1、Skill 简介
播客内容提取器(podcast-extractor) 是一个专门解决"播客太长、信息太散、手动整理耗时"痛点的 Skill。
你只需要把播客的文字稿丢给它,它就能自动帮你:
- 提炼一句话总结 + 3-5 个核心观点
- 按话题拆解详细内容(含关键数据、案例、方法论、原话摘录)
- 整理可执行建议(按优先级分类)
- 汇总引用资源、开放性问题
- 输出一份精美的单文件 HTML,本地直接打开,无需联网
适合谁用:知识工作者、内容创作者、学习者、研究员——任何需要从长音频/访谈中提取价值的人。
2、使用场景
真实痛点
现在的播客/访谈越来越长,动辄 2-3 小时。比如最近罗福莉(原DeepSeek 核心成员)接受了一场 3.5 小时的深度访谈。
在点开播放键之前,我完全不知道这 3.5 小时里讲了什么:
- 不知道值不值得听:3.5 小时是很大的时间投入,万一内容不适合自己?
- 不知道重点在哪里:访谈涉及多个话题,哪些是我关心的?
- 无法针对性收听:即使决定听,也不知道该重点听哪一段
之前的做法
我之前的做法是:硬着头皮从头开始听,听到一半发现不是自己想听的,或者听到某个感兴趣的话题,但不知道后面还有没有更深入的讨论。时间花了,收获却不确定。
现在的做法
现在我会先把文字稿丢给这个skill,5-10 分钟后得到一份结构化的 HTML 预览:
- 一句话总结:30 秒判断这个播客是否适合自己
- 核心观点卡片:罗列最重要的观点,带确定性标签
- 话题卡片 + 时间戳:每个话题的概览和对应的时间段
- 可执行清单:哪些建议可以立即落地
然后我决定:
- 如果核心观点都不感兴趣 → 直接跳过,省下 3.5 小时
- 如果有 2-3 个话题很吸引我 → 直接跳到对应时间戳收听
- 如果整体很有价值 → 完整收听,同时用 HTML 笔记作为参考
省下的时间:从"盲听 3.5 小时" → “预览 10 分钟 + 精准收听 30 分钟”。
## 3、创作过程
这个 Skill 不是一次成型的,而是经历了 4 轮真实迭代,每一轮都来自实际使用中的反馈。
第一轮:确定提取框架
最初的起点很简单:“播客太长了,我想知道里面讲了什么重点”。
我和 SOLO 一起梳理了 8 个提取维度:
1. 元信息(播客名、嘉宾、时长、标签)
2. 一句话总结
3. 核心观点(3-5 个,带确定性标签)
4. 关键数据与事实
5. 案例与故事
6. 方法论与框架
7. 可执行建议(按优先级分类)
8. 时间戳映射
第二轮:从 Markdown 升级到 HTML
第一版输出是 Markdown,形式比较枯燥,于是添加了一套 温暖纸质风格的 HTML 模板:
- 米白背景 + 暖棕强调色 + 灰蓝辅助色
- 卡片式布局,圆角阴影
- 金句引用框、优先级标签、确定性标签
- 底部可折叠的原文区域

第三轮:建立完整 HTML 模板
为了让 HTML 输出质量可控,添加了完整的 HTML 模板。模型只需要按模板填空,就能保证输出质量一致。
第四轮:Skill打磨优化
分层加载结构:
```
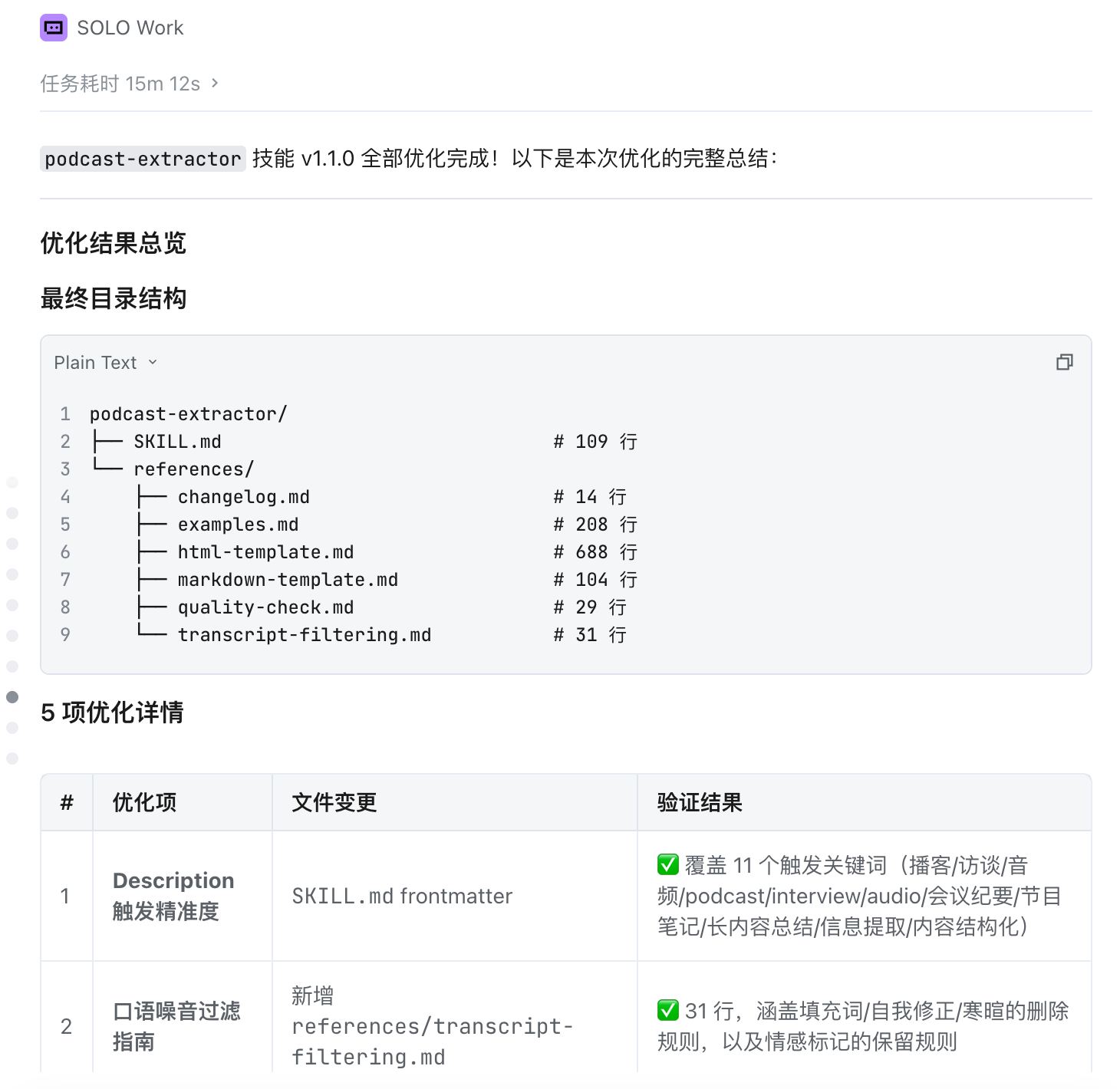
podcast-extractor/
├── SKILL.md (109 行,核心指令)
└── references/
├── html-template.md # 完整 HTML 模板
