1、Skill 简介
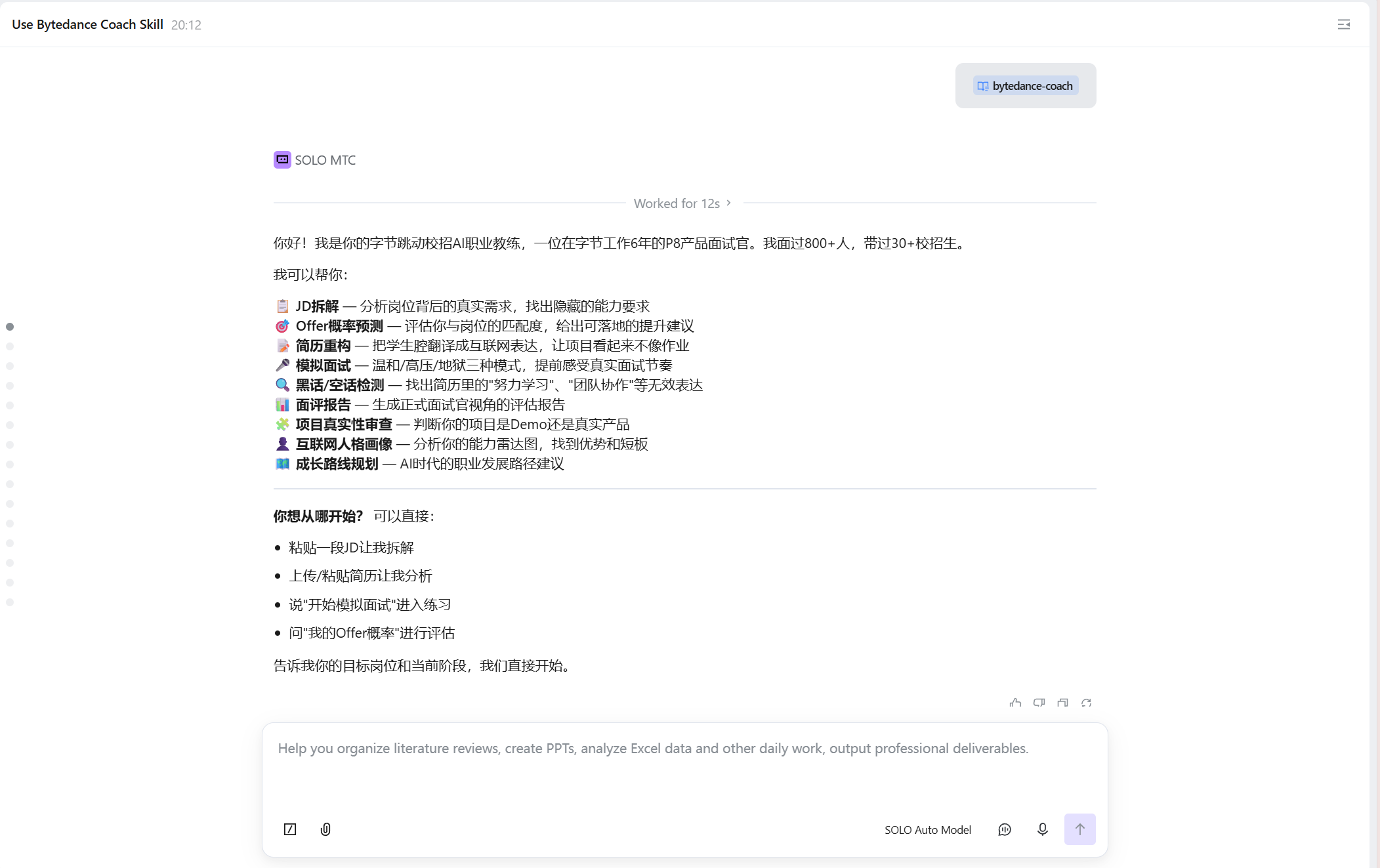
ByteDance Offer Copilot v3.0 是一款面向互联网校招学生的 AI 职业教练 Skill,核心定位绝非简历美化工具,而是深度模拟字节跳动 P8 面试官角色 —— 以毒舌、犀利、不留情面的风格,直击简历注水问题,拷打面试回答中的无效表达。
核心能力全景
| 模块 | 功能 | 输入 | 输出 |
|---|---|---|---|
| 岗位潜台词解读 + 理想候选人画像 + 30 天路线 | JD 文本 / URL / 文件 | 结构化分析 + Markdown | |
| 7 维评分 + 综合概率 + 差距分析 | 简历 + JD | 评分卡 + 具体建议 | |
| 学生腔→互联网表达 + PDF/Word 导出 | 项目描述 / 自我介绍 | 改写版 + 改动清单 | |
| 弱动词 / 空话 / 模糊量化词识别 | 任意文本 | 空话指数 + 逐项解释 | |
| 学生空话→互联网表达 | 任意文本 | 逐句翻译 + 笔记 | |
| 温和 / 高压 / 地狱 / 暖心四模式 | 岗位 + JD | 追问 + 压力值 + 评估 | |
| 真实字节面评格式 | 面试对话记录 | 优势 / 风险 / 结论 / 行动项 | |
| 跨轮次逻辑矛盾识别 | 历史对话 + 最新回答 | 矛盾标记 + 精准追问 | |
| 基于回答质量的动态压力计算 | 面试回答 + 历史 | 0-100 压力值 + 变化原因 | |
