为什么会想到这个skill呢?
因为很久以前我收藏过marscode的这个,当时我有注意到这里免费开放算力+ai免费侧边使用+有几百道题。后来虽然关了,但我还是留着这个收藏。
即使我也没怎么刷,但我还是觉得当时这个做的很好。
于是我想尝试复活一下它。
1、首先梳理需求
-
结构分析,skill怎么做结构?
-
要不要题库,从哪里找?github?
-
承接曾经的300+算法
-
增加vibecoding时代特色。考虑用户可以vibe一个服务器项目,全栈,TS,react,理解这些能不能服务于他的项目?
-
不能只靠 AI 自由生成内容,否则很容易产生幻觉
-
第一优先级是启动欲望,第二优先级是知识准确,第三优先级才是面试迁移
-
Skill 应该每天自动给出一个训练任务
-
最终产品是带题库、知识库、代码库、评测器和冷面试模式的训练 Skill
-
最终价值不是让用户刷更多题
-
最终价值是让用户在真实压力下还能说清、写对、判断准、扛追问、能复盘
总之跟ai聊一下。然后简单的收获一个开发skill的万字文档:-放文末了14000+字。
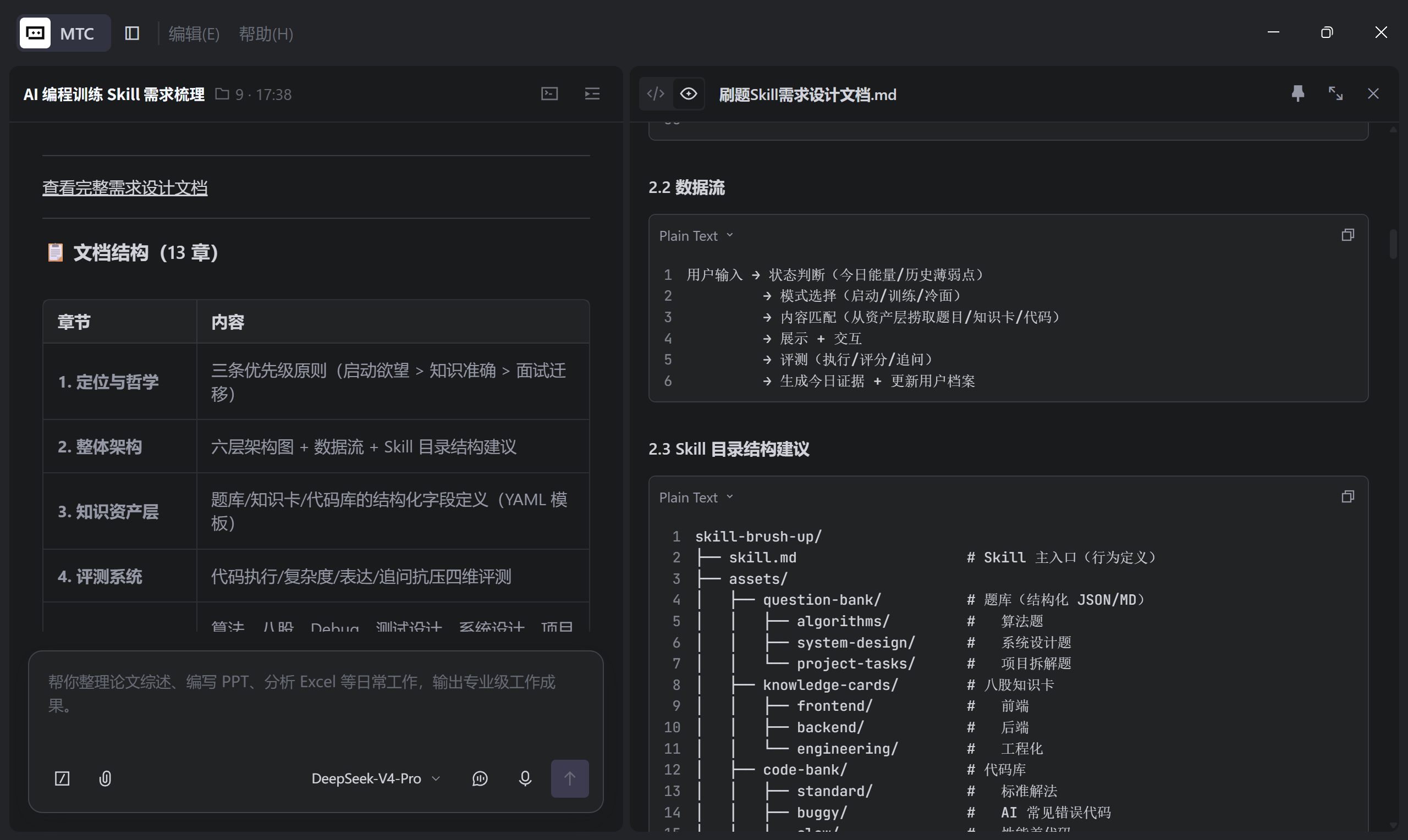
2、按照文档进行了初始化
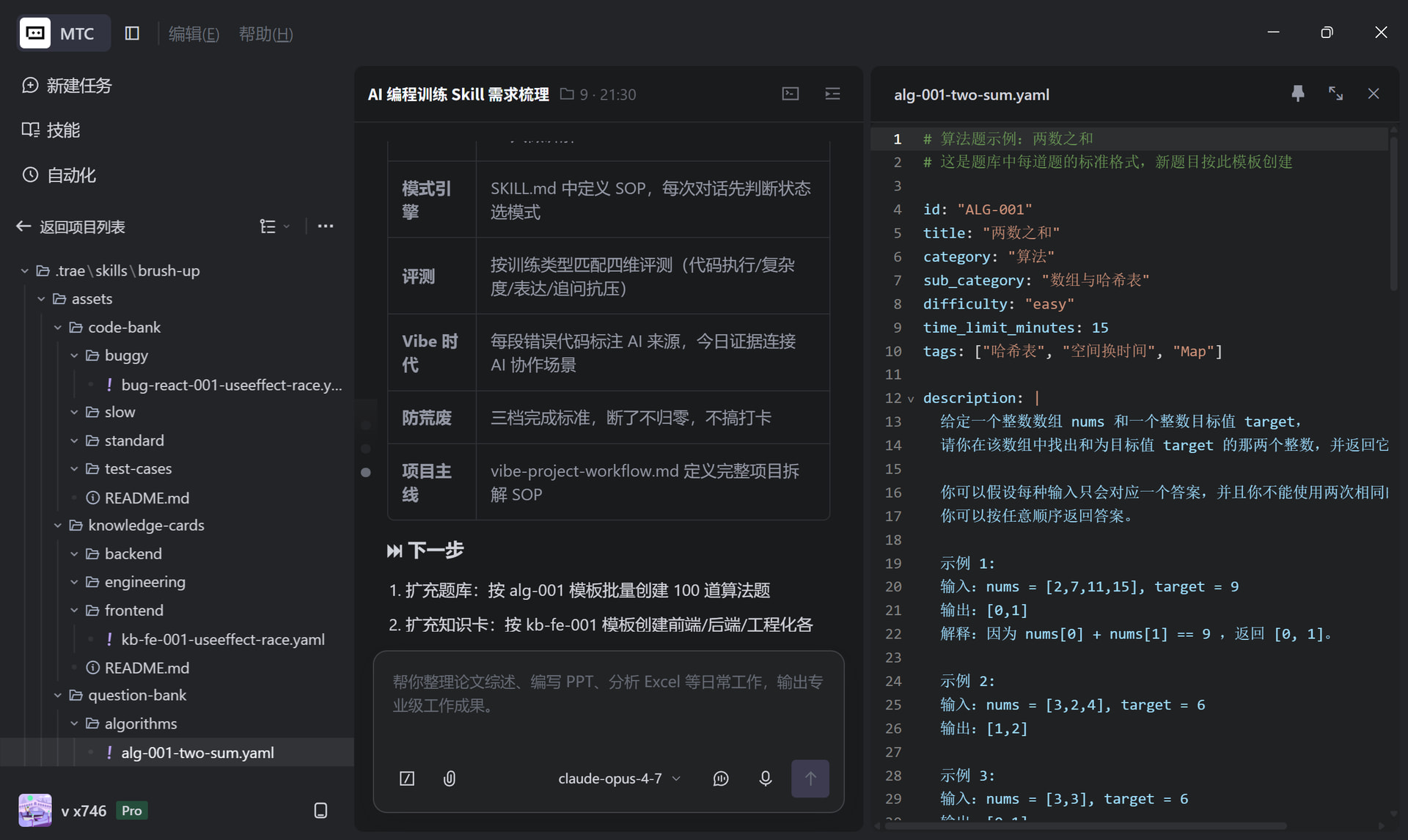
然后我们开始关注核心题库部分怎么建设。-github找找但是需要看看怎么和我们设计的兼容。
