一、Skill 介绍
背景
做口播视频的人都有一个痛:后期剪辑太耗时间。一段 20 分钟的原片里,充斥着"嗯"“啊”、说错重说、卡顿停顿、重复句……手动逐段排查标记裁剪,往往要花素材时长 2-3 倍的时间。
剪映的「智能剪口播」能解决一部分问题,但有两个硬伤:
- 不理解语义:重复说的句子、说错后纠正重说的段落,它识别不出来
- 字幕质量差:专业术语(Skill、GitHub)经常被识别成离谱的结果
videocut skill,让 AI Agent 帮你完成从转录、口误检测、字幕纠错到最终剪辑的全流程。你只需要一句话触发,最后在浏览器里确认一下就行。
使用场景
- 技术类口播(编程教程、技术分享)—— 专业术语多,ASR 容易出错,热词表纠正尤为重要
- 知识类口播(读书笔记、课程讲解)—— 容易重复句、说错重来,语义检测能精准识别
- 任何说话为主的视频素材 —— 播客、访谈、vlog 独白
- 批量处理 —— 传入文件夹,AI 自动为每个视频启动并行 Subagent
核心能力对比
| 能力 | videocut Skill | 剪映智能剪口播 |
|---|---|---|
| 语义理解 | AI 逐句分析,识别重说/纠正/卡顿 | 只能模式匹配 |
| 静音检测 | >0.3s 自动标记,阈值可调 | 固定阈值 |
| 重复句检测 | 相邻句语义比对(去掉口头禅前缀)→ 删前保后 | 无 |
| 句内重复 | “好我们接下来好我们接下来做” → 删重复部分 | 无 |
| 热词纠错 | 自定义热词表,ASR + LLM 双重纠正 | 无 |
| 规则可定制 | 9 条检测规则独立文件,随时修改偏好 | 无 |
二、具体使用方法
1. 安装 Skill
git clone https://github.com/sunnyswag/videocut-skill.git ~/.trae/skills/videocut
2. 安装依赖
# macOS
brew install node ffmpeg
# 安装 CLI 工具
npm install -g @huiqinghuang/videocut-cli
# 配置火山引擎 API Key(语音转录用)
export VOLCENGINE_API_KEY="your_api_key"
火山引擎 API Key 获取:火山引擎控制台 → 语音技术 → 语音识别 → API Key
3. 准备热词表
在项目目录创建 hotwords.txt,一行一个,提升识别和纠错质量:
container_of
GitHub
MCP
Claude Code
热词在两个阶段生效:
- 火山引擎 ASR 阶段:作为自定义词汇提升首次识别准确率
- LLM 分析阶段:作为关键词归一化词典,纠正谐音/拆词错误
4. 一句话触发
在 Trae/Cursor 中对 AI 说:
帮我剪一下这个视频 @video.mp4
批量处理:
处理 @videos-folder 里的所有视频
5. 完整流程
┌──────────────────────────────────────────────────────────┐
│ 前置条件:Node.js + FFmpeg + videocut-cli + API Key │
└──────────────────────────────────────────────────────────┘
↓
┌──────────────────────────────────────────────────────────┐
│ "帮我剪一下这个视频 @video.mp4" │
│ │
│ AI 自动执行: │
│ 1. 提取音频 → 火山引擎 ASR 转录 → 字级别时间戳 │
│ 2. 生成可读文本 → 逐段分析口误/静音/重复/语气词 │
│ 3. 生成 edits.json → 应用编辑 → 启动审核网页 │
└──────────────────────────────────────────────────────────┘
↓
┌──────────────────────────────────────────────────────────┐
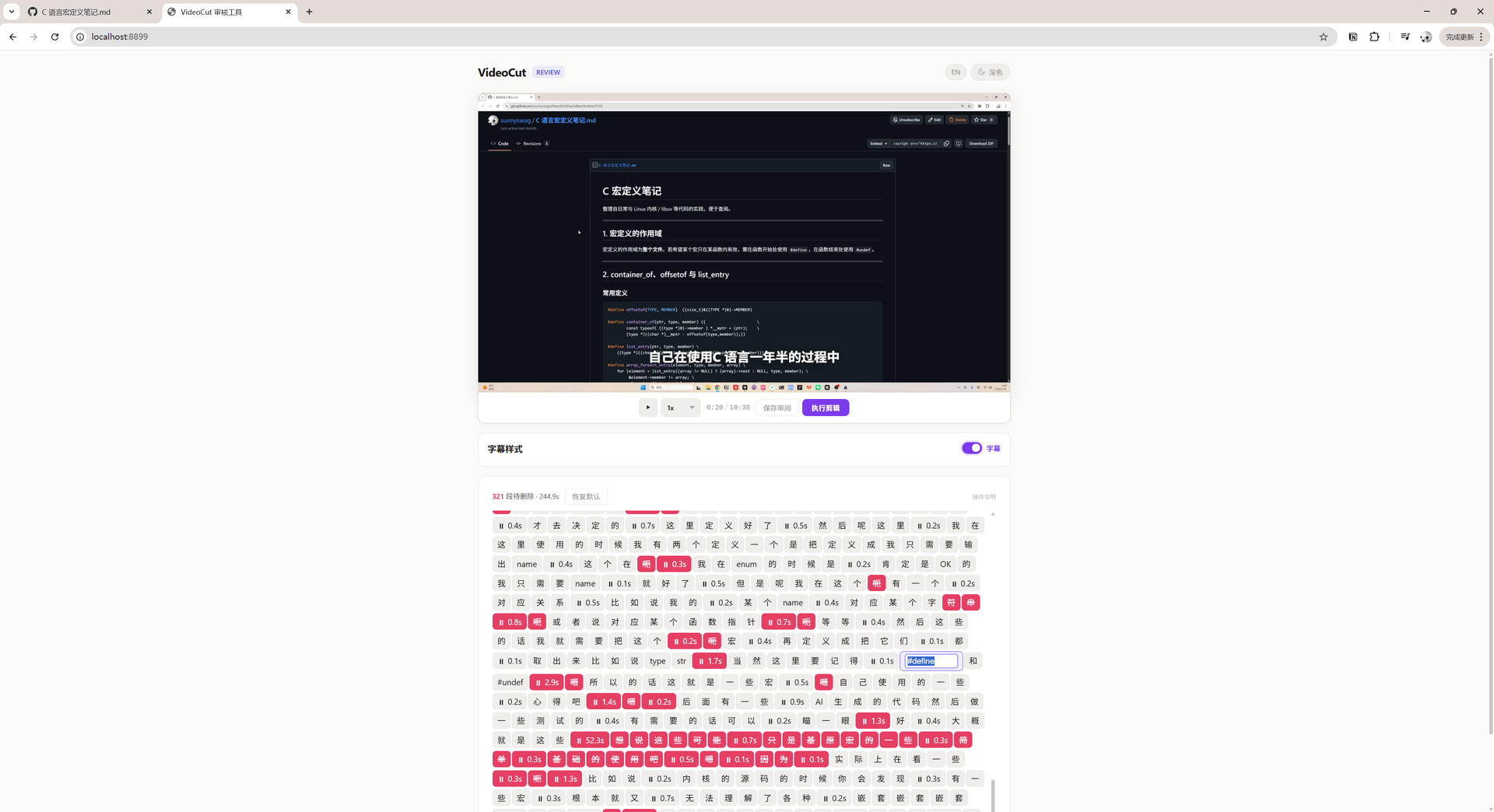
│ 人工审核 http://localhost:8899 │
│ │
│ - 点击句子跳转播放 │
│ - 勾选/取消删除项 │
