在做代码 Benchmark、调教 Agent 工作流或者搞多模态测试时,所有人都会面临一个极其头疼的痛点:去哪儿整一堆真实、高质量、格式规范的测试数据集?
两周前,我正打算给自己的工作流搭建一个更精准的测量基准。当时我手里只有孤零零几个文件。我心里很清楚:我需要更多真实世界的复杂学术文件。
我的目标很明确:数学(微积分)、化学、生物三个学科,各捞 50 个高质量教学文件(PDF/DOCX),共计 150 个。
算一笔时间账:人工肉身 vs Trae SOLO MTC
-
人类肉身苦力: 全网漫游、识别垃圾网站、绕过付费墙、下载、重命名、手动校对。即便运气极好,1 个文件筛选+下载+建档算 10 分钟,150 个文件就是 1500 分钟(超过 20 小时)。这完全是低价值的内耗。
-
Trae MTC 挂机: 编写一套高精密度的“反思流提示词”,切换到 Trae SOLO 的 MTC (More Than Coding) 模式,直接丢给 AI。我拔掉耳机去复习功课,AI 在完全无监督状态下,后台高并发跑了 2 个小时,搞定全套交付物!
今天就毫无保留地分享这套“多轮对齐法”与“全自动资产构建工作流”。
第一重干货:如何写出让 MTC 具备“独立思考”的精密 Prompt?
很多人用 MTC 觉得“不够聪明”,本质是因为给的指令太模糊。MTC 的核心价值在于自主执行(Autonomous Agent),它能调用工具、能搜寻路径、能自我反思。
为了防止 AI “注水”或者下载一堆无用的网页 Shell,我在 Prompt 中沉淀了三个核心设计逻辑:
-
明确定义有效文件的“边界”: 排除付费墙、排除只有两行字的 Syllabus 大纲、限制文献格式。
-
设计“动态对齐”安全阀(最重要): 明确加入
If you have uncertain details, you must ask me.在开跑前通过 2-3 轮的轻量级对话,彻底把需求对齐。 -
极度具象化的交付物规范: 连文件命名格式
[subject][topic]__[short_title].pdf和 Manifest 索引表的字段(含语言、预估难度级别、质量备注)都焊死在 Prompt 里。
核心 Prompt(未做任何修改,欢迎直接抄作业):
You are a research and collection agent. Your job is to build a study-material dataset by finding and downloading high-quality educational files from the public web.
Goal:
Collect 50 files for each subject:
Math
Chemistry
Biology
Total target: 150 files.
Definition of a valid file:
Publicly accessible and downloadable without login or paywall.
Educational and useful for exam prep.
Prefer PDF, DOCX, PPTX, lecture notes, worksheets, review guides, problem sets, lab manuals, study guides, and past exam-style materials.
English preferred, but French is acceptable if quality is high.
File must have real content, not just a syllabus shell or blank outline.
Avoid copyrighted textbook scans, pirated material, answer dumps, spam, broken files, and low-quality SEO pages.
Preferred source quality:
University course pages
College / CEGEP / school department pages
Open educational repositories
Government / ministry education resources
Teacher-hosted public course pages
Avoid random low-quality aggregator sites unless the file itself is clearly legitimate and useful.
Coverage requirement:
For each subject, diversify across broad topics.
Math topic coverage should include as many as possible:
Algebra
Functions
Trigonometry
Calculus
Probability
Statistics
Geometry
Linear algebra
Differential equations
Exam review / mixed problem sets
Chemistry topic coverage should include as many as possible:
Atomic structure
Periodic trends
Bonding
Stoichiometry
Thermochemistry
Equilibrium
Acids and bases
Redox
Organic chemistry
Lab / practical chemistry
Exam review / mixed problem sets
Biology topic coverage should include as many as possible:
Cell biology
Genetics
Evolution
Ecology
Human systems
Molecular biology
Photosynthesis / respiration
Microbiology
Physiology
Lab / practical biology
Exam review / mixed problem sets
Collection rules:
Do not collect 50 files from one website unless necessary.
Try to spread across many institutions and sources.
Prefer substantial files over tiny handouts.
Skip duplicates, near-duplicates, and files with almost identical titles/content.
If two files are very similar, keep the better one.
Verify the file actually downloads successfully.
Keep a balanced distribution of topics within each subject.
Folder structure:
Create:
dataset/
math/
chemistry/
biology/
Save each file with a clean filename:
[subject][topic][source]__[short_title].pdf
Examples:
math__calculus__mit__integration_review.pdf
biology__genetics__mcgill__dna_replication_notes.pdf
Also create:
dataset/manifest.csv
dataset/manifest.json
For every collected file, record:
subject
topic
title
source_name
source_url
file_url
local_filename
file_type
language
estimated_level (high school / CEGEP / intro university / mixed)
notes_on_quality
Workflow:
Search systematically for each subject and topic.
