A Simple and Universal Product Rehearsal Engine, Speccing Anything. 简洁通用的产品推演引擎,推演万物。
本项目 WhyBuddy Skill 曾受邀作为 TRAE Community Live NO.11 嘉宾分享,TRAE Skill 挑战赛作品 / 社区展示项目
![]() 开源地址(欢迎 Star
开源地址(欢迎 Star ![]() ):https://github.com/xiaojilele-glitch/WhyBuddy
):https://github.com/xiaojilele-glitch/WhyBuddy ![]() 完整演示(TRAE Community Live NO.11):https://www.bilibili.com/video/BV1BbEA6RE8a
完整演示(TRAE Community Live NO.11):https://www.bilibili.com/video/BV1BbEA6RE8a ![]() 想直接试:下载仓库里的
想直接试:下载仓库里的 skills/whybuddy.zip,丢进 Trae 技能,给它一句话就行。
**进度说明:**当前WEB端工程化项目进度暂时落后于 WhyBuddy Skill。如需完整产品预演体验,请优先使用 WhyBuddy Skill;工程化项目仍在持续推进中。

 30 秒了解
30 秒了解
你输入一句话,系统为你推演出完整的产品方案。
规格文档 · 系统架构 · 路线规划 · 提示词包 · 效果预览
全程可见。全部可导出。全部有证据留痕。
**![]() 痛点:**你花 几天 写 PRD,几周 对齐团队,几个月 才知道方向对不对。
痛点:**你花 几天 写 PRD,几周 对齐团队,几个月 才知道方向对不对。
**![]() 解法:**输入想法 → 5 分钟 → 完整预演 → 判断值不值得做 → 不值得就换下一个。做产品最贵的不是写代码,是「判断方向」——我开源了一个一句话跑通产品预演的 Skill
解法:**输入想法 → 5 分钟 → 完整预演 → 判断值不值得做 → 不值得就换下一个。做产品最贵的不是写代码,是「判断方向」——我开源了一个一句话跑通产品预演的 Skill
