该专区只发布初赛Demo帖,不交流,请于7月15日(含)前在该专区发布作品帖,即为报名。
tips:请报名通过后再来发布初赛作品帖哦~
大赛交流互动请前往大赛交流专区: 大赛交流专区 - TRAE 官方中文社区
该专区只发布初赛Demo帖,不交流,请于7月15日(含)前在该专区发布作品帖,即为报名。
tips:请报名通过后再来发布初赛作品帖哦~
大赛交流互动请前往大赛交流专区: 大赛交流专区 - TRAE 官方中文社区
复赛呢复赛呢
看来很激烈,还有初赛
复赛呢!!
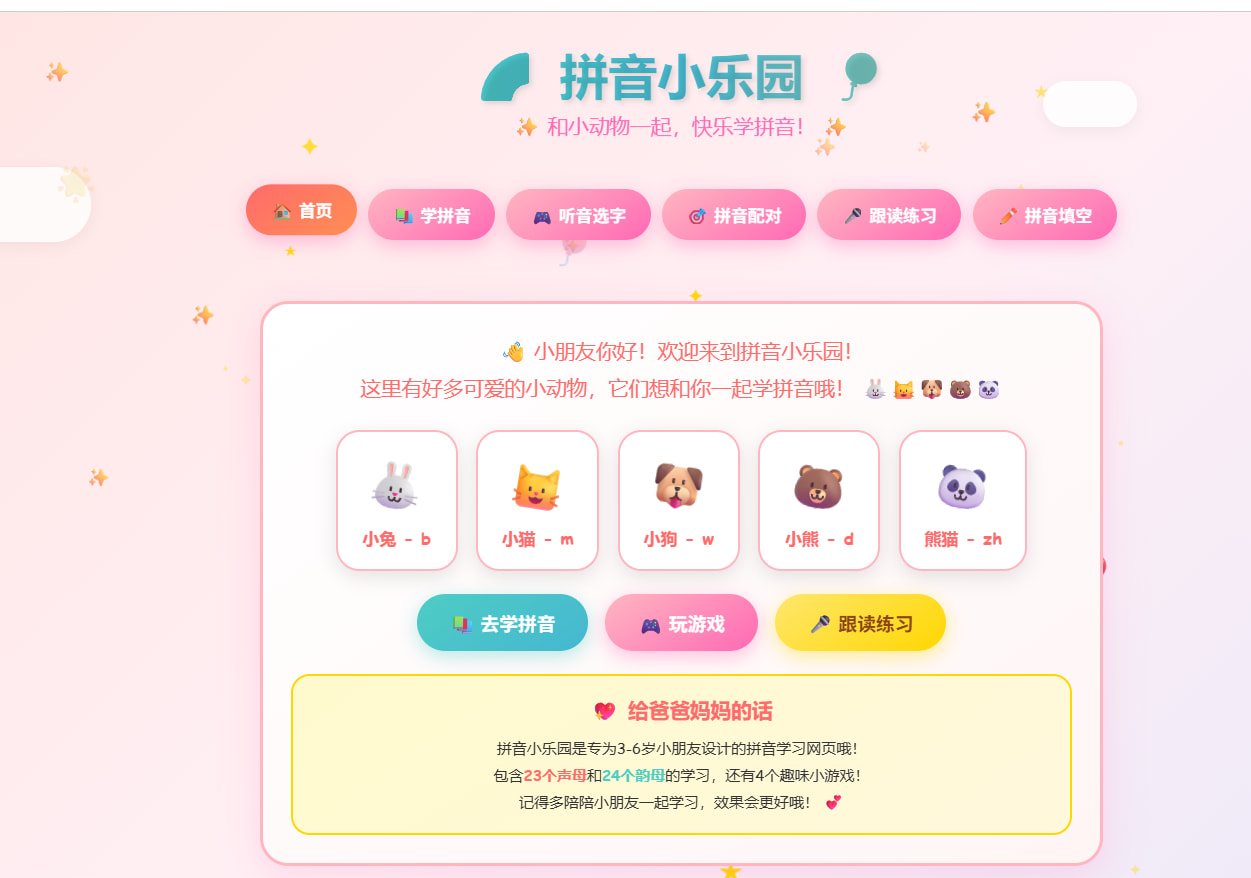
【学习工作赛道】拼音小乐园——四岁小朋友学习拼音,提供学习乐趣
![]() 创意名称 + 创意介绍
创意名称 + 创意介绍
创意名称
拼音小乐园
—— 给四岁女儿的一封情书,也是一份用代码写成的父爱
想解决什么问题
四岁女儿说"爸爸,我要学拼音,像哥哥姐姐那样!"