我个人挺想TS这个的,现在很多都是TS写。
我想把这个题库直接做进去。先内置300+,然后提示ai,现在不是普通编译器了。后续这块应该比较难调试。

AI画的架构图:
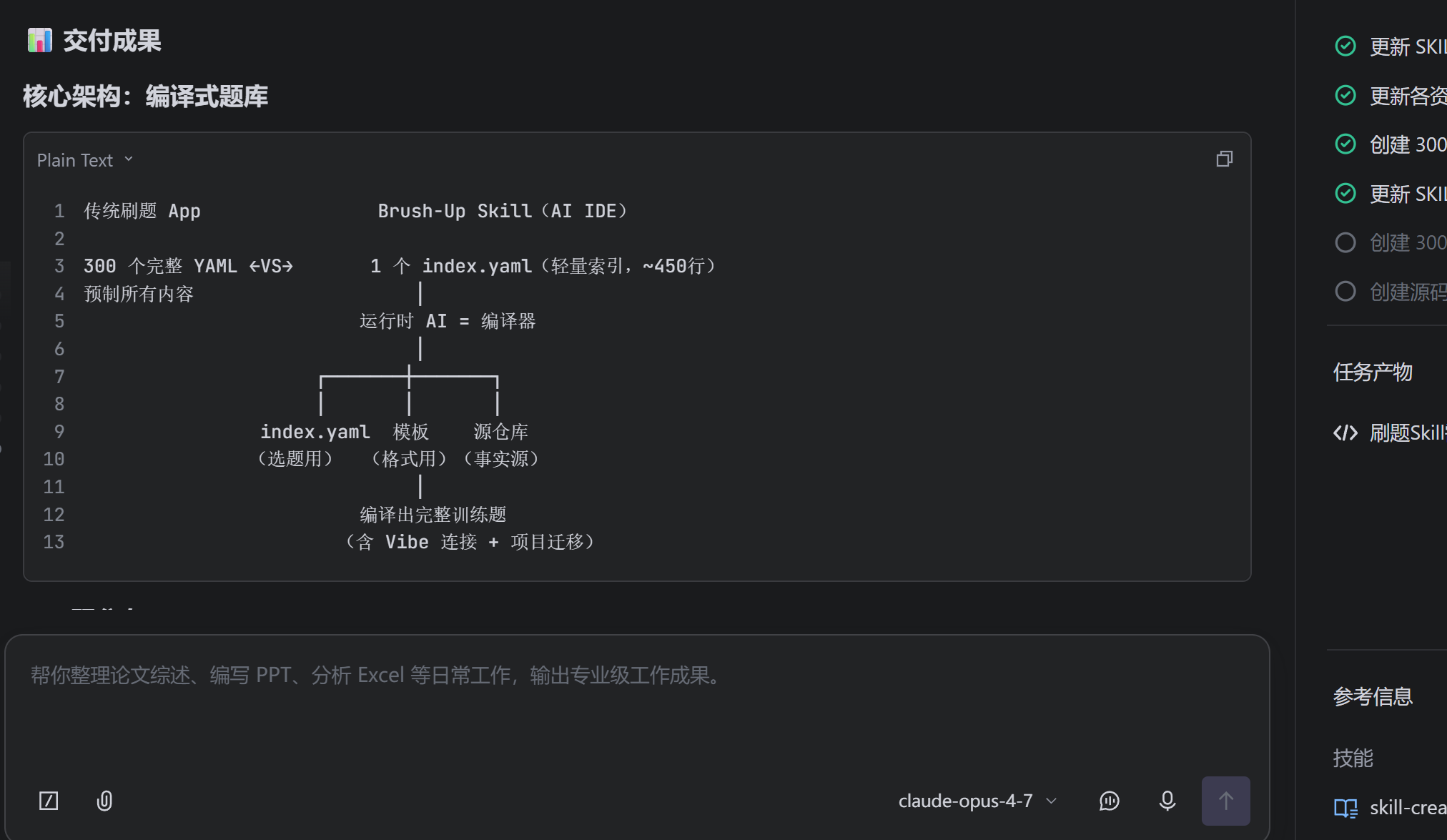
然后你也可以试试看:
安装 并开始第一个 https://github.com/gotocx/real-tech-training-field-public.git
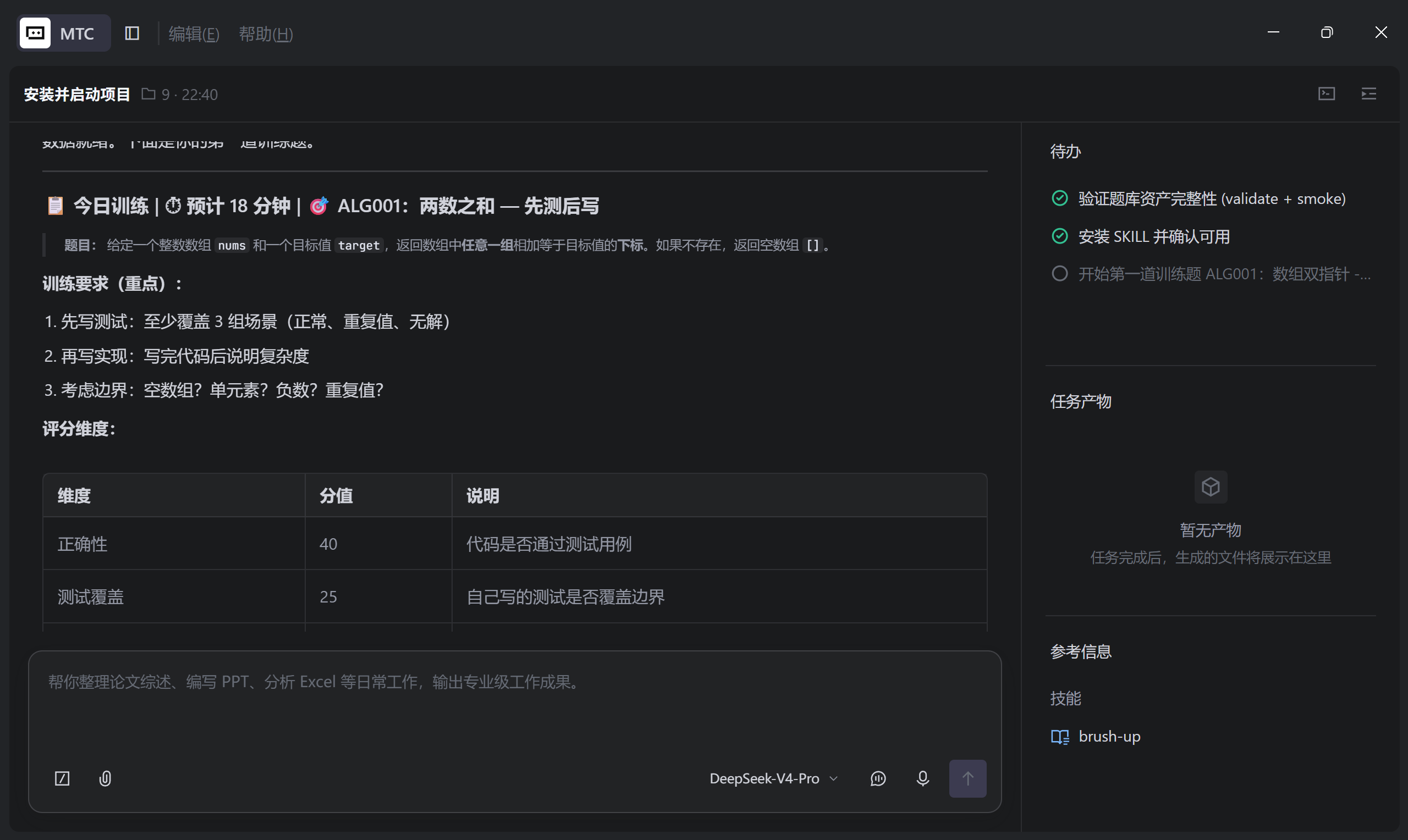
OK 搞定 还行 成功让我有兴趣了,和直接刷题不一样哈!
