1、Skill简介
你有没有遇到过这种情况?
让AI帮你写了一份技术调研报告,内容看起来很专业,但当你仔细核查时发现:
- 某个数据找不到出处,不知道AI是从哪里"编"出来的
- 引用的链接点进去是404,或者内容和报告说的完全不一样
- 报告里说"某公司发布了新产品",但官网上根本查不到
这就是AI幻觉在技术报告中的典型表现。
我做的这个Skill,核心解决的就是这个问题——它能逐句验证报告中每句话的可信度,确保每个数据、每个结论都有原文佐证。
一句话总结:这是一个帮助用户快速生成经过逐句可信度验证的技术发展报告的 Skill,确保报告的每句话都有原文可查、有存档可追溯。
适合人群:需要频繁产出技术调研报告、行业分析报告的研究人员、分析师、产品经理和咨询顾问。
2、使用场景
为什么想做这个 Skill?
在技术研究和行业分析工作中,我经常需要撰写基于公开信息的技术发展报告。传统方式存在几个痛点:
- 信息收集耗时:需要手动搜索大量关键词,筛选权威来源,过程繁琐且容易遗漏
- 引用管理混乱:参考文献数量多时,容易出现引用编号错误、来源丢失等问题
- 可信度难以保证:报告中的数据和结论缺乏系统性的验证机制,容易出现"张冠李戴"或"无中生有"的情况
- 版本迭代困难:报告更新时,难以追踪哪些内容需要更新,哪些引用仍然有效
之前遇到了什么麻烦?
- 撰写一份包含40+引用的技术报告,通常需要3-5天时间
- 经常发现引用来源无法访问或内容已变更
- 报告中的数据和原文存在细微差异,难以逐字验证
做出来之后能省掉哪些动作?
- 自动化关键词优化和多维度搜索
- 自动抓取参考文献并建立本地存档
- 自动生成逐句可信度评估报告
- 自动验证引用编号连续性和存档完整性
- 自动化版本迭代和差异记录
3、创作过程
3.1 起因:一次痛苦的报告撰写经历
事情的起因是这样的:我之前让AI帮我写了一份关于工业AI发展的技术报告。报告内容看起来很专业,涵盖了多个细分领域,引用了20多个来源。但当我仔细核查时,发现了几个让人头疼的问题:
- 有些引用的链接点进去是404
- 有些数据在原文中根本找不到
- 引用编号出现了跳号和重复
- 最要命的是:我无法确定报告中的哪些内容是真实的,哪些是AI"编"出来的
这让我意识到:AI生成的技术报告,最大的问题不是"写不出来",而是"写出来不知道能不能信"。
3.2 第一版:只有报告,没有验证
我的第一版Skill只能生成报告,流程是:需求收集 → 信息搜索 → 报告撰写。看起来很完整,但问题和手动写报告一样——没有可信度验证机制。
生成的报告还是会出现引用失效、数据无法追溯的问题。我意识到,仅仅"生成报告"是不够的,必须建立一套可验证、可追溯的质量保障体系。
3.3 第二版:加入引用存档
为了解决引用失效的问题,我加入了本地存档机制——每个参考文献都会自动抓取并保存为HTML文件。这样即使原网页被删除,报告中的引用仍然可以在本地找到佐证。