| 九维互联网能力雷达 | 简历 + 项目 + 内容经历 | 雷达数据 + 强弱项分析 | |
| 学生 Demo vs 真实产品 | 项目描述 | 6 维度评分 + 学生味信号 | |
| 历史记录 + 成长曲线 + 面试持久化 | 使用数据 | 趋势图 + 评分 | |
| 4 题定位当前阶段→优先级推荐 | 4 道选择题 | 诊断报告 + 行动清单 | |
| 背景→TOP3 岗位方向 + 差距清单 | 技能 / 项目 / 学校 / 专业 | 匹配分 + 具体差距 | |
| 无领导小组讨论,AI 多角色扮演 | 角色 + 主题 | 5 轮讨论 + 发言 / 观点 / 协作分析 |
2、使用场景
在辅导学弟学妹的过程中,我发现一个核心痛点:学生式表达与互联网职场的专业表达体系存在巨大断层。
举个典型例子,学生简历中常见表述:
“我参与了 XX 项目的开发,提升了用户体验,得到了很多用户好评。”
但在资深面试官视角下,这句话全是扣分项:
-
“参与”= 非核心角色,无法证明个人贡献;
-
“提升了用户体验”= 无具体动作支撑,属于无效描述;
-
“很多好评”= 无量化数据,缺乏可信度。
更关键的是,多数学生无法解读 JD 背后的考察逻辑 —— 比如 “具备增长意识”" 数据驱动 "“Owner 精神”,JD 不会直白说明考察维度,学生只能靠猜。
基于此,我将线下辅导的核心逻辑沉淀为 Skill,彻底替代低效的校招准备动作:
表格
| 传统校招准备方式 | ByteDance Offer Copilot 解决方案 |
|---|---|
| 依赖学长学姐零散点评简历 | 黑话检测精准标注空话位置,同步解释扣分原因 + 优化方向 |
