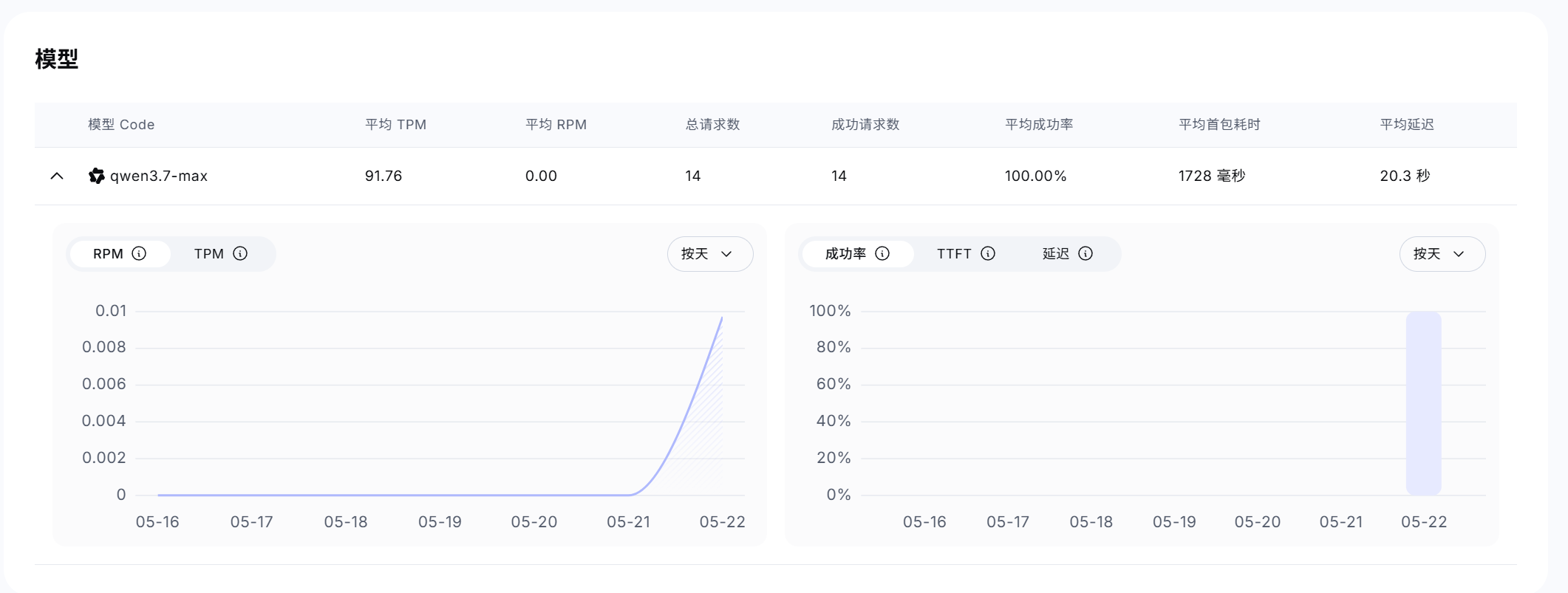
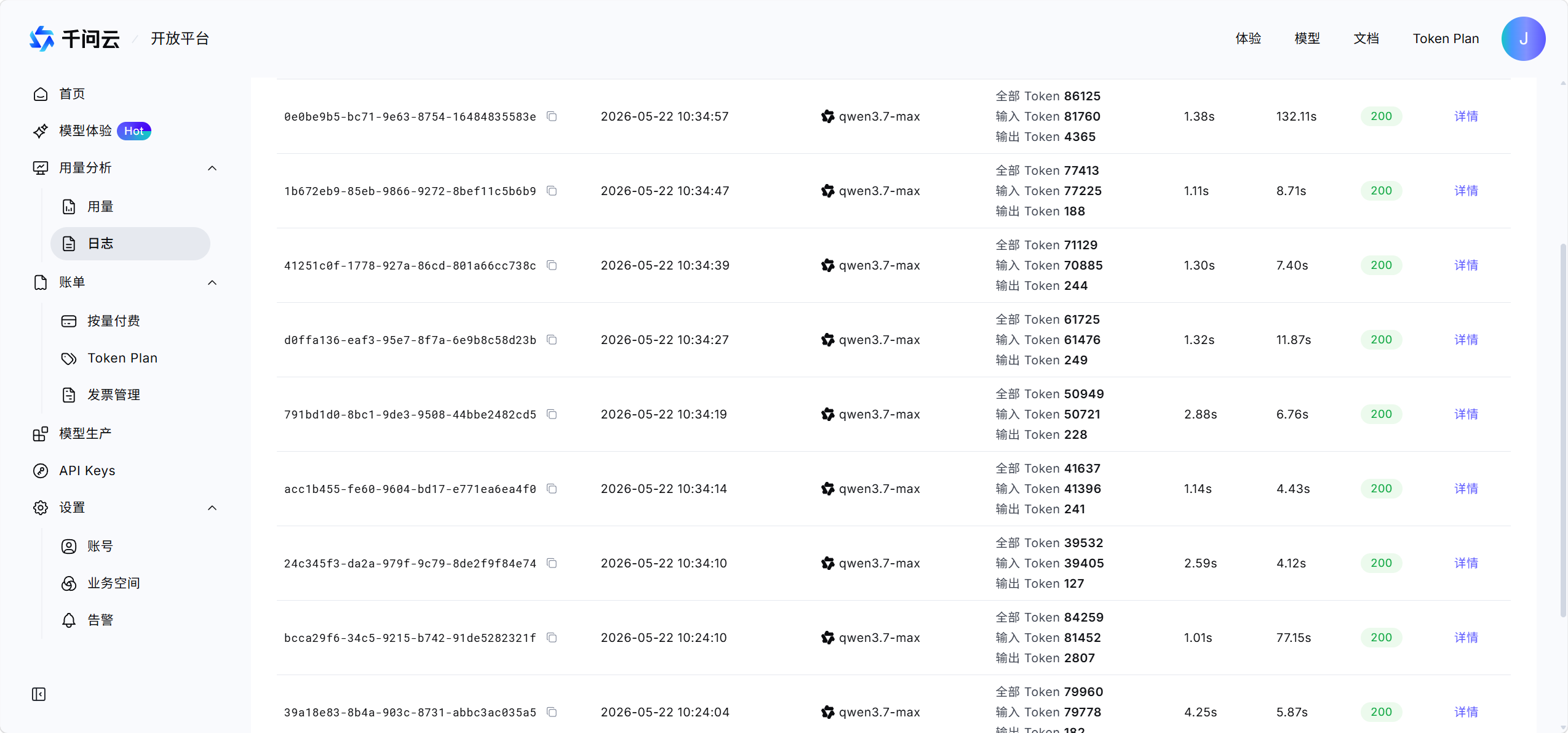
阿里方于5月20日正式发布Qwen3.7-Max旗舰模型,官方宣称能够胜任35小时长程任务,让模型真正成为Agent的智能内核,具备自主规划、持续迭代、跨工具协作的能力。