让我问问ai怎么写继续,不然就卡住了。。。。。。。。
这一步我想到加个检测ai回答的,并让ai对这个行为进行批评。比如通过指出这个ai回答的缺陷和过于ai以达到戳破的目的。
笑死,真好阿。写的东西真的有让我学到点东西。没想到我基础这么薄。
自己又当老师又当学生的感觉,一遍了解自己需要什么,借助ai实现工具demo。然后自己又变成用户直接使用这个demo。
使用过程我发现有第一个照着敲后面的,这种比较稳。比较还是得先知道测试用例得用unittest 写一个类进行测试用例实现。
- 目前薄弱点分析,虽然是一道题,但是没有立即结合vibecoding时代的内容,这个单独刷可能没有实质工程提升,这个得强调一下。
- 加一条“单题工程迁移门禁”解决上面问题吧,就用Trae常用技术栈。
- “把单题结论接到 TypeScript、React、Node.js、Supabase、Nginx 或 Vercel 项目里的一个真实薄弱点。”,“

# 刷题 Skill 需求设计文档
> 版本:V0.1(需求梳理稿)
> 日期:2026-05-26
---
## 目录
1. [Skill 定位与核心哲学](#1-skill-定位与核心哲学)
2. [Skill 整体架构](#2-skill-整体架构)
3. [知识资产层:题库 / 知识库 / 代码库](#3-知识资产层)
4. [评测系统](#4-评测系统)
5. [训练内容矩阵](#5-训练内容矩阵)
6. [双模式引擎:教练 vs 冷面](#6-双模式引擎)
7. [每日推送与节奏控制](#7-每日推送与节奏控制)
8. [防荒废与长期追踪](#8-防荒废与长期追踪)
9. [Vibe Coding 时代特色](#9-vibe-coding-时代特色)
10. [项目主线:从局部知识到完整项目](#10-项目主线)
11. [风格与语气分层](#11-风格与语气分层)
12. [MVP 最小可行版本](#12-mvp-最小可行版本)
13. [开放问题与决策点](#13-开放问题与决策点)
---
## 1. Skill 定位与核心哲学
### 1.1 我是谁
- **不是**普通刷题工具(不追求题量、不追求打卡、不制造大厂幻想)
- **是** AI 编程时代的真实技术筛选训练场
- 训练的不是"做题能力",而是六种底层能力:**拆解力、判断力、验证力、调试力、表达力、抗压力**
### 1.2 三条优先级原则
| 优先级 | 原则 | 含义 |
|--------|------|------|
| 第一 | 启动欲望 | 用户今天愿意动一下,比做什么更重要 |
| 第二 | 知识准确 | 答案必须正确,AI 不是事实源 |
| 第三 | 面试迁移 | 真实面试能用上的才算数 |
### 1.3 核心设计约束
1. **不能只靠 AI 自由生成内容**,否则严重幻觉
2. **专业度 = 题库 + 知识库 + 代码库 + 评测系统**,缺一不可
3. **AI 是讲解层,不是事实源**;事实源来自结构化资产
4. **失败不包装成成功**,错就是错,记录为训练资产
---
## 2. Skill 整体架构
### 2.1 分层架构图
```
┌──────────────────────────────────────────────────┐
│ 用户界面层 │
│ 每日推送 · 题目展示 · 代码编辑器 · 复盘面板 │
└──────────────────────────────────────────────────┘
│
┌──────────────────────────────────────────────────┐
│ 模式引擎层 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 启动模式 │ │ 训练模式 │ │ 冷面模式 │ │
│ │ (低能量) │ │ (正常) │ │ (高压) │ │
│ └──────────┘ └──────────┘ └──────────┘ │
└──────────────────────────────────────────────────┘
│
┌──────────────────────────────────────────────────┐
│ 训练内容层 │
│ 算法 · 八股 · Debug · 测试 · 系统设计 · 项目拆解 │
└──────────────────────────────────────────────────┘
│
┌──────────────────────────────────────────────────┐
│ 评测系统层 │
│ 代码执行 · 复杂度分析 · 表达评分 · 追问抗压 │
└──────────────────────────────────────────────────┘
│
┌──────────────────────────────────────────────────┐
│ 知识资产层(结构化,非 AI 自由发挥) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 题库 │ │ 知识库 │ │ 代码库 │ │
│ │ ~100题 │ │ ~100张卡 │ │ ~100段码 │ │
│ └──────────┘ └──────────┘ └──────────┘ │
└──────────────────────────────────────────────────┘
│
┌──────────────────────────────────────────────────┐
│ 用户数据层 │
│ 能力档案 · 错误记录 · 薄弱点图谱 · 训练痕迹 │
└──────────────────────────────────────────────────┘
```
### 2.2 数据流
```
用户输入 → 状态判断(今日能量/历史薄弱点)
→ 模式选择(启动/训练/冷面)
→ 内容匹配(从资产层捞取题目/知识卡/代码)
→ 展示 + 交互
→ 评测(执行/评分/追问)
→ 生成今日证据 + 更新用户档案
```
### 2.3 Skill 目录结构建议
```
skill-brush-up/
