系统体验地址:https://workbuddy-asd.preview.aliyun-zeabur.cn/ (注意要点击连接后端,否则体验的是不能调用模型的离线版本)

① 摘要
面向孤独症谱系障碍就业者 ,在工作现场提供“任务拆解导航 + 实时沟通翻译 + 情绪调节”支持,且可以根据障碍程度智能调整语速、工作步骤颗粒度和视/听觉展示。核心亮点是"沟通翻译"功能:用户输入"同事让我收拾垃圾",AI 即时翻译成可直接说出口的职场话术"好的,我来收拾",并语音朗读跟读,解决孤独症群体"不知道怎么说"的核心痛点。目前通过模拟工作场景测试验证,系统可在无专业辅导员在场的情况下,帮助用户独立完成多步骤任务并处理职场沟通。
系统整体截图如下(支持电脑+手机端)
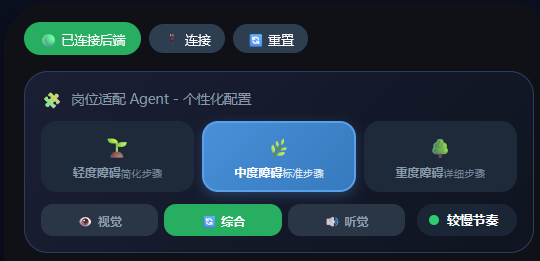

② 真实场景与需求
目标人群
轻度至重度孤独症谱系障碍就业者,已具备基本劳动能力,但在职场中需要持续支持。
痛点描述(具体到"一步任务/一次沟通")
-
任务执行:主管说"把货架整理好",用户不知道第一步该做什么、做到什么程度算完成
-
沟通表达:同事让帮忙搬东西,用户心里明白但嘴上不知道怎么说,要么沉默要么说错话
-
情绪调节:任务卡住时越来越焦虑,心跳加速,无法自行平复,最终情绪崩溃
-
岗位切换:从包装工调到补货员,需要重新学习整套流程,专业辅导员无法随时跟岗
本系统应对上述痛点所做的设计截图:
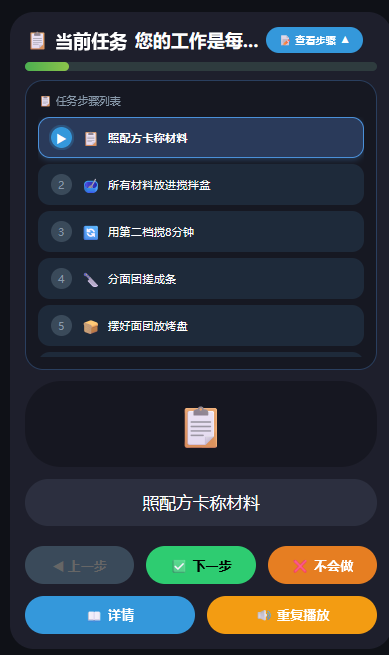
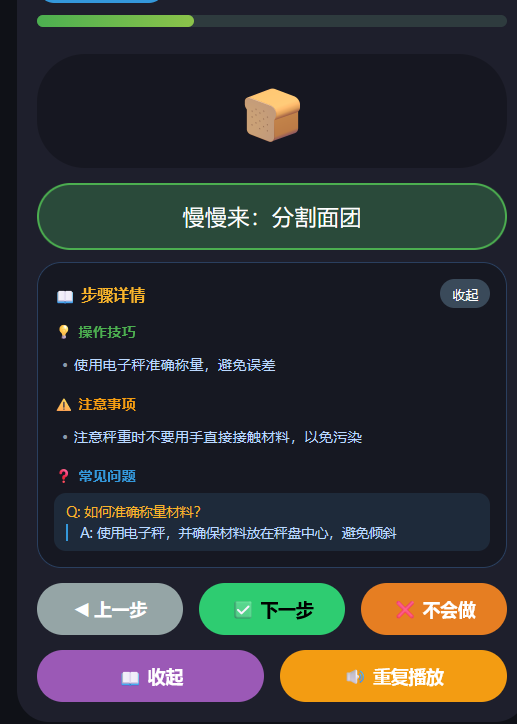
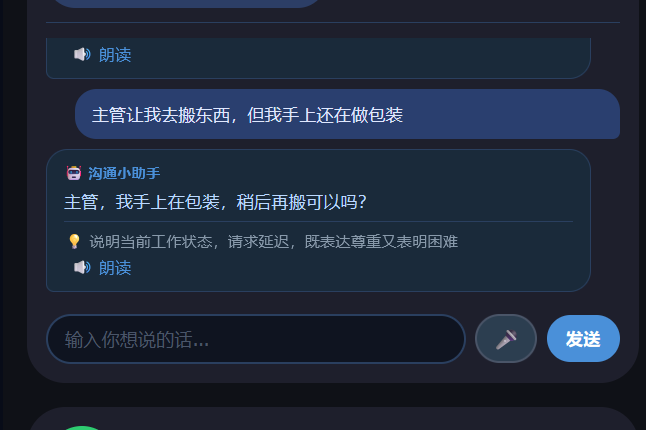
针对痛点一:用户可以知道工作的每一步需要做什么并可以反复练习,并有详情提示、简化步骤按钮(不会做)结合沟通小助手和情绪调节功能,可以更好地使用户快速上手工作
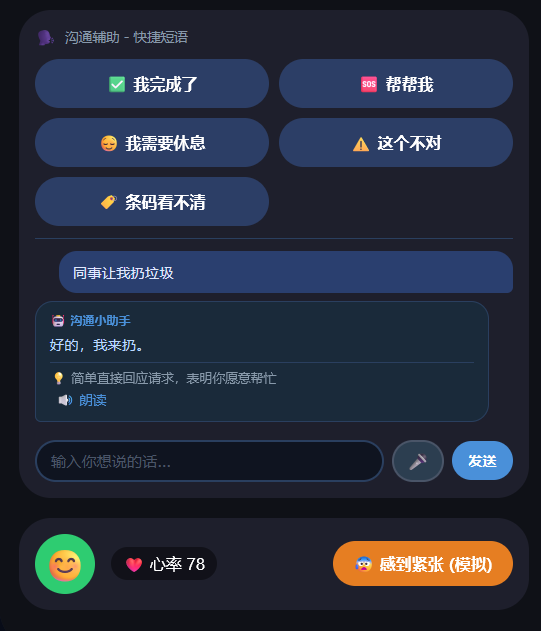
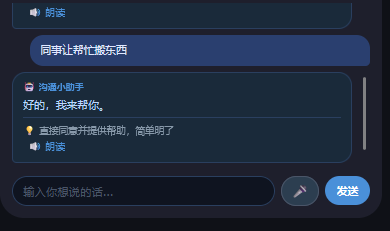
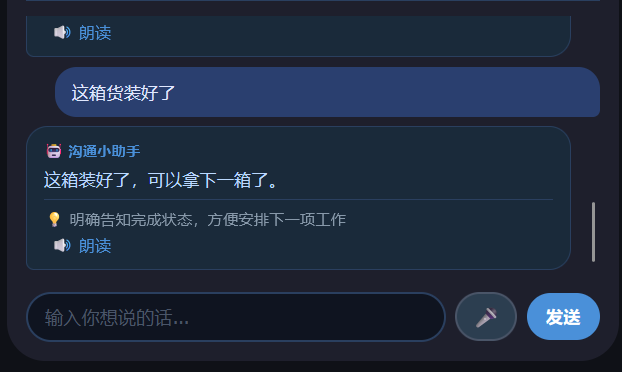
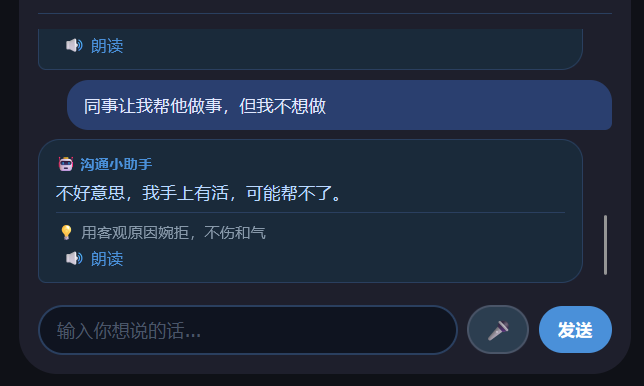
针对痛点二,系统可以将用户输入的自然语言(如"同事让我收拾垃圾"),AI 翻译成可直接说出口的话术,且生成的话术在听觉和综合模式下自动 TTS 朗读,用户可以直接跟着说,降低表达门槛。同时提供快捷话术本,高频场景一键播放,不需要每次都输入。
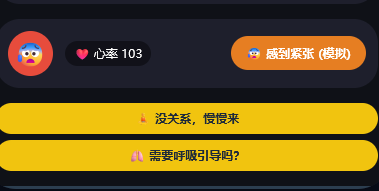
针对痛点三,该系统引入情绪调节agent,点击即可模拟用户紧张状态,系统自动调整语速、简化当前操作步骤并且语音播报安慰话语,且支持呼吸引导选项。
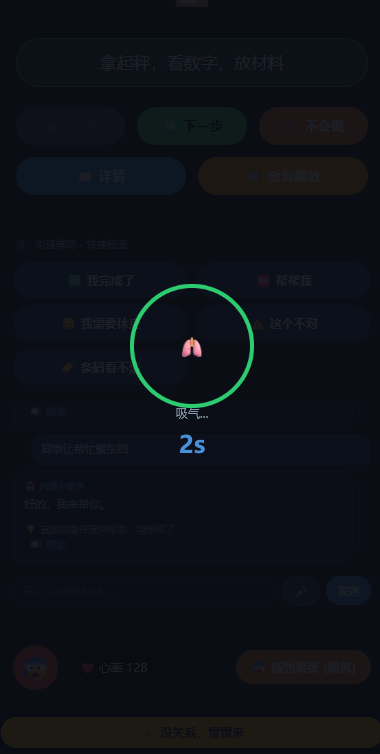
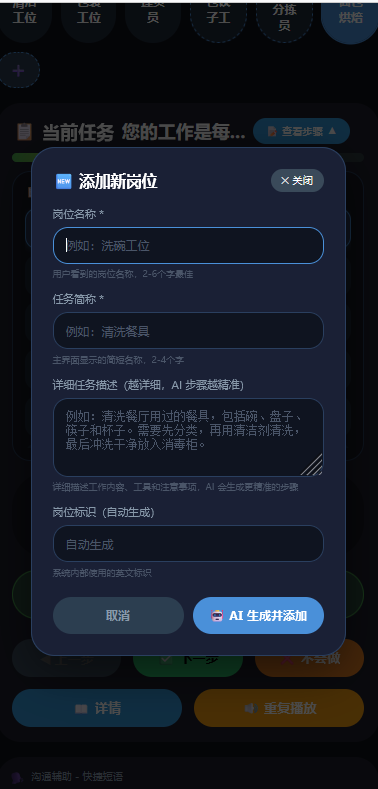
针对痛点四,用户可以轻松调换岗位的学习,且系统支持新增ai岗位,将工作步骤化并且适配不同患病程度的患者
现有做法为什么不够
-
人工跟岗辅导员:成本极高(1对1),无法规模化,且用户会产生依赖
-
传统纸质任务卡:静态、无法根据用户状态动态调整,沟通问题完全无法解决
-
通用 AI 聊天工具:不是"翻译"而是"陪聊",生成的安慰话用户无法直接拿来用
③ 作品介绍
WorkBuddy —— 孤独症多智能体现场工作陪伴助手
一个基于浏览器的 Web 应用,可在手机/平板上直接使用,无需安装。
核心功能:
-
岗位适配:预置包装工/清洁工/补货员,支持动态新增任意岗位(LLM 自动生成步骤),解决岗位切换时有支持的问题
-
任务拆解导航:将复杂任务拆成步骤,支持"上一步/下一步/查看详情/我不会",解决不知道第一步做什么的问题
-
沟通翻译:用户输入自然语言(如"同事让我收拾垃圾"),AI 翻译成可直接说出口且结合用户当前工作操作步骤的话术,解决不知道怎么说的问题
-
快捷话术本:每个岗位预置高频短语,点击即朗读,常见场景快速回应
