说实话,我一开始也搞不清楚这两个东西到底该怎么用,什么时候用哪个。但是用着用着就明白了,其实很简单。
先说我写的 knowledge-absorber
我为什么要写这个 Skill?因为我学习新东西的时候,每次都要重复做同样的事情。
比如说,我看到一篇技术文章,我想学习里面的内容。那我要干什么?我要让 AI 帮我抓取这个文章,然后清理掉那些广告、导航栏、页脚这些乱七八糟的东西,然后我还要让 AI 验证一下文章里的内容是不是准确的(因为很多文章都是过时的或者错误的),最后生成一个我能看的笔记。
这一套流程,我每次学习新东西都要做一遍。我不想每次都跟 AI 说:"你帮我抓这个链接,然后清理一下,然后验证一下,然后生成笔记。"太麻烦了,而且每次说的话还不一定一样,AI 理解的也不一定一样。
所以我就把这个流程写成了 Skill。现在我学习任何东西,直接一条命令:
python scripts/run_full_pipeline.py "https://example.com/article"
或者
学习"https://example.com/article"
就完事了。它会自动帮我做完所有事情:抓取内容、清理垃圾、验证准确性、生成笔记。如果是国学相关的内容,它还会自动用水墨风格渲染,看起来很有感觉。
这就是 Skill 的使用场景:你有个固定的流程,需要重复做很多次,那就把它写成 Skill。
重点来了:用 MCP 探索,然后转成 Skill
我装了 Playwright MCP,这是个浏览器自动化工具。我用它的方式,就是我理解 Skill 和 MCP 关系的核心。
第一次做某个浏览器操作(用 MCP 探索)
假设我要做一个任务:每天登录某个网站抓取数据。

第一次做的时候,我不知道具体要怎么操作,所以我让 AI 用 Playwright MCP 去探索:
我跟 AI 说:“帮我用 Playwright 打开这个网站,登录,然后抓取数据。”
AI 就开始用 Playwright MCP 操作:
- 打开浏览器
- 导航到网站
- 找到登录框
- 输入账号密码
- 点击登录按钮
- 等待页面加载
- 找到数据所在的元素
- 提取数据
- 保存到文件
这个过程中,AI 在用 MCP 工具,每一步都在消耗 token。而且 Playwright MCP 特别耗 token,因为它会把整个页面的可访问性树(accessibility tree)都传回来,每次操作都要传一堆数据。
根据实际数据,Playwright MCP 单次任务会消耗约 114K tokens,而且每次浏览器操作都会返回几千个 tokens 的结构化数据。