├── skill.md # Skill 主入口(行为定义)
├── assets/
│ ├── question-bank/ # 题库(结构化 JSON/MD)
│ │ ├── algorithms/ # 算法题
│ │ ├── system-design/ # 系统设计题
│ │ └── project-tasks/ # 项目拆解题
│ ├── knowledge-cards/ # 八股知识卡
│ │ ├── frontend/ # 前端
│ │ ├── backend/ # 后端
│ │ └── engineering/ # 工程化
│ ├── code-bank/ # 代码库
│ │ ├── standard/ # 标准解法
│ │ ├── buggy/ # AI 常见错误代码
│ │ ├── slow/ # 性能差代码
│ │ └── test-cases/ # 测试用例
│ └── evaluator/ # 评测器脚本
│ ├── code-runner/ # 代码执行评测
│ ├── complexity/ # 复杂度分析
│ └── expression/ # 表达能力评分规则
├── modes/
│ ├── startup-mode.md # 启动模式行为
│ ├── training-mode.md # 训练模式行为
│ └── cold-face-mode.md # 冷面模式行为
├── profiles/ # 用户档案(运行态生成)
└── templates/ # 输出模板
├── daily-evidence.md # 今日证据模板
└── error-review.md # 错题复盘模板
```
---
## 3. 知识资产层
> **核心原则:AI 只负责讲解,不负责任事实。事实源必须来自结构化资产。**
### 3.1 题库(Question Bank)
#### 题目来源
| 来源 | 说明 | 优先级 |
|------|------|--------|
| GitHub 优质仓库 | 如 LeetCode 题解仓库、interview 项目 | 高 |
| 经典面试题 | LeetCode Hot 100、剑指 Offer 等 | 高 |
| 自建 + 人工审核 | AI 生成后人工校验降低幻觉 | 中 |
| 真实项目场景抽象 | 从开源项目中提取真实 Bug/Debug 场景 | 特色 |
> **关于"300 还是 600 道"**:建议 **MVP 从 100 道起**,精选覆盖核心考点(数组、链表、树、DP、图、设计)。后续按需扩展,不追求题海,追求每道题都是"训练资产"。
#### 每道题的标准字段
```yaml
id: "ALG-001"
title: "两数之和"
category: "算法"
sub_category: "数组 / 哈希表"
difficulty: "easy" # easy / medium / hard
time_limit_minutes: 15 # 建议完成时间
tags: ["哈希表", "两数之和变体"]
# 题目描述
description: "..."
# 考点
key_points:
- 哈希表 O(1) 查找
- 空间换时间
# 标准解法(最优解)
standard_solution:
code: "..."
complexity:
time: "O(n)"
space: "O(n)"
explanation: "..."
# 暴力解法(对比用)
brute_force_solution:
code: "..."
complexity:
time: "O(n²)"
space: "O(1)"
# 常见错误
common_mistakes:
- type: "返回下标 vs 返回值混淆"
wrong_code: "..."
explanation: "..."
- type: "重复元素处理遗漏"
# 边界条件
edge_cases:
- input: "[]"
expected: "..."
- input: "[3,3], target=6"
expected: "[0,1]"
# 追问问题(面试模拟)
follow_up_questions:
- "如果数组已排序,如何优化?"
- "如果要求返回所有不重复组合?"
# 评分维度
scoring_rubric:
correctness: 40 # 正确性
complexity: 25 # 复杂度
edge_handling: 15 # 边界处理
code_quality: 10 # 代码质量
explanation: 10 # 讲解能力
# 项目迁移连接
project_connection: "在 React 中类似问题:用 Map 做状态缓存,避免重复计算"
```
### 3.2 八股知识库(Knowledge Cards)
> **八股知识必须进入知识库,不能让 AI 临场编答案。**
每张知识卡的标准字段:
```yaml
id: "KB-FE-001"
title: "React 虚拟 DOM 与 Diff 算法"
category: "前端"
sub_category: "React 核心机制"
# 概念定义
concept: "虚拟 DOM 是真实 DOM 的 JS 对象抽象..."
# 核心机制
core_mechanism:
- "Tree Diff:只对同层级节点比较"
- "Component Diff:同类型组件继续 diff,不同类型直接替换"
- "Element Diff:通过 key 标识节点移动"
# 标准回答(可直接用于面试)
standard_answer: "React 虚拟 DOM 的核心思想是..."
# 常见追问
follow_up_questions:
- "为什么不建议用 index 作为 key?"
- "Fiber 架构对 Diff 有什么改进?"
- "Vue 的 Diff 和 React 有什么区别?"
# 常见错误回答(反面教材)
wrong_answers:
- content: "虚拟 DOM 比真实 DOM 快"
correction: "虚拟 DOM 的优势不在于快,而在于..."
- content: "Diff 是 O(n³)"
correction: "React Diff 通过三个前提假设优化到 O(n)..."