├── markdown-template.md # Markdown 备选模板
├── examples.md # Input/Output 示例
├── transcript-filtering.md # 口语噪音过滤指南
├── quality-check.md # 输出质量检查清单
└── changelog.md # 变更日志
```
同时做了 5 项优化:
1. 增强触发精准度:description 覆盖 11 个关键词(播客/访谈/音频/podcast/interview/会议纪要/节目笔记等)
2. 口语噪音过滤:提供填充词/自我修正/寒暄的删除规则
3. 质量检查清单:语法检查 + 占位符检查 + 内容完整性检查
4. 交互增强:返回顶部按钮 + 话题快速导航
5. 版本管理:添加 version 字段和变更日志
4、使用步骤
1. 获取播客文字稿:使用妙记或其它工具生成文字稿
2. 上传文件:将文字稿文件提供给 SOLO
3. 触发 Skill:SOLO 会自动识别并调用播客内容提取器
4. 等待生成:约 5-10 分钟,Skill 会完成分析和 HTML 生成
5. 查看结果:下载生成的 HTML 文件,本地浏览器直接打开
输出格式
- 默认:精美 HTML 页面(单文件,无外部依赖)
- 备选:Markdown 格式(用户明确要求时)
5、效果展示
使用前后对比
| 维度 | 使用前 | 使用后 |
|------|--------|--------|
| 时间投入 | 盲听 3.5 小时 | 预览 10 分钟 + 精准收听 30 分钟 |
| 内容判断 | 听完才知道值不值 | 预览后决定是否收听 |
