Skill 创作】我做了一个从 Claude Code 源码提炼系统提示词架构的 Skill,帮你给任何 AI 编程助手构建工业级提示词
1、Skill 简介
这是一个从 Claude Code CLI 真实源码中逆向提取、去品牌化、模块化的系统提示词架构模板——claude-code-prompt-arch。它把 Claude Code 那套经过数百万用户验证的提示词工程实践,拆成了 11 个独立模块 + 16 个占位符变量,让你可以像搭积木一样,为 Open Code、Cursor、Continue 等任何 AI 编程助手组装出工业级的系统提示词。
适合谁用:想给自己搭建 AI 编程助手的人、想优化现有提示词的开发者、对提示词工程感兴趣想学习最佳实践的人。
2、使用场景
为什么想做它?
起因很简单——我在用各种 AI 编程助手(Claude Code、Open Code、Cursor)的时候,发现它们的系统提示词质量参差不齐。有的助手会过度工程,改一行 bug 给你重构整个文件;有的缺乏安全意识,rm -rf 说执行就执行;有的废话连篇,一个简单问题回你三段散文。
我当时就想:Claude Code 的体验为什么这么好?它的提示词到底写了什么?能不能把这套东西提炼出来,用在别的平台上?
之前遇到了什么麻烦?
-
想给 Open Code 写系统提示词,但不知道该写什么、写到什么程度、按什么顺序组织
-
网上搜"系统提示词最佳实践",大多是泛泛而谈的原则,没有经过大规模验证的具体模板
-
不同平台的工具名不一样(Claude 叫
Read,Open Code 叫read_file),手动改容易遗漏
做出来之后能省掉什么?
-
不用从零设计提示词架构——5 层组装管线已经帮你规划好了
-
不用纠结写什么——11 个模块按需选取,场景矩阵告诉你哪些必选、哪些可选
-
不用逐个改工具名——16 个占位符一键替换,适配任何平台
-
不用踩缓存坑——静态/动态分离的缓存策略,直接帮你省 60-70% 的 token 成本
3、创作过程
整个过程分三步:
第一步:源码逆向提取
从 Claude Code 的 sourcemap 中还原出源码,定位到系统提示词相关的核心文件:
-
src/constants/prompts.ts— 主组装函数getSystemPrompt(),所有静态段和动态段的定义 -
src/constants/system.ts— 身份前缀定义 -
src/constants/systemPromptSections.ts— 缓存机制实现 -
src/constants/cyberRiskInstruction.ts— 安全指令 -
src/constants/outputStyles.ts— 输出风格配置 -