# 工程场景连接
engineering_scenario: "当你在项目中遇到列表渲染性能问题时,你可以... 检查 key 使用 / 考虑虚拟列表 / 分析是否需要 React.memo"
# 来源校验
source: "React 官方文档 2024 / React Conf 演讲"
```
### 3.3 代码库(Code Bank)
> **代码训练不能只讲思路,必须能运行、能测试、能判定。**
代码库四类资产:
| 类型 | 用途 | 示例 |
|------|------|------|
| **标准代码** | 展示正确写法 | 正确实现的 LRU Cache |
| **错误代码**(AI 常见) | Debug 训练 | AI 生成的含竞态条件的 useEffect |
| **性能差代码** | 优化训练 | O(n²) 的列表渲染 |
| **边界错误代码** | 测试训练 | 未处理空数组的二分查找 |
每段错误代码附带:
```yaml
id: "BUG-REACT-001"
title: "useEffect 竞态条件"
code_snippet: |
useEffect(() => {
fetchUser(id).then(setUser)
}, [id])
bug_type: "race-condition"
what_is_wrong: "快速切换 id 时,旧请求可能后返回,覆盖新数据"
fix_code: |
let cancelled = false
fetchUser(id).then(data => {
if (!cancelled) setUser(data)
})
return () => { cancelled = true }
test_case: "..."
ai_model_that_made_this: "GPT-4 / Claude" # 标注哪个 AI 容易犯
vibe_coding_connection: "用 Cursor/Copilot 生成 useEffect 时,经常漏掉 cleanup"
```
---
## 4. 评测系统
> **用户答案不能只被鼓励,还要被判定是否真实可用。**
### 4.1 四大评测维度
```
┌──────────────────────────────────────┐
│ 1. 代码执行评测 ← 可自动化 │
│ - 能否通过所有测试用例 │
│ - 超时判定(大输入) │
│ - 内存溢出检测 │
├──────────────────────────────────────┤
│ 2. 复杂度评测 ← 可自动化 + AI 辅助 │
│ - 时间复杂度分析 │
│ - 空间复杂度分析 │
│ - 与标准解法的差距 │
├──────────────────────────────────────┤
│ 3. 表达能力评测 ← AI 辅助 │
│ - 思路是否清晰 │
│ - 关键步骤是否解释 │
│ - 是否遗漏重要细节 │
├──────────────────────────────────────┤
│ 4. 追问抗压评测 ← 冷面模式专用 │
│ - 回答是否自洽 │
│ - 被追问后是否崩溃 │
│ - 能否在压力下修正 │
└──────────────────────────────────────┘
```
### 4.2 评测结果输出
```yaml
evaluation_result:
overall_score: 72 # /100
passed_test_cases: 8/10
complexity_match: "接近最优,差一个优化点"
expression_clarity: "思路清晰但遗漏边界说明"
follow_up_performance: "第一问回答良好,第二问卡住"
failure_points:
- "未考虑空数组输入"
- "时间复杂度可以优化到 O(n)"
next_action: "专项修补:边界条件处理"
```
---
## 5. 训练内容矩阵
> **不只是算法,覆盖真实技术筛选的全部维度。**
| 维度 | 训练目标 | 形式 | 频率 |
|------|---------|------|------|
| **算法** | 拆解、验证、复杂度判断 | 限时解题 | 日常 |
| **八股** | 概念表达、追问抗压 | 知识卡 + 追问链 | 日常 |
| **Debug** | 发现 AI 代码错误 | 给定错误代码 → 找出问题 | 每周 2-3 次 |
| **测试设计** | 设计用例逼出错误 | 给定代码 → 写测试 | 每周 2-3 次 |
| **系统设计** | 架构思维、取舍表达 | 设计题 + 追问 | 每周 1 次 |
| **项目拆解** | 大需求拆小任务 | 需求 → 任务拆分 → 技术选型 | 每周 1 次 |
| **代码审查** | 判断 AI 代码可靠性 | Review AI 生成的 PR | 每周 1-2 次 |
---
## 6. 双模式引擎
### 6.1 教练模式(Coach Mode)
> **解决"不想学"和"不会学"**
- 语气温暖、鼓励但不虚假
- 允许短时间(3 分钟完成一个判断也算训练)
- 给出梯子:提示、拆解、降低难度
- 适用于启动模式和训练模式
### 6.2 冷面模式(Cold Face Mode)
> **解决"自以为会"**
- 模拟真实面试压力
- **限时**:严格计时,超时直接判无效
- **少提示**:不给线索,只给问题
- **强追问**:连续追问 3-5 轮,直到用户暴露边界
- **直接判错**:不兜圈子,直接说"这个答案真实面试过不了"
- **不羞辱**:指出问题但不说教,"冷"不等于"侮辱"
### 6.3 模式切换规则
```
用户低能量 ──→ 启动模式(教练语气)
用户有一点力气 ──→ 训练模式(教练语气 + 明确纠错)
用户状态较好 ──→ 冷面模式(限时 + 追问 + 直接判错)
强制规则:每周至少安排 1 次冷面模拟(不可跳过)
```
---
## 7. 每日推送与节奏控制
### 7.1 每天做什么:不提问,直接给任务
> **Skill 不应该每天问用户想学什么,应该每天自动给出一个训练任务。**