记录流程,写成 Skill
AI 操作完之后,我知道了整个流程是怎么做的。这时候我就把这个流程记录下来,写成 Skill。
Skill 的内容大概是这样:
---
name: daily-data-scraper
description: 每天登录网站抓取数据
---
# 用法
运行这个 Skill 自动完成数据抓取
# 流程
1. 打开浏览器,导航到 https://example.com
2. 找到 id="username" 的输入框,输入账号
3. 找到 id="password" 的输入框,输入密码
4. 点击 class="login-btn" 的按钮
5. 等待 3 秒让页面加载
6. 找到 class="data-table" 的元素
7. 提取所有 tr 标签的内容
8. 保存到 data.csv
以后每天执行(用 Skill)
以后每天我要抓数据的时候,我就直接跑这个 Skill。AI 看到这个 Skill,知道要做什么,直接按照流程执行就完事了。
不用每次都让 AI 重新用 Playwright MCP 去探索一遍,不用每次都传那些可访问性树的数据,不用每次都消耗那么多 token。
Token 消耗对比
这里是关键,我找到了实际的数据对比:
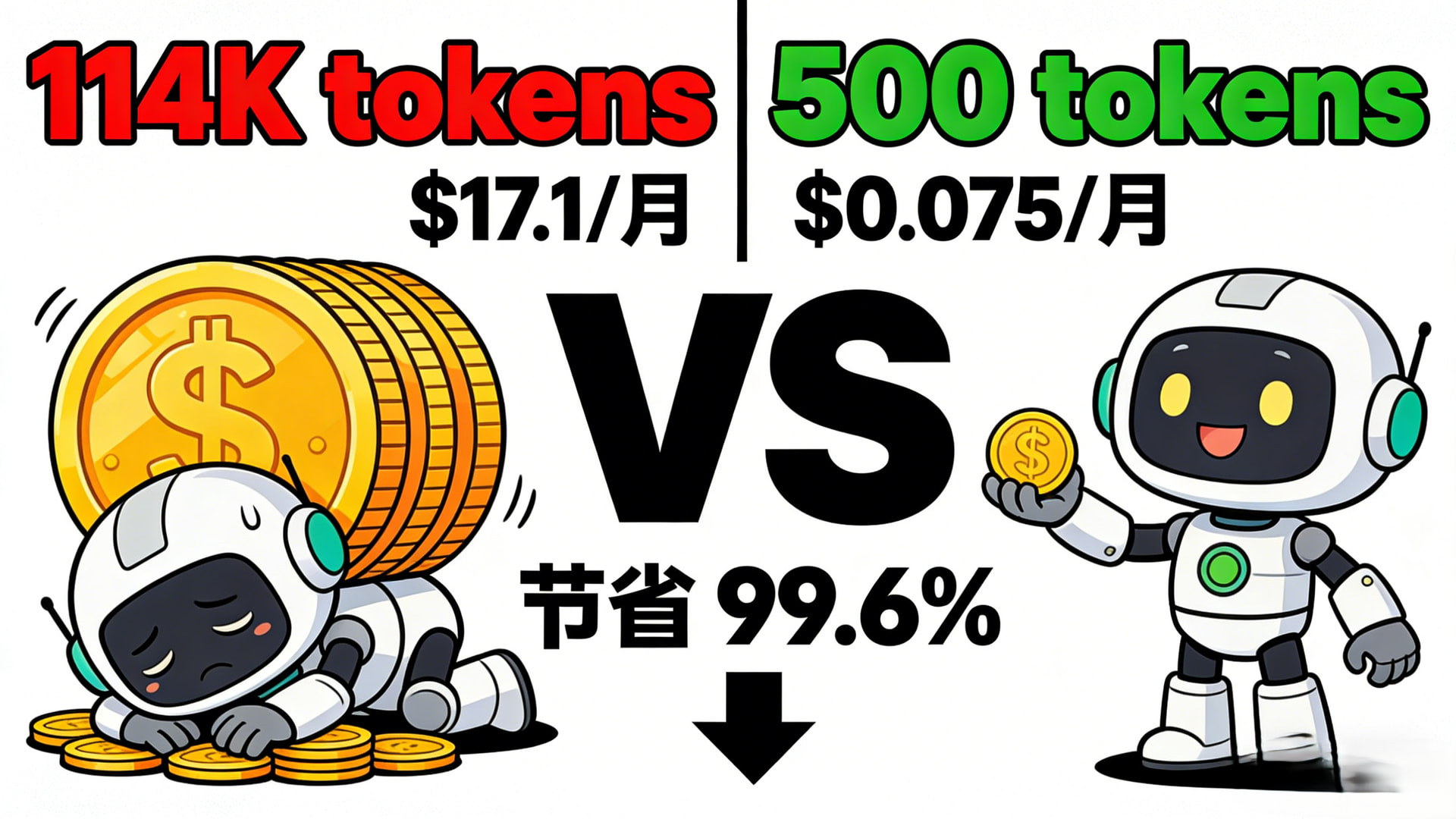
每次都用 MCP:
- Playwright MCP 单次任务:约 114K tokens(来源)
- 如果你每天都要做这个操作,一个月就是:114K × 30 = 3,420K tokens
- 按照 Claude API 的价格(Opus 4.6 是 $5/百万 input tokens),一个月光这个操作就要花:3.42M × $5 = $17.1
写成 Skill 后:
- Skill 加载:不到 500 tokens(来源)
- 一个月:500 × 30 = 15K tokens
- 费用:0.015M × $5 = $0.075
节省:
- Token 节省:3,420K - 15K = 3,405K tokens(节省 99.6%)
- 费用节省:$17.1 - $0.075 = $17.025(节省 99.6%)
这还只是一个操作。如果你有多个重复性操作,节省的就更多了。
而且这个数据还是保守估计。根据另一个数据,MCP 相比 CLI/Skill 方式多消耗约 90,000 tokens,而且CLI 架构比 MCP 节省 94% 的 token 开销。
为什么 MCP 这么耗 token?