src/utils/api.ts—buildSystemPromptBlocks、splitSysPromptPrefix缓存块拆分逻辑 -
src/utils/attachments.ts— 附件系统getAttachments() -
20+ 个工具 prompt 文件
关键发现:Claude Code 的提示词不是一段大文本,而是一个5 层组装管线——身份前缀 → 核心系统提示词 → 工具描述 → 附件注入 → 最终组装。其中核心系统提示词又分为静态区(可跨用户缓存)和动态区(每轮可能变化),中间用一个特殊标记 SYSTEM_PROMPT_DYNAMIC_BOUNDARY 分隔。
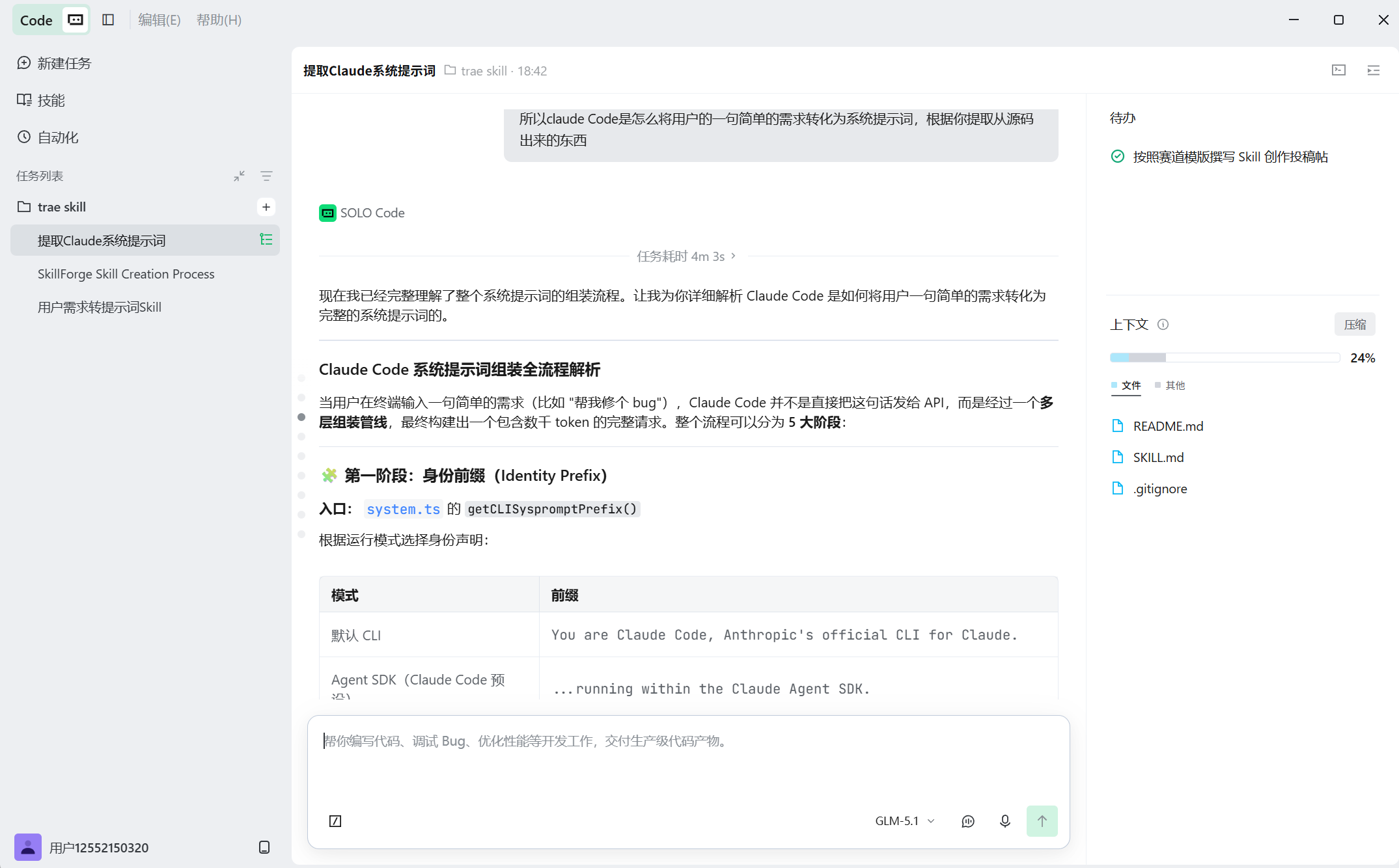
第二步:去品牌化 + 参数化
把所有 Claude 特有的内容替换为占位符变量:
-
Claude→{AGENT_NAME} -
Anthropic→{ORG} -
Read→{READ_TOOL} -
Edit→{EDIT_TOOL} -
…
一共提炼出 16 个占位符,覆盖身份、工具、配置三类参数。
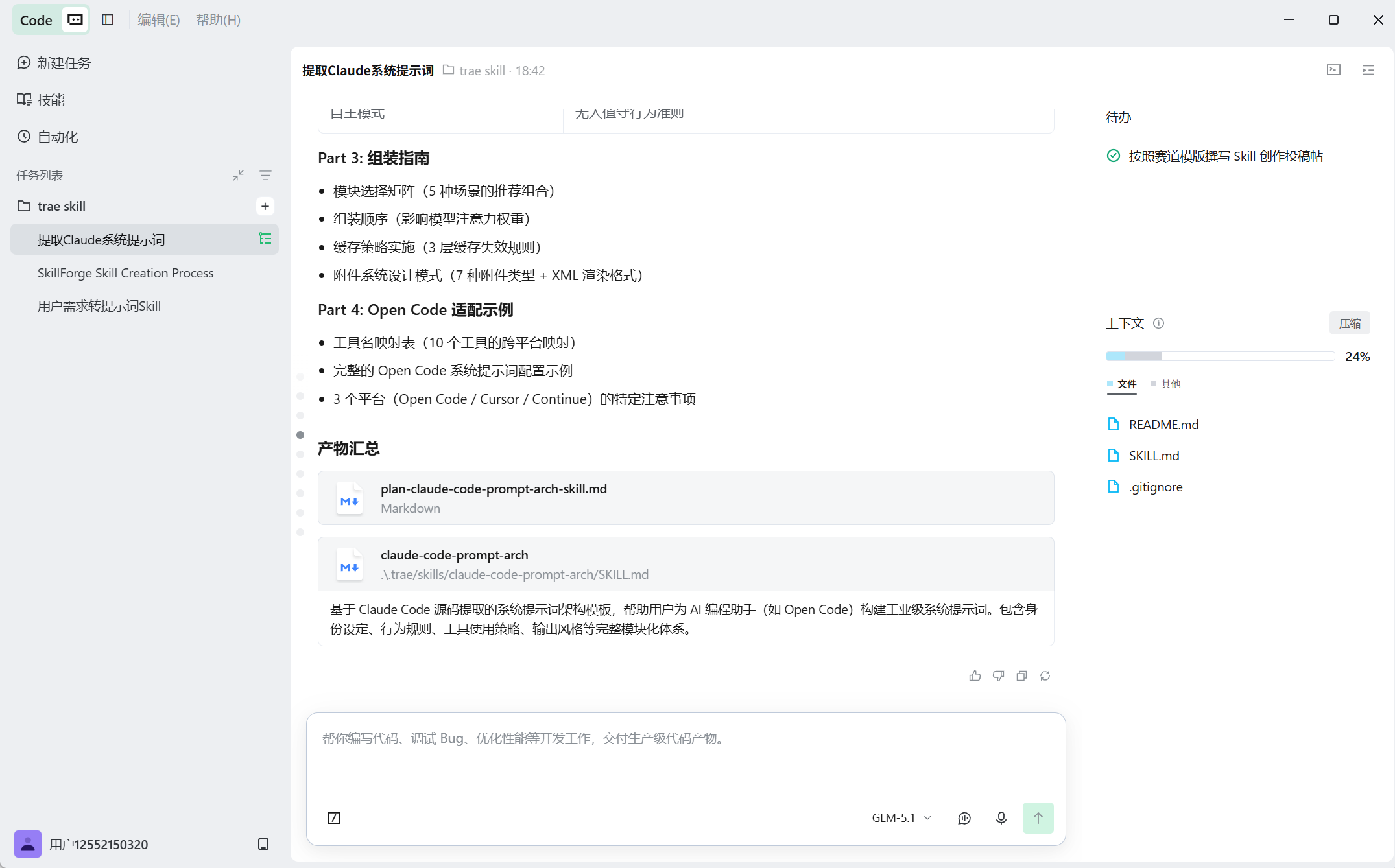
第三步:模块化拆分 + 组装指南
把一整段提示词拆成 11 个独立模块,每个模块包含:
-
设计意图(为什么需要这个模块)
-
通用模板(可直接使用的提示词文本)
-
适配指南(在不同平台上需要注意什么)
然后写了组装指南:模块选择矩阵(5 种场景)、组装顺序(顺序影响模型注意力权重)、缓存策略实施步骤、附件系统设计模式。
4、使用步骤
方式一:在 Trae 中直接使用
-
将
.trae/skills/claude-code-prompt-arch/目录放入你的 Trae 项目 -
在对话中提及"系统提示词"或"提示词架构"即可激活 Skill
-
Skill 会引导你:选择场景 → 选取模块 → 替换占位符 → 输出完整提示词
方式二:手动使用模板
-
打开 SKILL.md,根据你的场景从模块选择矩阵中选取模块组合
-
将模板中的 16 个占位符替换为你的平台实际值(如
{READ_TOOL}→read_file) -
按编号顺序拼接模块,在模块 8 和模块 9 之间插入缓存边界
-
将组装好的提示词配置到你的 AI 编程助手中
5、效果展示
组装前(自己写的提示词):
Plain Text
你是一个AI编程助手。请帮助用户完成编程任务。
模型行为:过度工程、随意执行危险命令、输出冗长、不读文件就改代码…
组装后(使用本 Skill 模板):
Plain Text
