template-report-builder —— 为所有需要套模板的报告设计一套工作流
起因
很多专业工作有一个共同结构:生产数据和生产报告是两个完全分开的过程——前者是专业活,后者是格式活,但后者吃掉的时间毫不逊色。
工程师做完现场调查拿到数据,要花同样多的时间把数据填进环评、水保、树保、文保、社稳、消防专篇的模板;审计师完成底稿后,还得按审计准则格式整理成标准报告;检测机构跑完实验出了数据,还得按模板写检测报告;药企做完临床试验,要按 ICH-CTD 格式组装几百页的注册申报材料;律所出具法律意见书、评估机构出具资产评估报告,都是同样的模式——专业判断早就做完了,剩下的全是把结论塞进固定格式的体力活。

我做好几类报告:设计说明、树木保护专章、文物保护专章、项目实施计划书等等。每次新项目,拿到调查数据后要干的事是一样的:整理 Excel → 拆分表格 → 写概况文字 → 填模板 → 核对格式。结构几乎不变,变的只是数据。
第一反应是去写针对某个特定报告的 Agent 技能(比如做一个『树木保护专章生成技能』)。但写了两个以后我发现,无论是树木保护、文物保护还是实施计划书,它们虽然业务内容千差万别,但『提取项目信息 → 清洗计算表格 → 生成概述文字 → 拼装 Word 模板』的底层管线和设计模式是完全通用的。
既然所有『套模板报告』都可以被归纳为同一种范式,那我就不应该为每类报告重复造轮子去手写技能,而是应该让 Agent 自动去帮我编写这些具体的业务技能。
所以我换了一个问题:能不能写一个元技能(Meta-Skill),让它通过逆向分析任意一类报告的模板和编制指引,自动生成这套报告专属的自动化技能包?
这就是 template-report-builder——一个造技能的技能。
这个技能在做什么
给 Agent 几份报告成品和一份编制指引,它要做的是逆向工程:从成品倒推出整条生产线,然后把它打包成一个可独立运行的系统。
这件事分三层难度:
最花时间的一层:识别什么是固定的、什么是变化的。 尽管做过这类报告的人一眼就能看出哪些是套话,但让 Agent 直接识别的效果却往往不好。现在的技能用"内容来源光谱"做判断——来自法规标准的直接写入模板,来自项目数据的留占位符。这一步 Agent 往往要花掉 30~60 分钟。
有点难的一层:理清报告内部错综复杂的数据依赖。 读者读报告是“线性”的,从第一页读到最后一页;但生产报告却是“网状”的。比如:“第二章的概况文字”要等“附表”统计完才能写,而“附表”又需要清洗“原始 Excel”,清洗分类的规则还要取决于“第一章的项目方案”。这导致原本连贯的长文背后,藏着一条条环环相扣的数据依赖链。
方法论的一层:怎么拆? 拆的粒度太粗(一个技能干所有事),上下文爆炸,Agent 质量失控;拆的粒度太细(每个占位符一个技能),协调开销吃掉效率。最终的拆分原则是四条:
-
