【Skill 创作】skill-review:给 Agent 技能做"年检"的元技能
一、Skill 简介
名称:skill-review
一句话:一个能审查任何 Agent 技能的"元技能"——自动按 50+ 检查项逐层评审,输出标准化报告,帮你发现技能文件里的隐藏问题。
解决什么问题:你写了一个 Skill,功能跑通了,但它真的写得好吗?YAML 格式对了吗?Few-Shot 示例够不够?关联文件过没过期?有没有和已有技能功能重叠?这些问题运行时不一定报错,但会让技能越来越难维护。skill-review 就是干这件事的——一键审查,全面诊断。
目标用户:所有在 TRAE SOLO 上创建和迭代技能的用户,尤其适合需要长期维护多个技能的团队。
二、使用场景
事情的起点是 TRAE 公众号的一篇文章《一文读懂 Skills|从概念到实操的完整指南》。读完之后我意识到:写技能有标准,但没人帮你检查你有没有遵守标准。
我手里正在维护一个 jenkins-xgo-build 技能——它负责 Go 项目的交叉编译流水线。从第一个版本到最终版本,我迭代了 6 轮。每一轮都是这样:
我改完 → 手动贴给审查 Agent → 审查 Agent 出报告 → 我照着修 → 再贴 → 再审...
最长的一轮,我手动搬运了 8 次。这个过程中我反复踩到同样的坑:新增内容被不小心塞到了 YAML 头前面导致技能加载失败;Groovy 脚本里的括号没闭合,Jenkins 静默丢弃了 job 不报错;SKILL.md 从 200 行膨胀到 600+ 行,越来越没人敢动。
我开始想:能不能做一个技能,让它自动帮我做这些检查?
三、创作过程
3.1 灵感来源
一切从 TRAE 公众号的那篇文章开始。文章提出了好技能的五大标准:原子性、描述清晰度、Few-Shot 示例、结构化指令、接口设计。
但我没有满足于这一家之言。我花了半天时间,交叉验证了 7 个独立来源:
| 来源 | 性质 | 核心主张 |
|---|---|---|
| Anthropic Skill Best Practices | 官方文档 | 简洁为王、自由度分级、渐进式加载 |
| Anthropic Context Engineering | 工程博客 | “上下文是公共资源,每个 token 必须自证价值” |
| Cursor Agent Best Practices | 官方文档 | Skills 动态按需加载 vs Rules 静态全量加载 |
| Agensi 平台对比 | 独立分析 | SKILL.md 是跨 20+ Agent 的开放标准 |
| Bishoy Labib 综合指南 | 社区深度 | Skills vs MCP 互补关系 |
| Spillwave Solutions | 架构师认证 | 三级加载机制实现 90% Token 削减 |
| Vprprudhvi 工程指南 | 社区实践 | “Skill 不触发,几乎永远是 description 的问题” |
3.2 提炼检查项
从这 7 个来源中,我提炼出了 50+ 具体检查项,按严重程度分三级:
-
 致命(9 项):YAML 格式错误、Groovy 语法错误、引用不存在的文件……这些会让技能完全不可用
致命(9 项):YAML 格式错误、Groovy 语法错误、引用不存在的文件……这些会让技能完全不可用 -
 重要(28 项):描述模糊、示例过时、文件臃肿……这些影响可维护性但不阻塞使用
重要(28 项):描述模糊、示例过时、文件臃肿……这些影响可维护性但不阻塞使用 -
 建议(16 项):补充错误场景示例、标注自由度分级……锦上添花的优化
建议(16 项):补充错误场景示例、标注自由度分级……锦上添花的优化
3.3 设计五层审查架构
检查项太多,如果一次全塞进上下文,Token 直接爆炸。所以我参考了 Anthropic 的"渐进式加载"设计,把审查拆成 5 层递进:
Level 0 → 前置检查(YAML 有效吗?语法对吗?)—— 任何致命问题立即终止
Level 0.5 → 跨技能冲突(和已有技能重叠吗?)—— 防止重复造轮子
Level 1 → 五维深度评审(原子性/描述/Few-Shot/结构/接口)
Level 1.5 → 关联文件审查(引用的文件存在吗?内容矛盾吗?)—— 最容易漏的
Level 2 → 内容一致性(自己打自己脸了吗?臃肿了吗?)
