name: kz-article-deep-analysis
description: 深度解读非学术类文章(博客、随笔、评论),抽取核心议题与核心主张,评估其对读者认知的增量与张力,输出结构化分析报告。
版本: v1.0.2
作者: K叔
用途: 深度挖掘文章的核心逻辑与认知价值
适用范围: 博客、公众号文章、随笔、评论(不适用于学术论文或书籍)
背景
非学术类文章(博客、随笔、评论)的阅读场景里,用户往往需要的不只是摘要,而是:
- 抽取作者真正试图回应的核心议题与中心命题
- 梳理论证路径与隐含假设
- 评估文章对读者的认知增量与张力,并沉淀可复用洞见
于是引入一个“小而专、易验证”的 Skill:kz-article-deep-analysis,用于生成结构化的深度解读报告。
使用场景
- 用户提供文章 URL 或正文,要求“深度解读/拆解/解构/认知增量/迁移”类输出
- 输出为结构化 Markdown 报告,便于复用、对照与评审
使用说明
演示
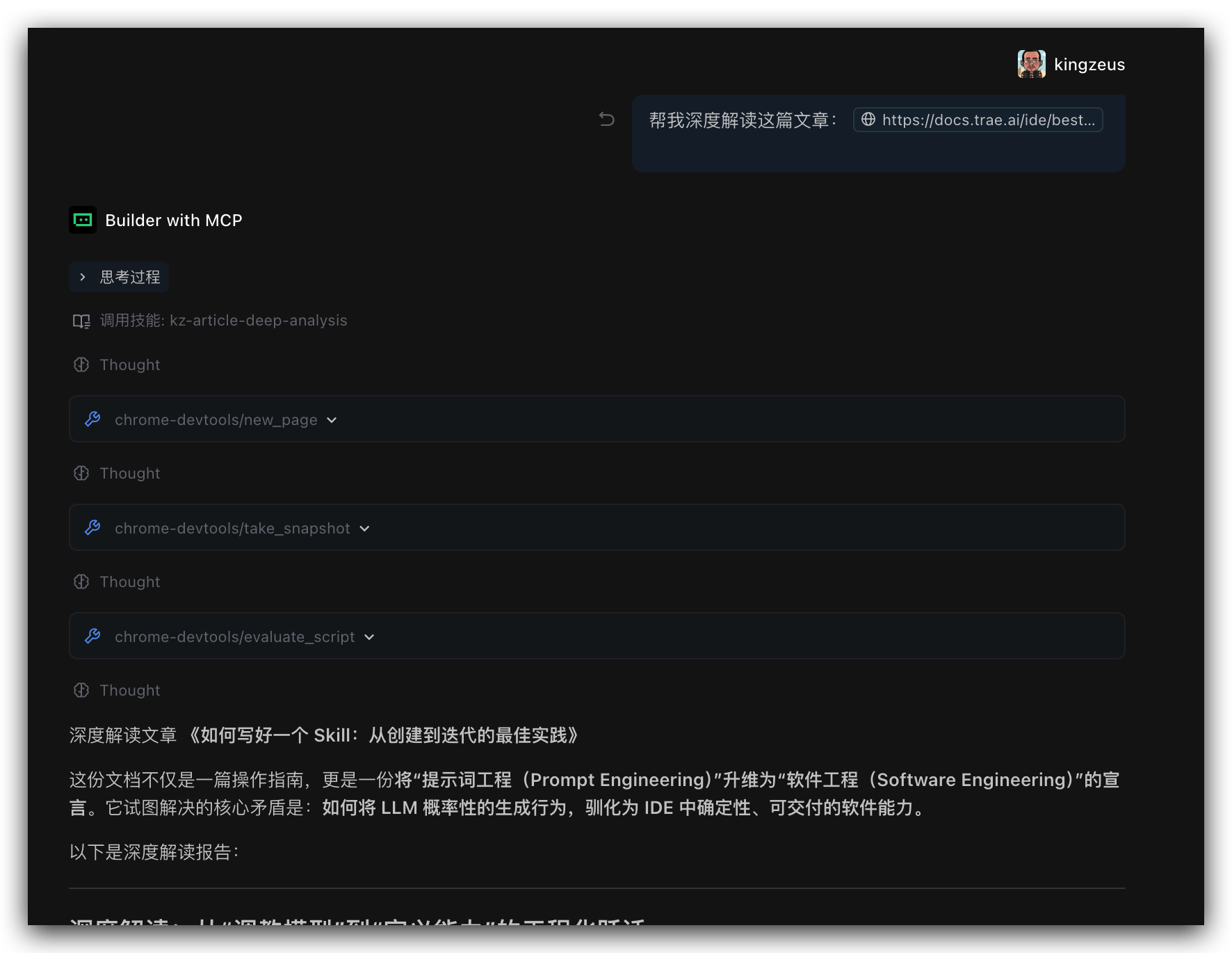
生成的报告:
深度解读:从“调教模型”到“定义能力”的工程化跃迁
——评《如何写好一个 Skill:从创建到迭代的最佳实践》
这份文档不仅是一篇操作指南,更是一份将“提示词工程(Prompt Engineering)”升维为“软件工程(Software Engineering)”的宣言。它试图解决的核心矛盾是:如何将 LLM 概率性的生成行为,驯化为 IDE 中确定性、可交付的软件能力。
1. 核心议题:对抗不确定性
文章表面上是在教你怎么写 Skill,实际上是在回应一个更深层的行业痛点:
在有限的上下文窗口(资源约束)和不确定的模型推理(概率约束)下,如何构建高可靠的 AI 辅助能力?