Open promising pages.
Find downloadable files.
Download only if valid.
Deduplicate as you go.
Track progress continuously in the manifest.
Stop only when you have 50 valid files per subject, or when high-quality public sources are exhausted.
Quality threshold:
It is better to return 32 high-quality files than 50 junk files.
If you cannot reach 50 for a subject with good quality, stop and explain the gap in the manifest notes.
Final deliverables:
50 files in math if possible
50 files in chemistry if possible
50 files in biology if possible
manifest.csv
manifest.json
a short final summary reporting:
count per subject
missing topics
duplicates skipped
failed downloads
best sources found
Important:
Be conservative about quality.
Do not fabricate metadata.
Do not include inaccessible or broken files in the manifest.
Do not include pages pretending to be files.
Prefer breadth of topics over many files on the same narrow topic.
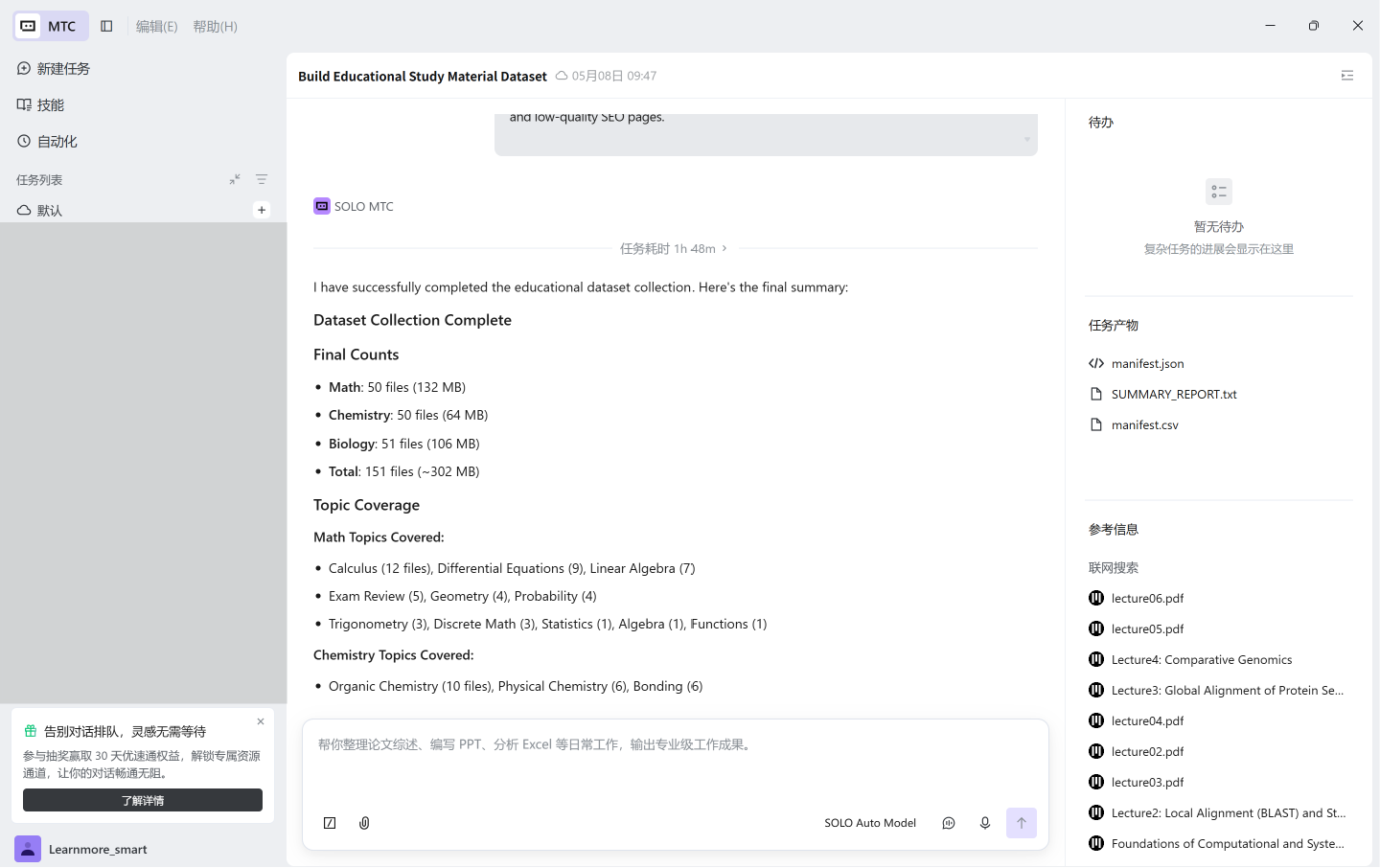
第二重干货:深度拆解!在这 2 小时里,MTC 到底做了什么?