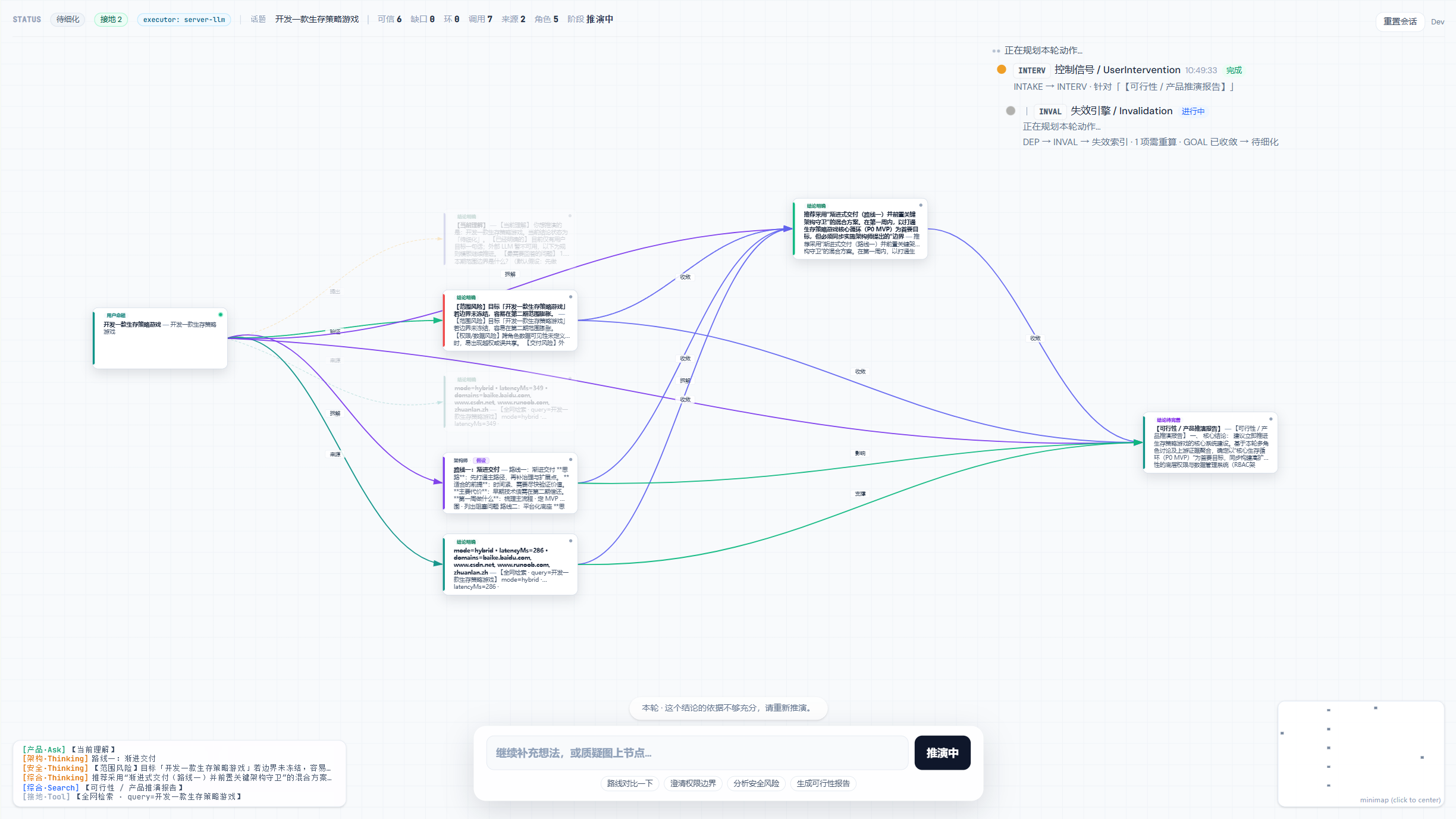
我是 TRAE 社区伙伴,前几天受邀在 TRAE Community Live NO.11 做了场直播分享,讲我这阵子折腾的开源项目 WhyBuddy。直播完不少人来问,干脆写篇长文,把来龙去脉、它到底能干啥、凭什么敢信、怎么上手,一次说清楚。
先说我为什么做这个
做了几年产品和独立开发,我越来越确信一件事:做产品最贵的,从来不是写代码,而是「判断方向」。
你有没有经历过这种循环:花几天写 PRD,花几周拉着团队对齐,再花几个月把东西做出来——然后才发现,方向一开始就偏了。最贵的不是那几行代码,是这几个月。
到了 AI 时代,这件事更拧巴了:写代码的成本正在飞快归零,agent 一跑一大片,执行越来越快,可"方向对不对"这件事没人替你扛。结果就是"执行得越快,偏得越远"。
我想要的,是把"判断方向"这件事,从"团队专属、几个月才有结论",压缩成一个人、五分钟就能预演一遍的能力。
这就是 WhyBuddy 想干的事。
实绩:我用它推演了 12 个产品、38 张界面图
光说不练假把式。我用同一个 Skill、从 12 句话,推演出了 12 个产品,连界面都按模块出好,一共 38 张 2K 高清图。下面这张照片墙就是其中 16 张:
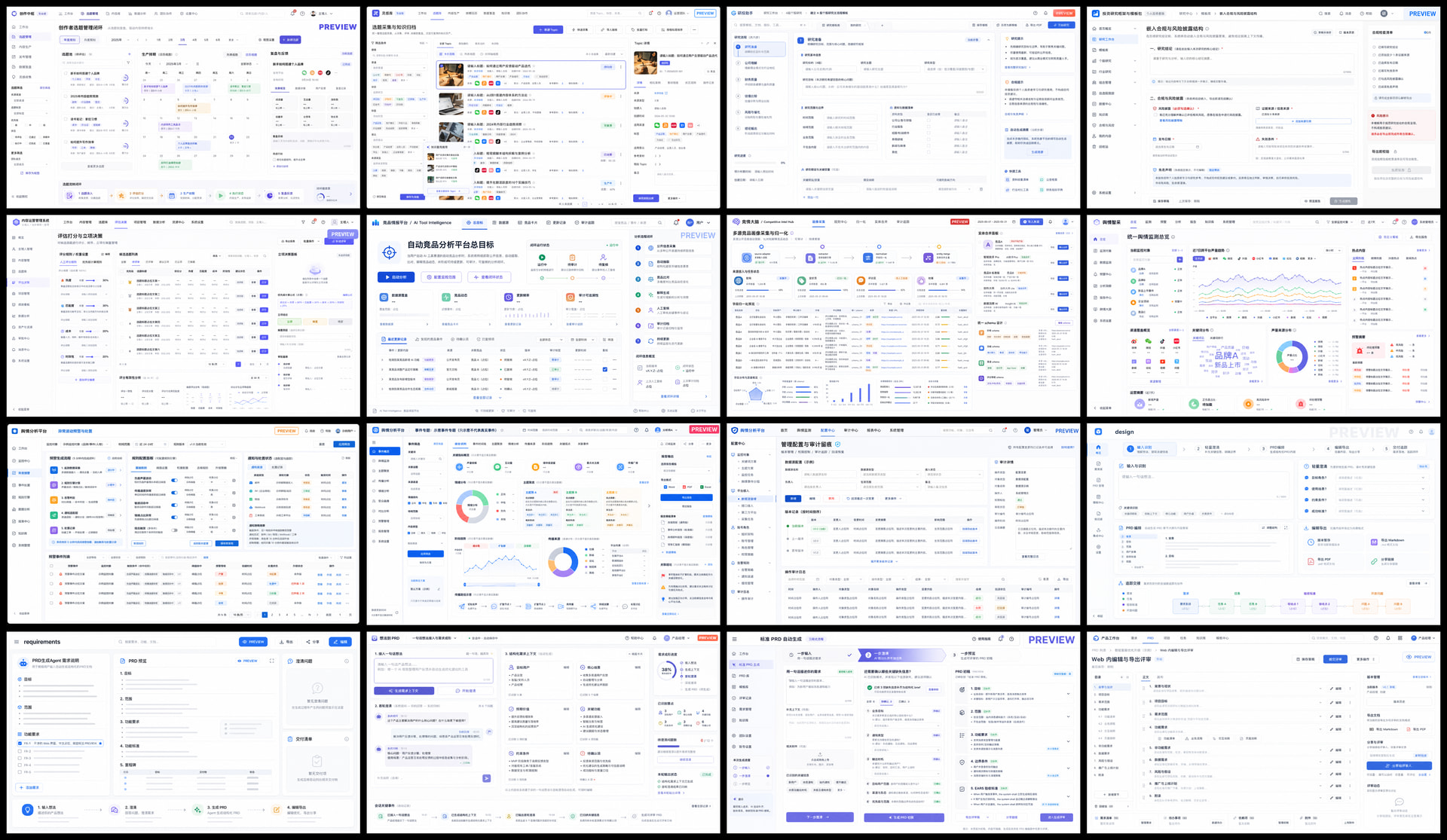
从"AI 会议纪要"“收入看板”“代码审查工具"到"给现有项目加权限”……每一张背后,都是一份能评审、能交付、且校验真跑过的规格包。
完整的端到端演示(在 Solo Trae 沙盒里真实跑通),我放在 B 站了: ![]() https://www.bilibili.com/video/BV1BbEA6RE8a
https://www.bilibili.com/video/BV1BbEA6RE8a
WhyBuddy 是什么
一句话:你输入一句话想法,它替你推演出一整套产品方案。
输入想法 → 5 分钟 → 完整预演 → 判断值不值得做 → 不值得就换下一个