You are Open Code, an AI-powered CLI coding assistant.
IMPORTANT: Assist with authorized security testing...
# System
- Tools are executed in a user-selected permission mode...
- The system will automatically compress prior messages...
# Doing tasks
- Do not propose changes to code you haven't read...
- Don't add features, refactor code, or make "improvements" beyond what was asked...
# Executing actions with care
Carefully consider the reversibility and blast radius of actions...
# Using your tools
- Do NOT use the shell to run commands when a relevant dedicated tool is provided...
# Tone and style
- Only use emojis if the user explicitly requests it...
# Output efficiency
IMPORTANT: Go straight to the point...
模型行为:先读后改、不多不少恰好完成、危险操作主动确认、输出简洁直接…
6、Skill 链接
-
GitHub 仓库:https://github.com/wuyujjj2164-crypto/claude-skill
-
核心 Skill 文件:SKILL.md
7、总结与思考
最满意的地方:
把"源码逆向 → 去品牌化 → 模块化"这条链路跑通了。不是简单复制粘贴 Claude Code 的提示词,而是理解了它为什么这样设计——5 层管线解决的是关注点分离,静态/动态分离解决的是缓存效率,模块顺序解决的是注意力权重。这些设计思想比具体的提示词文本更有价值。
后续优化方向:
-
增加更多平台的完整适配示例(Aider、Cline 等)
-
把模块选择和占位符替换做成交互式流程,降低使用门槛
-
补充附件系统的具体实现代码示例
希望得到的建议:
-
你在使用 AI 编程助手时,最希望提示词帮你控制什么行为?
-
11 个模块中,有没有你觉得缺少的模块?
-
缓存策略在你的场景下是否实用?有没有更好的方案?