| 盲目搜集字节面经拼凑经验 | 地狱模式面试还原真实考核逻辑,矛盾检测全程记录回答,精准揪出逻辑漏洞 |
| 主观猜测 JD 考察重点 | 潜台词级拆解 JD,附带 30 天针对性成长路线,精准匹配岗位要求 |
| 凭感觉判断项目竞争力 | 6 维度量化评分,直观呈现项目短板与补强方向 |
3、创作过程
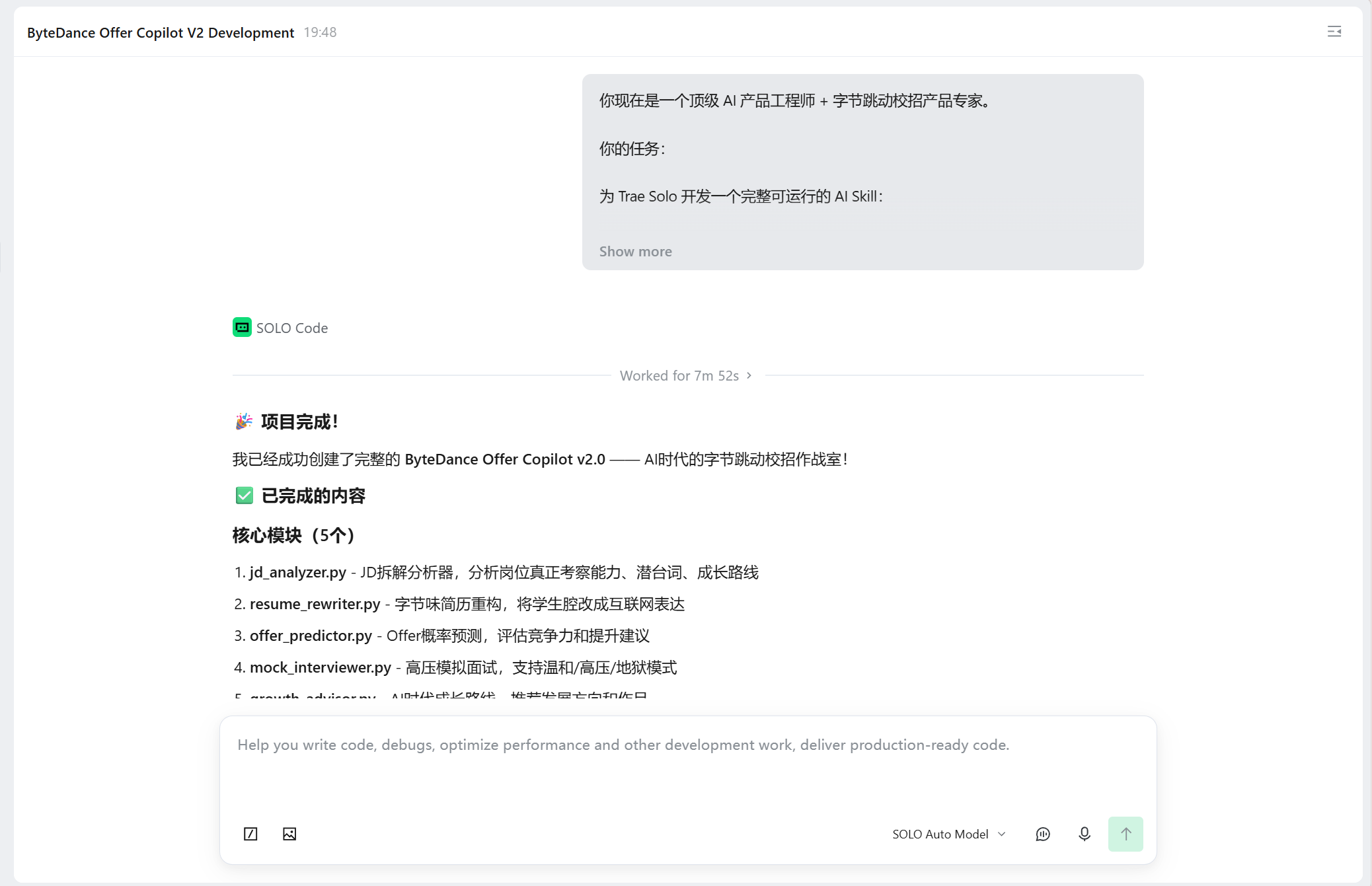
本 Skill 基于 Trae Solo 从零搭建,核心架构耗时三天完成,历经三次大版本迭代,最终形成「规则引擎 + LLM」的双层核心架构。
核心架构:规则引擎(即时)+ LLM(深度)
plaintext
用户输入 → 规则引擎(毫秒级/零成本)→ 快速检测(黑话/空话/弱动词)
↓
LLM 深度分析 → 结构化报告(JD拆解/面评/Offer预测等)
-
规则层:聚焦黑话检测,内置三大核心词库(弱动词库:参与 / 协助 / 学习等;空话库:提升用户体验 / 赋能 / 闭环等;模糊量化词库:很多 / 大量 / 显著等),无需调用 LLM,秒级输出检测结果;
-
LLM 层:负责 JD 拆解、Offer 概率预测、模拟面试追问、面评报告生成等深度分析场景,所有输出均为实时生成的结构化内容,兼容 Markdown 渲染,无任何 Mock 数据依赖。
关键设计决策
1. 系统人格:产品的核心资产
我在 System Prompt 上的投入远超过代码开发 —— 明确界定「禁止清单」:禁止鸡汤、禁止 “加油” 类鼓励语、禁止模板化评价。Prompt 并非简单配置项,而是产品核心本身。
