TRAE 中国版内置的 Kimi-K2.6/2.5 模型
现已支持原生视频理解能力
看到有挺多人困惑怎么使用原生视频理解能力,刚好周末录了个视频,解答一下初学者们的疑惑。
原生视频理解能力指的是 Kimi-K2.6/2.5 模型不再只是逐帧看图片,而是能直接"看懂"视频的连续内容——包括画面中的动效变化、操作流程、交互行为等。它能理解视频里"发生了什么",而不是仅仅识别每一帧的静态画面。
大家应该比较多用到的场景是网站或者视频动效录屏直出前端代码。
首先要说一下原文中的视频路径指的是本地路径,这是 TRAE 这个 IDE 工具内的功能,需要你本机上有视频文件,传入该文件的路径即可让模型分析。
不是 B 站链接或在线视频 URL。
所以本地路径应该是:
<mac 端视频路径示例>
/Users/你的用户名/Desktop/fps_gameplay.mp4
或者你就像我一样直接把视频拖进工作区,再右键添加到对话也可以

你可以像我一样对产出的结果做一些约束,比如我上面截图写的:
请逐帧分析这段视频中展示的内容,目标是100%还原:
1. 精确识别所有UI元素:每个按钮的位置、尺寸、颜色、圆角、阴影
2. 逐帧记录所有动效:每个元素的动画曲线、时长、延迟、缓动函数
3. 完整还原交互逻辑:点击/悬停/滚动触发的所有状态变化
4. 精确匹配所有颜色:提取每个元素的HEX/RGB值
5. 还原所有布局细节:间距、对齐方式、响应式断点
输出完整的前端代码(HTML+CSS+JS),
确保代码运行效果与视频中展示的完全一致。
我录屏的是一个比较经典的 H5 页面:in pieces
原网站
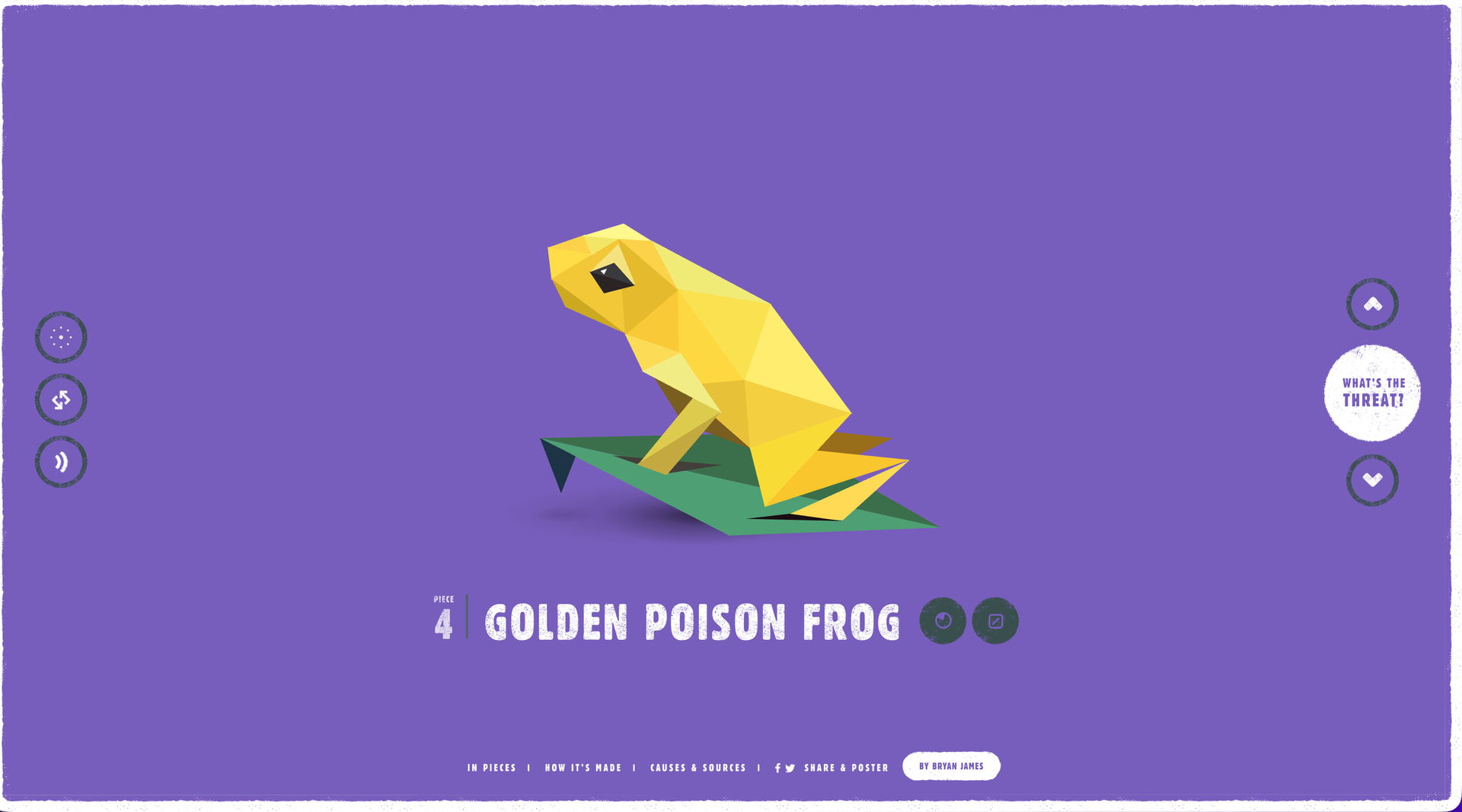
Kimi 复刻

我要圆一句,这个网站其实非常的复杂,有非常夸张的动画效果,所以仅凭一段文字约束和十几秒的视频就可以做到这样程度的复刻,我觉得未来可期!
视频同时也发在了 B 站,时长很短想要看复刻效果对比的可以去看下
【Kimi 2 天没用已经到这种程度了吗-哔哩哔哩】 https://b23.tv/lrCGOKU