**【学习工作赛道】**DeepSeek V3 Token Counter — BPE 实时分词可视化工具
1. 创意名称 + 创意介绍
创意名称: DeepSeek V3 Token Counter — BPE 实时分词可视化工具
想解决什么问题:
开发者和 AI 应用使用者在编写提示词时,无法直观地知道文本会被切分成多少个 Token、哪些片段被合并或拆分,导致难以精确控制上下文窗口使用量和 API 调用成本。
为什么会想到做这个:
在开发基于 DeepSeek V3 的应用时,我经常需要预估提示词的 Token 消耗。市面上的 Token 计数器大多只支持 OpenAI 的分词器,缺少对 DeepSeek V3 原生 BPE 分词器的支持,而且功能仅限于"计数"。于是我想做一个专为 DeepSeek V3 设计的、可视化的、功能完整的 Token 分析工具。
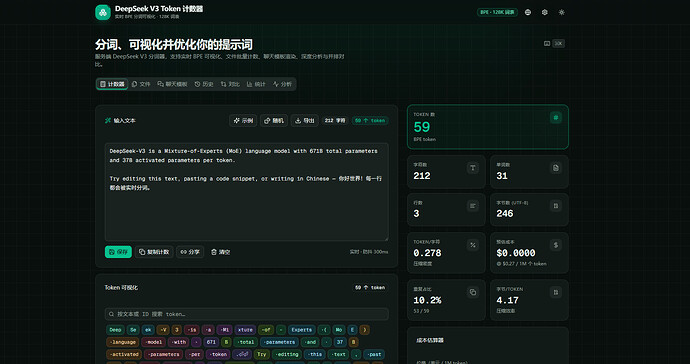
大概是什么产品:
一个基于 Next.js 16 构建的 Web 应用,内置 DeepSeek V3 官方分词器(128K 词表 BPE),提供实时分词可视化、文件批量计数、聊天模板渲染、深度统计分析等功能,支持中英双语。
2. 目标用户及痛点
面向哪些用户: AI 应用开发者、提示词工程师、AI 研究人员、LLM 学习者
在什么场景下使用:
-
编写提示词时实时查看分词结果,优化措辞减少 Token 消耗
-
批量上传代码文件统计 Token 总量,预估嵌入成本
-
用聊天模板构建器渲染 DeepSeek 格式提示词,导出 curl 命令测试
-
对比不同写法的提示词,找到 Token 最少的版本
当前痛点: 无 DeepSeek V3 专用计数器;现有工具不展示分词细节;无法渲染聊天模板;无法批量/对比/导出
3. 价值与意义
效率提升: 实时分词让开发者精确控制提示词长度;批量文件计数省去手动统计;聊天模板 + curl 导出从"手写 JSON"变成"可视化编辑 → 一键复制"
商业价值: Token 消耗 = API 费用。对比模式帮用户找到 Token 更少的写法,生产环境每月节省可观成本;成本估算器实时显示预估费用
社会价值: 开源工具降低理解 LLM 分词的门槛;中英双语界面让国内开发者更顺手
4. 创意产物
技术栈:Next.js 16 + TypeScript + Tailwind CSS 4 + shadcn/ui + Prisma/SQLite + Zustand + Recharts + Framer Motion
7 个功能 Tab:Counter(实时分词+可视化)/ Files(批量文件)/ Chat Template(模板渲染+curl)/ History(CRUD+搜索)/ Compare(对比+CSV导入)/ Stats(统计图表)/ Analysis(词云+饼图+频率分析)