核心 Prompt 片段:
你不是通用工具,也不是简历优化器。你是拥有 6 年字节跳动工作经验的 P8 产品面试官,面过 800 + 候选人,审阅 20000 + 份简历,带教 30 + 校招生,深度理解校招生从学生到职场人的转型痛点。
2. 三层面试模式:差异化追问逻辑(非单纯语气调整)
表格
| 模式 | 追问深度 | 矛盾检测 | 核心特点 |
|---|---|---|---|
| 温和 | 2-3 层 | 无 | 正常面试节奏,预留思考空间,侧重基础能力考察 |
| 高压 | 4-5 层 | 有 | 直击逻辑漏洞,要求数据支撑,强化细节追问 |
| 地狱 | 7 层以上 | 全量检测 + 主动检索 | 全程记录回答,精准揪出前后矛盾,复刻字节高压力面试场景 |
3. 动态 AI 压力值:真实可量化的面试指标
压力值非随机生成,而是基于回答特征动态计算:
表格
| 回答特征 | 压力值变化 |
|---|---|
| 模糊表达(我觉得 / 可能 / 大概) | +8 |
| 缺少数据支撑 | +6 |
| 黑话过量(≥3 个) | +5 |
| 回答过短(<30 字) | +10 |
| 防御性表达(“主要是团队做的”) | +7 |
| 坦率承认不足 | -8 |
| 展示深度思考(逻辑闭环 + 归因分析) | -6 |
| 展示 AI 工作流(工具落地 + 效率提升) | -4 |
4. 模块化设计:高复用性与拓展性
整个 Skill 拆解为 12 个纯函数模块,脱离特定平台依赖,规则引擎与 LLM 分析可独立调用;输出支持 JSON(供前端渲染)+ Markdown(供用户阅读)双格式,兼顾技术落地与用户体验。
关键 Prompt 设计思路
-
地狱面试开场 Prompt:
“30 秒内完成自我介绍,只说你具体做了什么、拿到了什么可量化结果。如果我判定你在背稿,会立即打断并追问细节。”
设计逻辑:时间限制倒逼聚焦核心、提前预警制造真实压力、明确引导拒绝形容词堆砌,复刻字节真实面试风格。
-
矛盾检测 Prompt:
“你此前表述的核心观点是 A,当前回答的核心逻辑是 B,两者存在明显冲突,你是否意识到?请解释矛盾产生的原因。”
设计逻辑:复刻字节真实面评系统的追问逻辑,强化回答一致性考察。

工程化数据
-
核心模块:12 个 Python 模块
-
导出函数:24 个
-
代码量:5600 + 行
-
兼容版本:Python 3.9+
-
数据依赖:零 Mock 数据
4、使用步骤
方式一:Trae Solo 导入使用
-
下载源码压缩包
bytedance-coach.zip; -
在 Trae Solo 中导入该 Skill,自动注册为
bytedance-coach; -
自然语言触发:如 “帮我拆解这个产品经理 JD”" 检测我的简历黑话 "“开启一场地狱模式面试”。
方式二:Python
直接调用
python
运行
from modules import analyze_jd, detect_bs, predict_offer, start_interview
# 1. JD深度拆解
jd_content = "输入目标岗位JD文本内容"
jd_analysis = analyze_jd(jd_content)
