几个月回老家过年,翻到一本落灰的相册。
里面有我三岁骑在爸爸肩上的照片,有我奶奶年轻时穿旗袍的照片,还有一张我爸妈结婚时的合照——这些照片只有纸质版,没有底片,也不可能再洗一套出来。相册边角已经泛黄,有几页甚至粘在一起了。
我当时就在想:能不能把整页扫下来,然后让程序自动把里面的每张照片单独裁出来?回去查了一圈,没找到趁手的工具,于是就有了这个新项目 —— PhotoCrop。
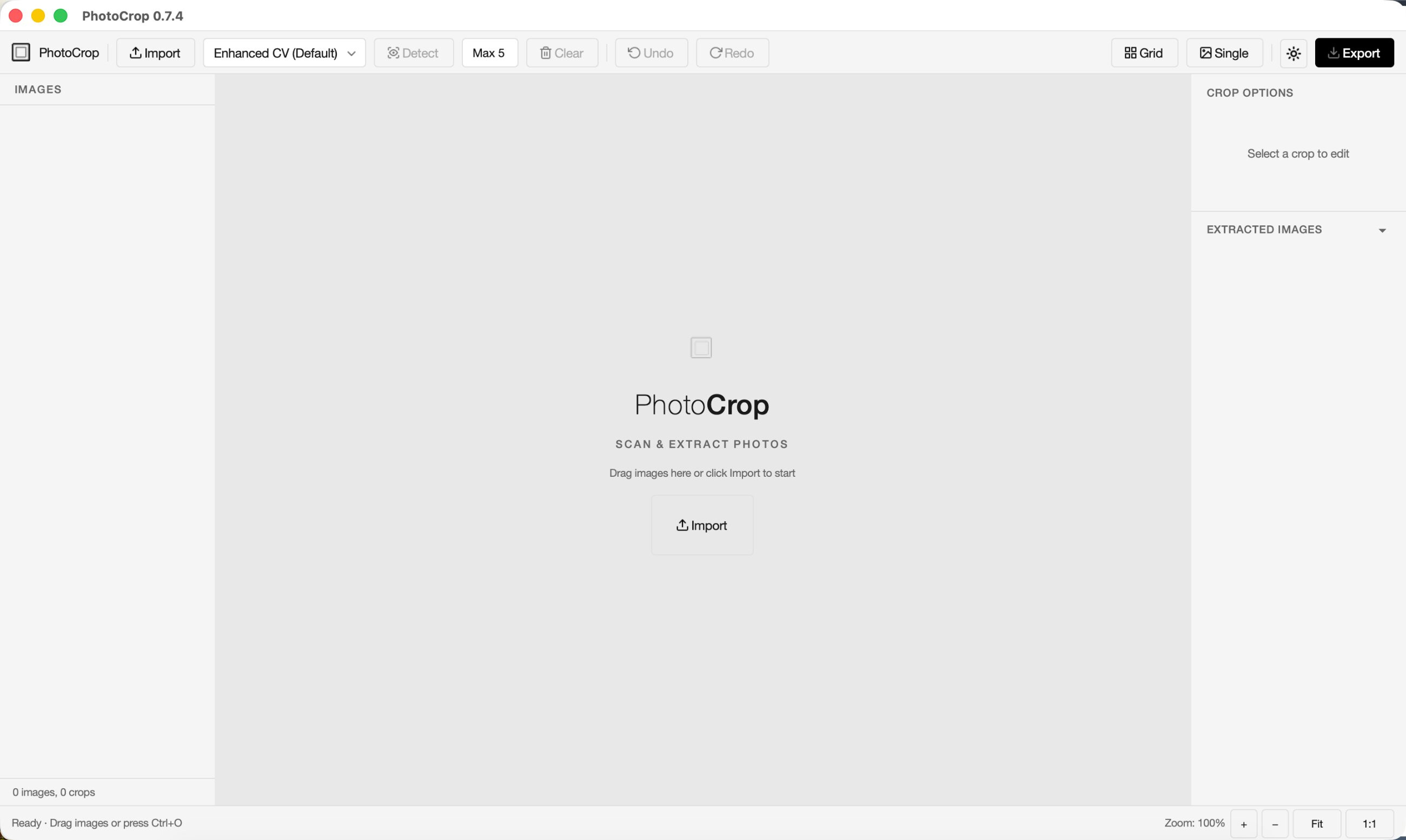
PhotoCrop 做的是一件很朴素的事:你拿公司打印机把一整页相册扫成 PDF 或图片,丢进这个工具,它自动识别出里面有几张照片、每张照片在什么位置,然后干净地裁成单独的文件。
技术上有几个我觉得值得分享的亮点:
第一,检测策略是可插拔的。 我写了一个 ABC 基类,目前接入了四种检测器:增强版 CV(我自己调的一套边缘+形态学流程,对低质量扫描件比较鲁棒)、传统 CV、IoU 投票融合(多个检测器的结果加权表决),以及 YOLO-World 的零样本检测。需要换模型或者自己加一个检测器,只需继承基类、注册进工厂就行。
第二,GUI 是用 PySide6 写的,交互参考了常见的图片编辑软件。 裁剪框可以直接拖拽调整、旋转、锁定宽高比,撤销重做是完整的双栈实现。左右分栏布局,左侧面板管理多图/PDF 多页,右侧是属性面板,底部是提取预览。主题支持 Light/Dark,带过渡动画。
第三,整个识别和裁剪流程跑在本地, 不需要联网,照片不会上传到任何服务器。这个对我来说很重要——老照片本来就是很私人的东西。
目前的版本已经覆盖了这些场景:
-
单张扫描图片的自动检测 + 手动微调 + 导出
-
整本 PDF 相册的批量处理
-
命令行模式,方便写脚本批量跑
-
拖拽导入,支持 JPG/PNG/TIFF/PDF 等 8 种格式
如果你家里也有那种"每年只翻一次"的老相册,可以试试看。项目的初衷很直白:把柜子里的回忆变成硬盘里的回忆,让它们能在微信里发出去、能在云盘里跟着你走。
欢迎体验,有问题尽管提。