我的行业 / 角色 / 职业: 我在证券行业工作,做数字化赋能相关的工作。最近接到业务一个请求,他们日常需要处理大量来自交易所的项目数据,并生成专业的分析报告。
我的高频工作内容: 每天的一部分核心工作是从上海证券交易所、深圳证券交易所、北京证券交易所三大交易所采集再融资、重组、发行上市等项目的最新数据。同时还要整理Wind金融终端导出的补充数据,包括可转债、增发、并购重组等专项数据,以及港股市场的股权承销、保荐人业务等信息。这些数据来源复杂、格式不一,需要进行合并清洗后,最终生成券商投行业务排名报告,为公司内部决策提供数据支撑。以前都是通过各种表格透视表,vlookup来实现。但随着时间推移,文件体积越来越大,要维护的表格和表格内sheet越来越多。
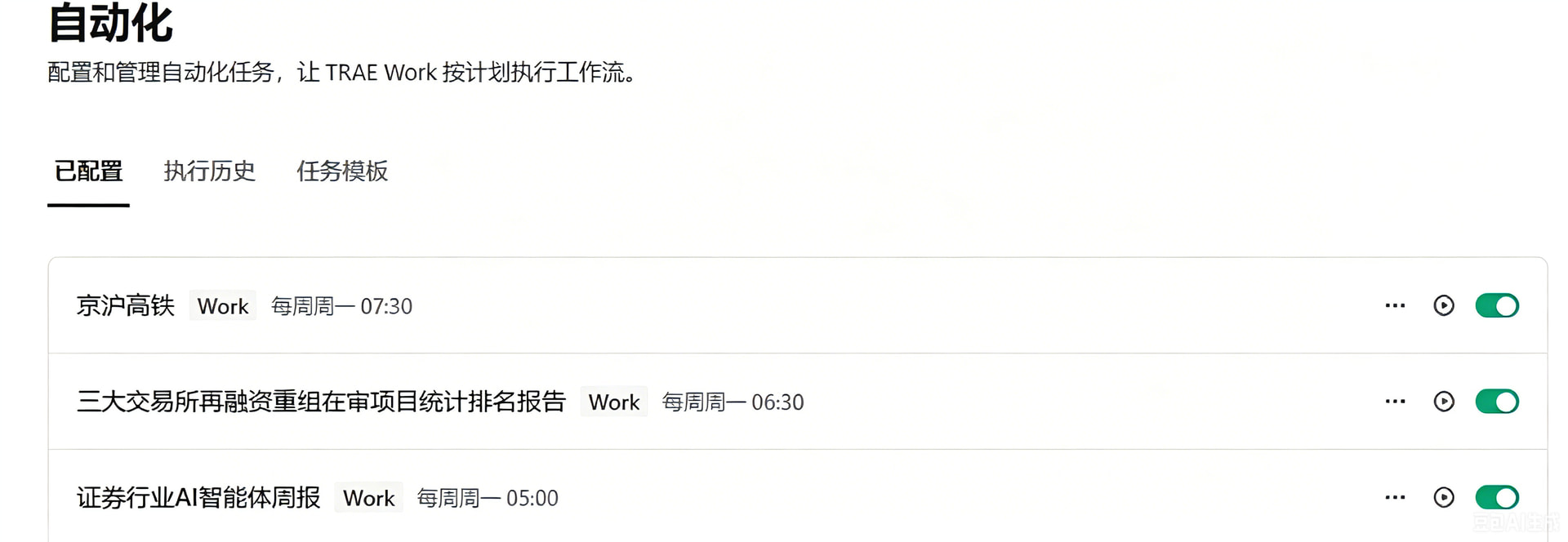
我会在哪些办公场景使用 TRAE SOLO Work:
- 数据采集场景 :每天早上需要获取三大交易所的最新数据时,通过Trae Work, 我编写了一组技能,分别用来下载数据和分析数据。我会使用se-downloader技能一键批量下载,省去了手动登录各个交易所网站的繁琐步骤。
- 数据汇总场景 :下载完成后,调用se-ib-stat技能对多个数据源进行自动合并和统计分析,生成标准化的数据汇总表。
- 报告生成场景 :利用analyze_data.py工具对汇总数据进行深度分析,生成包含排名、趋势等多维度的可视化报表。
- 数据维护场景 :当遇到券商名称不匹配或数据格式异常时,需要灵活调整券商名称映射字典,确保数据准确性。
我一般怎么用它(使用技巧): 我的常规操作流程是:在Trae work窗口唤起数据下载技能,这个脚本会自动触发se-downloader技能,依次从三大交易所抓取数据并保存到data目录。数据下载完成后,再执行se-ib-stat.bat脚本启动数据汇总流程,系统会自动读取data目录下的所有数据源,包括交易所数据、Wind补充数据和港股数据。
