我的行业 / 角色 / 职业:美妆/数据分析/信息技术岗
我的高频工作内容:经营数据采集、数据清洗、数据分析、数据报告提报
办公工具栈:TRAE SOLO Work + Skill 自动化 + 飞书云文档
一、海量数据需求,RPA软件流程不稳定,"复制粘贴"纯耗时,数据链路长,操作步骤分离
-
在运营数据需求支持工作中,需要定期对多个数据源进行周期性定位趋势表现进行分析,才能充分分析运营策略是否需要进行调整和节奏把控。
-
在数据采集,数据清洗,数据整合,数据分析,数据报告提报。以往都是割裂的。
-
刚开始数据采集,需要手工一个一个复制粘贴,后来通过RPA软件模拟数据采集,虽然人可以稍微轻松,但是经常定位不准,突然卡断,总要重新跑几次才能实现采集结果。
-
数据清洗和数据整合,第一阶段也存在标准不一致,结果通过人眼手工处理。第二阶段稍微改善,通过脚本快速执行清洗合并,但采集和清洗,整合往往是割裂分离状态。
-
数据提报也只能通过飞书消息对话传文件,并不能很好形成追溯。
TRAE Work让我想到完整串联解决以上的办公痛点:通过一条真正可以无人值守、自动执行、能够自我校验、结果自动归档到飞书的数据生产线。
二、核心办公场景
场景一:Skill 驱动的数据采集(替代人工操作网页)
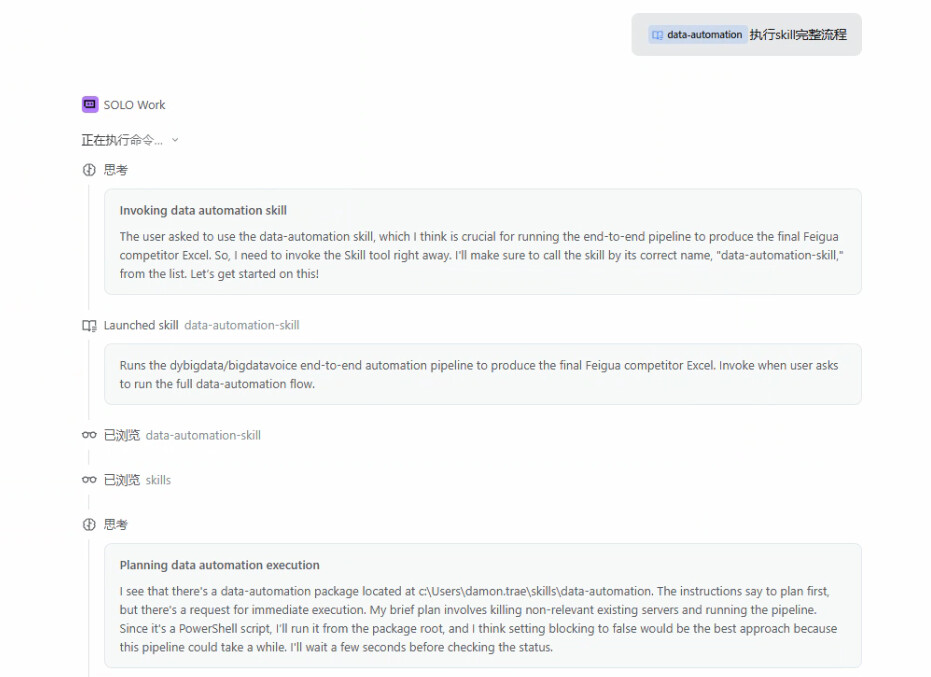
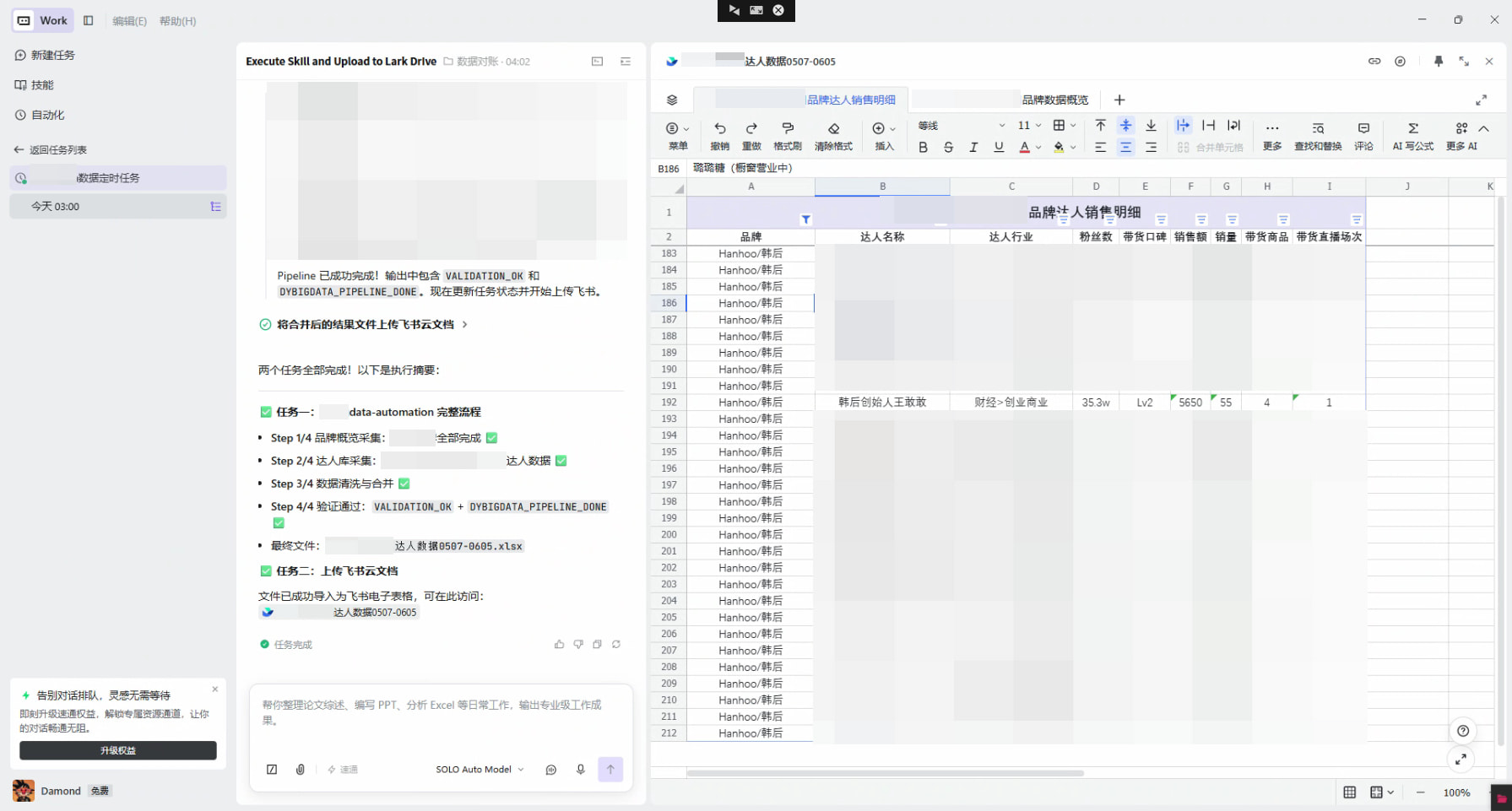
我把自己日常在数据平台上的完整操作流程,封装成了一个 TRAE Skill(data-automation)。
整个 Skill 包含一条完整的 CLI 自动化流水线:
环境检查 → 依赖安装 → 经营概览采集 → 条件筛选 → 经营明细数据采集
→ 数据清洗 → 数据合并 → 数据校验 → 输出最终 Excel