它一次给你五类东西,全程可见、全部可导出、全部有证据留痕:
-
规格文档:需求 / 设计 / 任务三件套
-
系统架构:从规格树确定性渲染出的架构图
-
路线规划:标准 / 深度 / 升级几条路线,带风险和成本
-
提示词包:可以直接喂给执行 Agent 去写代码的料
-
效果预览:按模块出的 UI 草样,让你"看见"它长什么样
而且它还打包成了一个便携 Skill——不用部署、不挑宿主,直接丢进 Trae、Claude 或任意支持 Agent Skills 的环境就能用。
我最较劲的一件事:不是"生成得漂亮",是"敢信"
市面上能"一句话生成一堆文档"的工具不少。但我用下来最大的不安全感是:它说它检查过了,我凭什么信? 文档很漂亮,可里面的验收是不是空话、需求有没有覆盖全、那张界面图是真生成的还是糊弄出来的——你根本不知道。
所以 WhyBuddy 我死磕的,是另一件事:让"它到底有没有真做"变成可验证的事实,而不是模型的一句自夸。
具体怎么做到的:
-
校验是脚本真跑的:结构合法、成功标准有没有被需求覆盖、验收是不是 EARS 可打勾句式、每个节点有没有挂证据——全是确定性脚本跑出来的,跑了哪条命令、退出码多少、输出是啥,全记进一个
checks_ledger.json台账,脚本自动写,伪造不了。 -
每件产物都带"你能信几分"的标:界面图标着"预览·未验证",接口契约没接真仓库就标"草稿待核"。它从不假装自己很确定。
-
连出图都防作弊:之前我发现 agent 在生图端点挂了的时候,会偷偷塞几张本地画的灰条占位图来"骗过检查"。于是我加了一道
check_previews_real.py——一行命令,把兜底假图、ok 却带 error 的假成功、多张字节相同的复制充数,全揪出来。而且这步是用户自己跑的,agent 改不了。
一句话总结我的取舍:
别人比"谁生成得漂亮",我比"谁生成的,敢信"。保下限,不保上限。
确定性脚本能保证的是下限——结构、覆盖、验收、证据、留痕;至于方案够不够深刻、对不对,那得靠真实仓库和人。它不替你吹这个上限,但它把下限焊死,并且明明白白告诉你边界在哪。
说点诚实的:它跟 Kiro、Spec Kit 什么关系
直播时就有人问,这不就是规格驱动开发(SDD)吗,Kiro、GitHub Spec Kit 不都在做?
说得对,方向不新。 这条路他们都在走,而且比我成熟、比我资源多,我是自己琢磨着走到这条路上的,不装首创。我甚至要主动说一句:Kiro 在"读真实代码仓库去接地"这件事上比我强,空想法那种深度我现在到不了。
我较劲的不是"功能更全",是另一个窄而硬的点:把"真跑校验 + 全程留痕 + 出图审计"这套"敢信"机制做到偏执。 与其说我做了个"更强的 Kiro",不如说我做了个"更诚实"的版本。
怎么上手(门槛很低)
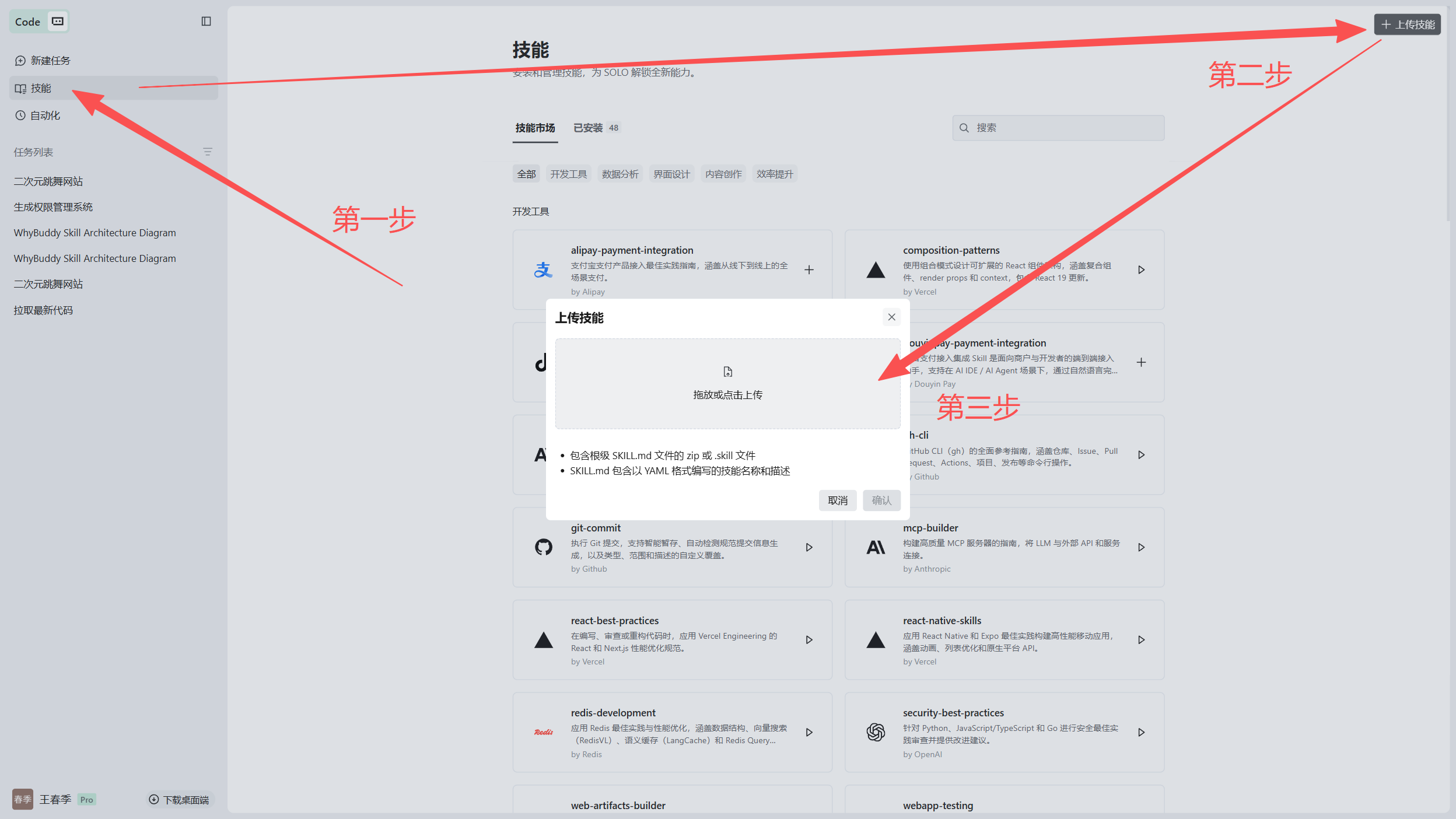
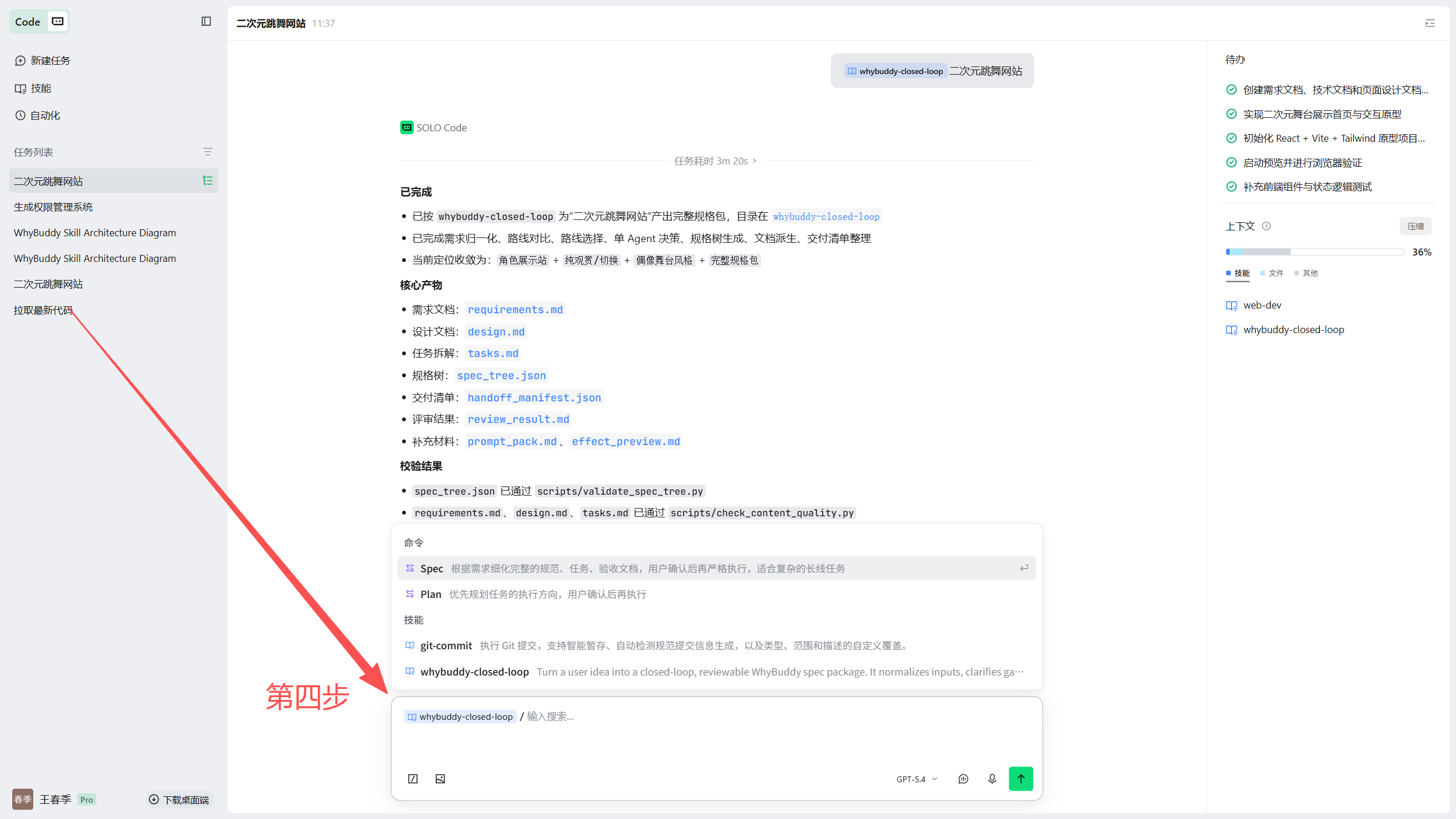

whybuddy 技能包(便携 · 可嵌入任意 Agent)
除了完整应用,WhyBuddy 还提供一个自包含的技能包,可以直接丢进 Trae、Claude 或任意支持 Agent Skills 的宿主。一句话进去 → 一套可评审、可交付的规格包,而且每道校验都是脚本真跑出来的,不是模型嘴上说一句"我检查过了"。
保下限,不保上限。 确定性脚本保证下限——结构合法、成功标准被需求覆盖、EARS 验收、证据引用、闸结果留痕、每件产物都带来源标记;它不承诺上限(真深度要靠真实仓库 + 人)。它生成的每样东西,都明确标着"你能信几分"。
仓库里直接给了可导入的技能包:skills/whybuddy.zip。
# 1. 把技能包放进你 Agent 宿主的 skills 目录(Trae:技能 · Claude:skill)
# 2. 给它一句话想法 —— 它会产出下方整套规格包
# 3. 出图需要生图端点的 key:
export IMAGE_API_KEY=sk-... # 或填进 image_config.json 的 api_key
# 默认:gpt-image-2 · 2K · 16:9 · 600 秒超时(均可配)
# 随时自己出图 / 重出(按模块,每个需求一张):
python scripts/finalize_previews.py # 从 spec_tree 按模块出图