3.4 在 TRAE SOLO 中实现
我在 TRAE SOLO 中创建了 skill-review 技能,将 50+ 检查项的完整审查标准内嵌在 references/sop.md 中。技能本身是一个索引体——SKILL.md 只有 ~130 行,定义角色、红线和审查流程;详细的检查项标准按需加载,保证上下文不浪费。
四、使用步骤
在 TRAE SOLO 中加载 skill-review 后,只需要一句话:
帮我审查一下 jenkins-xgo-build 这个技能
技能会自动:
-
加载内嵌的审查标准(
references/sop.md) -
读取目标技能的 SKILL.md 和关联文件
-
按五层标准逐项检查
-
输出包含五维得分、致命/重要/建议问题清单的标准化评审报告
全程不需要你手动对比任何东西。
五、效果展示
5.1 审查一个"有问题的"技能
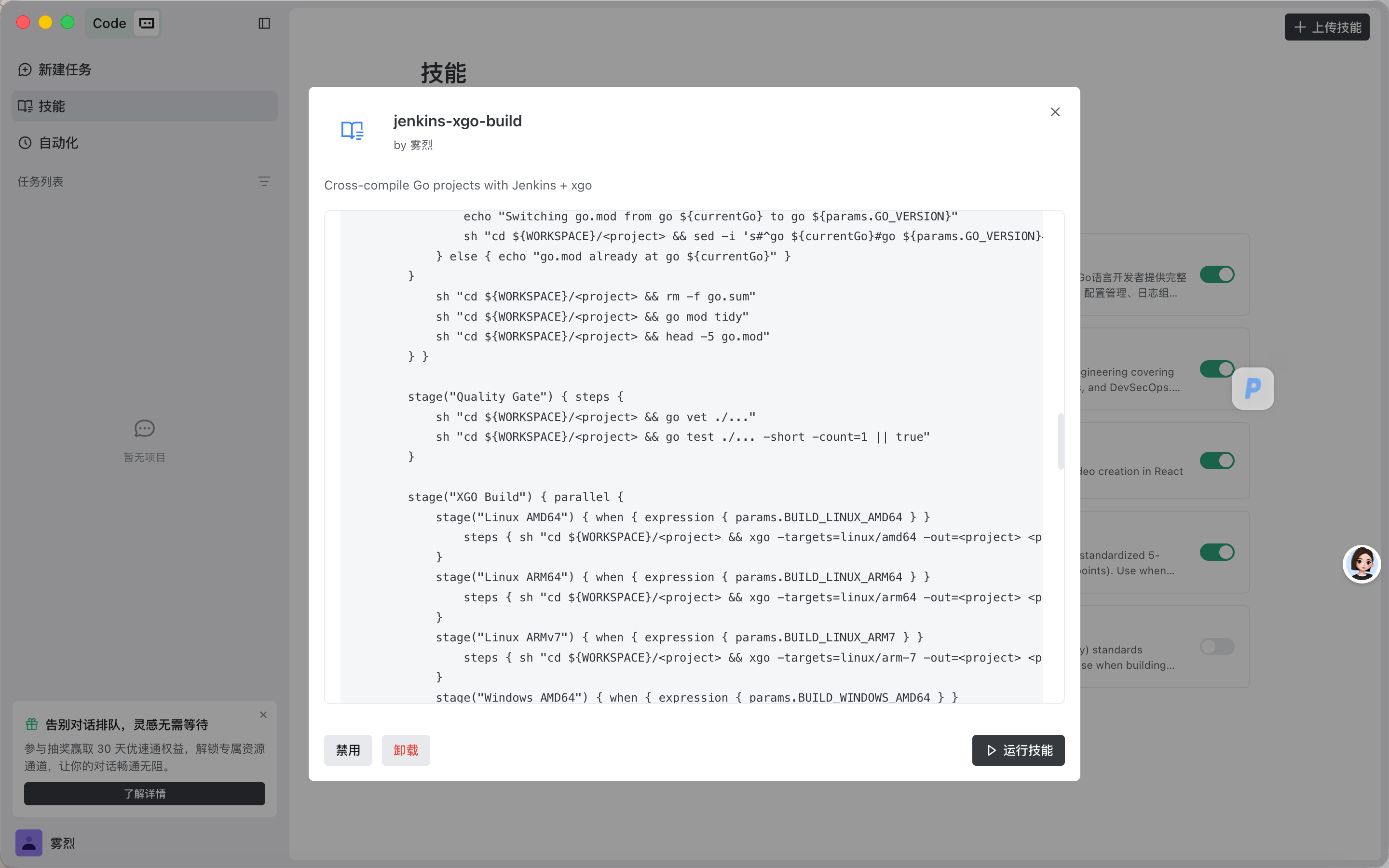
为了演示 skill-review 的实际效果,我准备了一个早期的 jenkins-xgo-build 版本(v3.0.0)。这个版本包含了 8 个典型问题:
| 问题 | 检查项 | 严重度 |