但市面上的拼音 App,不是三秒一个弹窗广告,就是界面复杂到大人看了都头疼。
我想用自己会的技术,给她做一个干干净净、好玩有趣、她真的愿意主动玩的拼音学习工具。
为什么会想到做这个
那是一个普通的晚上,女儿拿着我的手机乱划,突然停下来问我:
“爸爸,这个字怎么读?”
我教了她几个拼音之后,她兴奋地说:
“爸爸,我要学拼音!”
那一刻我愣住了——作为一个做技术的爸爸,我能用代码写 App、写网页、写各种复杂的系统,但从来没想过,给女儿做一件属于她的、专属于她的东西。
打开应用商店搜"拼音学习",满屏都是付费订阅、 banner 广告、氪金弹窗。
孩子的小手一戳就跳到别的页面,花了钱不说,学到的内容少之又少。
我决定:自己来。
与其在那些乱七八糟的 App 里浪费孩子的时间,不如用自己会的技术,给女儿做一个"爸爸牌"专属学习工具。
于是,"拼音小乐园"诞生了。
大概是什么产品
一款专为 3-6 岁儿童设计的拼音学习互动网页。
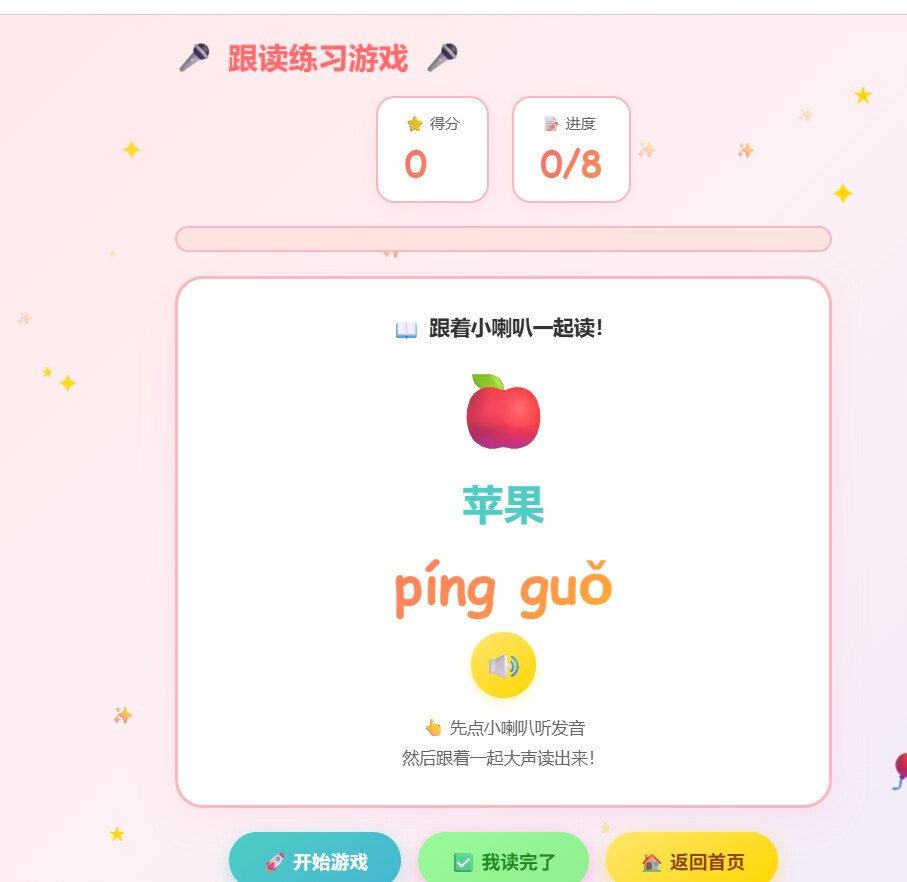
23 个声母 + 24 个韵母 + 4 个趣味游戏,全程动画陪伴,点击即可发音。
双击 HTML 文件就能用,无需下载、无需联网、没有任何广告。
女儿每天放学后第一件事,就是喊"爸爸,我要玩拼音小乐园!"
