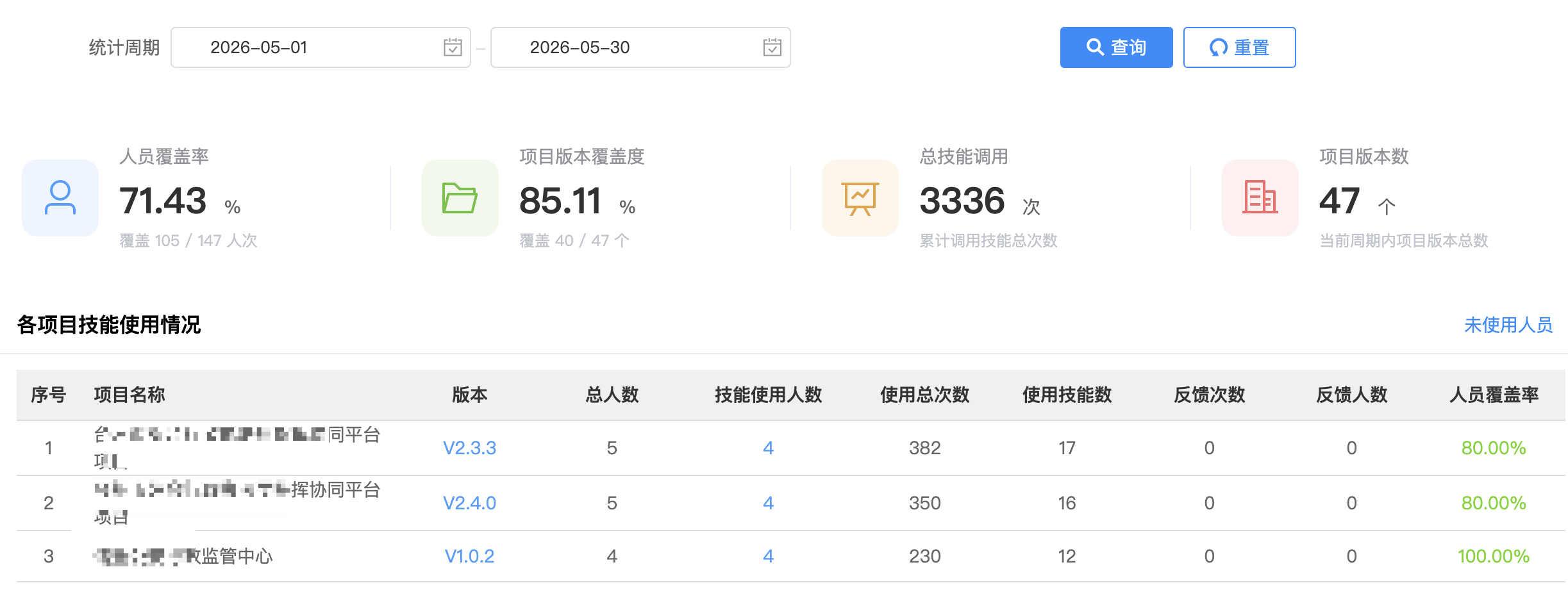
我的行业 / 角色 / 职业
- 行业:政府 SaaS 平台
- 角色:研发岗
- 职业:全栈工程师
- 使用周期:从 2026 年 3 月开始,到现在 3 个月,亲历团队从 L0(无 AI)走到 L3(技能链路贯通)
我日常干的事情跨度很"杂"——早上可能还在和前端对联调接口,下午就被产品拉去澄清 PRD 里的边界场景,晚上还得加班帮客户排查一个生产环境的奇怪问题。所以我需要的 AI 不是"专精一项",而是能跟着我的工作流走、能在不同场景之间无缝切换。
刚好,我们交付中心自研的"技能市场"项目(icinfo-agent-skills),通过 TRAE SOLO Work 加载并执行,给我的就是这种感觉。技能市场里沉淀了 30+ 个技能,前端、后端、需求、测试、交付全链路都有;TRAE SOLO Work 是承载这些技能被调用、被组合、被埋点统计的那个 Agent 平台——一个负责"长技能",一个负责"跑技能",分工很清晰。
我的高频工作内容
把一天的活拆开看,我大概 80% 的时间耗在这 5 件事上:
- 写后端代码:ICInfo Framework + Spring Boot + MyBatis 这套,分层写 Controller、Service、Mapper,偶尔要写分布式事务、长链路一致性这些高风险场景
- 写前端代码:Vue2 + TypeScript + Element UI,列表页、表单页、详情页、流程图、统计图都干
- 看需求 / 改 PRD:产品给过来的 PRD 经常有"留白",要去找产品经理澄清边界
- 拉项目知识库:每个新项目我都要先建
.project-kb,把工程规则、模块边界、反模式库沉淀下来 - 写代码 / 审查代码:自己写的要 review,同事写的也得 review,提 PR 之前过一遍
剩下 20% 是开会、答疑、运维杂事。
我会在哪些办公场景使用 TRAE SOLO Work
下面这 4 个是我每天都用的场景,按"省事程度"排:
办公场景 1:接新需求前的"知识库打底"
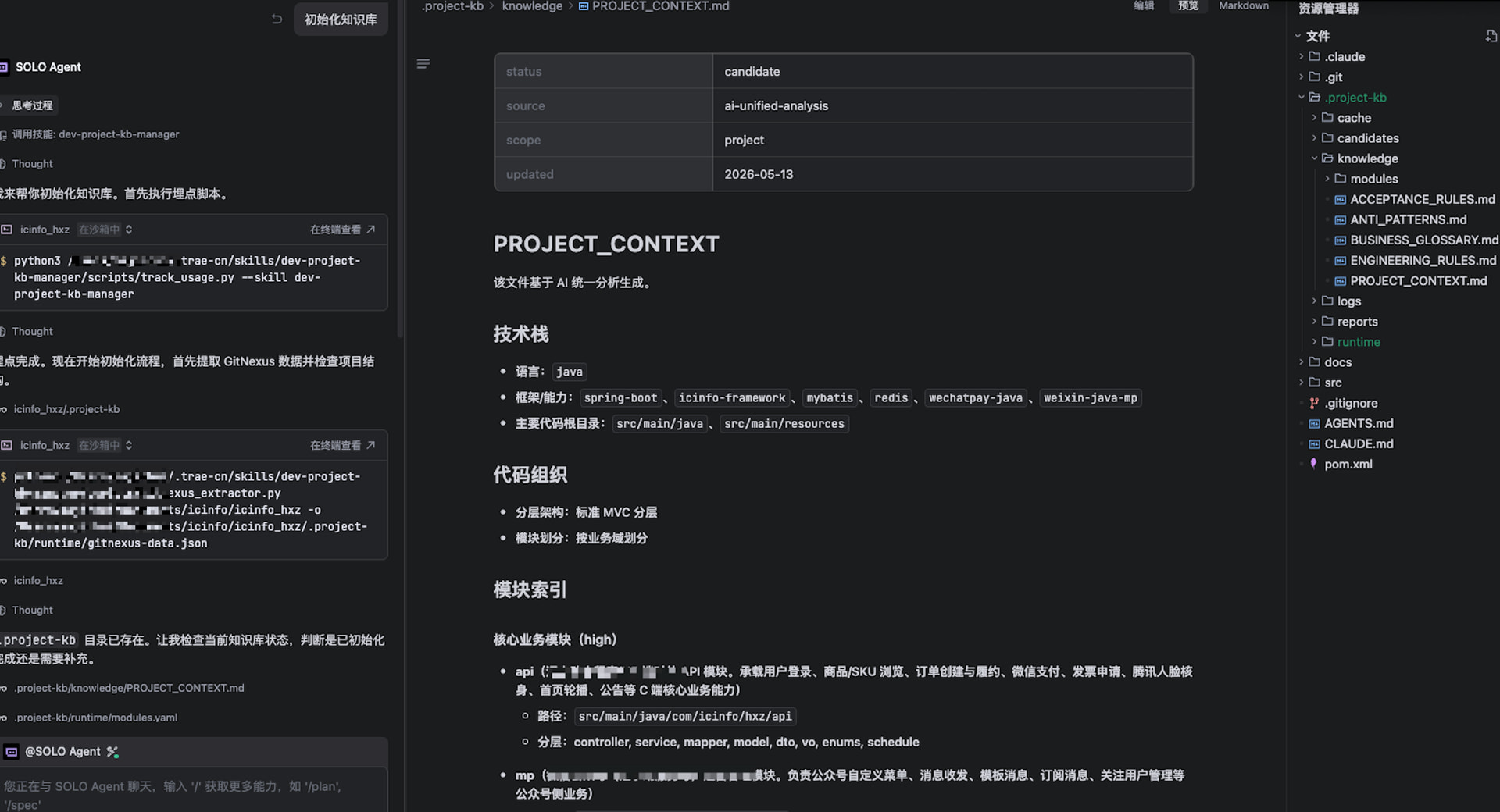
新项目一来,我先做的事情是建 .project-kb/。但建知识库这个活,光是"找文档 + 抽规则"就要半天。
我现在的做法:
- 在 TRAE SOLO Work 里直接说:“用
dev-project-kb-manager技能,给项目 X 初始化知识库” - AI 读完项目代码 + 已有文档后,把
PROJECT_CONTEXT.md、ENGINEERING_RULES.md、模块卡片全生成出来 - 我做的是审核 + 改写,不是从零写
对比:以前一个新人接项目,光"摸清项目"就要 2 周;现在配合知识库 + 后面要讲的需求澄清,第 2 天就能上手写代码。
办公场景 2:PRD 写完到开发设计之间的"门禁"
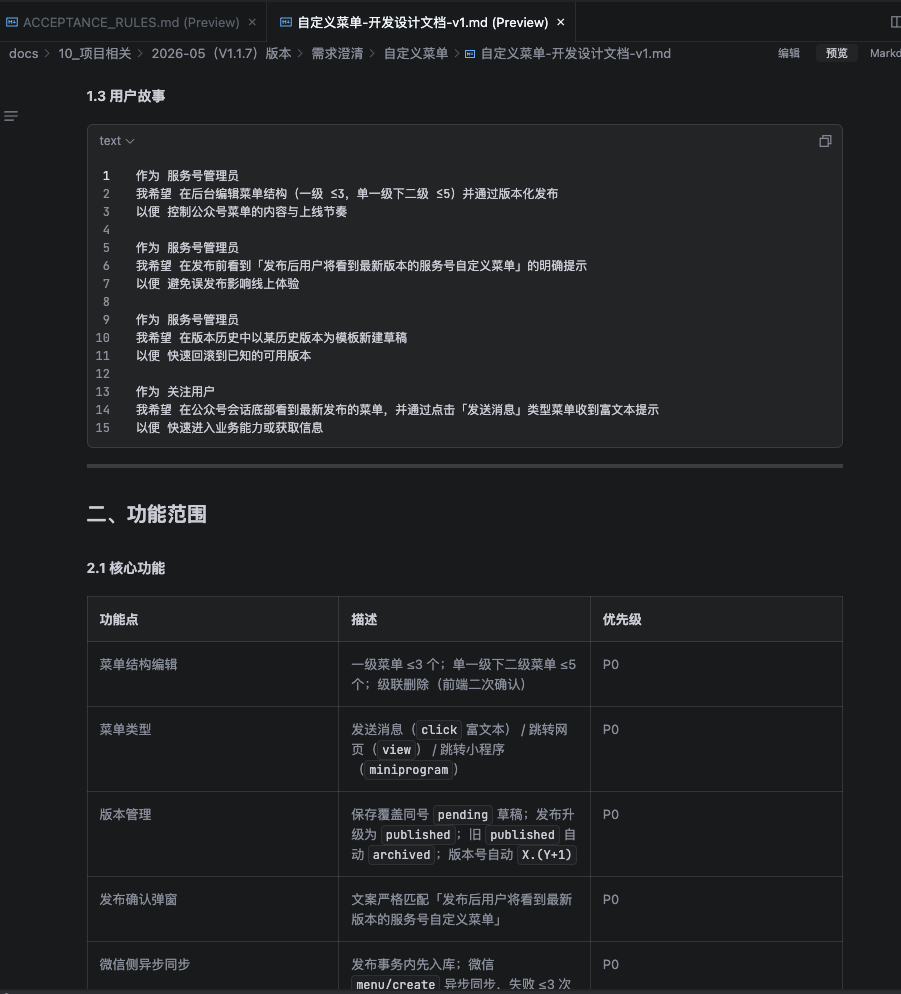
PRD 写完 ≠ 可以写代码了。我们团队有道硬门禁叫 codegen_ready,没有这张门禁,开发助手会拒绝出设计文档。
我现在的做法:
- PRD 写完,喊
req-prd-clarification技能 - AI 把 PRD 拆成"已确认事实 / 暂存假设 / 冲突项"三类
- 按 P0/P1/P2 分级铺出"决策卡"——每张卡是一个必须澄清的边界问题
- 产品经理逐条确认后,状态升级为
codegen_ready - 我再喊
dev-backend-assistant或dev-frontend-assistant出开发设计
对比:以前 PRD 模糊就模糊,“到时候再说”——结果开发到一半返工;现在门禁前置了 90% 的扯皮。
办公场景 3:写后端代码 / 改 BUG
这是用得最多的。
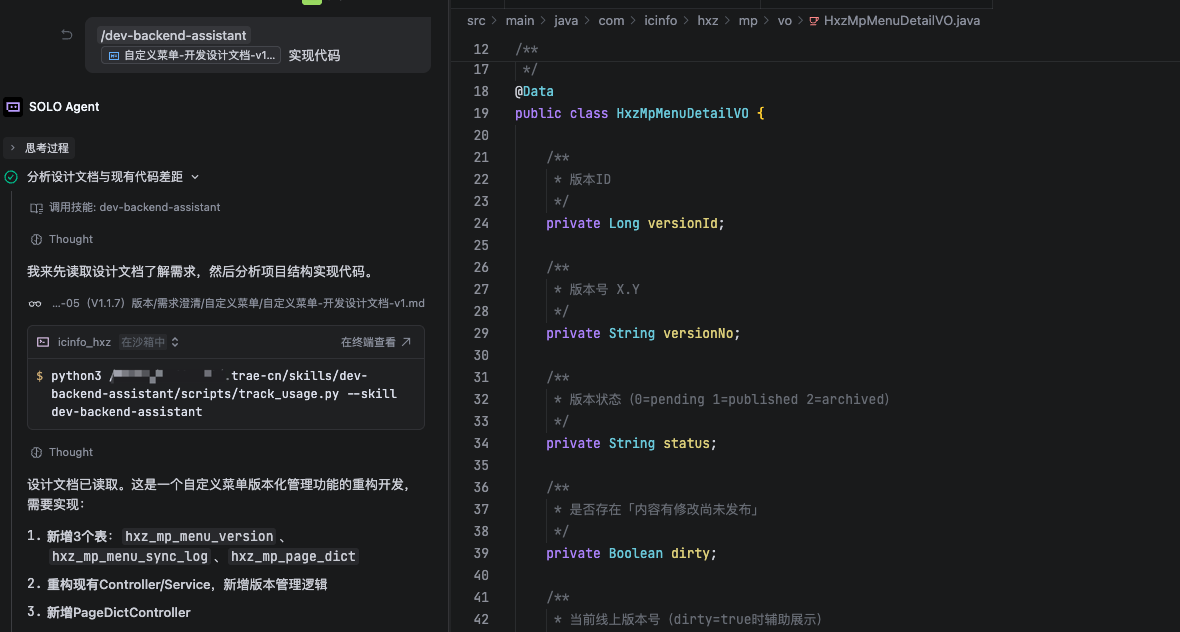
我现在的做法:
- 在 Trae 里说"用
dev-backend-assistant技能,写一个 XXX 接口" - AI 识别项目生态——是 ICInfo 主路径还是