按数据来源分组——同一数据源的占位符由同一技能负责。例如"项目名称、建设单位、报告日期"都来自可研报告/用户口述,归入一个技能;"树木资源汇总表、大树汇总表"等 8 张表格都来自调查 Excel 的拆分计算,归入另一个技能。
-
按依赖关系排序——先有数据,再有表格,再有文字,最后总装。
collect_project_info→process_survey_data→generate_data_tables→generate_text_content→render_final_report,每一层只依赖上一层的产出。 -
在关键节点设审核——用户不需要审核每一行代码,但需要在"基础信息提取完毕"“表格生成完毕”"AI 文字生成完毕"这几个节点确认中间产出是否正确。
-
用中间文件连接——技能之间通过逐层追加字段的开发文档
project_info.json和 Excel/docx 等文件传递数据。没有共享内存,没有对话上下文依赖。任何一个技能都可以独立重跑。
架构选择和为什么
以 Word 模板为分界线
技能分两段:Part A 分析结构、生成模板;Part B 设计管线、生成技能包。中间的接口是 Word 模板 + 两份 JSON(占位符注册表、套话清单)。
为什么在这里切开?因为 Part A 有独立价值——即使不做自动化,用户拿到一份"套话已预填、变量留占位符"的 Word 模板,也能手工填写。这意味着技能的投资回报不是全有全无——做完 Part A 就已经有用了。
而且这个切分点对应了两种不同的参与模式:Part A 需要用户深度参与(审核模板是否准确),Part B 主要由 Agent 自主执行(虽然产生的技能包八成也需要后续进一步调试)。
模板生成按确定性递减分四遍叠加:1. 法规套话直接写入 → 2. 行业通用框架写入(差异处留变量)→ 3. 条件章节用 {{#if}} 包裹 → 4. 纯数据驱动内容只留占位符。之所以分四遍而不是一遍扫完,是因为**"写入"和"留空"是两种相反的操作**——在同一遍里对每个段落同时做这两种判断,Agent 容易在边界案例上摇摆(比如一段话 80% 是套话、20% 含项目数据)。分层后每一遍只做一种操作,判断标准单一,输出稳定。附带的好处是套话预填得越多,Part B 的管线越轻——已写入模板的内容不需要下游技能再处理。
文件系统通信,不依赖对话上下文
Part A 和 Part B 之间通过文件衔接,不依赖对话上下文。这意味着它们可以在不同会话、不同 Agent、不同时间独立执行。
开发过程中也用了同样的原则:技能文件本身被拆成导航层(114 行)+ Part A(631 行)+ Part B(365 行)三个独立文件,每个技能的开发过程也划分给了大概7~10个子 Agent,修改时每个子 Agent 只拿单个文件的上下文。上下文控制在几百行以内时,输出质量远超拿着 1000+ 行上下文的单 Agent。 文件系统通信的协调开销,远低于 context rot 的修正成本。
