https://my.feishu.cn/sync/AisAdxLoQsNXgabrjuvcXpJGnxe?from=from_copylink -zip链接
增加12大项经验,优化为英文版,进行针对特定领域的某些用法的二次脱敏大福减少skill.md 的字数。
记录设计skills的经验:
- reference文件夹放一些经验
- 脱敏,针对个人信息,特定项目,特定实现。变为通用skills
- 英文
- skill减少字数?
一、新增一份脱敏的失败模式库,覆盖一个新对话历史真实踩过的典型坑:
claim 引错图表
appendix 诊断结果泄漏到 main claim
missing timing 被画成 0
profile alias 和真实模型身份漂移
生成表/图 stale
子集分析被写成 full results
heterogeneity split 退化成全样本
main/submission 两个 tex 因宏或 include 不一致
不完整 ablation 被写得像完整
appendix context row 被误读为 matched comparator
baseline 扩展后正文措辞没同步
cross-profile 指标塌缩到简单 baseline
compile-critical 产物未跟踪
figure 标签重叠
已披露局限被误报成硬错误
二、增加,增加新经验的规范
并且,为后续增加这个经验设计了标准:把模板和设计说明也一起改了,后续可以继续把新坑往这个 failure-pattern 库里加,但要求必须先通用化、脱敏,再入库。
三、入库形式简要说明,详见reference文件夹-亦符合skills设计规范
并且,入库形式规范为,以什么视角发现的问题,什么问题,怎么解决。三段式
再次更新1.2.0
更新version说明+显示工作流。
极大改进了ai阅读论文的积极性。
因为设计之初的理念就是促使ai一次对话审查完整问题,把272k上下文进行极大的压榨,确保每次读入更多内容进行更完整审查。
同时察觉到这个skill相对保守,它会很理智的告诉你,你的图我没看。-这是因为前面已经暴露了10+问题这个确实没有到进一步看的时候。
建议使用方式单次对话注入skill进行审查,避免上下文过大影响性能
此次实战时间:10分钟运行 gpt5.2 耗资0.82刀。-1.1-1.2这个过程学会了如何改进skill。感谢k叔的审查技能很nice。门控才是核心阿,我觉得我这个审查也属于门控的一种?
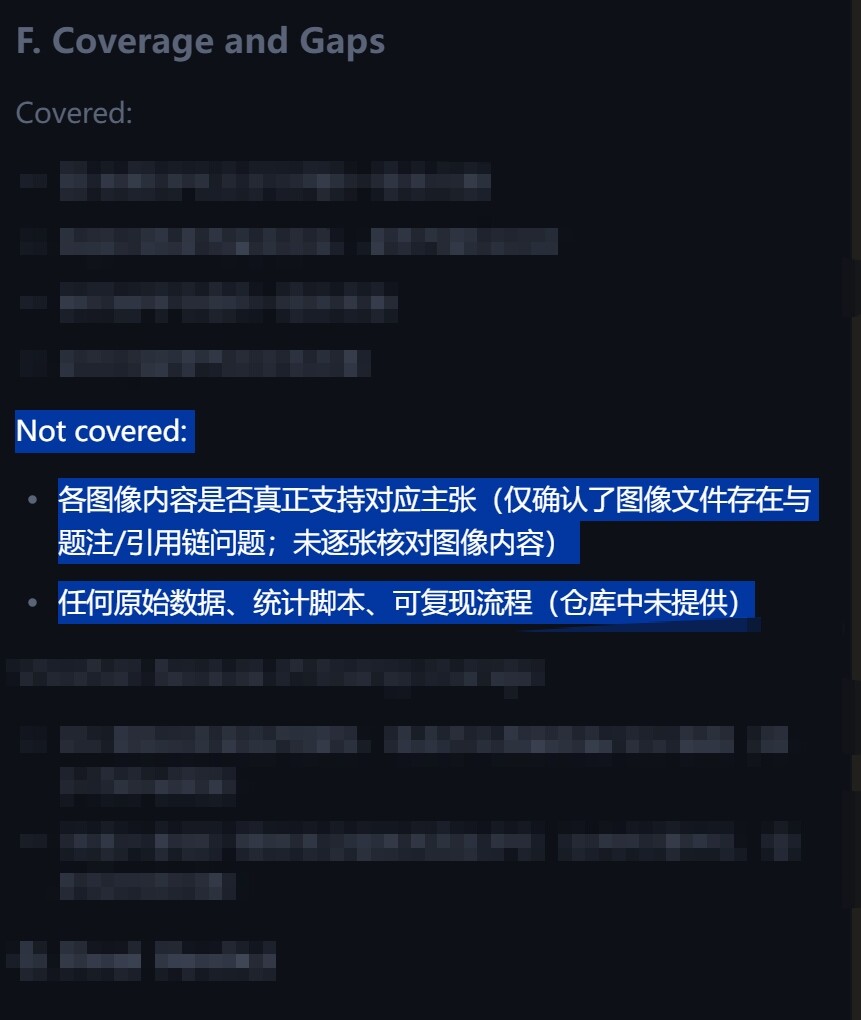
上一篇帖子:今天又写了个skills
k叔优化版: [skill]科研产物红队审计