### 7.2 流程
```
Day Start
│
├─ 1. 状态判断
│ - 用户历史薄弱点
│ - 上次训练时间
│ - 本周冷面是否完成
│ - 今日最低要求 ↓
│
├─ 2. 任务分发
│ - 你今天需要完成___(具体题目/知识卡/代码片段)
│ - 预计用时___分钟
│ - 完成标准:___
│
├─ 3. 交互 + 评测
│
└─ 4. 生成今日证据
- 今天获得了什么能力
- 连接到项目迁移
- 连接到面试表达
- 连接到 AI 协作场景
```
### 7.3 三档完成标准
| 档位 | 名称 | 最低要求 | 适用场景 |
|------|------|---------|---------|
| 🟢 | 低能量完成 | 完成一个判断动作(如"这段代码有问题吗?") | 真的不想动 |
| 🟡 | 正常训练完成 | 完成一题 + 完整知识点闭环(解 → 评 → 复盘) | 日常 |
| 🔴 | 高压模拟完成 | 限时输出 + 接受追问 + 获得冷面评价 | 状态好/每周必做 |
---
## 8. 防荒废与长期追踪
### 8.1 防荒废机制
> **不靠连续打卡,靠最低有效动作。**
- 只要用户完成一个真实判断、一次复盘、一个测试用例 → **不算荒废**
- 断了之后 **不归零**,允许直接回到最低模式
- 不制造连续打卡压力和焦虑
### 8.2 长期薄弱点追踪
```
用户档案:
├── 薄弱点列表(按错误频次排序)
│ ├── 🟡 递归终止条件遗漏(出现 5 次)
│ ├── 🟡 React useEffect cleanup 遗漏(出现 3 次)
│ └── 🟢 二分查找边界(出现 1 次,已修复)
├── 最近 7 天训练日志
├── 冷面模拟记录
└── 待修补任务队列
```
### 8.3 错误 → 训练资产转化
```
用户答错
→ 评测系统记录失败点
→ 生成专项修补任务(放入队列)
→ 下次训练优先安排
→ 反复错 → 升级为高优先级修补任务
```
> **不追求新题,重视旧错复盘。**
---
## 9. Vibe Coding 时代特色
> AI 编程时代,**写代码的价值下降,判断代码的价值上升。**
### 9.1 六项 Vibe 时代核心能力
| 能力 | 训练方式 | Skill 对接 |
|------|---------|-----------|
| 指挥 AI 写代码 | 给用户一个需求,要求 Prompt 驱动 AI 完成 | 项目拆解题 |
| 判断 AI 代码可靠性 | 给一段 AI 生成的代码,判断是否正确 | Debug 训练 |
| 发现复杂度问题 | 给一段"看起来对但性能差"的代码,指出问题 | 复杂度评测 |
| 设计测试用例逼出错误 | 给一段代码,要求设计能发现 bug 的测试 | 测试设计训练 |
| 接管 AI 写坏的代码 | 给一段有问题的 AI 代码,修复 | Debug 训练 |
| 知识迁移到真实项目 | 每道题/卡连接真实场景 | 今日证据 |
### 9.2 典型 Vibe 场景:全栈 TS + React 项目
用户可以这样子"Vibe"一个服务器项目:
```
用户:我想写一个全栈项目,用 TypeScript + React + Node.js,
做一个类似 Notion 的协作文档工具
Skill 响应:
好的,让我们一步步把这个需求梳理清楚。
[生成结构化的需求文档 MD]
现在我们从"训练视角"看这个项目,把它拆成训练任务:
📋 项目拆解(系统设计训练)
├── Week 1: 数据模型设计 + API 设计
├── Week 2: 实时协作(CRDT / OT 理解)
├── Week 3: 前端编辑器实现
└── Week 4: 权限系统
🎯 今天的训练:设计协作文档的数据模型
- 八股卡:数据库范式 vs NoSQL 选择
- 代码训练:写出 User / Document / Version 的 TypeScript 类型定义
- 评测:你的类型设计是否考虑了所有边界?
- Vibe 连接:用 Cursor 生成 CRUD API 时,你如何判断它是否正确?
📌 今日证据模板:
今天你获得了「数据建模」能力
→ 项目迁移:你的 Notion 项目中,Document 表设计正确了
→ 面试表达:你能说清楚为什么用 PostgreSQL 而不是 MongoDB
→ AI 协作:你知道如何让 AI 生成 migration 并检查它
```
### 9.3 代码库中标注 AI 来源
所有错误代码都应该标注"哪个 AI 模型容易犯":
```yaml
ai_model_that_made_this: "GPT-4"
vibe_coding_scenario: "用 Cursor 的 Copilot 自动补全函数时容易出现"
```
这样用户在实际 Vibe Coding 中遇到类似问题时,能立刻召回训练记忆。
---
## 10. 项目主线
> **项目是主线,局部知识是项目中的武器。**
### 10.1 不让用户孤立刷题
- 每周至少一个**端到端项目任务**
- 每天小训练**服务于项目能力**
- 算法题 → 连接真实开发场景
- 八股知识 → 连接工程场景
- 代码审查 → 连接 AI 协作场景
### 10.2 用户自己带项目 or 系统提供
```
选项 A:用户带自己的项目(如"我正在做 Notion 克隆")
→ Skill 围绕用户项目拆解训练内容
选项 B:系统提供标准项目模板(如"电商后台管理系统")
→ 逐步拆解、逐步训练
```
---
## 11. 风格与语气分层
| 场景 | 语气 | 示例 |
|------|------|------|
| 低能量 / 启动 | 不羞辱、不施压、给梯子 | "你今天可以只做 3 分钟,看看这段代码有没有问题就行" |
| 正常训练 | 明确纠错、有依据 | "你的解法通过了测试,但时间复杂度是 O(n²),标准解法是 O(n)" |
| 冷面模拟 | 接近真实面试、限时、少提示 | "你的回答缺少对边界条件的说明。真实面试中,面试官会在这一点上追问你。这个答案过不了。" |
关键语录:
- 🟢 "你今天可以只做 3 分钟"
- 🟡 "你的解法还可以优化,看这里..."