generic降级 - 自动读
.project-kb里我刚才建好的工程规则、模块边界、反模式库 - 给我吐出一份符合我司规范的分层代码(Controller、Service、Mapper、DTO、VO 全套)
- 我做的是改字段 + 调逻辑,不是从零写
对比:以前写一个标准 CRUD 接口,模板代码 + 业务代码至少 1.5 小时;现在 AI 给我 80% 的底子,我补 20% 业务文档,40 分钟搞定。
办公场景 4:代码写完,一键跑完测试全流程
以前我对"测试"两个字是抗拒的——后端代码刚提交,测试那边就开始追着我要接口文档;UI 还没调通,自动化脚本的活又压过来;测完了还得自己写测试报告。一个完整的测试环节,至少要协调 3 个角色,一个跨模块的测试活动轻松吃掉两天。
现在用 test-assistant 这个调度中心,我自己一个人就能把活全干了。
我现在的做法:
- 后端代码 merge 之后,在 TRAE SOLO Work 里说:“用
test-assistant技能,给 XX 模块生成测试方案 + 测试用例 + 接口自动化脚本” - AI 自动识别场景——是要测试方案、还是要测试用例、还是只要接口脚本——按关键词路由到对应的子技能
- 我不用关心它里面挂了几个子技能,只告诉它"我要什么"
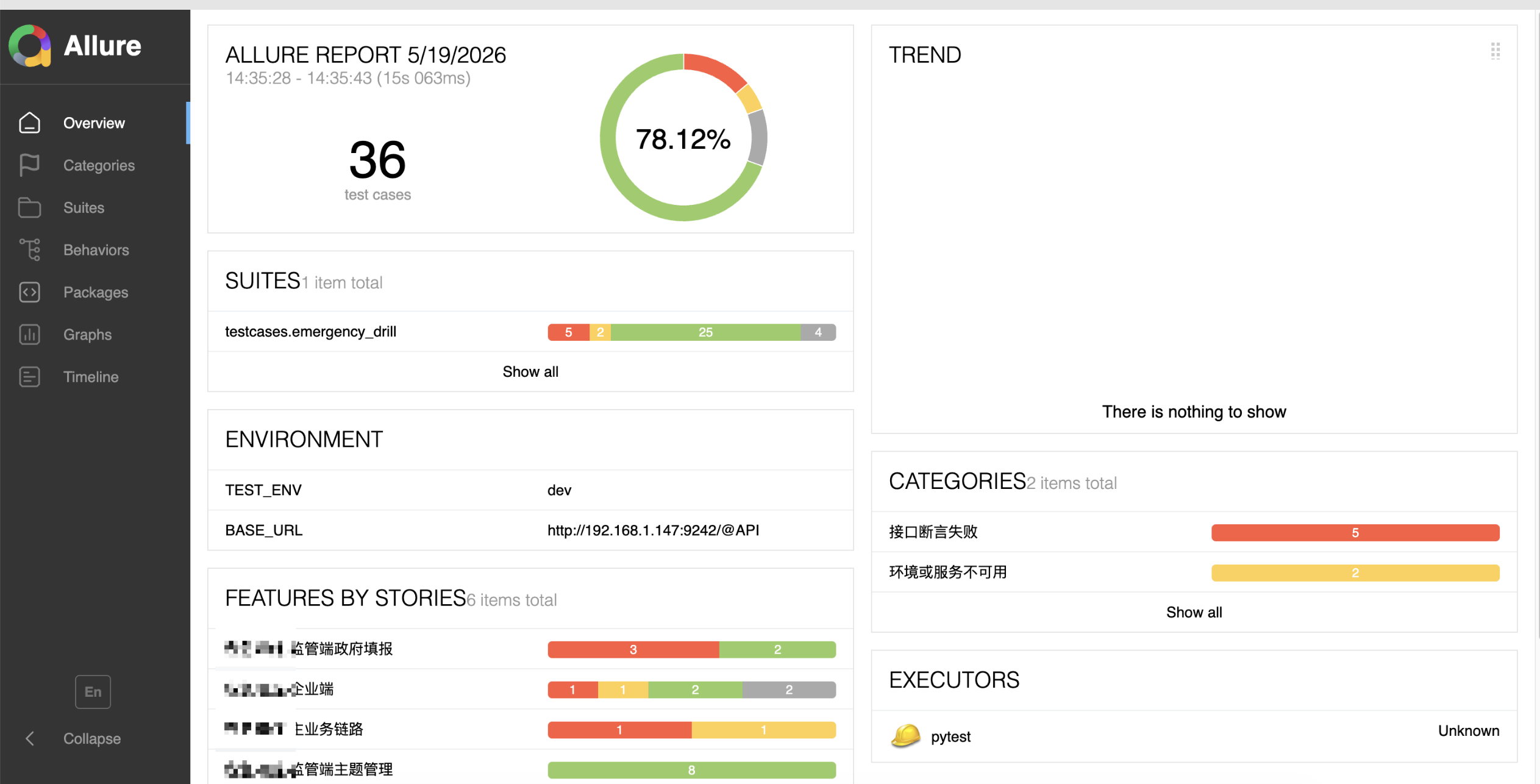
- 接着让它执行 P0 级别的 UI 自动化(用 Playwright 跑)
- 跑完直接给我出功能测试报告 Word 文档
真实例子:
- 案源管理模块改完,我一句话:“用
test-assistant,根据刚才的 PRD 给我出测试用例,再生成 Python 接口测试脚本” - AI 自己从 PRD 里抽出 21 条用例,pytest 脚本一次跑通 19 条,2 条失败的原因是后端真的少写了一个边界判断——我马上回去补
- 补完再跑,全绿,AI 直接把 Word 测试报告吐给我,我贴到交付文档里就行