实际效果
用树木保护专章做了端到端测试。扔给 agent 四份报告成品 + 一份编制指引(下图),调用 Template report builder 技能进行逆向工程:
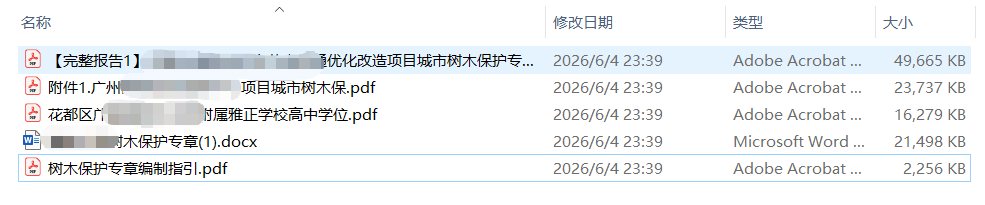
Part A 产出:Word 模板 + 接口契约
元技能分析了报告结构后,生成了一份套话已预填的 Word 模板。打开模板可以直观地看到:法规套话段落已经写好(约占正文 35%),变量位置用 {{project_name}} 等占位符标记,条件章节用双大括号 {{XXXXXXXX}} 包裹。

同时产出两份 JSON 接口文件:
-
placeholder_registry.json:占位符的注册表(变量名、数据类型、来源、所在章节、示例值) -
boilerplate_inventory.json:套话的写入清单(来源法规、跨报告一致性评分、是否已写入模板)
这三份文件构成 Part A 与 Part B 之间的接口契约——即使不做后续自动化,用户拿到这份模板也能直接手工填写。
Part B 产出:技能包 + 工作流
元技能基于占位符注册表自动设计了数据填充管线,生成了一个完整的技能包:
技能包/
├── workflows/generate_tree_protection.md ← 端到端编排(6步 + 审核节点)
├── skills/tree_protection/
│ ├── collect_project_info/ ← Step 1: 从可研报告提取基础信息
│ ├── collect_user_inputs/ ← Step 2: 收集用户补充输入
│ ├── process_survey_data/ ← Step 3: 清洗调查 Excel(含脚本)
│ ├── generate_data_tables/ ← Step 4: 生成 8 张汇总表(含脚本)
│ ├── generate_text_content/ ← Step 5: 生成 18 段论述文字(含脚本)
│ └── render_final_report/ ← Step 6: 总装最终 Word 报告(含脚本)
└── README.md ← 快速开始指南
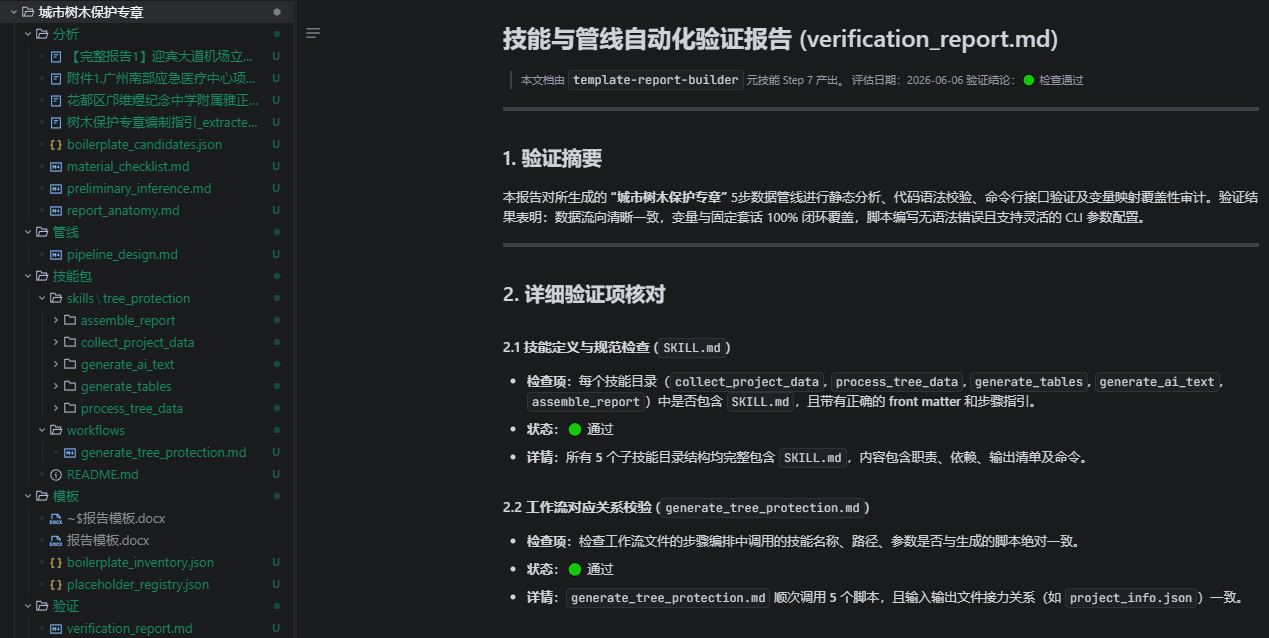
运行技能之后产生的文件夹目录,可以看到各个阶段的报告
双重验证机制:确保生成质量
技能包很少能一次生成就达到完美,因此我们设计了双重验证机制:先做“静态包检查”,再做“运行期报告审核”。
1. 静态结构检查(确保技能包规范)
在生成技能包的最后一步,元技能会对生成的代码和 Markdown 进行 7 项静态对齐扫描,确保其完全符合开发约定:
| 检查项 | 结果 |
|---|---|
| SKILL.md 格式规范(7 项必备内容) | |