- 表层问题:怎么写一个能用的 Skill?
- 深层矛盾:自然语言的模糊性 vs 工程交付的确定性。
- 解决路径:通过结构化约束(元数据、I/O定义)和流程化管理(评测驱动、渐进披露),将 Prompt 异化为一种“伪代码”或“配置文件”。
2. 核心主张
Skill 本质上不是“更好的 Prompt”,而是“自然语言编写的软件代码”。
因此,构建 Skill 必须遵循软件工程的核心原则:定义明确的接口(I/O)、单一职责(SRP)、异常处理(Failure Handling)以及测试驱动开发(TDD/评测驱动)。
3. 论证骨架与逻辑拓扑
文章通过三个维度支撑上述主张:
-
认知纠偏(破):
- Skill $\neq$ Prompt(前者是复用模块,后者是临时交互)。
- Skill $\neq$ 说明书(前者是给机器的指令,后者是给人的解释)。
- 复杂 $\neq$ 强大(上下文是稀缺资源,简洁即正义)。
-
工程标准(立):
- 确定性构建:通过“边界条件”和“结构化 I/O”锁定模型行为。
- 防御性编程:强制定义“失败策略”,预设模型会出错。
- 可维护性设计:利用“渐进式披露”和“文件引用”管理复杂度,避免 Token 爆炸。
-
迭代方法论(行):
- 提出“失败优先”原则:先找基线问题,再写 Skill 修复,最后回归评测。这与软件开发中的“复现 Bug → 修复 Bug → 回归测试”逻辑完全一致。
逻辑推理拓扑图:
[不确定性: LLM的概率本质]
|
v
[冲突: IDE需要确定性行为]
|
(引入工程化手段)
|
+-------+-------+------------------+
| | |
v v v
[接口标准化] [防御性设计] [评测驱动]
(I/O, Meta) (失败路径, 边界) (基线对比)
| | |
+-------+-------+------------------+
|
v
[核心主张: Skill = 软件工程实体]
|
v
[结果: 高命中率、高稳定性的能力]
4. 认知增量:你可能忽略的关键点
这篇文章对普通开发者的认知冲击主要体现在以下几个维度的视角转换:
增量点 1:从“成功导向”转向“失败优先”
- 旧认知:写 Prompt 时,我们通常只以此为目的:“怎么说才能让模型做对?”
- 新认知:写 Skill 时,必须假设模型一定会做错。“定义失败”比“定义成功”更重要。
- Why? 因为模型最可怕的不是“不会做”,而是“在错误的时间瞎做”(幻觉或过度自信)。显式定义
When NOT to use(负向边界)是高命中率的关键。
- Why? 因为模型最可怕的不是“不会做”,而是“在错误的时间瞎做”(幻觉或过度自信)。显式定义
+-------------------+ +---------------------+
| Prompt 思维 | | Skill 思维 |
| | | |
| "请帮我做 X..." | ==> | 1. 什么时候不做 X? |
| (期待由模型补全) | | 2. 失败了怎么报错? |
| | | 3. 才是怎么做 X |
+-------------------+ +---------------------+
增量点 2:上下文经济学(Context Economics)
- 旧认知:把所有背景知识都塞给模型,越详细越好。
- 新认知:上下文是付费且稀缺的公共资源。
- 渐进式披露(Progressive Disclosure):SKILL.md 只是索引/路由,具体知识按需加载。这类似于编程中的
Lazy Loading或Import机制。任何多余的 Token 都在降低 Skill 的信噪比,增加“被遗忘”或“被误解”的概率。
- 渐进式披露(Progressive Disclosure):SKILL.md 只是索引/路由,具体知识按需加载。这类似于编程中的
增量点 3:自由度分级(Freedom Levels)
- 旧认知:Prompt 只有“好”与“坏”之分。
- 新认知:控制权应根据任务类型动态通过。
- 高自由度(代码审查):给原则(Heuristics),让模型发挥推理能力。
- 中自由度(报告生成):给模板(Template),约束输出格式。
- 低自由度(数据库迁移):给脚本(Script),完全禁止模型发挥,只做执行器。
- 洞察:不要在需要创造力的地方搞微操,也不要在需要精确执行的地方谈灵感。
总结
这篇文章不仅是 Trae IDE 的 Skill 开发文档,更是一份通用的**“LLM 应用工程化指南”。它告诉我们:不要再把 AI 当作一个需要“哄”的聊天对象,而要把它当作一个需要严谨定义接口、明确异常处理、并通过测试用例验收**的函数模块。
一句话带走:
写 Skill 的最佳心态,不是在写文档,而是在写代码——请带上你的架构师思维。