对比:以前一个跨模块的测试活动要 2 天;现在我自己一个下午搞定,↓ 60%。
最爽的是——它背后其实有 8 个子技能在协作(测试方案、测试用例、UI 自动化、接口自动化、测试报告、用例评审、操作手册……),但我只看到"一个入口"。这种"调度中心"的封装方式,对全栈工程师特别友好,不用记那么多技能名。
我一般怎么用它(使用技巧)
用到现在,我总结了几条真正能提升效率的用法,不是"会用 prompt 就行"那种花活:
技巧 1:把项目知识库当"事实来源"
.project-kb/ 是我每次开新对话的"必读清单"。我会让 AI 在每个任务开始时先去读 PROJECT_CONTEXT.md + ENGINEERING_RULES.md,再去写代码。
反例:以前我图省事不读,AI 经常给出"理论正确但项目里行不通"的代码——比如它不知道我们项目禁用了某个反模式,给我的方案反而触发了反模式规则。
技巧 2:决策卡 = 项目级"长期记忆"
每张决策卡不是一次性文档。codegen_ready 之后的卡片,会持续影响后续模块。
我做项目的标准动作:
| 阶段 | 动作 | 产物 |
|---|---|---|
| 需求澄清 | 用 req-prd-clarification |
决策卡合同 |
| 知识库初始化 | 用 dev-project-kb-manager |
.project-kb/ |
| 开发设计 | 用 dev-backend-assistant / dev-frontend-assistant |
设计文档 + 代码 |
| 代码审查 | 用 deliver-code-review |
审查报告 |
| 测试 | 用 test-assistant |
测试用例 + 报告 |
5 步走完一次,下一个模块直接复用上一次的成果。
技巧 3:多技能联动 = 真正的"工作流"
我从来不是"只用一个技能",而是链式调用:
项目知识库(打底)
↓
需求澄清(codegen_ready 门禁)
↓
开发设计(后端 / 前端助手)
↓