面向哪些用户
| 用户群体 | 规模估算 | 核心诉求 |
|---|---|---|
| 全国约 1 亿+ | 好奇心强,需要有趣的方式引导学习 | |
| 约 2-3 亿 | 希望孩子赢在起跑线,但工作忙、时间碎片化 | |
| 全国约 200 万+ | 需要免费、好用、无广告的教学工具 |
在什么场景下使用
早晨 10 分钟:送幼儿园前,孩子吃早餐时玩一局"听音选字"
车上无聊时:自驾出游、等红绿灯,孩子拿出手机自己玩
等餐时:餐厅等上菜,孩子不哭不闹,专注学拼音
睡前亲子时光:熄灯前和爸爸一起玩一局,是游戏也是学习
周末大屏展示:老师用投影仪带全班一起做拼音游戏
当前痛点分析
| 痛点 | 真实场景 | 数据支撑 |
|---|---|---|
| 孩子正学得认真,突然弹出"下载送皮肤",一点就跑 | 调研显示 82% 的儿童 App 含广告 | |
| 四岁孩子手指小,点击"下一步"总是点错位置 | 平均一款早教 App 含 7+ 个层级菜单 | |
| 静态卡片配录音,孩子看三秒就跑了 | 儿童注意力平均仅能维持 3-5 分钟 | |
| 没 WiFi 就没法用,在农村、车上根本打开不了 | 2023 年农村地区网络覆盖率仅 60% | |
| App 要求获取通讯录、定位、摄像头 | 儿童 App 隐私泄露事件年增 40% |
如果没有我的产品
家长只能在应用商店里反复试错,装了删、删了装;
孩子面对满是广告的屏幕,要么学不进去,要么学到的是错误信息;
老师想用数字工具辅助教学,却找不到一个免费无广告的方案。
![]() 教育价值:弥合教育资源的不平等
教育价值:弥合教育资源的不平等
城市里的孩子有iPad、有线上课程、有外教一对一。
但在那些没有优质资源的角落,那些用着父母千元机的孩子,他们怎么办?
拼音小乐园打破了这些门槛:
当城里的孩子在上千块一节的私教课时,农村的留守儿童用一部旧手机,打开拼音小乐园,也可以同样快乐地学习。
这就是我认为这个作品最有意义的地方。
![]() 亲子价值:让陪伴更有质量
亲子价值:让陪伴更有质量
现代父母都知道"高质量陪伴"的重要性,但996的工作、碎片化的时间,让陪伴变成了"人在心不在"。
拼音小乐园创造了一种新的陪伴方式:
有一天,女儿跑过来跟我说:“爸爸,我今天在幼儿园读拼音,老师夸我了!”
那一刻,我觉得这比任何 KPI、任何业绩都值得。
![]() 效率价值:把碎片时间变成学习时间
效率价值:把碎片时间变成学习时间
| 传统学习 | 拼音小乐园 |
|---|---|
| 需要固定 30 分钟坐下来学 | 随时打开、随时结束 |
| 需要家长全程陪伴讲解 | 孩子独立玩耍,家长做自己的事 |
| 没效果就浪费了时间 | 玩 5 分钟也有 5 分钟的收获 |
以前孩子拿手机 = 看视频/玩游戏
现在孩子拿手机 = 学拼音 + 玩游戏
一部手机,两种可能。
![]() 产品价值:技术实现的亮点
产品价值:技术实现的亮点
| 技术亮点 | 实现方式 | 解决的问题 |
|---|---|---|
| Web Speech API | 浏览器内置语音引擎,无需音频文件 | 节省 95% 的文件体积,实现即时发音 |
| 纯 CSS 动画 | 用 CSS keyframes 替代 JS 动画 | 60fps 流畅运行,低配设备也流畅 |
| 响应式布局 | 一套代码适配手机/平板/电脑 | 一处开发,全平台使用 |
| 单文件交付 | 所有 HTML/CSS/JS 集成在一个文件 | 零安装、零依赖、双击即用 |
| 离线可用 | 不依赖任何外部资源 | 没网络也能玩 |
![]() 差异化竞争优势
差异化竞争优势
| 对比维度 | 市面拼音 App | 拼音小乐园 |
|---|---|---|
| 价格 | 付费订阅/内购 | 完全免费 |
| 广告 | 弹窗/Banner/激励视频 | 零广告 |
| 安装包大小 | 50MB-200MB | 100KB(仅为常规 App 的 0.1%) |
| 首次使用 | 注册→登录→验证→付费 | 双击文件,2秒开始 |
| 隐私权限 | 读取通讯录/定位/相册 | 零权限,纯本地运行 |
| 趣味性 | 静态卡片/单调录音 | 全程动画+游戏+奖励 |
| 扩展性 | 受平台限制 | 一个文本编辑器就能改 |
"这是我用代码写给女儿的一封情书,
也是我希望能帮助到全国每一个想学拼音的孩子的一份心意。"
附件
拼音小乐园.zip (11.2 KB)
pinyin-learning-kids.html (58.6 KB)
3 个 Session ID
第一个:3071394522863508:93dbfb184fd9e351bacf2c98ba39c67c_6a30c2526c578958656a8198.6a30d6f662ce18a38780890c.6a30d6f662ce18a38780890a:TRAE Work CN.0.1.19.no_sid.no_ppe.T(2026/6/16 12:54:14)
第二个:3071394522863508:bd5ea54206be9e8c6177ee38df6346e7_6a30c2526c578958656a8198.6a30d72d62ce18a387808917.6a30d72d62ce18a387808915:TRAE Work CN.0.1.19.no_sid.no_ppe.T(2026/6/16 12:55:09)
第三个:3071394522863508:5cbde53a95dc0908056c778a55412042_6a30c2526c578958656a8198.6a30d8c462ce18a38780892e.6a30d8c462ce18a38780892c:TRAE Work CN.0.1.19.no_sid.no_ppe.T(2026/6/16 13:01:56)
截图
报名报名报名!!!