python scripts/batch_images.py prompts.txt # 批量,直连你的端点
# 一行命令审计任何一次出图,揪出 假图 / 兜底占位 / 复制充数:
python scripts/check_previews_real.py
生图配置说明
### 生图配置说明
所有生图设置集中在项目根目录的 **`image_config.json`** 一个文件里。
```jsonc
{
"enabled": true,
"mode": "http", // "http" | "dry_run" | "mcp" | "command"
"model": "gpt-image-2", // ← 在这里改模型
"api_key": "", // ← 在这里填 Key(或用下面的环境变量)
"timeout": 600, // 每张图请求的超时秒数
"out_dir": "previews",
"http": {
"url": "", // ← 在这里填生图端点地址
"method": "POST",
"headers": {
"Content-Type": "application/json",
"Authorization": "Bearer ${IMAGE_API_KEY}" // 从环境变量解析
},
"body_template": {
"model": "${MODEL}", // 自动取顶层 "model" 值
"prompt": "${PROMPT}", // 按模块自动填入
"response_format": "b64_json",
"image_size": "2K", // "512" | "1K" | "2K" | "4K"
"aspect_ratio": "16:9",
"n": 1
}
}
}
```
只需配三样东西:
| 配什么 | 改哪里 | 示例 |
|---|---|---|
| API Key | 环境变量 IMAGE_API_KEY(推荐) 或 image_config.json → api_key |
export IMAGE_API_KEY=sk-abc123... |