代码审查(review 助手)
↓
测试用例(测试助手)
↓
交付文档(交付助手)
这 6 个节点不是孤岛,是一条龙——前一个的产物,就是后一个的输入。
和之前相比,效率提升体现在哪
这一段我不用虚的,直接给数字(来源:我们团队 5 月底的真实复盘数据):

| 指标 | 转型前 | 现在 | 变化 |
|---|---|---|---|
| 一个标准 CRUD 接口 | 1.5 小时 | 40 分钟 | ↓ 55% |
| 新人接项目到上手 | 2-4 周 | 2-3 天 | ↓ 80% |
| PRD 模糊导致的返工 | 每模块 2-3 次 | 几乎 0 | ↓ 90% |
| 跨模块测试活动 | 2 天(协调 3 个角色) | 1 个下午(自己干) | ↓ 60% |
| 一份完整的 PRD | 1 人/天 | 1 人/2 小时 | ↓ 75% |
| 一套管理端 CRUD 页面 | 等前端 2 天 | 自己 2 小时 | ↓ 80% |
最有冲击力的对比,是这两个:
案例 1:PRD 提效 5 倍——1.5 天写完 17 份
这个数字出现在我们团队一位产品经理参与的某省执法监督一体化项目里。项目要求 17 份 PRD 文档,覆盖监督要素版块的全部内容。传统做法是 1 个人写 1 周以上,PRD 多了还会出现"前后矛盾、字段定义不一致"的硬伤。
用 req-prd-generator 之后:
- 1.5 天完成 17 份(高质量)
- 每一份都过了 L5 终点条件检查(10 项必要信息 + 风险判断 + 质量校验)
- 另一个独立验证:某省综合一体化二期项目——行政强制版块所有 PRD 产出,交给需求澄清技能自动校验后,仅剩 3 个待确认内容,意味着 AI 写出来的东西,可信度已经高到"只有边界问题需要人确认"
5 倍提速。关键是没有牺牲质量——技能L5 级别的终点条件强制把每一份 PRD 都过一遍质量门,糊弄不过去。
案例 2:全栈工程师自己写页面——30 分钟 vs 等 2 天
这个是我自己最爱的故事,因为它彻底改变了"全栈 = 什么都会但都慢"的刻板印象。