在 TRAE SOLO 中只需要一句话就能启动:
执行 data-automation 完整流程
SOLO 会自动读取 Skill 说明、安装依赖、打开 Chrome、完成登录授权、逐一采集数据、清洗合并、校验通过后输出 Excel。
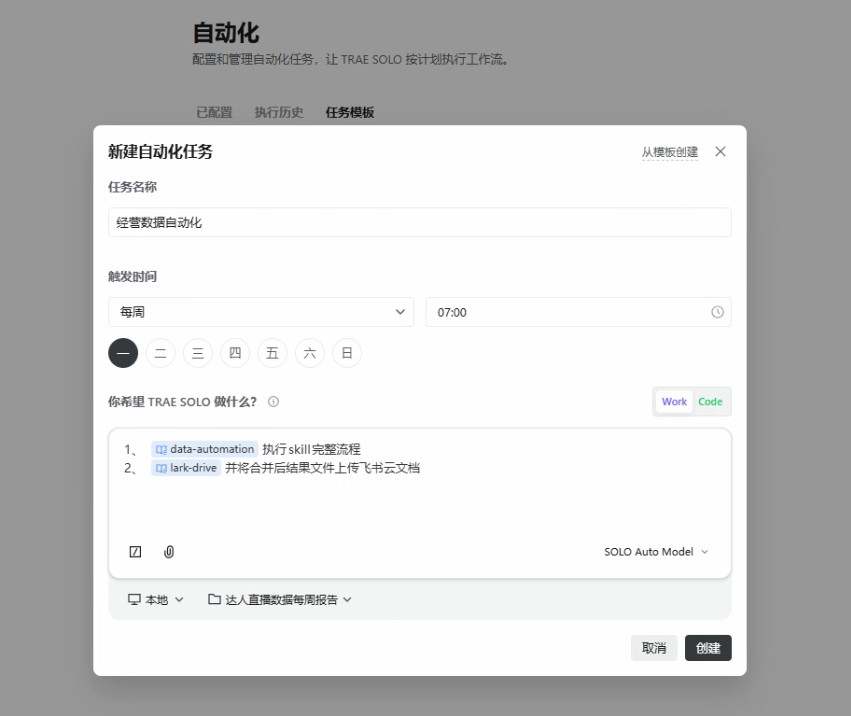
场景二:SOLO Work 定时任务(无人值守自动执行)
数据采集不需要我每天手动触发。我通过 SOLO Work 的定时任务功能,配置了每周一早上 7 点自动执行:
- 执行 data-automation Skill 完整流程;
- 将合并后的结果文件上传飞书云文档。
配置完成后,每周一早上我到工位打开飞书,最新的竞品数据报告已经在那里了。
场景三:飞书云文档自动归档(团队协作零延迟)
过去采集完数据后,还要手动上传到飞书、更新文档链接、通知团队成员。现在这一步也自动化了。
Skill 执行完成后,SOLO Work 会自动调用 飞书 CLI,将最终 Excel 作为飞书电子表格上传到飞书云文档。团队成员打开飞书就能直接查看最新数据,周一上班直接打开数据结果链接:开会!。
整个流程从"人工操作网页 → 手动整理 Excel → 手动上传飞书",变成了:
SOLO Work 定时触发 → Skill 自动采集 → 自动清洗合并校验
→ 自动上传飞书电子表格 → 团队直接在飞书查看
保留一下我老板也在努力![]() 做主播呢!!【涉及数据敏感信息已屏蔽/已修改】
做主播呢!!【涉及数据敏感信息已屏蔽/已修改】
场景四:数据校验与质量保障(不让错误流入下一环节)
这是和之前最大的区别。以前人工操作时,漏选一个筛选条件可能几天后才发现;现在每一步都有校验:
- 每个核心采集点必须全部采集成功;
- 每个核心采集点必须有 30 条数据;