- 🔴 "这个答案真实面试过不了"
---
## 12. MVP 最小可行版本
### 12.1 V0.1 范围
| 资产 | 数量 | 说明 |
|------|------|------|
| 题库 | **100 道高质量题目** | 算法 60 + 系统设计 15 + Debug 15 + 项目 10 |
| 八股知识卡 | **100 张** | 前端 40 + 后端 30 + 工程化 30 |
| AI 错误代码 | **100 段** | 覆盖 React/TS/Node/算法常见 AI 生成错误 |
| 训练模式 | **3 种** | 启动模式 / 训练模式 / 冷面模式 |
### 12.2 三种模式的 MVP 定义
| 模式 | 解决什么 | MVP 行为 |
|------|---------|---------|
| 启动模式 | 不想学 | 推一张 3 分钟判断卡("这段代码对吗?")+ 鼓励 |
| 训练模式 | 不会学 | 完整流程:出题 → 做题 → 评测 → 复盘 → 今日证据 |
| 冷面模式 | 自以为会 | 限时 + 追问 + 直接判错 + 失败点记录 |
### 12.3 题库来源 MVP(回答你的问题)
**要不要题库?** → **要。没有题库,AI 自由生成的内容幻觉严重。**
**从哪里找?**
| 来源 | 内容 | 获取方式 |
|------|------|---------|
| GitHub | LeetCode 题解汇总仓库、interview 项目 | 直接下载,筛选 100 题 |
| GitHub | [TheAlgorithms/TypeScript](https://github.com/TheAlgorithms/TypeScript) | 收录标准解法 |
| GitHub | [donnemartin/system-design-primer](https://github.com/donnemartin/system-design-primer) | 系统设计题参考 |
| GitHub | 各类 interview-questions 仓库 | 八股题源 |
| 自建 | AI 错误代码库 | 需要人工收集和标注 |
| 自建 | 八股知识卡 | 结合权威文档编写,标注来源 |
**"300 还是 600 道"?** → MVP 100 道精选,后续按需扩展。600 道题海不是我们的目标,每道题都应该是"训练资产"而非"题号"。
---
## 13. 开放问题与决策点
以下是需要进一步讨论和决策的关键问题:
### 13.1 题库方面
- [ ] **100 道题的筛选标准**:哪些是必选?按 LeetCode Hot 100 来?还是按真实面试频率?
- [ ] **题库格式**:JSON / YAML / MD?建议 YAML(可读性好,结构清晰)
- [ ] **题库更新机制**:谁来维护?如何 review?多久更新一次?
### 13.2 代码执行评测
- [ ] **是否需要沙箱执行**?用户写的代码直接在 Skill 环境中运行?
- [ ] **支持的语言**:先只支持 TypeScript/JavaScript?还是 Python/Java 也要?
- [ ] **超时和内存限制**如何设定?
### 13.3 用户状态
- [ ] **"低能量/正常/高压"如何判断**?用户自报?还是系统根据日期/历史自动判断?
- [ ] **用户档案存储在哪里**?本地文件?云端?
### 13.4 Vibe Coding 对接
- [ ] 是否需要与 Cursor / Copilot / Windsurf 等工具的 API 对接?
- [ ] 还是纯粹通过 Skill 模拟"AI 协作场景"?
### 13.5 项目主线
- [ ] 用户自带项目 vs 系统提供标准项目?还是两者都支持?
- [ ] 标准项目模板有哪些(全栈博客 / 电商 / Notion 克隆 / 聊天应用)?
### 13.6 Skill 技术实现
- [ ] Skill 以什么形式存在?一个 `.md` skill 文件 + assets 目录?
- [ ] 评测系统的代码执行能力取决于 Skill 运行环境的能力边界?
- [ ] 冷面模式的"限时"如何实现?利用 Skill 的 timeout 机制?
---
## 附录:术语表
| 术语 | 定义 |
|------|------|
| 题库 | 结构化题目资产,包含题目/考点/标准解/错误解/追问/评分点 |
| 知识卡 | 结构化八股知识资产,包含概念/机制/标准答/错误答/追问/来源 |
| 代码库 | 标准代码 + 错误代码 + 测试用例的结构化集合 |
| 评测器 | 对用户答案进行代码执行/复杂度/表达/抗压四维评分的系统 |
| 教练模式 | 温暖引导、给梯子的模式,解决"不想学"和"不会学" |
| 冷面模式 | 限时、少提示、强追问、直接判错的模式,模拟真实面试压力 |
| 今日证据 | 每天训练后的能力总结,连接项目迁移/面试表达/AI协作 |
| 能力痕迹 | 用户完成一次真实判断/复盘/测试的不可伪造的训练记录 |
| 最低有效动作 | 防止荒废的最小单位(做一次判断即算训练,不断打卡) |
| 专项修补任务 | 根据用户反复出错的知识点自动生成的针对性训练 |
- 1.0.1 更新对用户直接粘贴ai内容的检测
- 1.0.2 更新直接提示用户这个题目能不能在当前全栈项目的哪个点观察实践