在这个过程中,我会特别注意维护券商名称匹配字典,确保不同来源的数据能够正确关联到同一券商。对于Wind导出的数据,我会先检查并清洗表头,删除合并单元格等异常格式,确保数据能够被脚本正确识别。
和之前相比,效率提升体现在哪: 在使用TRAE SOLO Work之前,我需要手动完成以下工作:依次登录三个交易所网站,找到相应的数据下载入口,手动下载Excel文件;然后打开每个文件检查格式,手动调整表头和数据结构;接着将多个数据源复制到一个汇总表格中,手动进行数据匹配和统计;最后再根据汇总数据制作分析报告。整个过程通常需要3-4小时,而且容易出现人为错误。
使用TRAE SOLO Work后,整个流程实现了自动化。点击运行脚本后,系统会自动完成数据下载、格式转换、数据合并、统计分析等全部步骤,整个过程只需要15分钟不到。更重要的是,数据准确性大幅提升,通过标准化的券商名称映射,机构名称匹配准确率达到99%以上,不再需要人工逐行核对。
最后,针对外部公开数据,我还通过SOLO设置了自动下载,每周一早晨到公司,打开SOLO就能直接拿到已经准备好的Excel文件。
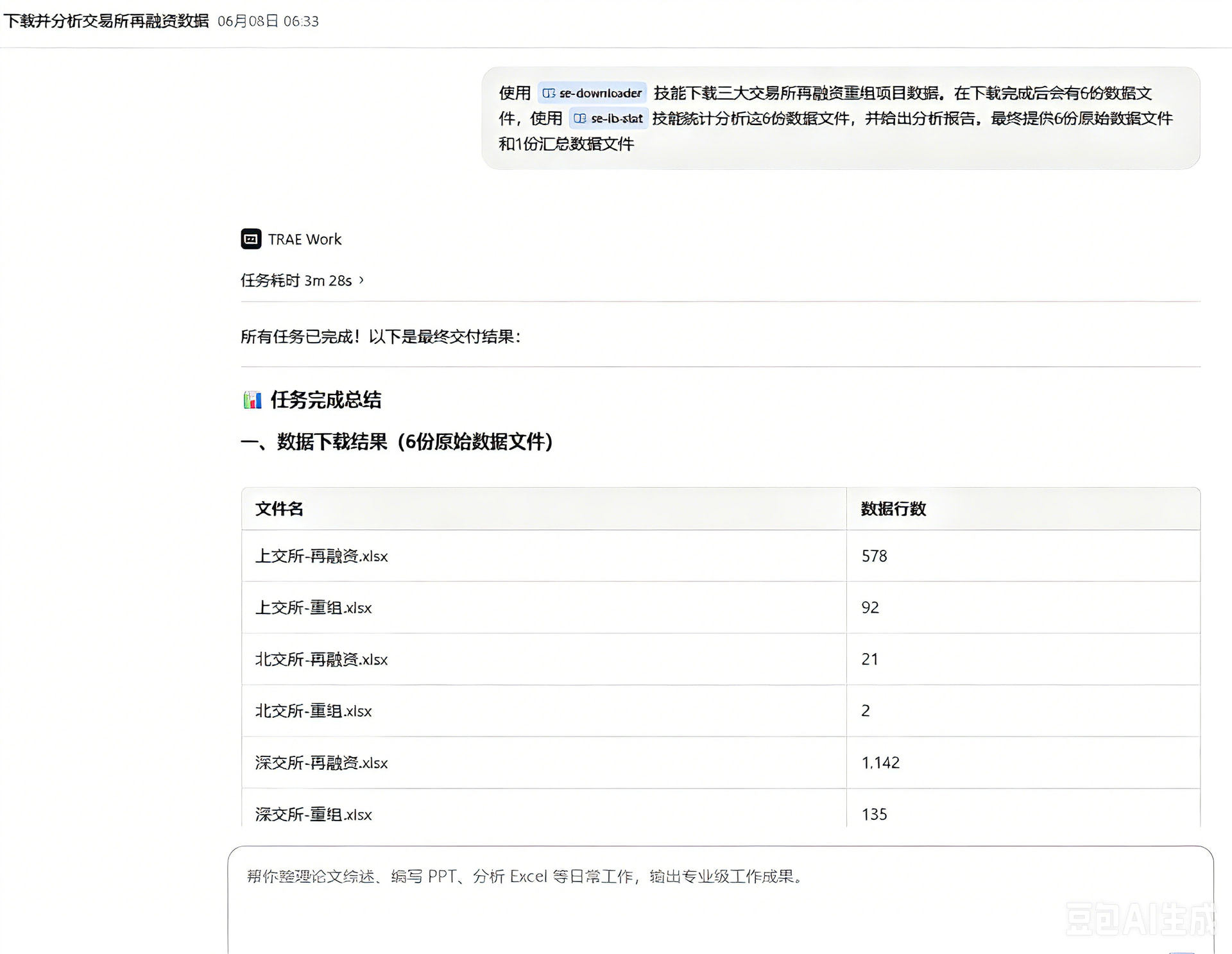
图片是真实的,用豆包处理了一下截图水印,所以右下角会有标记。
我还希望 TRAE SOLO Work 优化什么(办公场景的产品建议):
- 支持更多数据源接入 :目前主要依赖手动导入Wind数据和港股数据,希望能够直接对接更多数据源,实现数据的自动同步。
- computor use,视觉操作 :最好能提供类似其他工具的computor use,视觉操作浏览器的功能。这样日程办公中的节点审批等点击类操作也能用TRAE SOLO Work实现了,现在还不行。
- SOLO支持邮件发送功能,目前垂类如Wind Alice都已经支持用户自行配置邮件服务,实现文件的收发。如果SOLO能够支持邮件收发功能,日常办公中可以应用到更多的场景。