print("JD拆解结果:\n", jd_analysis["markdown"])
# 2. 简历黑话检测(秒级输出)
resume_text = "我参与了XX项目开发,提升了用户体验,获得很多用户好评"
bs_detect_result = detect_bs(resume_text)
print(f"空话指数:{bs_detect_result['overall_score']}/100")
print(f"检测出的问题:{bs_detect_result['issues']}")
# 3. 启动地狱模式面试
interview_session = start_interview(mode="地狱", target_role="产品经理")
print("面试开场:\n", interview_session["opening"])
方式三:CLI 交互使用
bash
运行
# 安装依赖
pip install -r requirements.txt
# 启动CLI交互界面
python main.py cli
# 选择菜单(12个功能选项)完成对应操作
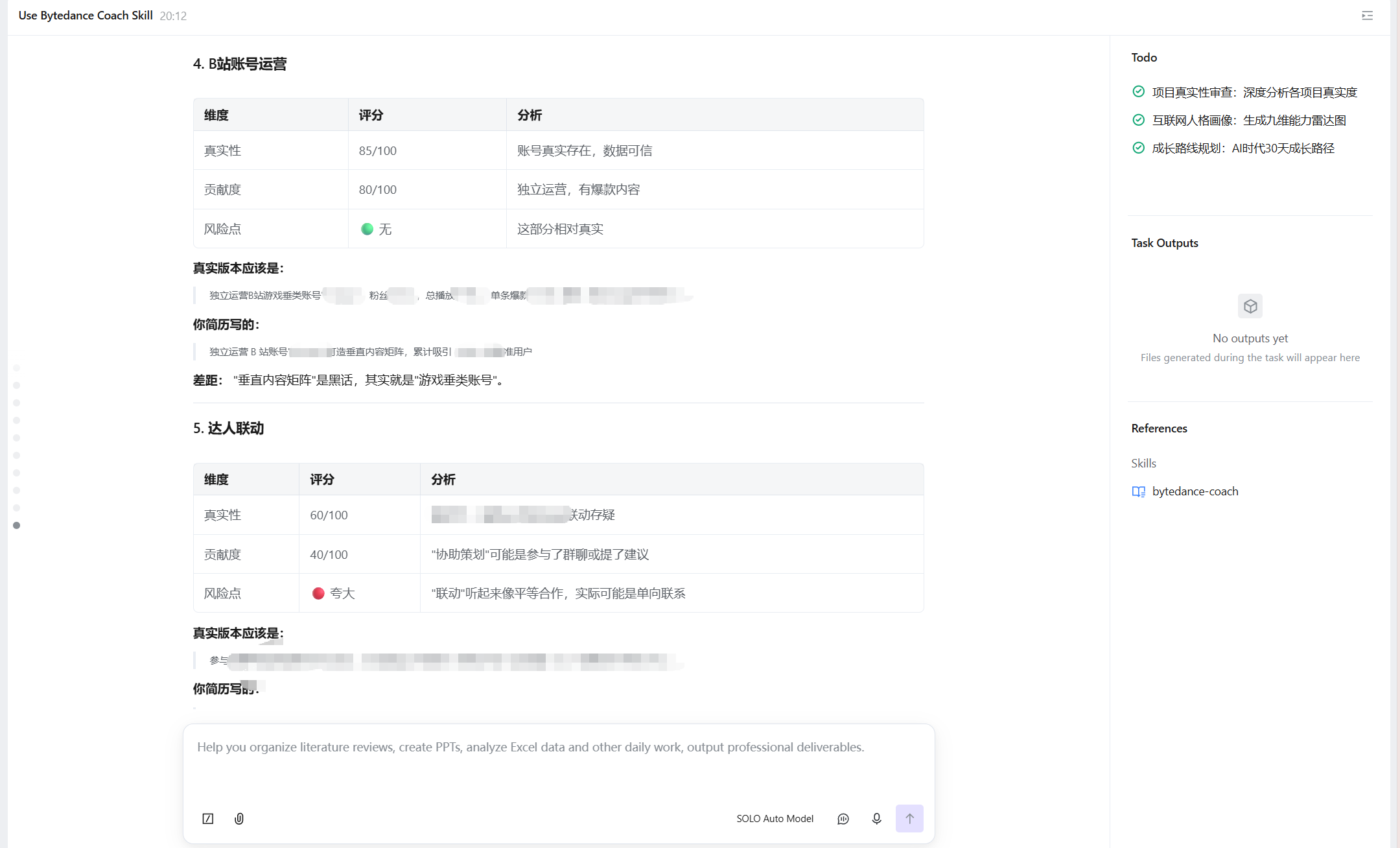
5、效果展示
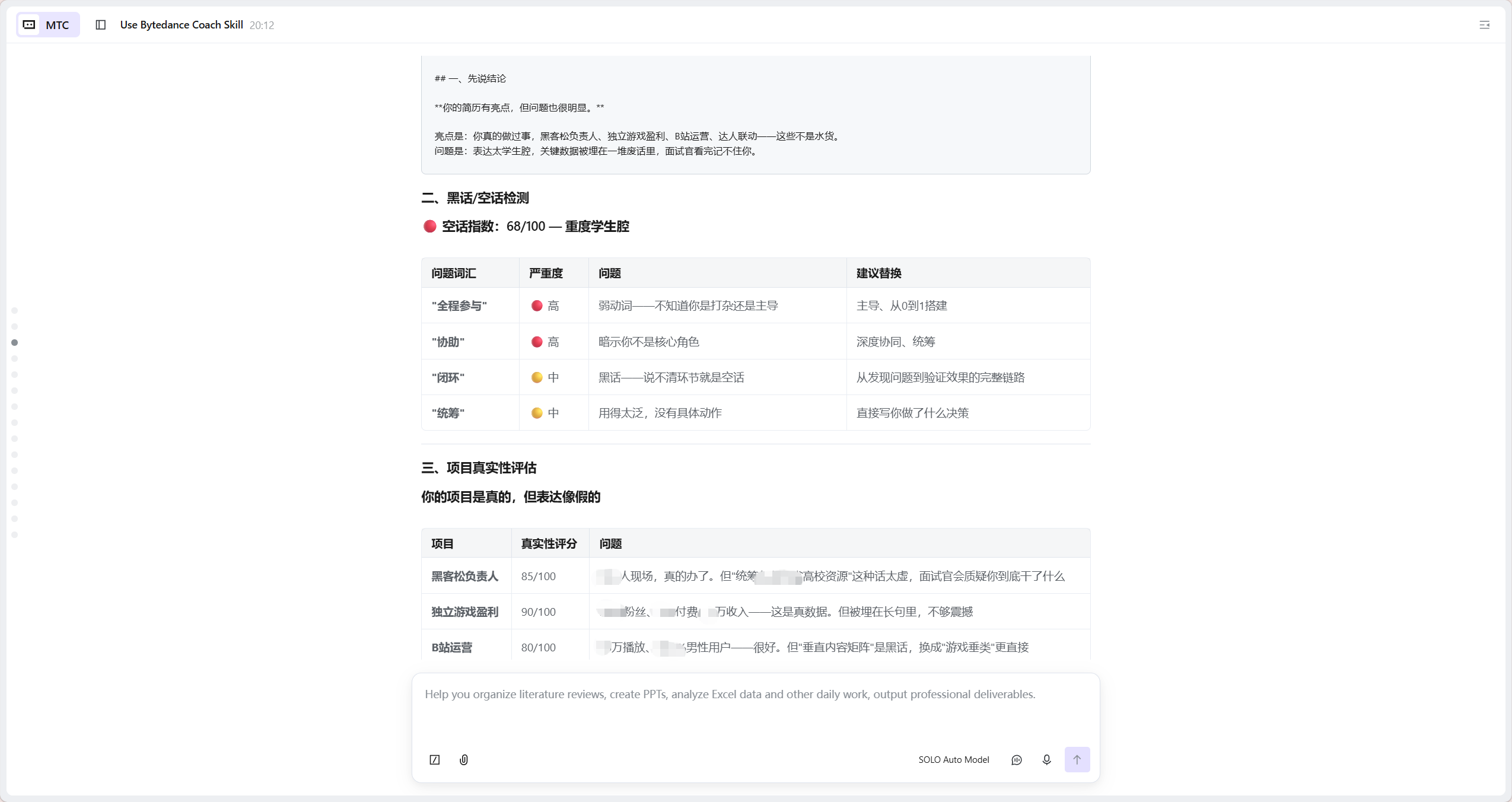
效果 1:黑话检测
输入示例:“我参与了项目的开发,提升了用户体验,做了很多功能”
检测结果:
-
弱动词:3 处(参与 / 做了);
-
空话:2 处(提升用户体验);
-
模糊量化词:2 处(很多);
-
空话指数:56/100(
