1、Skill 简介
深度分析 GitHub 开源项目的大模型应用实现。当用户提供 GitHub 项目地址并要求拆解、分析、存档时使用此技能。此技能会克隆项目到本地,识别和提取所有提示词(Prompts)与工具(Tools),生成中文翻译文档和完整的项目 AI 应用分析报告。
适合所有需要快速理解一个陌生 AI 开源项目的开发者、研究员和技术管理者。
2、使用场景
我为什么想做它?
最近在研究一些 AI 开源项目的架构,比如 last30days-skill。这个项目有 400+ 个文件,提示词散布在 SKILL.md(1709 行)、Python 代码、YAML 配置里。为了搞清楚它到底怎么用的大模型,我手工做了一遍:
grep搜索关键词 → 找到几十个匹配- 逐个文件阅读 → 理解上下文
- 手动翻译英文提示词 → 记录笔记
- 画流程图 → 梳理数据流
- 整理成文档 → 写分析报告
一个项目花了 2 个多小时。 如果有 5 个项目要研究呢?不敢想。
做出来之后能省掉的动作
| 传统手工流程 | 这个 Skill 自动完成 |
|---|---|
| 手动 grep 搜索关键词 | 4 类方法系统扫描,0 遗漏 |
| 逐文件阅读理解上下文 | 自动追踪导入链和调用链 |
| 手动翻译英文提示词 | 自动翻译 + 保留 JSON/Markdown 格式 |
| 手动画流程图 | 自动生成 Mermaid 彩色时序图 |
| 零散笔记整理 | 一份 7 节结构的完整中文报告 |