- 单位转换存在中文可阅读需求,必须在数字转换和也排序同时支持;
- 最终 Excel 必须包含品牌达人明细和品牌概览两个 Sheet;
- 任一校验不通过,流程立即停止并保存 debug 截图。
三、我是怎么和 TRAE SOLO 协作的
我没有一开始就让 AI “直接写一个完整脚本”,而是把工作拆成多个可以肉眼验收的步骤。
第一步:先让 SOLO 理解真实流程
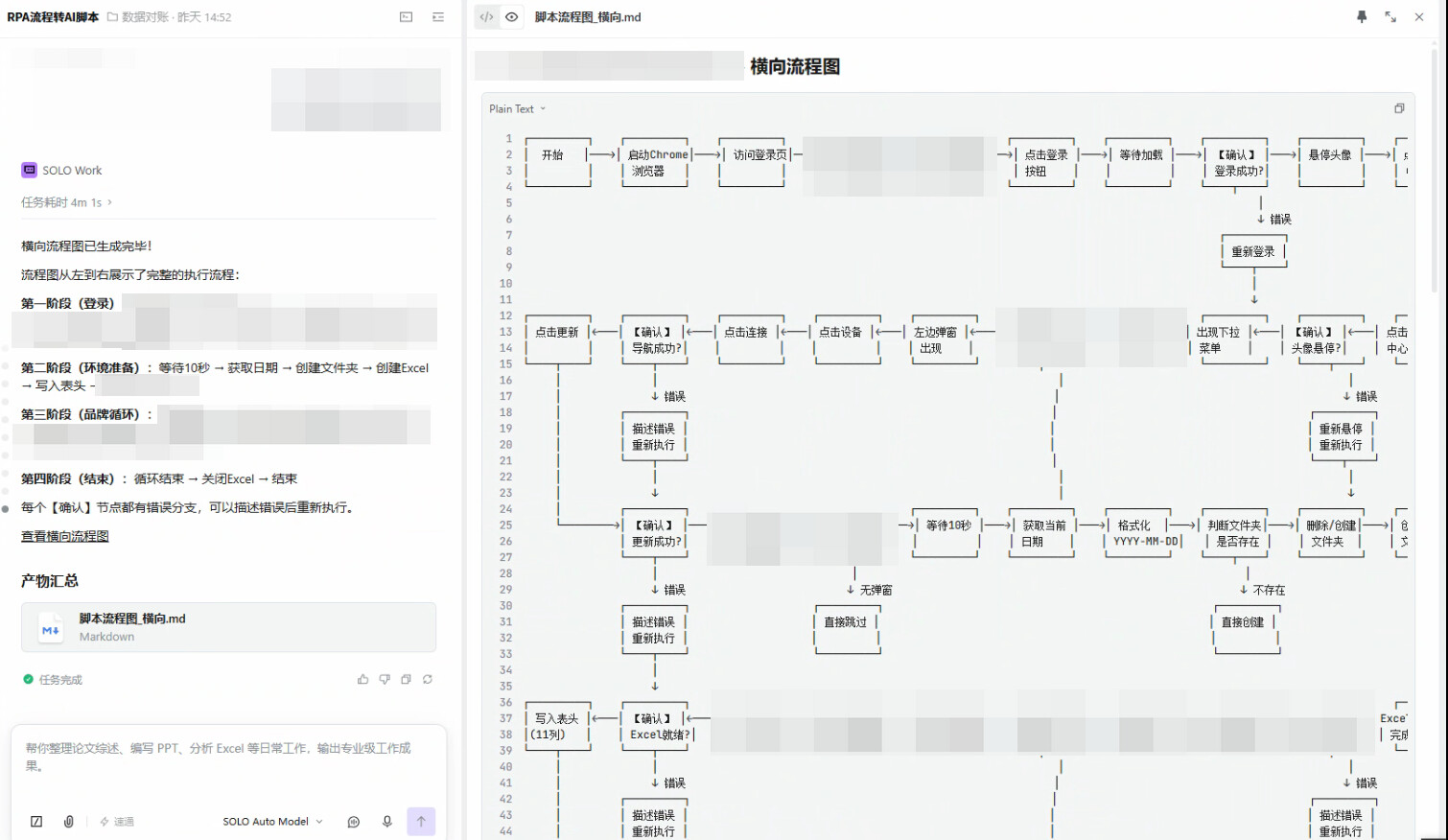
我把原有 RPA 流程图、Python 脚本、操作录屏和字段要求一起交给 SOLO,让它先整理流程,而不是急着写代码。
先不要完整运行。
请根据 操作步骤 流程图、现有 Python 脚本和操作录屏,
整理从登录、采集、明细采集,到清洗和合并的完整操作步骤,
并列出每一步的输入、输出和校验条件。
【涉及数据敏感信息已屏蔽/已修改】
第二步:分段执行,逐段验收
整个项目按阶段推进:登录验证 →品牌概览 → 全量概览 → 筛选验证 → 单达人 → 全量达人 → 清洗测试 → 合并测试 → 完整流程 → 飞书上传 → 定时任务配置。
这个过程最有价值的一点,是 SOLO 可以持续读取运行日志、截图和 Excel 结果,再修改脚本,而不是每次都从头解释项目。
第三步:从"能跑"升级到"能调度"
脚本稳定后,我让 SOLO 帮我做了三件事:
- 封装成 Skill:补齐 SKILL.md、配置文件、自动依赖安装、默认输出目录、结果校验,让其他环境也能调用;
- 配置定时任务:通过 SOLO Work 的 Schedule 功能,设定每周一自动执行;
- 对接飞书:通过飞书 CLI,将结果自动上传为飞书电子表格。
四、最难的问题,SOLO 是怎么帮我解决的
1. Chrome 原生 HID 弹窗无法用网页选择器控制