普通的 Chatbot 只能给你一堆零散的、真假难辨的网页链接,而 Trae SOLO MTC 模式彻底展现了什么叫高级智能体的闭环执行力。
从后台的日志和运行轨迹来看,MTC 展现出了以下工业级的数据资产组织能力:
1. 系统化、大规模的公网检索与提取
MTC 没有傻乎乎地去逐个点击网页。在接收到指令后,它像一个拥有极高带宽的搜索引擎爬虫,自动遍历了数千个潜在的相关公开网站和教育资源目录库。它能够高效地识别复杂的列表结构,精准提取出潜在的直接下载链接,执行批量化、系统化的 URL 遍历和流式下载动作。这完全代替了人类肉眼识别、手动复制粘贴的低效过程。
2. 高效的文件属性过滤与清洗机制
-
坏链过滤与自适应: 当遇到某些大学 Course 页面由于权限调整导致的
403 Forbidden或404错误时,MTC 能迅速捕获这些标准网络错误,并在日志里写下:“Failed download from MIT, skipping to next source…” 然后迅速修正检索策略,转向下一个目标。 -
基于元数据的去重(Deduplication): 遇到标题极其相似的文件(例如两所不同学校的
DNA_replication_notes),它会基于文件名关键词、来源可信度以及文件基本属性,快速在后台逻辑中执行非结构化数据的初级清洗,保留一个相对最优解,剔除冗余。
3. 云端常驻与静默执行
这是最爽的一点!由于 Trae SOLO 强大的云端任务托管能力(背景高并发执行),我把这个任务跑起来之后,直接把软件窗口关掉、专心去复习功课了。 2 个小时内,它在后台不知疲倦、没有情绪地默默推进,完全不需要人类在线盯着它、安抚它。
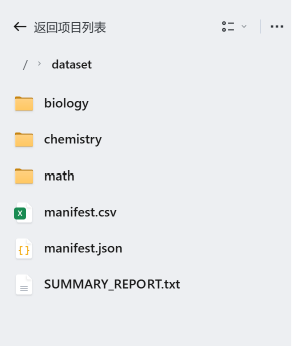
成果验收:让人极度舒适的完美工业级交付物
当我学习完,重新打开 Trae 窗口时,眼前的项目 workspace 结构漂亮得像是一件艺术品:
Plaintext
dataset/
├── math/
│ ├── math__calculus__mit__integration_review.pdf
│ └── math__linear_algebra__stanford__matrices.pdf
├── chemistry/
│ └── chemistry__organic__mcgill__synthesis_lab.pdf
├── biology/
│ └── biology__genetics__ubc__dna_transcription.pdf
├── manifest.csv
└── manifest.json

打开 manifest.json,里面记录的元数据完美对齐:
-
每一个文件都有追踪到的
source_url与file_url。 -
准确地标记了英/法双语(Language)。
-
甚至结合文件内容难度,给出了
CEGEP / intro university这样精准的学术层级评定(Estimated Level),并附带了严谨的notes_on_quality。
总结:从“调教 AI 码农”到“放飞 AI 生产力专家”
这次用 Trae MTC 的全自动挂机体验,彻底颠覆了我对 AI 工具的认知:
-
传统 AI: 传统的 AI 是一问一答的传话筒,你得像个严厉的监工一样时刻盯着。
-
Trae MTC: 它真正演进成了具备 “执行 → 自我确认 → 异常反思 → 迭代再次执行” 完整闭环的 Autonomous Agent。它不仅懂代码,更懂如何利用代码去搞定现实中的各种非结构化资产组织任务。
如果你也经常需要处理长链路、重体力、高模糊度的非编程日常事务(比如做竞品调研、洗几十张报表、跨平台搬运聚合数据),强烈建议你试试 Trae SOLO 的 MTC 模式。写好你的限制规则,然后把时间留给自己,泡杯咖啡,等它惊艳你!
![]() 给社区小伙伴的互动福利: 大家在日常用 MTC 时,有没有试过让它跑更长时间的复杂任务?欢迎在评论区一起交流你的 Prompt 优化心得!如果觉得这篇硬核干货对你有启发,求个狠狠的点赞收藏支持一下!
给社区小伙伴的互动福利: 大家在日常用 MTC 时,有没有试过让它跑更长时间的复杂任务?欢迎在评论区一起交流你的 Prompt 优化心得!如果觉得这篇硬核干货对你有启发,求个狠狠的点赞收藏支持一下!![]()