一条命令触发,2~5 分钟拿到报告。效率提升 20 倍以上。
3、创作过程
灵感来源
这个 Skill 的创作始于 @comeonzhj 分享的 howPrompt——一个定义如何拆解开源项目、提取提示词的工作流程文档。howPrompt 里面有清晰的方法论(4 类搜索方法、4 阶段工作流),但它是一个「给人看的指南」,每次执行还需要手动操作。
我的想法是:把它变成一个 Skill,让 AI 自动执行这套工作流。
用 SOLO 把想法变成 Skill
核心创作过程分三步:
Step 1 — 用 SOLO 把 howPrompt 转化为 Skill 骨架
我把 howPrompt.md 的工作流提炼为 5 个顺序阶段,在 SOLO 里逐步敲定:
仔细阅读`howPrompt.md`工作流程,开发成一个 Skill。当用户提供一个 GitHub 项目地址,要求拆解并存档时使用这个技能。此技能将帮助 Agent 对项目进行分析拆解,
第一步:下载项目
第二阶段:项目结构探索
第三阶段:提示词识别
第四阶段:文档化
第五阶段:分析报告
确保技能是自包含的。
SOLO 输出了第一版 SKILL.md,包含完整的阶段划分和工具指令。
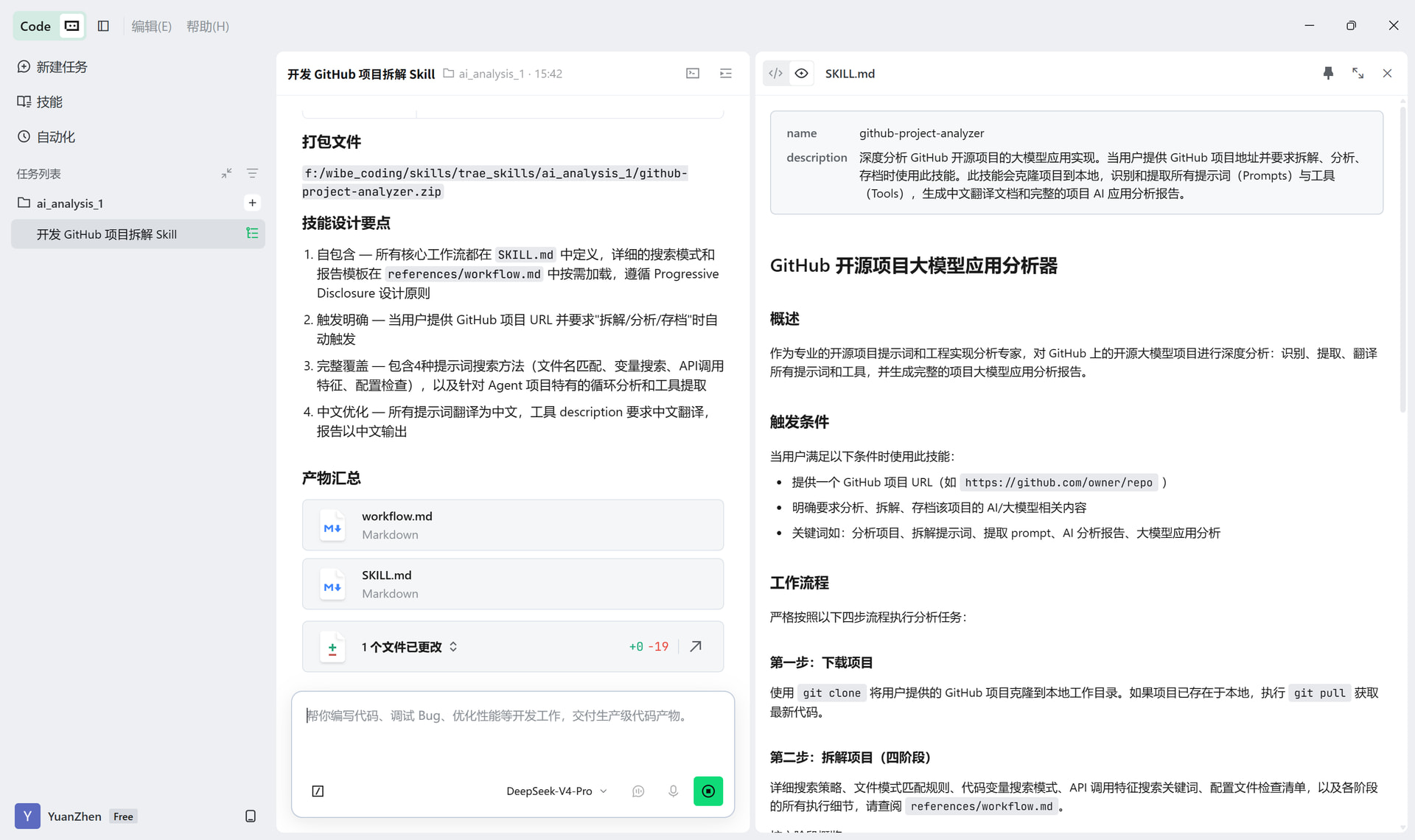
Step 2 — 用真实项目验证和迭代
我直接用 last30days-skill 作为测试目标,在 SOLO 中让 Skill 跑了一趟完整流程。发现初始版本只有 4 个阶段(少了一个「探索结构」阶段),立即修复。同时发现翻译文档缺少「相关代码上下文」字段,也一并补上。

4、使用步骤
安装
将 Skill 安装到本地 Agent Skills 目录即可:
npx skills add Guan-Yep/open-source-llm-analyzer -g
或直接从 GitHub 克隆:
git clone https://github.com/Guan-Yep/open-source-llm-analyzer.git
# 然后移动到你的 skills 目录
触发方式
在 AI 对话框中输入以下任一方式即可触发:
帮我分析一下 https://github.com/xxx/xxx拆解 https://github.com/xxx/xxx 项目的大模型用法提取 https://github.com/xxx/xxx 的所有提示词分析这个项目的 LLM 架构
输出
Skill 会在项目根目录下生成 ai_analysis/ 文件夹:
ai_analysis/
├── translated_prompts/ ← 所有提示词的中文翻译
│ ├── INDEX.md ← 索引表
│ └── xxx_prompt_zh.md ← 每个提示词的翻译文档
└── AI_MODEL_USAGE_ANALYSIS.md ← 综合大模型应用分析报告
5、效果展示
测试案例:分析 last30days-skill