登录后需要点击右上角头像、点击"更新",再在 Chrome 原生 WebHID 浮窗中选择 USBKey。
最初只能使用屏幕坐标点击,但这对分辨率和系统缩放非常敏感,不适合打包成可迁移的 Skill。
最终方案:
- 枚举 USBKey 的 VID/PID;
- 为目标网站写入 Chrome
WebHidAllowDevicesForUrls策略; - 默认关闭坐标点击,仅在策略无法生效时保留鼠标点击作为兜底。
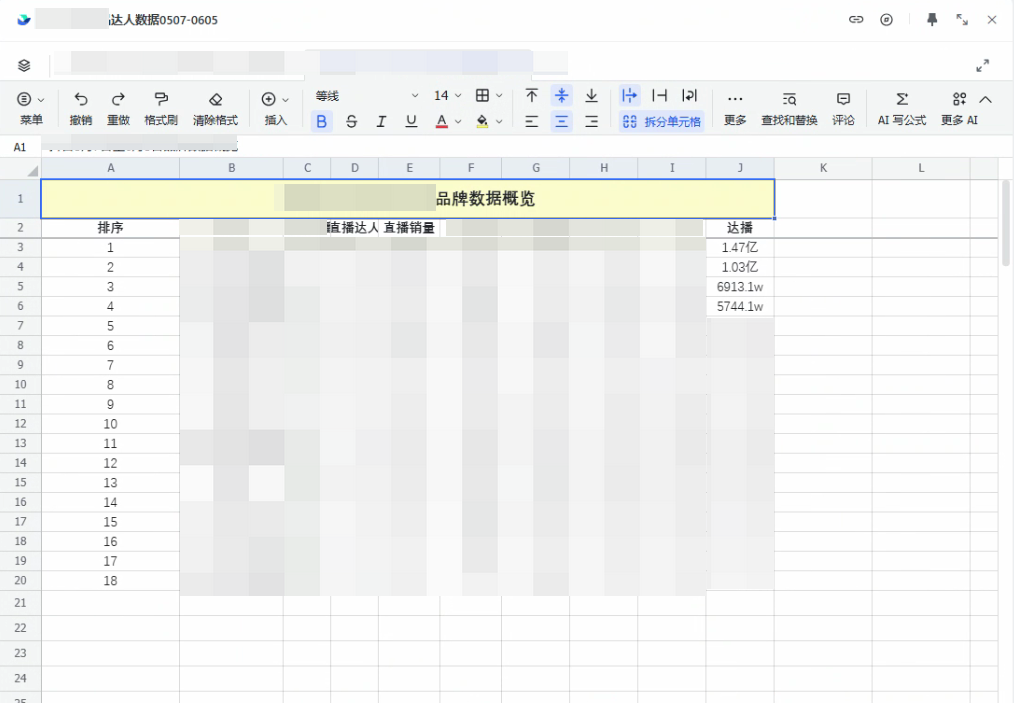
2. "亿"单位丢失导致排名错误
1.26亿 被截成 1.26,3.21亿 被截成 3.21,亿元级数据反而排到了万元级后面。
SOLO 帮我从最终 Excel 一路反查到采集源头,发现销售额拆分正则只识别 w,没有识别中文的 万/亿。最终处理方式:采集阶段完整保留 万、亿、w;展示值保留原单位;排序时统一换算为数值;校验时主动查找疑似被截断的裸数字。
【涉及数据敏感信息已屏蔽/已修改】
五、最终做成了什么
最终成果是一个 Skill + 定时任务 + 飞书云文档 的完整自动化方案:
data-automation-skill/
├─ SKILL.md # Skill 说明文件
├─ run_full_pipeline.ps1 # 单一入口
├─ config/
│ ├─ config.json # 运行配置
│ └─ config.example.json # 配置模板
├─ scripts/
│ ├─ data_brand_scraper.mjs # 概览采集
│ ├─ data_blogger_scraper.mjs # 明细数据采集
│ ├─ clean_blogger_excel.py # 数据清洗
│ ├─ merge_feigua_data.py # 数据合并