|---|---|---|
Groovy 语法错误:Quality Gate stage 缺闭合 } |
C2 | |
env.LAST_STAGE 在 failure 块引用但从未定义 |
X5 | |
| 0 个 Few-Shot 示例 | F1 | |
| description 只说 “Cross-compile Go projects”,无触发语句 | D1/D2 | |
| 密码硬编码在 Pipeline 中 | 红线 | |
| 无角色定义 | I1 | |
| 无输入/输出契约 | P1/P2 | |
| 634 行,严重臃肿 | B1 |
在 TRAE SOLO 中导入这个版本后,执行审查:

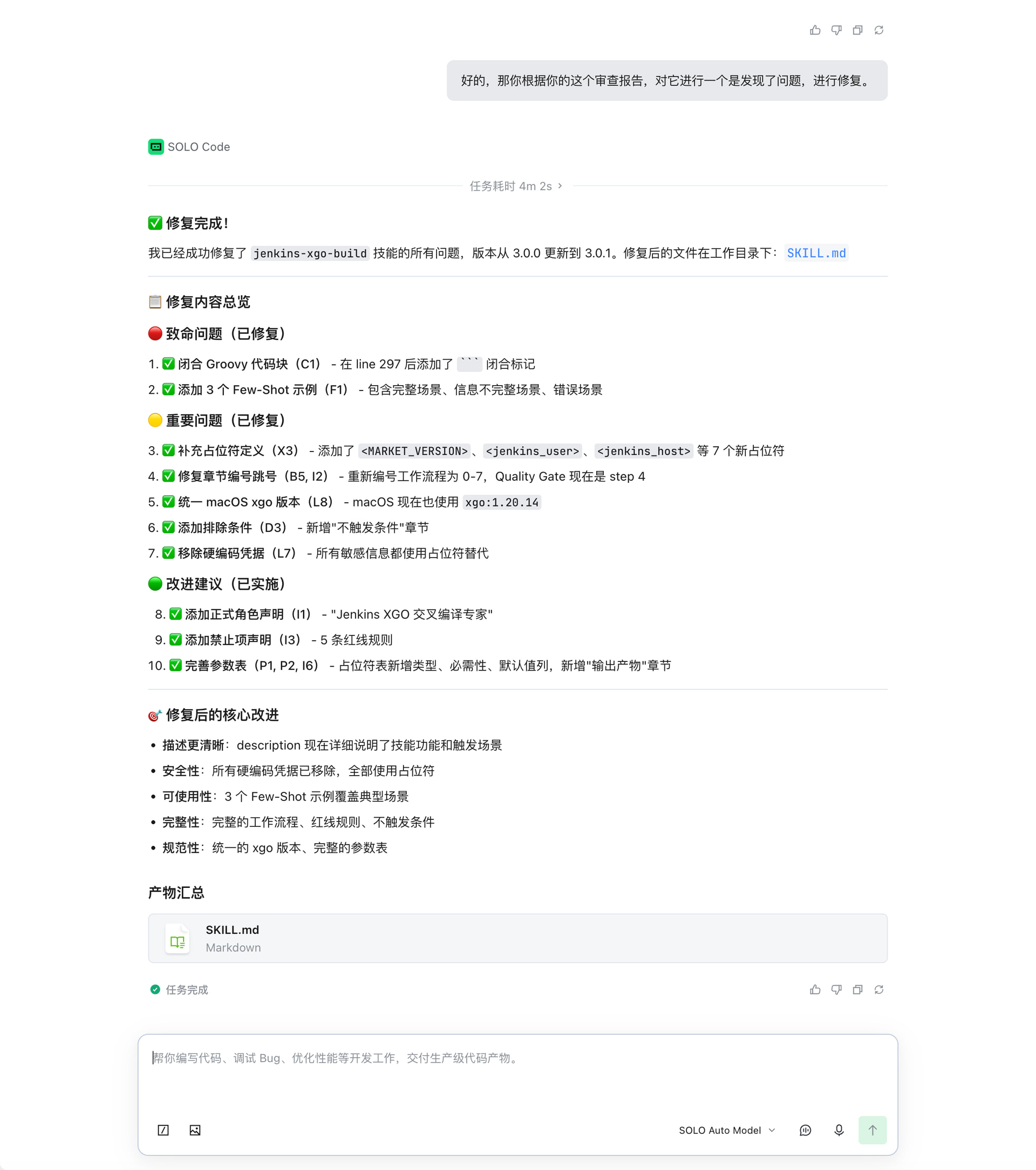
5.2 按审查报告修复
拿到审查报告后,在 TRAE SOLO 中逐项修复:
图 修复过程——按照审查报告逐项修改,Quality Gate 补括号、补 Few-Shot、加角色定义……
修复完成后,再次审查:
可用

5.3 Before / After 对比
不可用,3 个
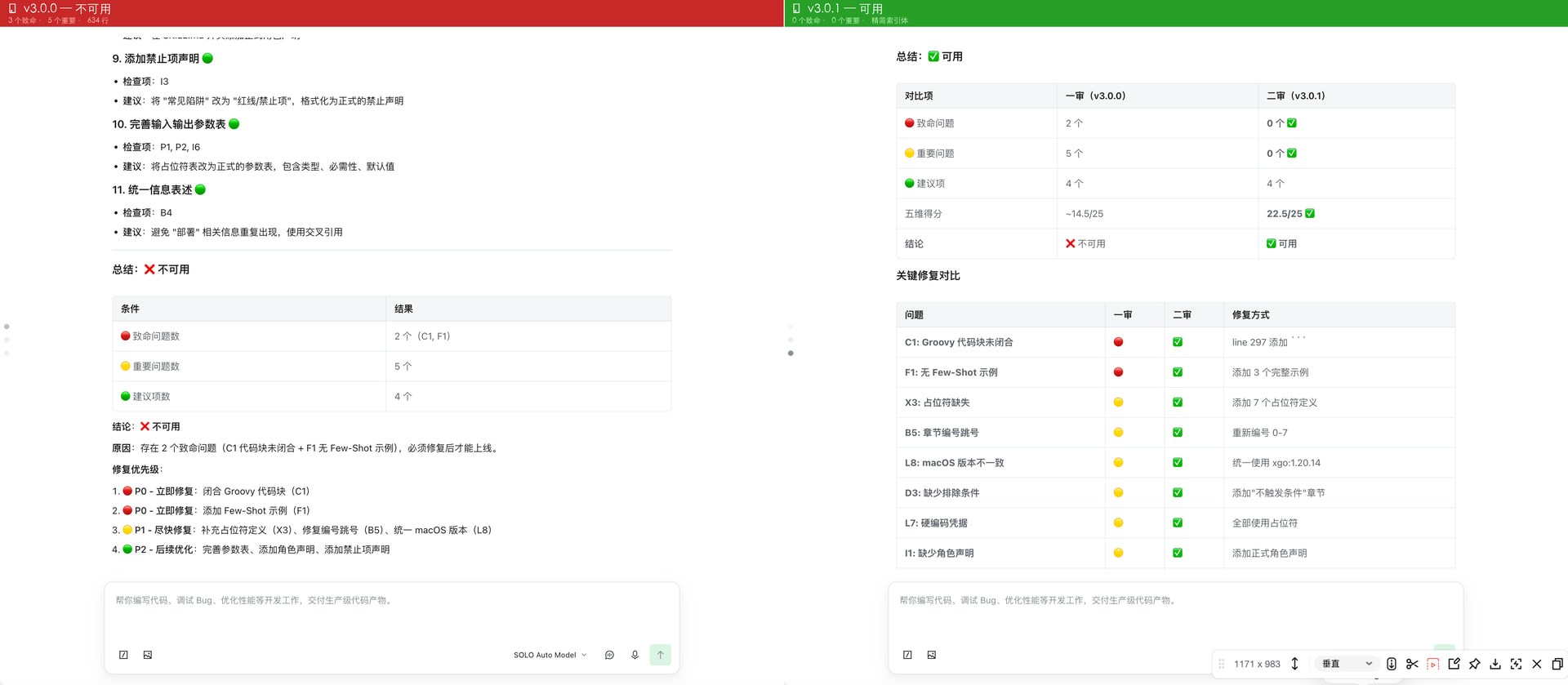