-
情绪调节:感到紧张时一键降低语速、简化步骤、呼吸引导,解决情绪崩溃无法平复的问题
-
离线可用:LLM 不可用时自动降级为规则版本,核心功能不中断,适应现场网络不稳定的情况
双智能体架构设计
系统采用模块化多智能体设计,两个核心 Agent 各司其职,通过 AgentRouter 协调工作:
LLMJobAdapterAgent(岗位适配智能体)
负责"人"的适配:根据用户障碍程度自动调整步骤粒度、语速、节奏显示,同时承担沟通辅助(直接生成可以直接说出口的话术)和情绪调节功能。它解决的是"这个用户需要什么样的支持"的问题。
LLMTaskAgent(任务拆解智能体)
负责"事"的推进:管理任务步骤的导航、简化、详情展示,处理"上一步/下一步/我不会"等操作。它解决的是"当前这一步怎么做"的问题。
两个智能体如何协同工作
以用户完整的工作流程为例:
-
用户打开页面 → LLMJobAdapterAgent 初始化会话,加载默认配置
-
用户点击"清洁工"岗位 → LLMJobAdapterAgent 切换到对应岗位,加载步骤和快捷话术
-
显示第一步 → LLMTaskAgent 接管,展示步骤内容和进度条
-
用户卡住说"我不会" → LLMTaskAgent 触发步骤简化,LLMJobAdapterAgent 同时提供情绪安抚
-
用户说"同事让我递剪刀" → LLMJobAdapterAgent 识别为沟通场景,翻译成"好的,给你"并语音朗读
-
用户点"下一步" → LLMTaskAgent 进入第二步,更新进度
-
用户感到紧张 → LLMJobAdapterAgent 启动情绪调节:降低语速 + 简化步骤 + 呼吸引导
这种分工的优势在于:每个 Agent 只专注一类问题,逻辑清晰不纠缠;用户的一个操作可能触发多个 Agent 协作,但前端只收到统一的结果,体验流畅。
④ 用 SOLO 实现的过程
任务拆解
我把整个项目拆成 5 个阶段,用 Trae SOLO 逐一实现:
-
阶段1:基础框架 → 岗位切换 + 用户类型适配 + 步骤展示