| 针对性 | 从头到尾线性收听 | 按时间戳跳转到感兴趣部分 |
| 信息覆盖 | 容易遗漏重点 | 8 维度全覆盖,不遗漏 |
| 笔记整理 | 边听边记,打断体验 | 收听时参考 HTML 笔记 |
使用示例:罗福莉 3.5 小时深度访谈
我的输入:
skill经过十多分钟,完成分析:
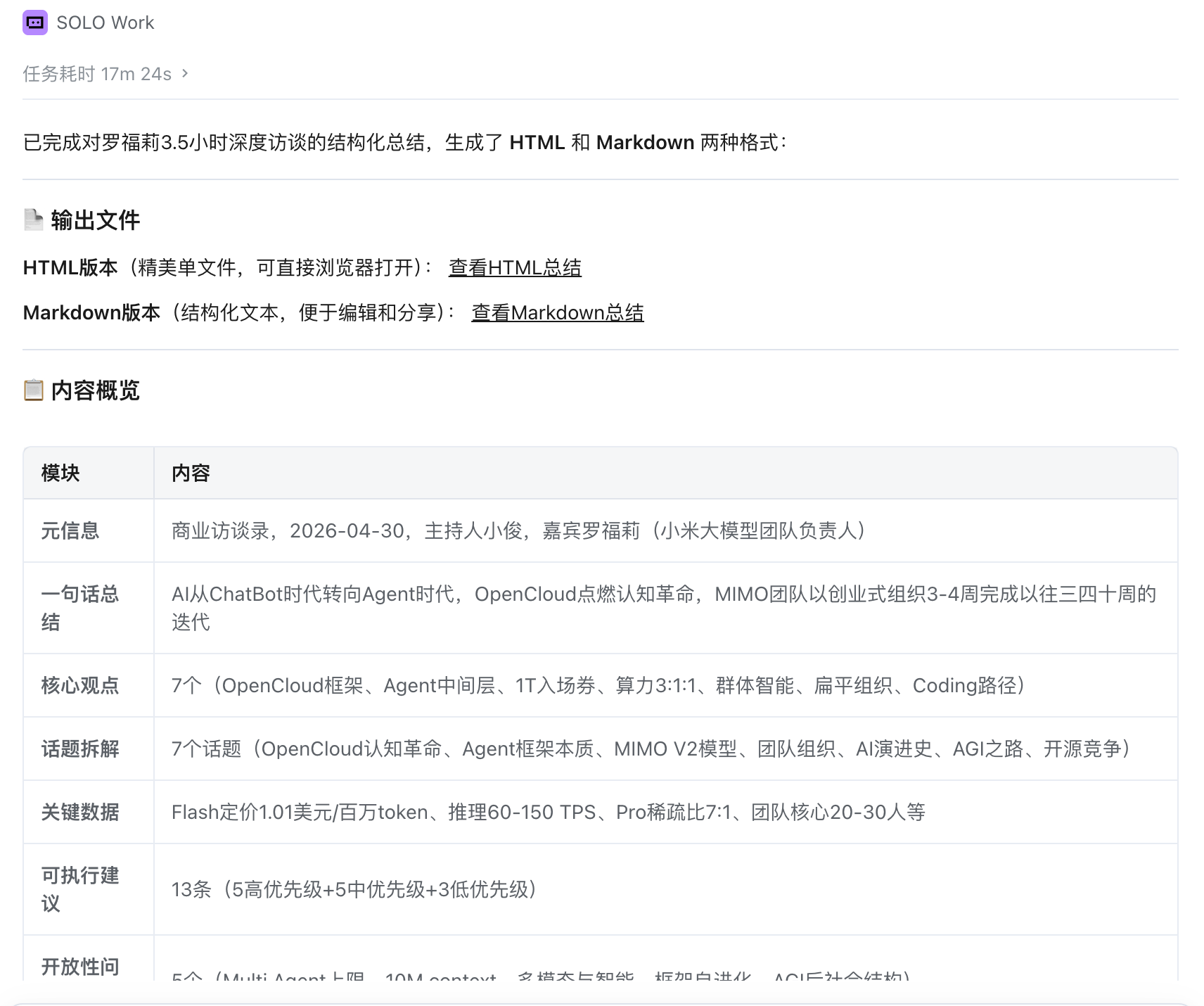
下面是skill生成的html版本的总结,由于报告很长,以下截取了一部分:
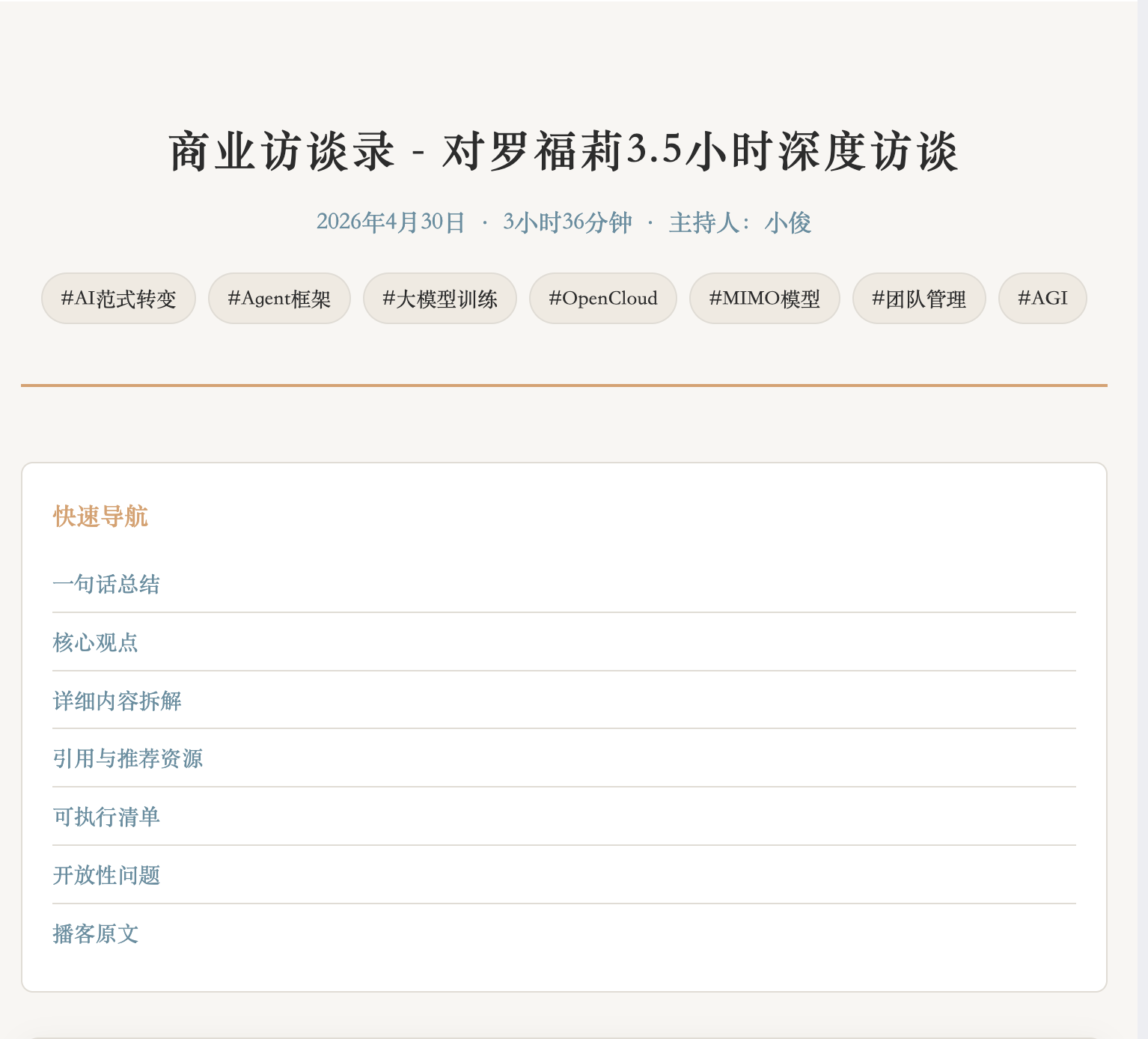



HTML 页面效果
- 温暖纸质风格:米白背景 + 暖棕强调色,阅读舒适
- 快速导航:顶部导航栏,一键跳转到任意板块
- 返回顶部:滚动后右下角出现返回顶部按钮
- 响应式设计:手机、平板、电脑都能完美阅读
6、Skill 链接
Skill 地址:myskills/podcast-extractor at main · sarahxu0205/myskills · GitHub
7、总结与思考
最满意的地方:
1. 从真实痛点出发:每次迭代都来自实际使用中的反馈。
2. 输出质量可控:通过完整的 HTML 模板 + 占位符系统,确保每次输出的结构和风格一致。
3. 分层架构:references/ 目录让模型按需加载,不浪费上下文。
后续还想怎么优化:
1. 支持更多输出格式:PDF、Notion 导入格式
2. 多语言支持:英文播客自动输出英文笔记
3. 智能话题拆分:不依赖时间戳,基于语义自动划分话题边界
如果你也经常听播客、看访谈、参加会议,欢迎试用这个 Skill!
期待你的反馈!
以上,感谢你的阅读。![]()