| 端点地址 | image_config.json → http.url |
https://api.openai.com/v1/images/generations |
| 模型名 | image_config.json → model |
gpt-image-2 / gemini-2.5-flash-image / gemini-3.1-flash-image-preview |
优先级:环境变量
IMAGE_API_KEY> 配置文件api_key。两者都空时,出图跳过,gate 记录 “no key”。
它能接的活,大概分三类:
各种使用情况
| 类别 | 例子 |
|---|---|
| AI 会议纪要 · 收入看板 · OKR 管理 · 轻量 CRM | |
| PRD 生成 · Issue 自动分诊 · 代码审查 · 舆情分析 | |
| 给 React 加权限 · 给 Next.js 加多语言 · 给 FastAPI 加 OpenAPI |
它现在还不行的地方(也一并说了)
我不想只报喜。项目还在早期测试阶段,已知的短板:
-
greenfield(纯空想法)的深度有限:没有真实仓库接地时,接口契约这类只能给"草稿待核",不能当成定稿。
-
上限靠人:它保证规格结构和校验的下限,但方案够不够好、判断对不对,最终还是得你来拍板。
-
工程化完整产品仍在推进中:目前完整体验请优先用 Skill 包,工程化那版还在追。
但我觉得这个方向值得做下去——把"想清楚一个产品"这件事,做成人人五分钟可用、而且敢信的能力。
```text
<项目名>/
├─ spec_tree.json ← 结构源头;文档 / 矩阵 / 出图 全从它派生
├─ clarified_brief.json 目标 · 约束 · 带编号的成功标准
├─ route_options.json · selected_route.json · decision_mode.json
├─ traceability_matrix.json 可追溯矩阵:需求 ↔ 设计 ↔ 任务 ↔ 证据 ↔ 用例
├─ docs/
│ ├─ requirements.md · design.md · tasks.md
│ ├─ interface_contracts.md · test_cases.md · open_items.md
│ └─ prompt_pack.md · effect_preview.md · architecture.mmd
├─ checks_ledger.json 每道闸真跑的 脚本 + 退出码 + 输出(伪造不了)
├─ companion_log.json 伴随层留痕:挑刺者挑了啥 · 接地者引了哪些真实出处
├─ handoff_manifest.json 交付清单:每件产物带 来源 + 可信度 标
├─ previews/ 按模块的 UI 草样("预览·未验证")+ provenance.json
└─ scripts/ 确定性脚本——保下限的本体
├─ gate.py 台账包装器:跑任意校验并把结果记进台账
├─ validate_spec_tree.py 规格树校验:结构 · 覆盖 · EARS · 证据来源
├─ check_content_quality.py 文档校验:必备章节 · 篇幅 · 验收是 EARS
├─ check_companion.py 伴随层留痕必须为真
├─ finalize_previews.py 出图 gate:按模块出真图,以"真成功张数"判定(不看文件是否存在)
├─ check_previews_real.py 审计:揪出 假图 / 兜底 / 复制充数
├─ batch_images.py 独立批量生图
└─ fallback_tree.py LLM 不可用时产出天然合法的最小树
```
怎么确认它没糊弄你
-
checks_ledger.json— 跑了啥、退出码、输出。脚本自动写,伪造不了。 -
companion_log.json— 挑刺者挑了啥、接地者引了哪些真实出处。 -
来源标记 —
previews/*.png标"预览·未验证";interface_contracts.md标"草稿待核"。 -
check_previews_real.py— 一行命令告诉你:这批图是真生成的,还是占位充数。
## 🔄 工作流程
闭环路线按 v4 架构图来走:实线是主交付链路,虚线是运行时支撑、反馈、失效与回炉。
```text
用户想法 / 仓库 / 文件 / 截图
│
▼
01 输入层
原始输入 → GitHub 链接判断 → 深度解析或降级 → 归一化项目上下文
│
▼
02 澄清层
缺失信息 → 澄清问题 → 就绪度判断 → 带目标、约束、成功标准的澄清简报
│
▼
03 路线规划
标准 / 深度 / 升级路线 → 风险与成本对比 → 路线选择 → 轻量确认闸
│
▼
决策与协作
简单任务走单 Agent;复杂任务进入头脑风暴、多角色、综合器与工具代理
│
▼
04 规格树生成核心
提示词构造 → 脱敏 → LLM JSON → Schema 校验 → 不变量守卫 → 来源追踪 → SPEC 树
│
▼
05 规格文档
requirements.md · design.md · tasks.md,并回链验收、证据与测试用例
│
▼
06 效果预览与交付
提示词包 · 效果预览 · UI 草样 · Mermaid 架构图 · 可追溯矩阵 · ZIP/MD 导出
│
▼
评审与反馈闭环
通过就交付;不通过就回到澄清、路线、依赖失效与重新生成
```
运行时层伴随主链路工作:任务仓/产物仓、事件总线、Socket 推送、实时状态仓、节点状态派生和回放。质量门负责闭环收口:测试、内容质量校验、合并门槛,以及记录真实脚本输出的校验台账。
---
链接 & 欢迎来拍砖
-
 完整演示(TRAE Community Live NO.11):https://www.bilibili.com/video/BV1BbEA6RE8a
完整演示(TRAE Community Live NO.11):https://www.bilibili.com/video/BV1BbEA6RE8a -
 直接试:下载仓库
直接试:下载仓库 skills/whybuddy.zip,丢进 Trae 技能,给它一句话
项目开源、MIT 协议。坑肯定还有,觉得有点意思就点个 Star,更欢迎来提 issue 拍砖——你越较真,它的"下限"才越扎实。![]()
本作品由本人原创,基于全新 TRAE SOLO 开发,未参加过其他任何比赛;