我手上有个客户项目,后端接口已经写完了,但客户要急着看一个管理端 CRUD 页面——列表页、查询条件、详情页、新增/编辑弹窗,一套基本款。按老规矩,得找前端同事排期,前面排着 3 个需求,最快也要等 2 天。
我心想:2 天?我自己写也用不了 2 天吧——但以前自己写 Vue,光是配字段,就能磨掉一下午。
我在 TRAE SOLO Work 里说了一句:
“用
dev-frontend-assistant技能,先出静态页面——管理端 CRUD,列表 + 详情 + 新增/编辑弹窗,数据先用 mock。”
30 分钟,前端骨架搭好了:
- 列表页:
sg-data-view列配置 + 分页 + 查询条件,全套按公司规范 - 详情页:字段展示 + 状态徽标 + 操作日志区
- 新增/编辑弹窗:
$modalDialog强制使用独立组件(这是我们公司的"危险交互治理"红线) - 表单控件:
sg-base-form的字段联动、必填校验、字典回显
改改字段名 → 调调业务逻辑 → 接上真实接口,又花了 1 小时。前后不到 2 小时,客户当天就看到了页面。
对比:等前端 2 天 vs 自己搞定 2 小时,↓ 80%。而且全栈工程师对业务的理解是前端同事没有的——我自己写的页面,字段、校验、状态机全是对的;前端同事接手可能还会再来回对几遍字段含义。
这才是"全栈 + AI"的真正杠杆:不是让全栈干两个人的活,而是让全栈一个人就是一个交付单元。
我还希望 TRAE SOLO Work 优化什么
用了 3 个月,整体是"爽"的,但作为全栈工程师,我也一个小小的建议:
建议 1:技能调用的埋点,不要再写在技能里面了
这是我的头号痛点。
我们技能市场目前有 30+ 个技能,每一个技能的 SKILL.md 文件里都注入了这么一段:
<!-- TELEMETRY_START -->
> 在执行本技能任何实际逻辑之前,必须先运行埋点脚本记录使用日志。
> python3 <skill-path>/scripts/track_usage.py --skill xxx