每个 MCP 工具定义就要消耗 500-2,000 tokens。如果你装了 5 个 MCP 服务器,每个有 10 个工具,光是加载这些工具定义就要消耗 25,000-100,000 tokens。
更夸张的是,5 个 MCP 服务器可以消耗 55,000 tokens(占用 28% 的 200K 上下文窗口),而你还没开始干活。
而 Skill 呢?只在需要的时候加载,而且只加载相关的 Skill。一个 Skill 完全加载也就不到 500 tokens。
我目前还使用过 UI-UX-PRO-MAX
这是别人写好的 Skill,我用过,做 UI/UX 相关的工作。我不知道它具体怎么实现的,我也不关心。我只知道它能帮我做 UI/UX 的活,我用就完了。
这也是我在第一章说的:你不需要知道原理,你知道它是干什么的就行了。
总结一下
什么时候用 MCP:
你第一次做某个操作,不知道具体流程,需要探索。这时候用 MCP,让 AI 用工具去探索。
什么时候用 Skill:
你已经知道流程了,需要重复执行。这时候把流程写成 Skill,以后直接用 Skill。
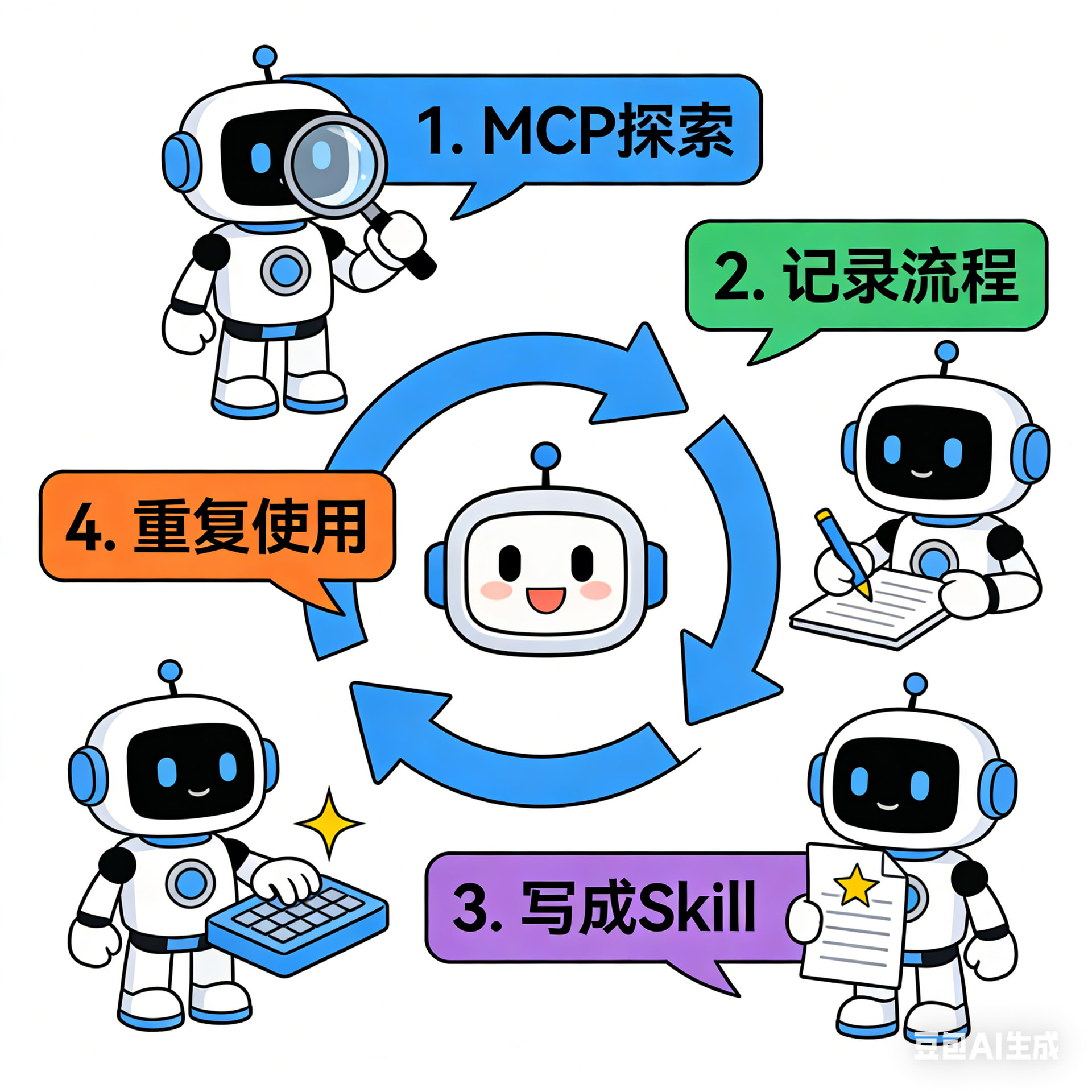
最佳实践:
用 MCP 探索 → 记录流程 → 写成 Skill → 重复使用
为什么要这么做:
- 节省 token(节省 94%-99.6%)
- 节省费用(如果你用 API 的话)
- 执行更快(不用每次都加载 MCP 工具定义)
- 更稳定(流程固定了,不会因为 AI 理解不同而产生不同结果)
就是这么简单,没有任何复杂的东西。
我的 knowledge-absorber 就是这个思路:我每次学习新东西都要做那一套流程,我就把它写成 Skill,现在我学习任何东西,直接扔个链接就完事了。
最后再说一遍:别纠结原理,别纠结定义,你知道它是干什么的,你会用就行了。行动永远比纠结重要。