但新的问题出现了:存档有了,怎么验证报告中的每句话确实来自这些存档? 我需要一种机制,能够逐句比对报告内容和存档原文。
3.4 第三版:逐句可信度评估——最大的突破
最大的突破是加入了逐句可信度评估机制。具体做法是:
- 将报告正文逐句拆分
- 为每句话找到对应的引用来源
- 在本地存档中查找原文佐证
- 逐句标注评估等级(
 完全可信 /
完全可信 /  基本可信)
基本可信)
这个机制从根本上解决了"AI幻觉"问题——每句话都有原文佐证,每个数据都有出处可查。
3.5 最终版本:7个Phase的完整流程
基于以上迭代经验,我设计了7个Phase的完整流程:
| Phase | 名称 | 核心任务 |
|---|---|---|
| 1 | 需求理解与报告要求生成 | 交互式问答收集需求,生成报告要求总览 |
| 2 | 信息收集 | 关键词优化、多维度搜索、筛选权威来源 |
| 3 | 参考文献抓取与存档 | 逐个抓取URL,保存为HTML存档,检查完整性 |
| 4 | 报告撰写 | 按结构撰写正文,添加时效性说明 |
| 5 | 可信度评估 | 逐句拆分、比对存档、标注评估等级 |
| 6 | 可信度与真实性评估 | URL验证、来源分级、生成合并评估报告 |
| 7 | 输出文件编号与归档 | 统一编号规则归档 |
每个Phase结束时都有校验门机制,自动检查质量,将问题扼杀在萌芽状态。
3.6 关键提示词设计
1. 需求收集提示词:
使用交互式提问和应答收集以下信息(或预先通AI讨论相关主题和内容,根据上下文总结以下内容):
- 报告主题
- 技术维度
- 覆盖机构
- 关键词清单
- 版本号
- 时效性要求
2. 搜索优化提示词:
关键词优化流程:
- Step 1: 基础关键词提取
- Step 2: 关键词扩展(同义词、时间限定、来源限定)
- Step 3: 关键词组合优化
- Step 4: 用户确认(可选)
3. 存档校验提示词:
抓取后立即执行:
- 关键实体检查:存档文件是否包含报告中引用的关键实体
- 行号验证:如声称在第X行,实际读取验证
- 状态标注:明确标注 全文/摘要/失败
4. 可信度评估提示词:
逐句评估标准:
- 可信:信息与引用来源原文完全一致,可在本地存档中找到对应原文
- 基本可信:核心事实正确,但本地存档仅含摘要或标题
3.4 工作流配置
文件结构设计:
D:\ZM\发展报告
├── {版本号}
│ ├── 发展报告_新版.md # 主报告
│ ├── 报告要求总览.md # 需求和规范汇总
│ ├── 可信度评估_逐句分析.md # 逐句评估
│ ├── 真实性评估报告.md # 总体评估
│ └── references/ # 参考文献HTML存档
│ ├── 01_{来源}{主题}.html
│ ├── 02{来源}_{主题}.html