输入:帮我分析一下 https://github.com/mvanhorn/last30days-skill
执行过程:Skill 在后台自动完成 →

git clone到本地- 扫描 400+ 文件,识别 Python 为主语言
- 4 类方法全量扫描,发现 10 个提示词
- 生成 9 个中文翻译文档 + 索引
- 产出完整分析报告
完整输出目录可在 GitHub 查看:ai_analysis/ 目录
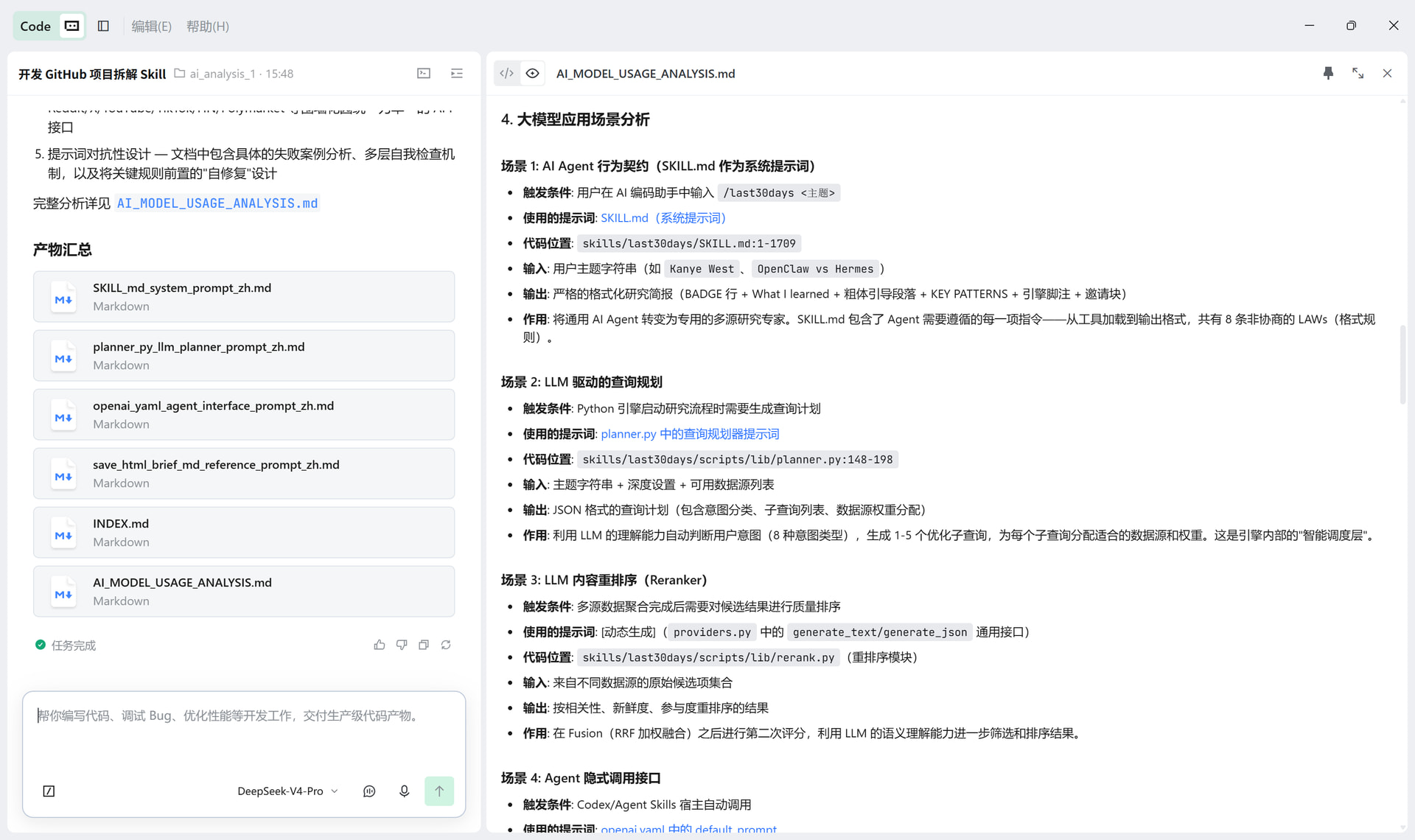
报告核心亮点
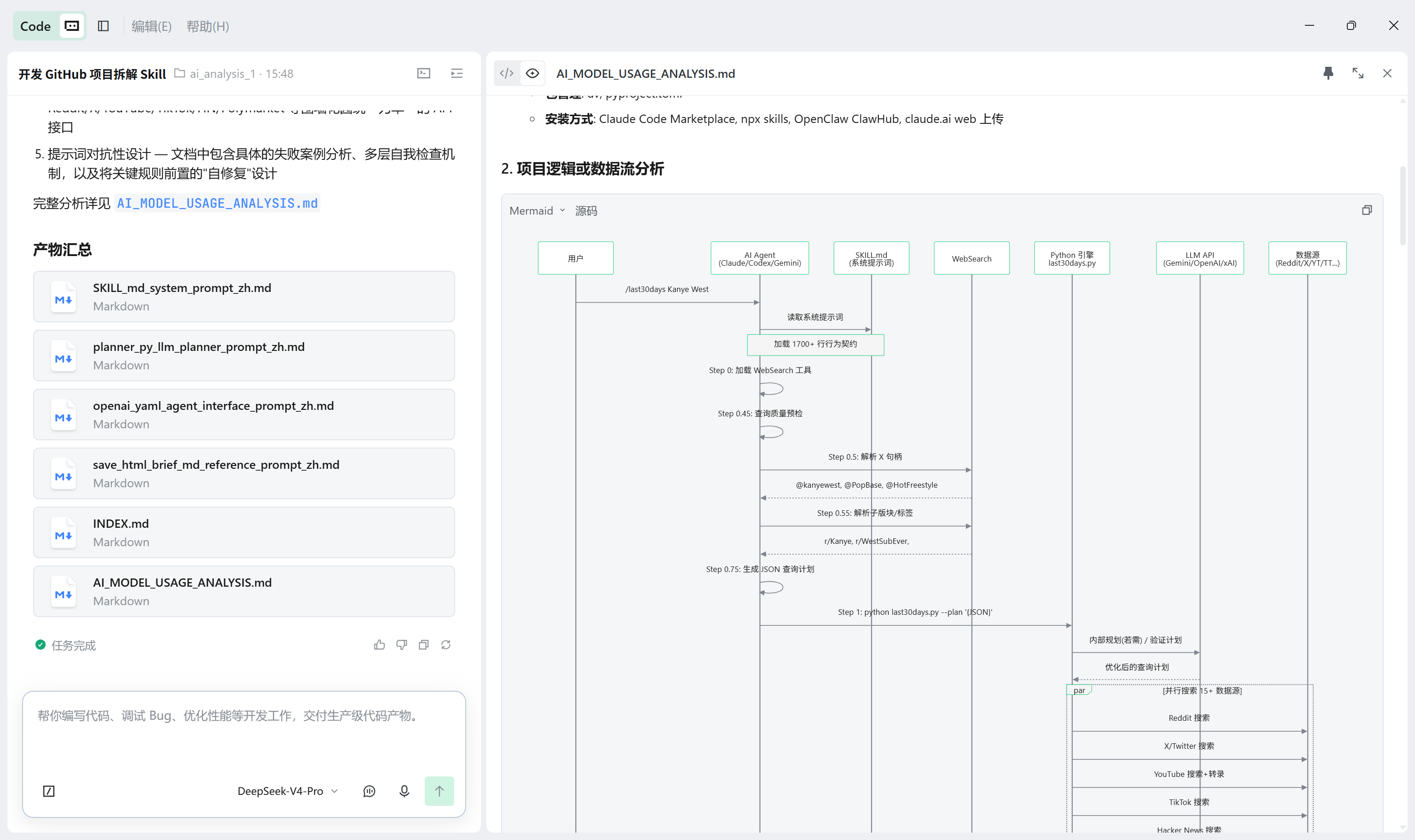
报告 Mermaid 数据流图
提示词分类统计表
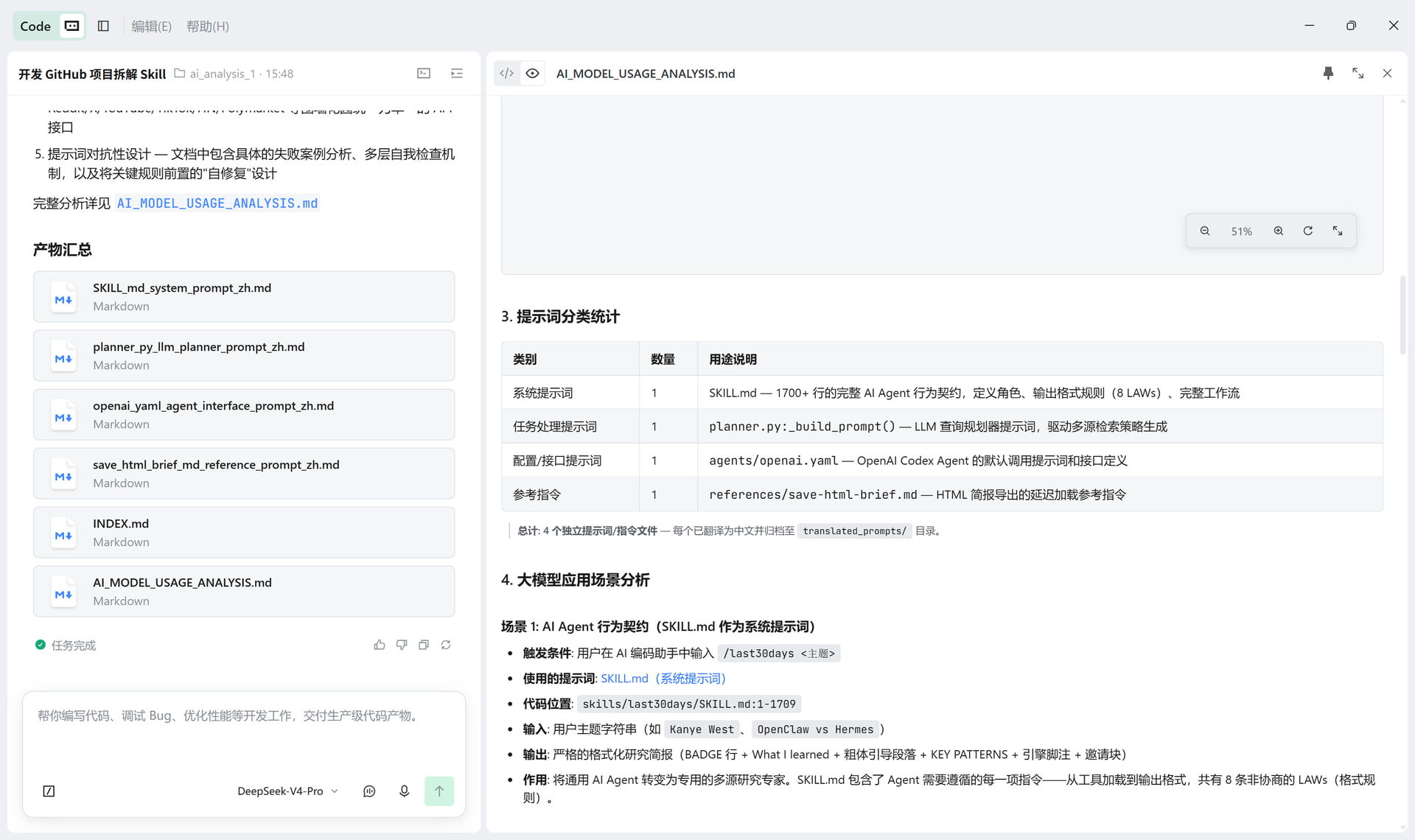
大模型应用场景分析
6、Skill 链接
| 资源 | 链接 |
|---|---|
| https://github.com/Guan-Yep/open-source-llm-analyzer | |
npx skills add Guan-Yep/open-source-llm-analyzer -g |
|
| README.md | |
| MIT License |
7、总结与思考
效率提升
以前分析一个开源 AI 项目的 LLM 用法,手工做需要 2~3 小时。有了这个 Skill,2~5 分钟拿到完整报告。效率不是提升了 50%,是提升了 20 倍以上。而且以前容易遗漏的提示词(尤其是嵌入在代码字符串里的),现在 4 类方法全量覆盖。
