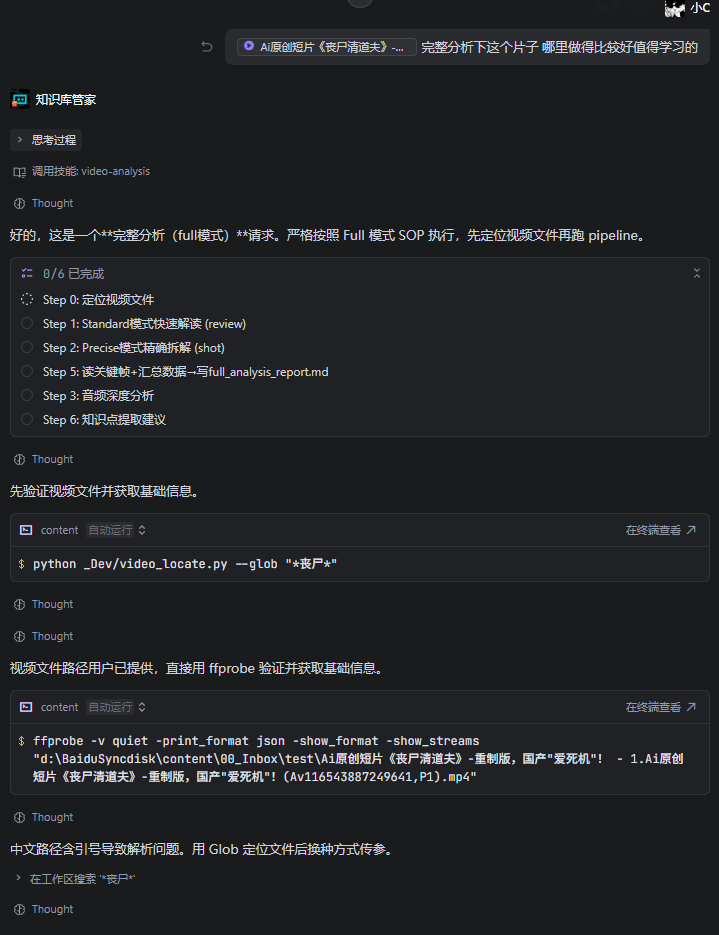
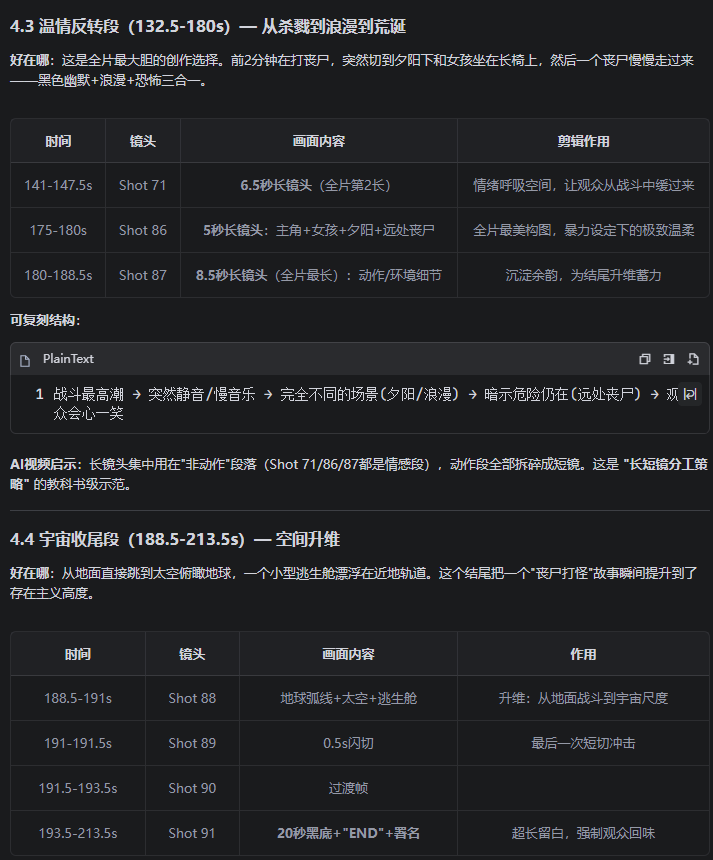
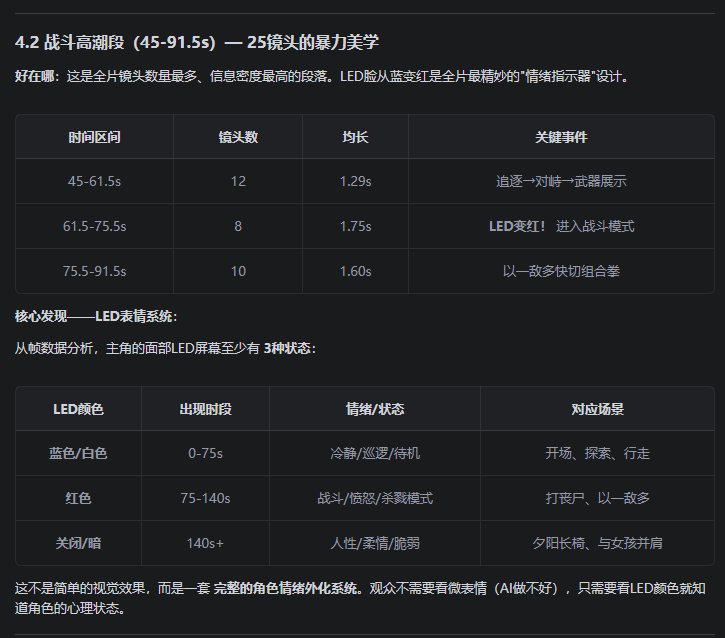
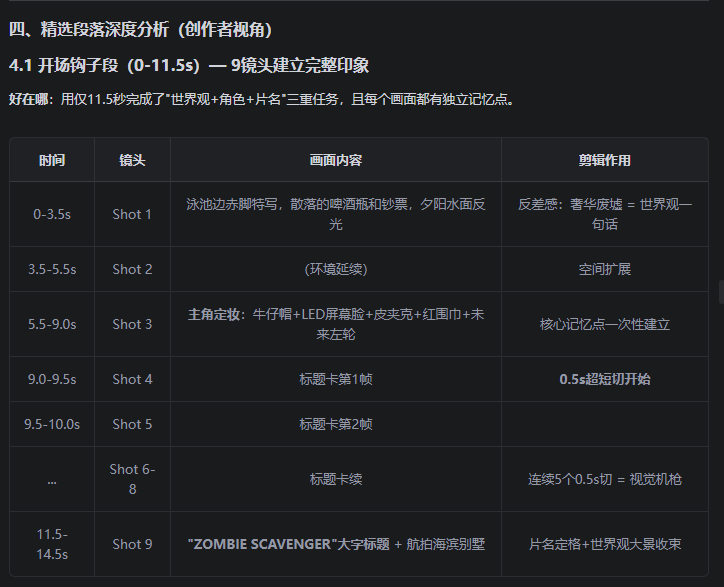
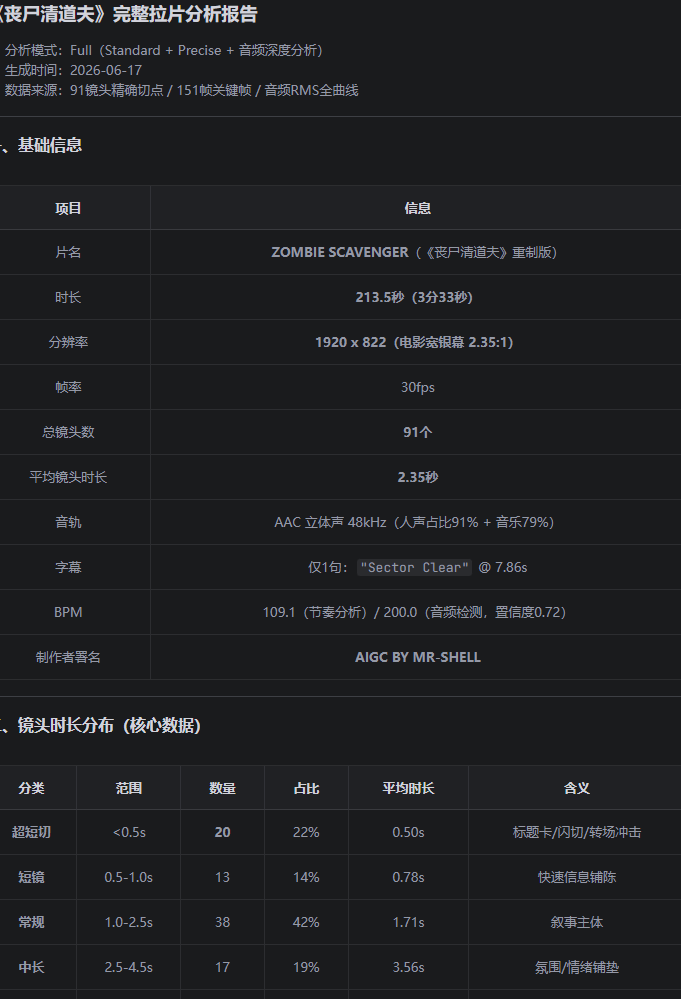
场景 3:日常维护 — “同步一下飞轮”
六、开发心得与未来方向
最有价值的三个决策:
- 文件系统即数据库 — 不依赖外部数据库,所有知识就是 .md 文件。这意味着零迁移成本、Git 版本可控、任何编辑器可用。代价是需要自己实现索引和检索,但换来的是极致的可控性。
- 负面知识单独成库(09_Negative) — 大多数知识库只存"正确做法",但 AI 创作领域"不要做什么"往往比"要做什么"更重要。把 13 张避坑卡独立出来,让质检流程可以逐条比对,这是命中率 100% 的关键之一。
- SOP 强制化 — 入库必须走 10 步、质检必须过 4 层、同步必须跑 3 阶段。看似繁琐,但正是这种"不跳步"的纪律保证了 338 张卡片零重复、零孤立。
- 正在做的事:
- 风格库扩容(OKR O1):从 11 种风格扩展到 100+ 种,覆盖时代感 / 国风 / 艺术 / 自然 / 城市 / 情绪 / 商业 / 游戏 / 节日 / 实验 10 大类别
- 规则库补强视觉理论弱项(OKR O2 KR2.1):目标 120 条规则