<!-- TELEMETRY_END -->
而且,每个技能目录下都有一份复制粘贴过来的 scripts/track_usage.py。
这带来 3 个问题:
- 维护噩梦:要改一次埋点逻辑(比如加个新字段、改个上报地址),得
node inject-telemetry.js --all全量重灌一遍,30+ 技能跑一遍 - 脚本膨胀:30 个技能 = 30 份相同的
track_usage.py,光是冗余就占了几 MB - 版本错乱:某个技能忘了重灌,埋点版本就和别的技能不一致了,排错起来怀疑人生
我希望的方案:
TRAE SOLO Work 应该在 IDE / Agent 层面提供一个"技能调用 Hook"机制。
具体来说:
- 技能被调用前,由 IDE 自动触发
onSkillInvoked(skillName, args),而不是让技能自己"提醒" AI 去跑埋点 track_usage.py这类脚本全局只保留一份,放在 IDE 的标准位置- 技能
SKILL.md里完全不需要写"第一步要跑埋点"这种 prompt - 升级埋点逻辑 = 升级 IDE 插件,和技能解耦
这才是真正的"基础设施下沉"——就像 Git 不会让每个仓库自己写"提交前先跑 lint",而是 pre-commit hook 在 Git 层面统一管理。
最后
我用 TRAE SOLO Work 这 3 个月,最大的感受是:
它不是"AI 工具",它是"我团队的标准作业程序"。
它把团队里最值钱的"老员工脑子里的经验"——怎么写 PRD、怎么澄清需求、怎么建知识库、怎么写后端、怎么 review——全部沉淀成技能,让我这个全栈工程师在不同场景之间无缝切换。
它不是让我"变强了",而是让我用和资深工程师一样的方法论在工作。
而我希望它下一步做的,是把这些技能背后的"基础设施"(埋点、更新、错误处理、链路编排)做得更下沉、更解耦——别让每个技能都背着"自己维护基础设施"的包袱。
那才是真正的"AI 原生"。