对 AI 工作方式的新感悟
做这个 Skill 的过程,让我对 AI 工具的理解有了一些变化:
Skill != 代码片段集合。 一个好的 Skill 不止是指令集合,更像一个「SOP文档」——它定义了该做什么(工作流)、怎么判断(规则)、怎么输出(模板)、边界情况怎么处理(降级策略)。
渐进式披露真的很重要。 刚开始我把所有细节都塞进 SKILL.md。拆成 SKILL.md(核心流程)+ references(详细参考)后,AI 的表现稳定了很多。这让我想到阅读也是类似的——先看概要,再按需深入。
目前最满意的地方
- 4 类搜索方法覆盖全面,从文件名、变量名、API 特征到配置文件,几乎不可能遗漏提示词
- Mermaid 时序图用彩色分区和自动编号,让人一眼看懂 LLM 在项目架构中的位置
- 输出模板化——翻译文档、索引、分析报告都有统一模板,不同项目之间可对比
后续优化方向
- 增加增量分析模式:现在每次都是全量扫描,对于频繁更新的项目,支持只分析 diff 部分
- 支持更多报告语言:目前只用中文输出,后续支持英文报告
希望得到的反馈
- 报告的结构和内容密度是否合适?太详细还是不够?
- 有没有你觉得「如果能支持这个就更好了」的功能?
本项目基于 @comeonzhj 的 howPrompt 改造而来,感谢他提供的初始工作流灵感。