-
阶段2:沟通辅助 → 对话翻译 + 快捷话术本 + 语音朗读
-
阶段3:任务增强 → 步骤简化 + 步骤详情 + 进度导航
-
阶段4:情绪支持 → 语速调节 + 呼吸引导 + 安抚语音
-
阶段5:稳定部署 → IP 限流 + 离线降级 + 错误处理
用了 SOLO 哪些能力
-
代码生成与补全:快速搭建前端 UI、后端 Agent 框架、WebSocket 通信
-
上下文理解:在修改提示词时,SOLO 能理解"沟通翻译"和"陪聊"的区别
-
多轮对话调试:沟通翻译的提示词调了 5 轮才达到效果,SOLO 能记住上下文持续优化
-
全栈开发支持:同时写前端 HTML/CSS/JS、后端 Python、Prompt 工程
关键 Prompt 设计(沟通翻译模块)
这是整个项目最核心的 Prompt,直接决定了"沟通辅助"是否可用:
核心角色定位:不是 AI 陪聊,而是"翻译官"
你是一个孤独症员工的沟通翻译助手。孤独症用户经常"不知道怎么说",你的任务是把用户想表达的意思翻译成一句可以直接对别人说出口的自然话术。
关键约束(踩坑后总结):
-
response 必须是用户自己的话,是用户对同事/主管说的,绝不能是 AI 对用户说话
-
必须是自然的口语,禁止书面套话(如"麻烦一下"、"您好"等生硬表达)
-
简短有力,不超过25字
-
礼貌但不过度客套,不卑不亢
少样本意图设计
沟通翻译的少样本示例不是随机设计的,而是基于孤独症员工在职场中最常见的 9 大意图场景:
-
help(需要帮助):“这一步不会做” → “请问这个该怎么做?”
-
rest(想要休息):“我需要休息” → “我需要休息一下,可以吗?”
-
frustrated(感到挫败):“又做错了,好烦” → “我做错了,能帮我看看哪里不对吗?”
-
happy(开心/完成):“终于做完了!” → “主管,我这个任务做完了!”
-
confused(困惑/不知道怎么办):“主管让我去搬东西,但我手上还在做包装” → “主管,我正在做包装,大概5分钟后去搬,可以吗?”