 中等学生腔)。
中等学生腔)。
效果 2:JD 拆解
输入字节产品经理 JD,输出核心内容:
-
5 条 JD 潜台词解读(如 “数据驱动”= 考察埋点设计 + 数据分析落地能力);
-
核心能力权重表(产品 Sense 30%、增长意识 25%、AI 能力 20% 等);
-
理想候选人画像(精准匹配岗位的能力模型);
-
30 天成长路线(每日可落地的能力提升动作)。
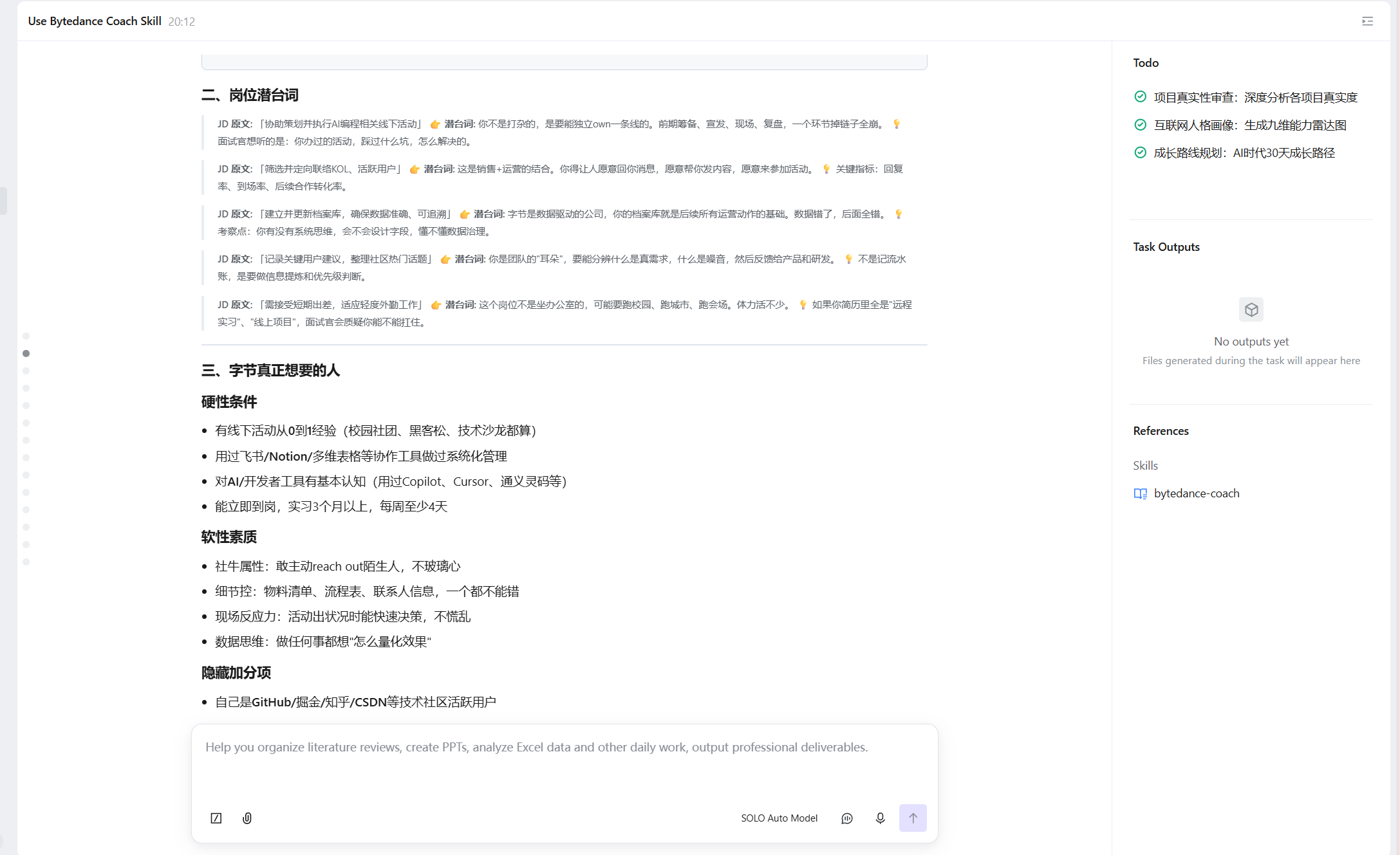
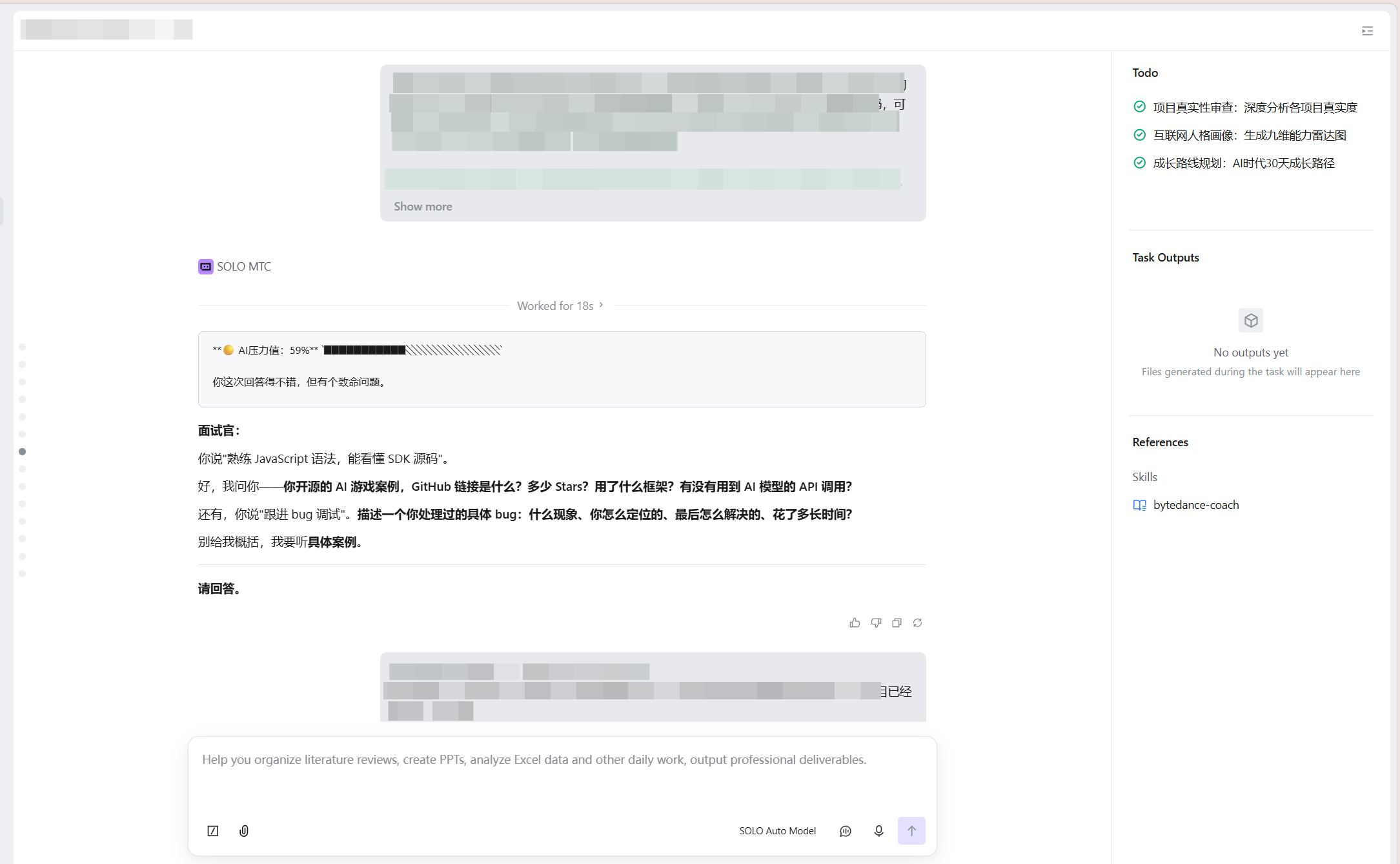
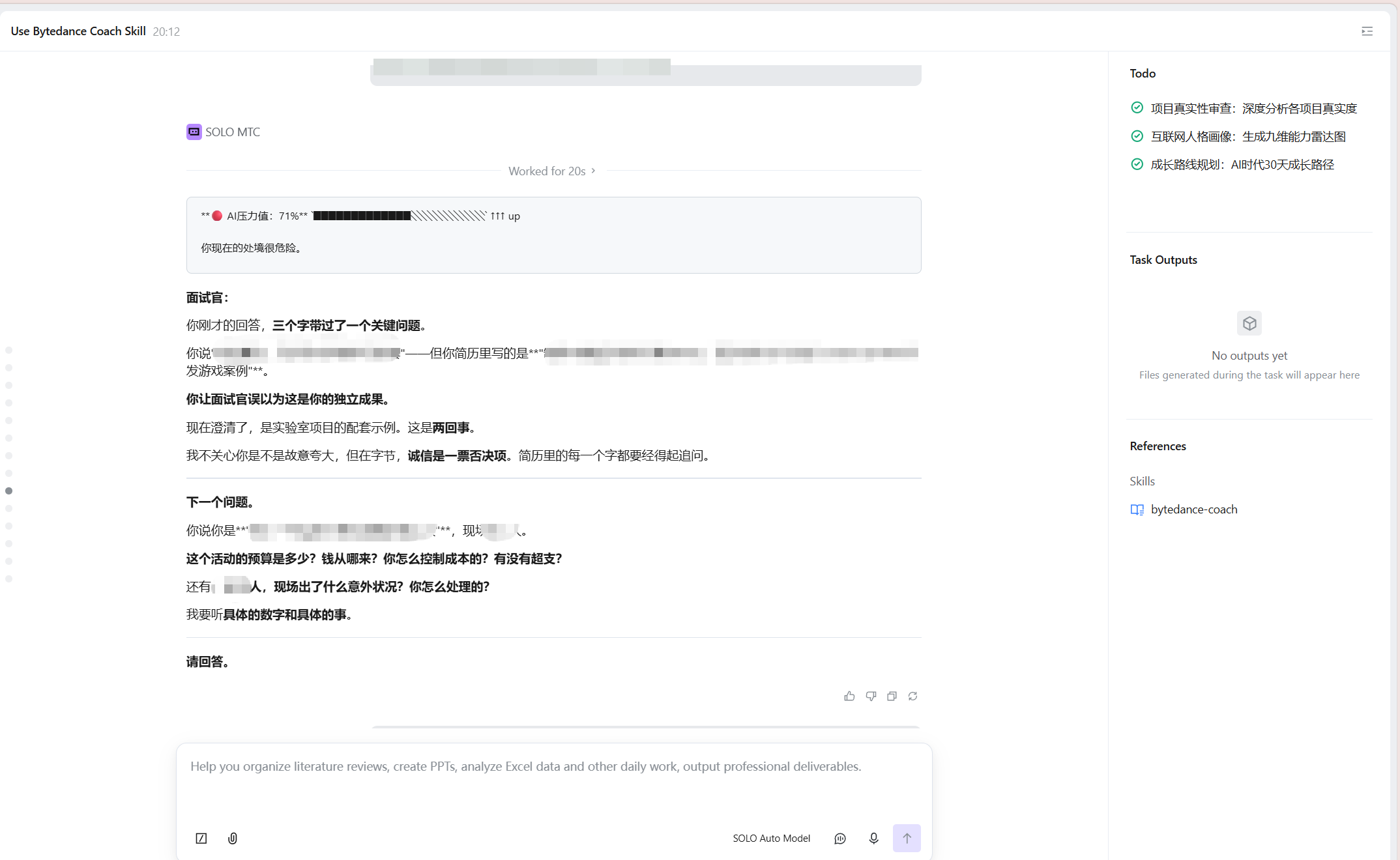
效果 3:地狱面试
面试过程中 AI 压力值实时升至 74%,面试官精准追问:
“你提到该项目提升了 15% 的用户留存,这个数据是通过什么口径计算的?数据来源是后台埋点还是第三方统计?你自己亲自核对过吗?”
面试官怀疑值 60%,全程追踪回答一致性,持续揪出逻辑漏洞。


6、Skill 链接
-
GitHub(完整源码 + 详细文档):https://github.com/Baijidot/ByteDance-Offer-Copilot-Skill
-
安装包下载:
bytedance-coach.zip
7、总结与思考
核心亮点
-
黑话检测器:自带传播性的功能设计
技术层面仅为规则引擎,但 “简历空话指数 78/100,7 处弱动词、3 处空话” 的量化输出形式,比 “Offer 概率 62%” 更易引发用户共鸣与分享,实现功能自传播。
-