报名!
报名!
x-layout —— 生产级的 AI 工作流编排平台
副标题:可视化拖拽搭建,零代码驱动 AI 业务流
企业在落地 AI 应用时,常陷入"单点调用"的困境——每个 AI 能力(LLM 对话、文档理解、代码执行、数据查询)都是孤立的工具,无法串联成完整的业务逻辑。例如"从用户提问 → 检索知识库 → LLM 推理 → 格式化输出 → 写入数据库"这条链路,目前需要大量手写胶水代码才能跑通。
在调研 Dify、LangFlow 等开源项目时发现,尽管它们在提示词工程方面做得很好,但在可扩展的节点体系和灵活的 DAG 执行引擎上仍有不足。多数平台将节点类型写死在引擎里,新增一种节点需要改动引擎核心代码,这违背了开闭原则。
我们希望打造一个节点可插拔、流程可编程、执行可观测的工作流平台,让开发者像搭积木一样组装 AI 业务流程,同时让引擎本身保持简洁、可测试。
Web 应用(SaaS 平台)—— 前端可视化编辑器 + 后端 DAG 执行引擎,用户通过浏览器即可完成工作流的设计、调试、部署和监控。
| 用户角色 | 特征 |
|---------|------|
| AI 应用开发者 | 需要快速将 LLM、RAG、代码等多环节编排成业务流水线 |
| 技术产品经理 | 懂业务逻辑但不想写代码,希望通过可视化方式定义 AI 流程 |
| 企业内部 IT 团队 | 需将 AI 能力嵌入现有系统(CRM、工单、审批流),需要标准化接口 |
| AI 学习/培训人员 | 正在学习工作流编排和 LLM 应用开发的学生或转行者 |
智能客服流程编排:用户提问 → 意图识别 → 知识库检索 → LLM 生成 → 工单创建
文档自动化处理:上传文件 → 文本提取 → 结构化解析 → LLM 摘要 → 写入数据库
数据分析流水线:SQL 查询 → 数据清洗 → LLM 分析 → 图表生成 → 报告输出
多模型协同推理:问题分发到多个 LLM → 结果聚合 → 交叉验证 → 择优输出
自动化测试 / QA:输入测试用例 → 调用被测 API → LLM 判断结果 → 生成测试报告
| 痛点 | 具体表现 |
|------|---------|
| 胶水代码泛滥 | 每个 AI 业务场景都需要手写 Python/Node.js 脚本来串联 API 调用、数据转换、条件判断 |
| 节点类型耦合 | 现有平台的新节点需要修改引擎核心代码,社区贡献门槛高 |
| 执行过程黑盒 | 工作流执行时无法查看中间结果,调试困难,出问题难以定位 |
| 缺少企业级特性 | 缺乏版本管理、执行历史、权限控制等生产环境必备功能 |
| 扩展成本高 | 想接入私有模型、内部 API 或自建知识库,往往需要 fork 项目做深度定制 |
降低 AI 应用开发成本:将原来需要 2-3 天手写的胶水代码,缩短到 30 分钟的可视化拖拽搭建
减少重复造轮子:企业可将通用的 AI 业务流(客服、审核、质检)封装为模板,跨部门复用
提升交付效率:开发者只需实现自定义节点(单个文件),即可无限扩展平台能力,无需改动引擎核心
降低人才门槛:非技术用户(产品、运营)可通过可视化界面编排简单流程,减轻开发团队负担
节点可插拔架构:新增节点类型只需实现 BaseNode 接口并注册,引擎无需任何改动。目前已内置 11 种节点类型(LLM、代码、条件判断、HTTP 请求、文档处理、数据聚合等)
DAG 并行执行:基于拓扑排序的并行执行引擎,可同时执行无依赖关系的节点,大幅缩短工作流总耗时
实时执行状态反馈:执行过程中前端实时展示节点状态(运行中/成功/失败/跳过),帮助快速定位问题
完备的数据持久化:工作流定义、节点配置、边关系、执行历史全部存入 MySQL,支持历史回查和审计
开闭原则设计:NodeRegistry 自动注册机制,新增节点零配置、零引擎改动
类型安全的节点契约:Pydantic v2 驱动节点输入/输出校验,运行时保证数据格式正确
全栈可观测:Loguru 结构化日志 + 执行记录持久化,支持端到端追踪
x-dify-prd.html (48.9 KB)
首页的小动物和拼音没有任何必然联系呀~感觉有点误导性