│ ├─ setup_chrome_webhid_policy.ps1 # WebHID 策略
│ └─ validate_pipeline_outputs.py # 结果校验
└─ output/ # 输出目录
三层自动化架构:
| 层级 | 工具 | 职责 |
|---|---|---|
| 执行层 | Skill (data-automation) | 数据采集、清洗、合并、校验 |
| 调度层 | SOLO Work 定时任务 | 每周一 07:00 自动触发执行 |
| 协作层 | 飞书 CLI + 云文档 | 结果自动上传为飞书电子表格 |
六、实际效率提升
时间对比
| 环节 | 人工操作 | 自动化后 |
|---|---|---|
| 概览采集 | ~60 分钟 | AI执行我在睡觉 |
| 明细采集 | ~1.5 小时 | AI执行我地铁 |
| 数据清洗与合并 | ~30 分钟 | AI执行我地铁 |
| 上传飞书云文档 | ~2 分钟 | AI执行我地铁 |
| 合计 | ~3 小时+人工值守 | ~AI执行没参与+无人值守 |
质量提升
以前人工操作中,漏选筛选条件、分页遗漏、单位丢失等问题时有发生,往往开会发现错漏,临时对数据需要返工。
现在:
AI执行,我直接提交结果
工作方式的变化
以前:每周一早上手动打开数据平台 → 逐一![]() 搜索 → 切换页面 → 复制字段 → 翻页 → 清洗 → 合并 → 上传飞书 → 通知团队
搜索 → 切换页面 → 复制字段 → 翻页 → 清洗 → 合并 → 上传飞书 → 通知团队
现在:每周一早上打开飞书,数据已经在那里了。
七、我的 TRAE SOLO 使用技巧
技巧 1:先让 AI 复述流程,再让它写代码
如果 AI 连真实操作路径都没有理解,写得越快,返工越多。