针对该模型的编程综合能力,我个人进行了简单测试,结果内容如下。
免责声明:模型的测试结果受项目复杂度、本地项目环境、提示词准确度等因素影响,本次测试结果仅为个人主观感受,并且只针对模型的code能力进行评价,不代表模型的综合能力水平。
接入环境:阿里官方千问云平台,官配Qwen3.7-Max模型API调用
模型核心参数:
- 上下文:1M (最大输入991.80K 最大输出65.53K)
- 速率限制:RPM 30K TPM 5M
- 内置工具: code_interpreter、 web_extractor、 web_search
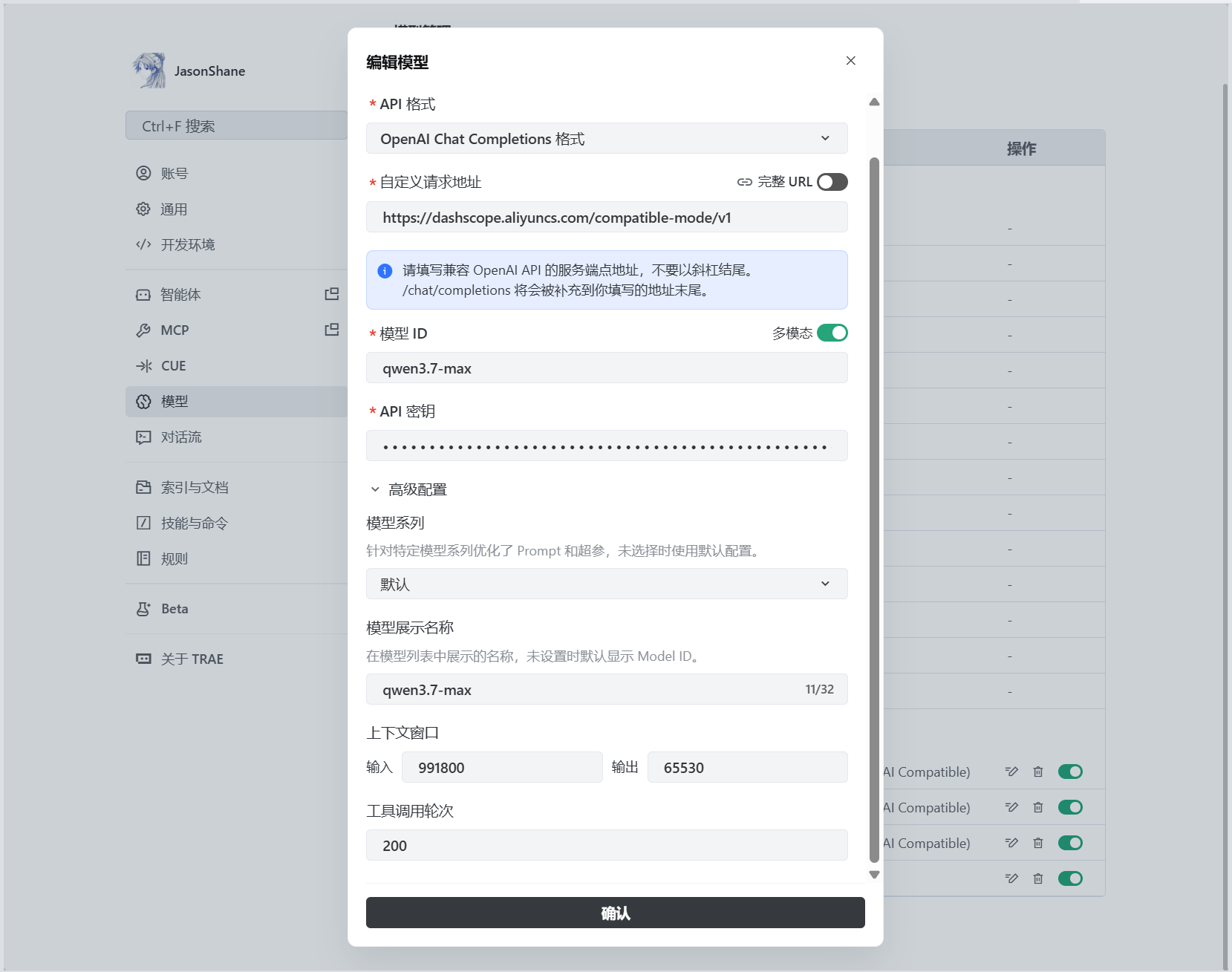
TRAE接入配置:
模型测试:
- 同项目同提示词复现程度:优秀

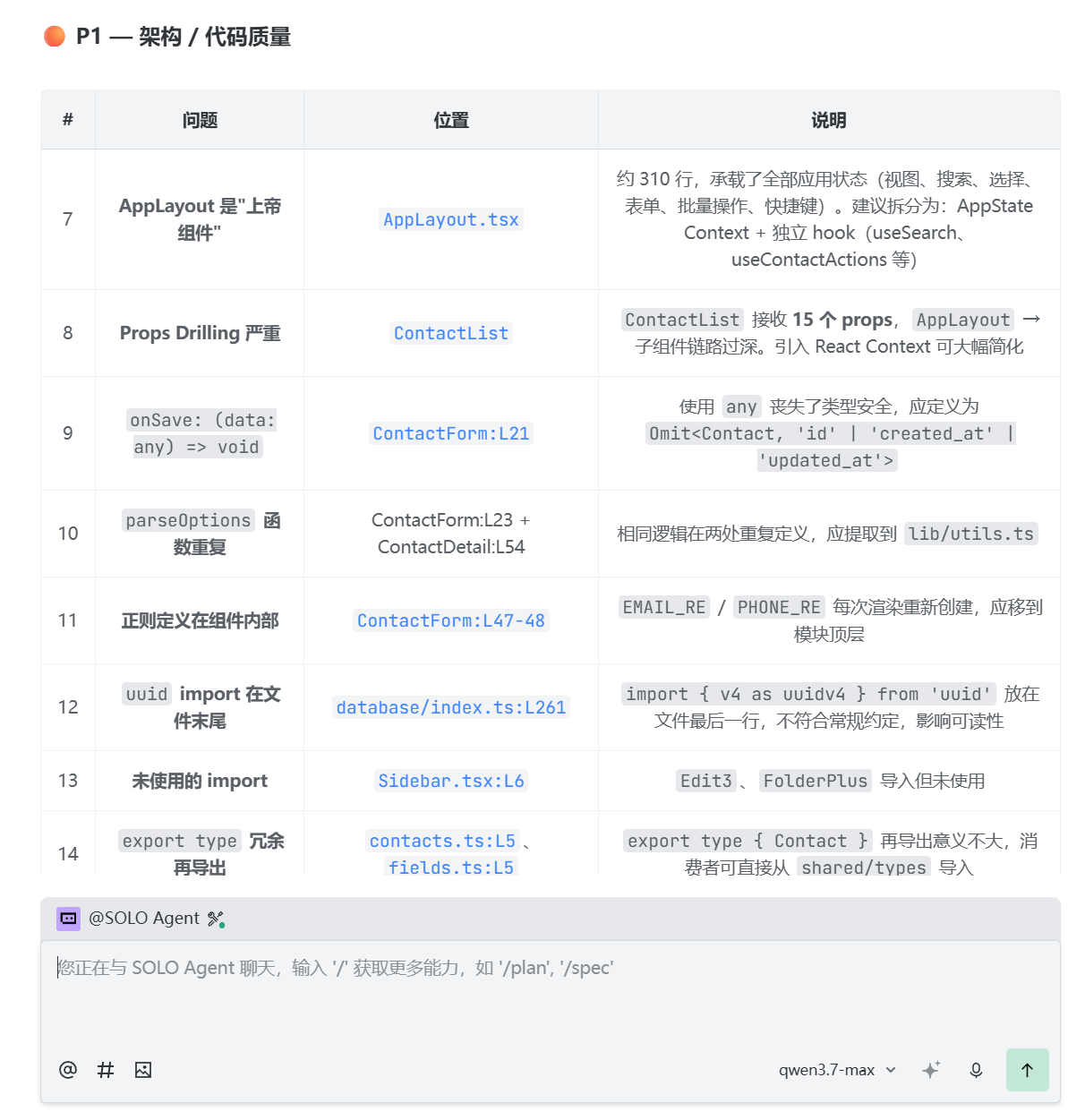
针对同一项目、同一环境、同一提示词(隔离对话)的复现程度相对比较优秀,对于项目理解也比较清晰。
- 同项目同提示词不同模型对比(GLM-5.1 vs Qwen3.7-Max)
表现优秀!
长输出内容在此不展示了,我综合看了一下对于项目理解,问题剖析,输出内容逻辑性而言,比GLM-5.1略胜一筹(单次测试存在偏差,不必刻意追究)
补充数据: