 简历雷达 · Resume Radar
简历雷达 · Resume Radar
让 HR 把 2 小时的翻简历,变成 2 分钟的点开 Excel
 它是什么?
它是什么?
简历雷达 是一个面向 HR / HRBP / 招聘经理的 SOLO Skill:
只要给它一个文件夹,它就会:
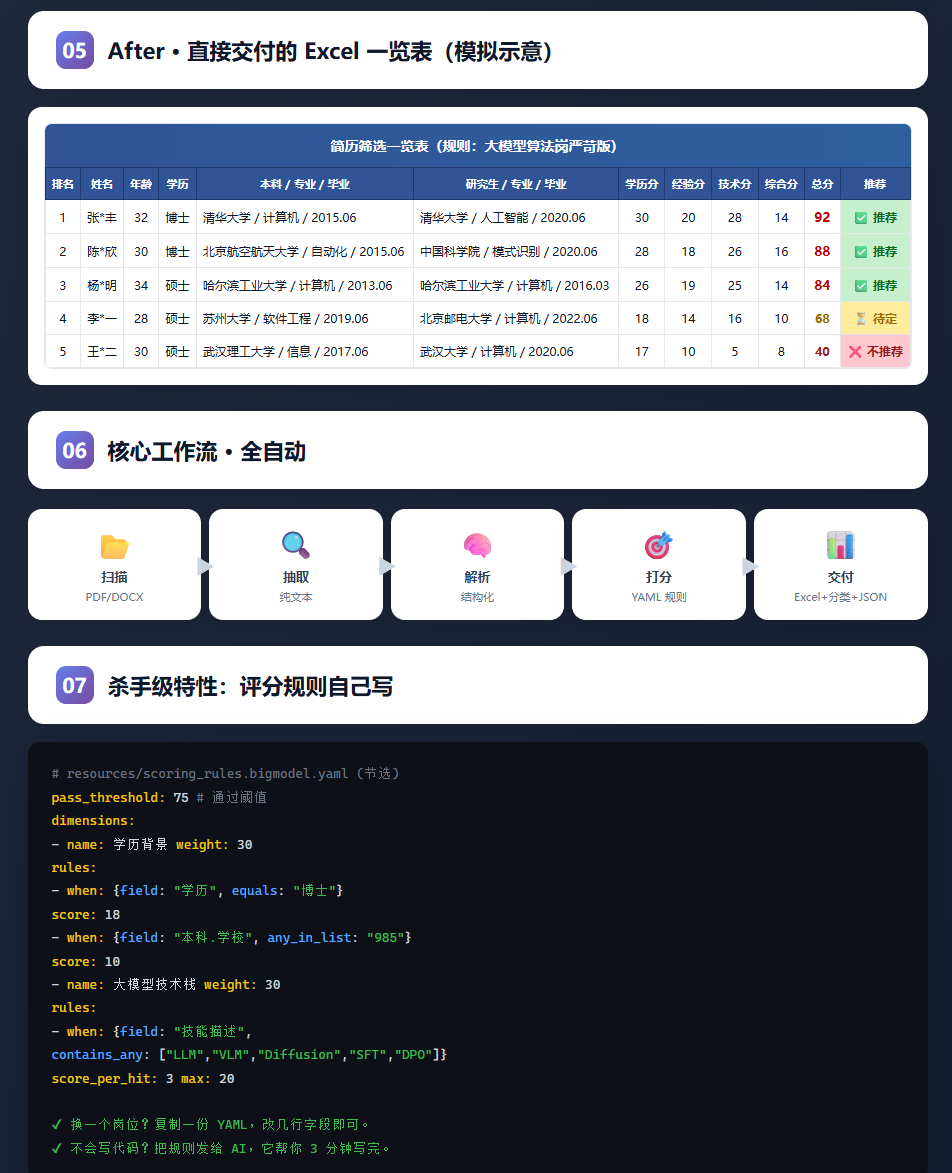
 扫描其中所有的 PDF / Word 简历(可嵌套子目录)
扫描其中所有的 PDF / Word 简历(可嵌套子目录) 自动抽取并结构化 —— 姓名、年龄、学历、本科/研究生的学校 + 专业 + 毕业时间、工作经历、技能、综合素质……
自动抽取并结构化 —— 姓名、年龄、学历、本科/研究生的学校 + 专业 + 毕业时间、工作经历、技能、综合素质…… 按照 用户自定义 YAML 评分规则 从 4 个维度(学历背景 / 工作经验 / 专业技术水平 / 综合素质)逐一打分
按照 用户自定义 YAML 评分规则 从 4 个维度(学历背景 / 工作经验 / 专业技术水平 / 综合素质)逐一打分 一键生成一张可直接交付的 Excel 一览表(含推荐等级
一键生成一张可直接交付的 Excel 一览表(含推荐等级  /
/ /
/ )
) 把原始简历按 通过 / 未通过 分到两个文件夹
把原始简历按 通过 / 未通过 分到两个文件夹 生成 结构化 JSON 档案库,方便后续二次分析或入库
生成 结构化 JSON 档案库,方便后续二次分析或入库

 用之前 vs 用之后
用之前 vs 用之后
| 维度 | 没有雷达 | 有了雷达 |
|---|---|---|
| 500 份简历耗时 | 半天 ~ 一天 | 约 2-5 分钟 |
| 主观偏差 | 情绪、顺序、疲劳 | 完全由规则驱动,可追溯 |
| 多岗位并行 | 记不过来多套标准 | 一个 YAML 一个岗位 |
| 向 leader 汇报 | 只能给模糊的"感觉不错" | 一个打分表直接发过去 |
|  | |
|  |
 5 秒快速上手
5 秒快速上手
1. 依赖
pip install pdfplumber python-docx openpyxl pyyaml pypdf
2. 一条命令跑通
python scripts/run_pipeline.py \
--input-dir "D:\招聘\2026校招-大模型岗" \
--job "大模型算法工程师" \
--rules "resources/scoring_rules.bigmodel.yaml"
3. 打开结果
<input-dir>/_筛选结果_20260513_140231/
├── 一览表.xlsx
├── json/
├── 通过_不低于75分/
└── 未通过_低于75分/
 自定义你的评分规则(杀手级特性)
自定义你的评分规则(杀手级特性)
复制 resources/scoring_rules.default.yaml 改个名:
version: 1
pass_threshold: 80 # 这个岗位必须 80+ 才算通过
dimensions:
- name: 学校硬性门槛
weight: 40
rules:
- when: {field: "本科.学校", any_in_list: "c9"}
score: 40
- when: {field: "本科.学校", any_in_list: "985"}