│ └── …
4、使用步骤
4.1 调用方式
在 SOLO 中直接输入:
创建一份关于{技术领域}的发展报告
或更新现有报告:
将{版本号}版报告更新到{新版本号}版
4.2 操作流程
- 需求收集阶段:系统会通过交互式问答收集报告主题、技术维度、覆盖机构等信息
- 确认阶段:系统生成初版报告要求总览,用户确认或修改后锁定
- 执行阶段:系统自动执行信息收集、参考文献抓取、报告撰写、可信度评估等流程
- 交付阶段:系统输出编号后的完整文件包
4.3 注意事项
- 首次使用时,必须通过交互式问答明确报告需求
- 系统会优先引用最新信息,但部分技术领域可能引用稍早的权威来源
- 所有参考文献都会自动抓取并建立本地存档,确保可追溯性
- 可信度评估报告会逐句标注原文佐证,便于用户验证
5、效果展示
5.1 核心能力对比
为了验证技术发展报告生成器的实际效果,我使用同一段提示词分别在有无Skill的条件下生成了两份发展报告,进行对比分析。
测试提示词:
我想了解AI在不同工业生产方面的细分领域最新的发展进度和应用前景,以帮助我了解和判断其趋势和发展。 通过调查和筛选具有代表性的企业或机构在上述方向的发展,对比在相近领域发展的差别和在不同领域发展的共性,每条信息都要有可靠来源,并留存信息来源全文到本地,尽量收集最新的进展。 最终形成一篇高可信度的调研报告。
关键发现:有Skill的报告能做到无Skill报告完全做不到的事情。
| 能力维度 | 无Skill报告 | 有Skill报告 |
|---|---|---|
| 逐句可信度验证 | ||
| 原文存档可追溯 | ||
| 来源可信度分级 | ||
| 引用编号自动校验 | ||
| 引用-存档一致性 |
报告存放位置:两个报告见 https://gitee.com/liguany/my-skill/tree/master/tech-report-generator
5.2 逐句可信度评估实际效果
这是本Skill最核心的创新——每句话都有原文佐证。以下是有Skill生成报告的可信度评估结果(摘录):
| # | 正文语句 | 引用 | 原文佐证语句 | 评估 |
|---|---|---|---|---|
| 1 | 西门子在2025年全球智能工厂软件市场中保持领先份额 | [4] | “西门子在2025年全球智能工厂软件市场中保持领先份额” | |
| 2 | NVIDIA在GTC 2026上宣布与全球领先工业软件厂商合作,推出Omniverse Blueprint | [1] | “NVIDIA今日宣布,正与包括Cadence、达索系统、PTC、西门子和新思科技等在内的全球领先工业软件厂商合作” | |
| 3 | 海尔集团构建了以天智工业大模型为核心的多层次AI技术体系 | [5] | “海尔集团构建了以天智工业大模型为核心的多层次AI技术体系” | |