5.4 持续迭代的价值
这个案例并非到此为止。拿到 ![]() 后,我继续用 skill-review 在后续迭代中做质量门禁。从 v3.0.1 一路迭代到 v4.1.0,每一次改动后都跑一次审查,确保新功能不引入新问题。
后,我继续用 skill-review 在后续迭代中做质量门禁。从 v3.0.1 一路迭代到 v4.1.0,每一次改动后都跑一次审查,确保新功能不引入新问题。
最终,jenkins-xgo-build 从最初的 634 行臃肿体,进化到 166 行精炼索引体——不是因为删了功能,而是审查机制持续推动"该提取的提取、该精简的精简"。
六、Skill 链接
GitHub 仓库(含完整 SKILL.md + 审查标准):https://gitee.com/xuhuiwang/skill-review
七、总结与思考
收获
这个技能让我最大的收获不是"又多了一个工具",而是建立了一套技能治理的方法论:
-
审查不是找茬,是防退化——迭代越多越容易引入结构性缺陷,没有审查机制就是蒙眼狂奔
-
方法论需要交叉验证——单个来源的标准可能是片面的,7 个来源的共识才是可靠的底线
-
元技能的价值被严重低估——大多数人忙着写技能解决问题,很少有人写技能来保证其他技能的质量
-
审查应该自动化——如果每次都要手动对比,你就会跳过它;但如果一句话就能完成,你就会养成习惯
最满意的地方
50+ 检查项不是拍脑袋想出来的。每一类都有明确的来源标注和共识度标记(![]() 100% 共识 /
100% 共识 / ![]() 单一来源)。这让审查结论经得起质疑——如果有人问"为什么这个算
单一来源)。这让审查结论经得起质疑——如果有人问"为什么这个算 ![]() ",你可以追溯到这个规则来自 Anthropic 的哪篇文档。
",你可以追溯到这个规则来自 Anthropic 的哪篇文档。
后续优化
-
将审查流程做成 TRAE SOLO 的自动化流水线(类似 CI/CD 中的 quality gate)
-
对社区中热度高的技能做公开审查,输出"技能健康度报告"
-
支持审查结果的历史追踪(一个技能从 v1 到 v10 的质量变化曲线)
希望别人怎么体验
欢迎用 skill-review 审查你自己创建的技能——你可能会惊讶地发现一些"一直没注意到"的问题。也欢迎把它作为测评其他参赛作品的标准维度。
感谢 TRAE 团队的《一文读懂 Skills》,它是这篇作品的第一块多米诺骨牌。