技巧 2:把"肉眼看到的问题"转成可执行校验
不要只说"推广按钮好像没点到",而要改成:"先判断“推广”按钮位置,再尝试操作,仍未检测到推广按钮时,停止采集并保存截图。"问题不会在下一次执行中悄悄复发。
技巧 3:单核心采集点验证通过后,再跑全量
全量运行接近 50 分钟。如果不先做单核心采集点验证,任何小错误都会浪费一整轮时间。
技巧 4:让 AI 检查最终文件,而不只是检查"脚本退出码"
真正的完成标准不是终端显示成功,而是 Excel 文件存在、行数正确、字段没有错位、金额单位没有丢失、排序符合业务逻辑。
技巧 5:用 Skill + 定时任务 + 飞书实现"闭环自动化"
脚本稳定后,三步升级:
1. 封装成 Skill(让 AI 可调用);
2. 配置定时任务(让执行可调度);
5. 对接飞书云文档(让结果可协作)。
这一步让项目从"我的电脑上能跑",变成"每周一早上数据自动出现在团队的飞书里"。
八、我还希望 TRAE SOLO Work 优化的地方
1. 长流程的进度展示与断点续跑
这类任务运行 30~60 分钟,希望 SOLO 能提供更清晰的阶段进度和预计剩余时间。如果 部分核心采集点已完成 ,希望重启后能从断点继续。
2. 支持computer use 能力,让AI能看到我操作的步骤和点位,让用户与AI能更加容易对齐需求。
九、结语
这次实践让我感受最深的是:AI 编程真正有价值的地方,不只是帮我多写了几百行代码,而是帮助我把一个模糊、易错、依赖人工经验的办公流程,逐步变成了可执行、可验证、可调度、可协作的系统。
从最开始"怎么点到 按钮 “,到"怎样让其他 AI 也能执行 Skill”,再到"怎样让数据每周一自动出现在飞书里"——项目的目标在不断升级。
最终交付的不只是一个 Excel,而是一套能稳定生产数据、自动归档到团队协作空间的无人值守生产线。