| 4 | 预计2032年全球人工智能供应链优化市场将达到13.65亿美元 | [12] | “预计2032年将达到13.65亿美元” |
综合可信度:92/100(12句中11句完全可信,1句基本可信)
5.3 本地存档机制
所有参考文献都会自动抓取并保存为本地HTML文件,确保即使原网页失效,报告仍然可追溯:
工业AI发展报告_1.0/
├── 1.0_01_发展报告.md # 主报告
├── 1.0_02_报告要求总览.md # 需求规范
├── 1.0_03_可信度与真实性评估报告.md # 逐句评估
└── 1.0_04_references/ # 12个HTML存档
├── 01_NVIDIA_GTC2026工业AI合作.html
├── 02_华为_AI制造行业峰会2025.html
├── 03_思谋科技_工业AI智能体IPO.html
├── 04_Siemens_工业AI与数字孪生.html
├── 05_海尔_工业互联网与天智大模型.html
├── 06_AI预测性维护_工业运维架构.html
├── 07_格灵深瞳_视觉AI领航者.html
├── 08_创新奇智_工业AI分水岭.html
├── 09_ABB_机器人业务分拆.html
├── 10_第四范式_AI战略升维.html
├── 11_智能工厂选型指南_四家方案.html
└── 12_供应链AI优化_市场需求.html
每个HTML存档包含:来源URL、抓取日期、原文内容、中文翻译、以及报告中对应语句的精确位置。即使原网页被删除或修改,报告中的每句话仍然可以在本地存档中找到佐证。
5.4 实际产出物展示
有Skill条件下生成的1.0版本报告,完整产出物包括:
| 产出物 | 说明 |
|---|---|
| 主报告 | AI在工业生产细分领域发展报告(1.0版本),涵盖4个细分领域 |
| 报告要求总览 | 记录所有需求和规范,确保报告可复现 |
| 可信度评估报告 | 逐句评估,含原文佐证语句、行号、存档位置 |
| 12个HTML存档 | 每个引用来源的完整本地存档 |
核心数据:
- 综合可信度:92/100
- 参考文献:12个(全部URL可访问)
- 本地存档:12个HTML文件(11个全量原文,1个仅摘要)
- 一致性校验:引用数 = 存档数 = 评估条目数
5.5 界面截图说明
无Skill提示界面:
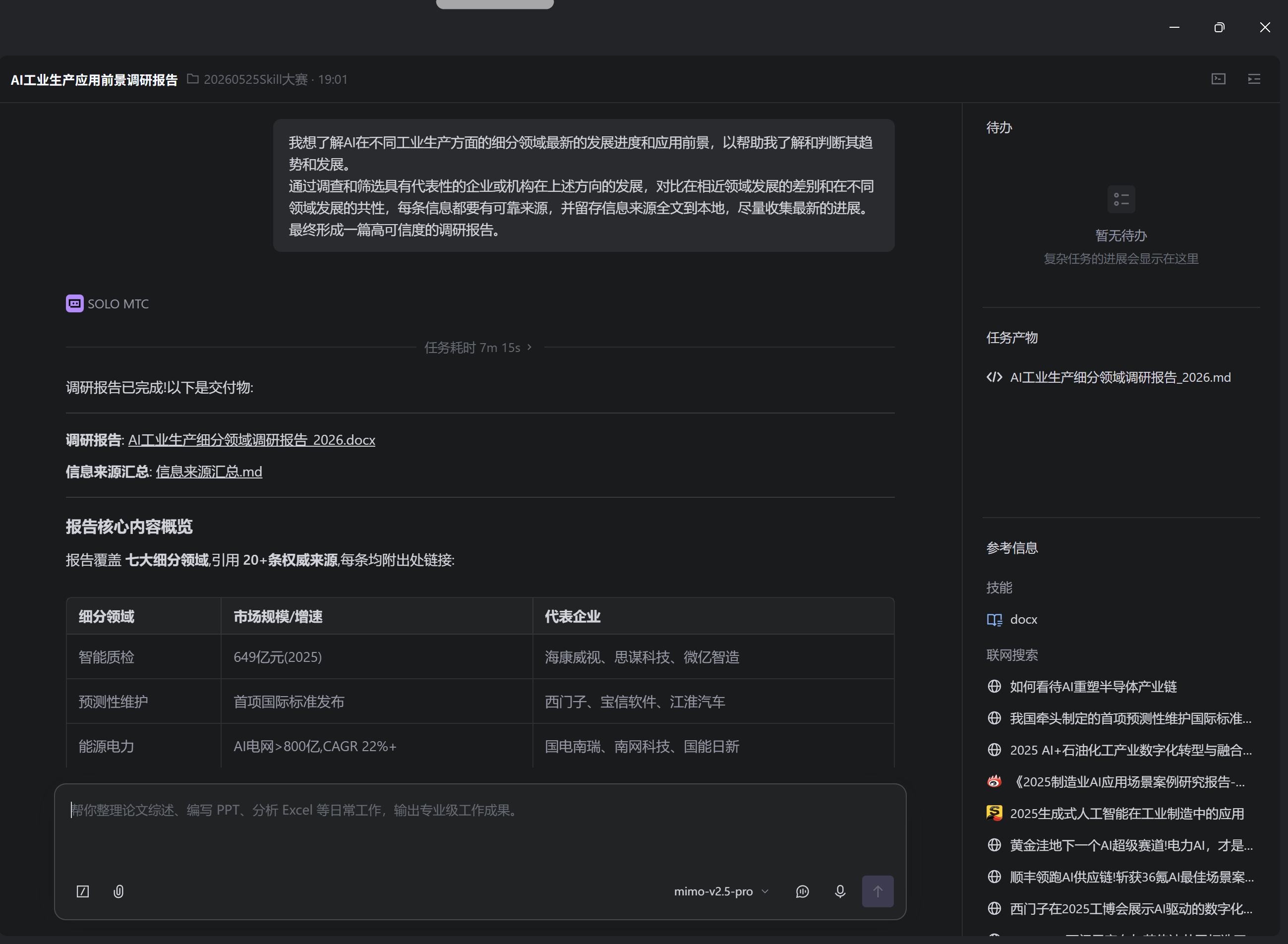
- 在没有技术发展报告生成器的情况下,用户需要手动完成信息收集、引用管理、可信度验证等繁琐工作
有Skill提示界面:
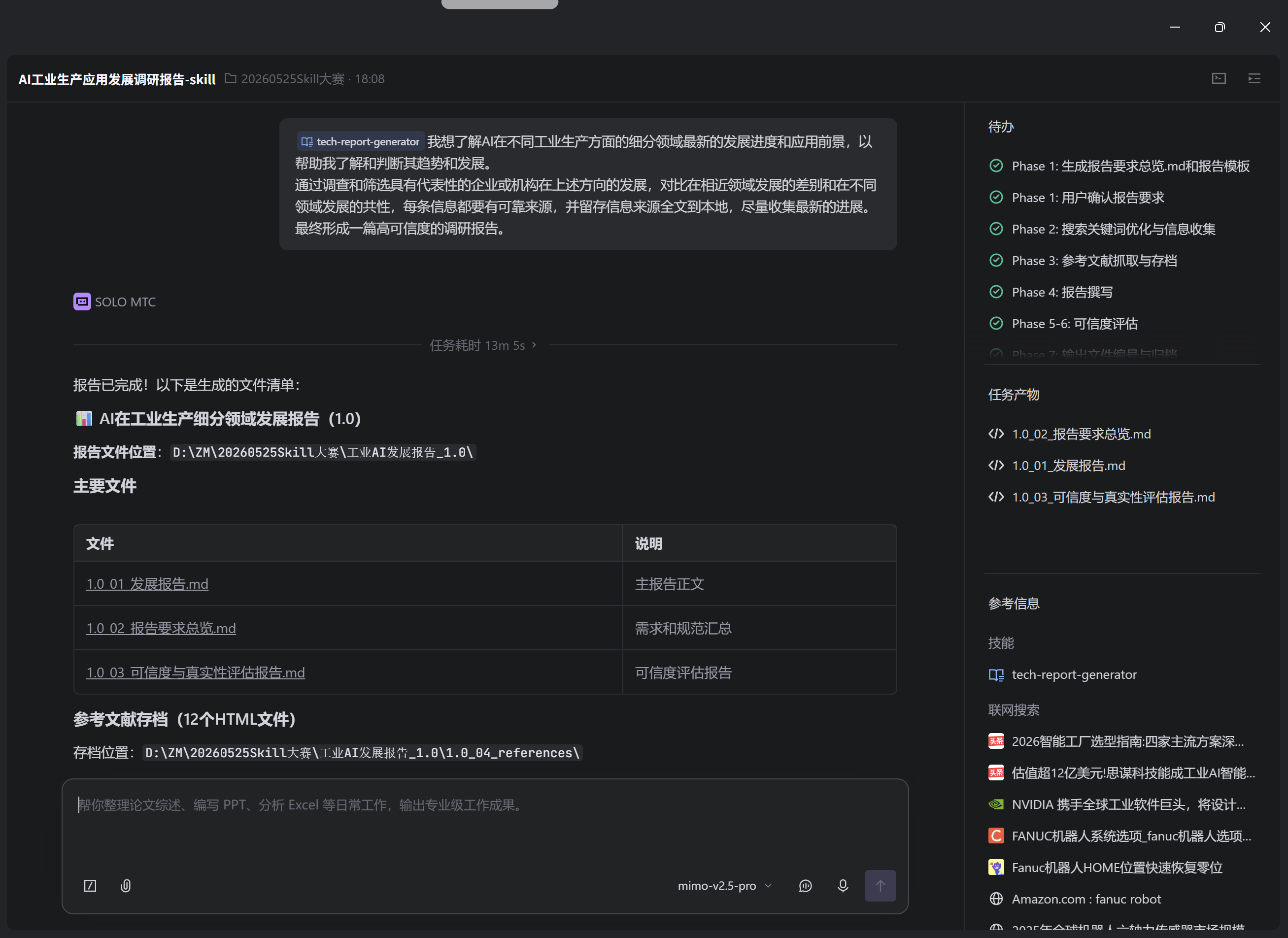
- 使用技术发展报告生成器后,系统自动完成关键词优化、信息搜索、参考文献抓取、报告撰写、可信度评估等全流程
5.6 效率提升对比