score: 30
- default: 0
- name: 英语水平
weight: 30
rules:
- when: {field: "技能描述", contains_any: ["CET-6","IELTS","TOEFL","海外"]}
score: 30
- default: 10
# ... 继续按业务需要写
然后 --rules your_rules.yaml 即可换套规则跑。
这就是它叫"雷达"的原因——你定义扫描的频段,它只告诉你命中的。
 示例
示例
examples/input_resumes/ 下放了 3 份完全虚构的脱敏示例简历,
运行 examples/run_example.ps1 就能看到对应的 Excel / JSON / 分类产物。
| 示例 | 预期总分 | 预期结果 |
|---|---|---|
| 示例简历1_张三丰_大模型算法博士.docx | 92 | |
| 示例简历2_李四一_大模型应用工程师.docx | 49 | |
| 示例简历3_王五二_数据工程师.pdf | 25 |
把示例简历 3 换成
scoring_rules.data_engineer.yaml规则再跑一次,它就会上升到推荐档。
这正展示了"不同岗位切换规则"的能力。
 目录
目录
resume-radar/
├── SKILL.md # ⭐ Skill 核心文档(Agent 触发入口)
├── README.md # 本文件
├── scripts/
│ ├── run_pipeline.py # 一键主流程
│ ├── extract_resume.py # PDF / DOCX 文本抽取
│ ├── parse_resume.py # 规则式结构化解析
│ ├── score_resume.py # YAML 评分引擎
│ └── build_report.py # Excel 一览表
├── resources/
│ ├── scoring_rules.default.yaml
│ ├── scoring_rules.bigmodel.yaml # 大模型岗严苛版
│ ├── scoring_rules.data_engineer.yaml
│ ├── schools_tier.yaml # 985/211/C9/QS 学校库
│ └── job_templates/
└── examples/
├── input_resumes/ # 3 份脱敏示例
├── expected_output/ # 示例运行产物
└── run_example.ps1
 FAQ
FAQ
Q: 会把简历上传到云端吗?
A: 完全不会。所有处理都在本地完成,不依赖任何外部 API。
Q: 扫描版 PDF 能处理吗?
A: 目前仅支持可提取文字的 PDF。纯扫描版 (图片) 会在日志中被跳过并提示。
Q: 规则写错了怎么办?
A: YAML 加载失败会立刻报错。每条规则命中过程都写进了 JSON 的 评分.明细,完全可追溯。
Q: 支持多语言简历吗?
A: 中英文简历都能抽取文本;规则匹配的关键词也可以写成英文,灵活度 100%。
Q: 能扩展到"人岗匹配"吗?
A: scoring_rules.*.yaml 已经就是你的"岗位向量"。后续版本会增加大模型 JD 自动生成规则的功能。
 License
License
本项目采用 Apache License 2.0 开源。
solo 技能创作赛