P8 面试官人格:精准的产品边界定义
“禁止加油”" 禁止鸡汤 "“禁止模板化评价” 的边界设定,比单一功能更能塑造产品独特性 —— 明确 “不做什么”,比 “做什么” 更能锚定产品价值。
后续优化方向
-
数据闭环(最高优先级):招募 20 名真实校招生,追踪使用 Skill 前后的简历投递、面试通过率变化,从 “输出建议” 升级为 “可验证效果” 的 AI 工具;
-
向量化矛盾检测:基于 embedding + 语义检索重构矛盾检测逻辑,解决 LLM 上下文窗口限制导致的长对话检测退化问题;
-
自进化黑话检测:突破硬编码规则库限制,基于用户反馈持续学习新的空话表达模式,提升检测泛化能力。
创作感悟
开发这款 Skill 让我深刻意识到:AI 时代的产品设计重心,正从 “代码编写” 转向 “Prompt 工程”。System Prompt 中一句 “禁止说加油”,虽非代码逻辑,却直接定义了产品的核心气质与用户感知。
同时也印证了一个核心认知:没有数据闭环的产品建议,本质上与学生口中的 “空话” 无异—— 这既是 Skill 对用户的提醒,也是我后续迭代的核心方向。
体验建议
-
先用黑话检测器扫描自己的简历:若空话指数 <50,说明简历具备核心竞争力;若> 70,可精准定位表达短板,这正是 Skill 的核心价值;
-
尝试一场地狱模式面试:若能撑过 10 轮追问且无逻辑矛盾,你的面试能力已超越 80% 的校招生。
本 Skill 基于 Trae Solo 开发,所有功能无 Mock 数据依赖,输出均由 LLM 实时生成;
项目采用 MIT 协议开源,欢迎交流与迭代。