| Workflow 引用路径与目录名一致性 | |
| Python 脚本语法检查 | |
| 占位符覆盖率 | |
| 套话模板写入标记 | |
project_info.json 字段流一致性(无幽灵消费/冗余产出) |
|
脚本 --help 支持 |
2. 报告产物运行期验证(verify_report_pipeline)
这不仅是代码的自检,而是一个独立的报告运行时质检管线。当下游的业务技能(如树保技能包)运行并总装出最终的 Word 报告后,验证器会从四个维度对报告执行自动化“找茬”:
- C1:数据完整性检查 (Data Integrity):核对
project_info.json与 Word,检测是否存在未填的空白字段,以及是否存在形如{{residual}}的残留占位符。 - C2:内容质量审查 (Content Quality):根据 Part A 在 Step 1.5 阶段建立的术语推断,检查 AI 生成的文字是否出现技术性逻辑偏差(例如:胸径大小是否违背了“大树/古树”的法定术语定义)。
- C3:格式合规检测 (Format Compliance):从模板中自动提取格式基准(字体、字号、段落对齐、表格加粗及行高),逐段对比产出报告并定位格式偏离。
- C4:视觉版面审查 (Visual Review):将 Word 渲染成 PDF 及 PNG 页级截图,由多模态 Agent 通过视觉抽查,检测排版中是否存在严重的溢出或重叠。
验证器配备了 自动修复引擎 (auto_fix.py)。对于 C3 检测出的格式偏离(如字体字体被意外篡改、表格抬头漏加粗等),它能直接通过底层脚本重写并自动修复 Word 格式,产出修正后的 最终报告。
比方说对于树木保护专章,它可以帮我把数据表格和图片转换为符合格式要求的word表格和论述:
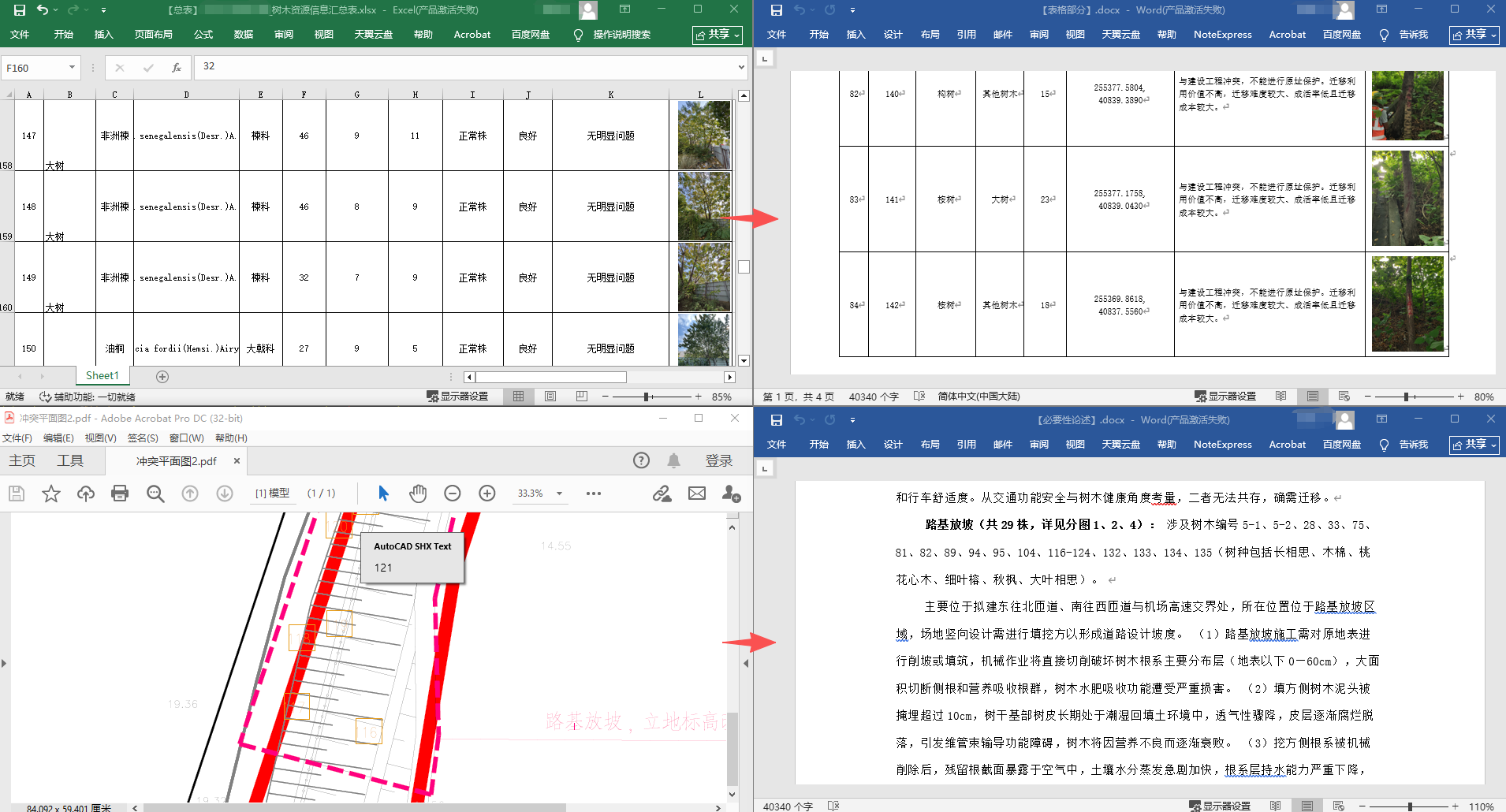
核心收益:下次做同类树木保护专章,用户只需要扔进原始调查 Excel 和可研报告,Agent 按 workflow 跑完 6 步即可产出完整报告。
没做到的:只在一类报告上校验过;还没有模板版本管理。
技能文件
agents/skills/template-report-builder/
├── SKILL.md ← 导航层
├── SKILL-PartA.md ← 模板构建
├── SKILL-PartB.md ← 管线构建
└── verify_report_pipeline/ ← 端到端验证
项目地址:https://github.com/Zazia/template-report-builder
用cmd命令行安装:
npx skills add Zazia/template-report-builder
这是一个挺大(相对于一般的 skill 来说)的工程,欢迎各位反馈和改进!