│ - 确认后点击「执行剪辑」→ FFmpeg 自动裁剪输出 │
└──────────────────────────────────────────────────────────┘
三、Skill 编写思路与技巧
1. 用示例 JSON 而非长篇文字定义数据格式
edits.json 是 AI 分析和 CLI 工具之间的「通信协议」。我在 Skill 中定义了三种操作格式,并附上 edits.example.json:
{
"deletes": [
{ "pathSet": { "parent": 0 }, "reason": "silence" }
],
"textChanges": [
{ "pathSet": { "parent": 2, "children": [1] }, "newText": "C", "oldText": "c" }
],
"combines": [
{ "pathSet": { "parent": 16, "children": [5, 6] }, "newText": "GitHub", "oldText": "get up" }
]
}
给 Agent 看一个具体的 JSON 示例,比写一大段文字描述有效得多。
2. 规则文件独立拆分,实现可定制 + 可进化
没有把检测规则硬编码在 SKILL.md 里,而是拆成 9 个独立文件:
rules/
├── 1-core-principles.md # 删前保后
├── 2-filler-words.md # 语气词列表 + 删除边界
├── 3-silence-handling.md # 静音阈值
├── 4-duplicate-sentences.md # 语义比对重复句
├── 5-stuttering.md # 卡顿检测
├── 6-intra-sentence-repeat.md
├── 7-consecutive-fillers.md
├── 8-self-correction.md
└── 9-incomplete-sentences.md
好处:
- 可定制:用户随时改某条规则(比如调静音阈值)
- 可进化:告诉 AI 偏好后直接更新对应文件
- 优先级明确:按编号排序,AI 分析时按序执行
3. 中英文双语规则,一套文件通吃
每个规则文件里都有 ## zh 和 ## en 两个 section。SKILL.md 里有语言检测逻辑:根据转录内容判断语言,只加载对应的规则段。一套规则文件同时支持中英文口播。
4. 批量处理用 Subagent 并行
处理多个视频时,Skill 指导 Agent 为每个视频启动独立 Subagent 并行执行步骤 0-4,最后才启动一个共享的 Review Server(Web UI 以 Tab 形式展示每个视频)。
四、效果展示
实际成果数据
输入:19 分钟口播原片(技术分享类,各种口误、卡顿、重复)
AI 自动分析结果:
- 检出 175 处问题
- ~30 处长静音 (>1s) 标记删除
- ~15 处残句/不完整句 标记删除(如 “然后第”、“就是在”、“比如说呃” 等)
- 2 处完全重复句 标记删除
- ~50 处语气词(嗯/呃)标记删除
- ~5 处卡顿词(就就/变成变成/这这/用用)标记删除
- 49 处 ASR 文字纠正(最主要的是"红"→"宏" 贯穿全片约 20 处)
- 15 处多词合并纠正(如 “on define"→”#undef"、“音钮"→"enum” 等)
- 文本纠错:专业术语修正(如 “get up” → “GitHub”,“红” → “宏”)
- 全程 AI 自动完成,人工仅需在 Web UI 确认
使用前 vs 使用后
| 对比项 | 手动剪辑 | videocut Skill |
|---|---|---|
| 耗时 | 40-60 分钟(20min 素材) | ~10 分钟(含确认) |
| 静音检测 | 手动听 + 标记 | 自动检测,阈值可调 |
| 重复句 | 逐句人耳辨别 | AI 语义比对,自动标记 |
| 专业术语字幕 | ASR 错误需逐个修 | 热词表 + AI 双重纠正 |
| 批量处理 | 逐个视频重复操作 | 传入文件夹,并行处理 |

五、相关链接
- Skill 仓库(规则 + SKILL.md):sunnyswag/videocut-skill
- CLI & Web UI 工具:sunnyswag/videocut
- 参考来源:Ceeon/videocut-skills