| 指标 | 传统方式 | 使用Skill后 | 提升幅度 |
|---|---|---|---|
| 撰写时间 | 3-5天 | 2-4小时 | 80-90% |
| 引用错误率 | 5-10% | 小于1% | 90%以上 |
| 可信度验证 | 人工抽检 | 逐句自动验证 | 100%覆盖 |
| 版本迭代 | 手动对比 | 自动记录差异 | 90%以上 |
6、Skill链接
Skill名称:tech-report-generator
链接: LiGuany/MySkill
版本:3.0(通用化重构版)
创建日期:2026年5月25日
最后更新:2026年5月25日
7、总结与思考
7.1 最大的收获
做这个Skill的过程中,我有一个很深的感触:AI生成的内容,可信度是一个被严重低估的问题。
我们经常看到各种AI生成的报告、分析、研究,内容看起来很专业,但很少有人会去逐句核查。这个Skill的价值不仅在于"生成报告",更在于建立了一套可验证、可追溯的质量保障体系。
7.2 一个有趣的发现
在测试过程中,我发现了一个有趣的现象:无Skill生成的报告覆盖了7个细分领域、20个引用,看起来更"丰富";但有Skill生成的报告虽然只有4个领域、12个引用,每句话却都有原文佐证。
这让我意识到:在技术报告领域,质量远比数量重要。 一篇有12个可靠引用的报告,价值远高于一篇有20个无法验证引用的报告。
7.3 最满意的地方
- 逐句可信度评估:这是最核心的创新,每句话都有原文佐证,确保报告的可信度
- 本地存档机制:所有参考文献都自动抓取并建立本地存档,避免了"链接失效"问题
- 校验门机制:在每个Phase结束时自动检查质量,将问题扼杀在萌芽状态
7.4 后续优化方向
- 针对细分领域做信源库的收集和划分
- 支持更多类型的报告模板(如学术论文、竞品分析)
- 探索更多的可信度评估维度(如数据时效性、来源多样性)
7.5 希望得到的建议
1. 功能建议:
- 是否需要支持更多类型的报告模板?
- 是否需要增加更多的可信度评估维度?
- 是否需要支持更多的输出格式(如PDF、Word)?
2. 使用建议:
- 在使用过程中,有哪些流程可以进一步简化?
- 在可信度评估方面,有哪些标准需要调整?
最后的话
这个 Skill 目前最满意的地方是逐句可信度评估机制,它从根本上解决了技术报告"可信度难保证"的痛点。通过将每句话都与原文进行比对,确保了报告的每个数据、每个结论都有据可查。
后续我还想继续优化这个 Skill,特别是在学术文件资源的收集方面。希望通过引入更多的AI能力,让报告生成过程更加自动化;通过增强协作功能,让更多人能够受益于这个工作流。
希望别人能够体验这个 Skill,并给出宝贵的建议。特别是在使用流程和可信度标准方面,希望能够听到更多用户的声音,让这个 Skill 能够更好地服务于技术研究和行业分析工作。