-
complete(完成任务):“这箱货装好了” → “这箱装好了,可以拿下一箱了。”
-
respond(回应别人的请求):“同事让我递一下剪刀” → “好的,给你。”
-
decline(婉拒别人的请求):“同事让我帮他做事,但我不想做” → “不好意思,我手上有活,可能帮不了。”
-
other(其他闲聊):“今天天气真好” → "是呀,今天天气真不错。
"这 9 个意图覆盖了孤独症员工在职场中 90% 以上的沟通场景。通过 Few-Shot 示例,LLM 能准确识别用户想表达的真实意图,并生成符合职场语境的自然话术,而不是机械地匹配关键词。
部分小助手测试截图如下:
大模型动态生成内容的优势
系统中多处内容由大模型动态生成,相比预置规则有显著优势:
-
新增岗位步骤生成:用户输入任意岗位名称和描述,LLM 自动生成 3 种难度版本的步骤(简化版/标准版/详细版)。好处是无需为每个岗位人工编写步骤,系统可无限扩展岗位类型,适应不同工作场景。
-
步骤详情生成:点击"查看详情"时,LLM 根据当前步骤实时生成操作技巧、注意事项、常见问题。好处是内容针对性强,比预置的通用提示更贴合具体步骤。
-
步骤简化生成:用户说"我不会"时,LLM 根据用户类型和卡住次数动态调整简化策略。好处是同样"不会",轻度用户得到的是动作分解,重度用户得到的是更细致的指导,实现真正的个性化。
沟通小助手的核心优势
相比通用 AI 聊天工具,本系统的沟通翻译有 4 个显著优点:
-
输出可直接使用:生成的话术是"用户对同事/主管说的话",不是 AI 安慰用户的话。用户可以直接照着说,不需要二次加工。
-
口语化自然表达:通过"禁止书面套话"约束和 Few-Shot 示例,输出的是"好的,给你"而不是"您好,麻烦您稍等一下",符合孤独症用户的表达习惯。
-
意图识别精准:基于 9 大职场意图设计,能区分"需要帮助"和"想要休息"、“感到挫败"和"想要婉拒”,不会把"同事让我收拾垃圾"误解为"用户不想做"。
-
配套语音朗读:生成的话术自动 TTS 朗读,用户可以直接跟着说,降低表达门槛。同时提供快捷话术本,高频场景一键播放,不需要每次都输入。
中间踩过的坑
-
AI 变成"安慰者":用户说"同事让我收拾垃圾",AI 回复"我理解你的感受…" → 在 Prompt 里加死约束:response 必须是用户对同事/主管说的话
-
话术太书面:输出"您好,麻烦您稍等一下" → 加约束:禁止书面套话,Few-Shot 示例全部用口语
-
快捷短语定位不清:一开始想做成"智能推荐",结果推荐的不准 → 改为"话术点播器",预置高频短语,点击即朗读
-
离线模式没声音:"上一步/下一步"按钮在离线时没语音 → 在前端离线处理函数里补上了 speakText() 调用
-
步骤显示异常:"查看步骤"点开空白 → 后端返回完整步骤列表,前端增加缓存机制
-
新建岗位生成太慢:一开始 LLM 同时生成 3 种难度版本的步骤,用户要等 10 秒以上 → 改为"按需生成":先只生成当前用户类型对应的版本,切换用户类型时再动态补生成其他版本,响应时间降到 3 秒内
-
步骤简化与情绪调节耦合:一开始 LLMTaskAgent 处理"我不会"时只简化步骤,没有通知 LLMJobAdapterAgent 提供情绪安抚 → 改为双 Agent 协作:TaskAgent 处理步骤简化,同时触发 JobAdapterAgent 的情绪支持,用户体验更完整
-
步骤详情缓存缺失:每次点击"查看详情"都调 LLM,重复请求浪费 token 且慢 → 改为"生成一次即缓存",同一岗位同一版本的步骤详情只生成一次,后续直接读取缓存
⑤ 成果展示
技术架构
前端(demo-backend.html):
-
岗位切换 + 用户类型适配
-
任务区域(步骤导航 + 进度条)
-
沟通辅助区(对话翻译 + 快捷话术本)
-
情绪调节(语速控制 + 呼吸引导)
后端(Python FastAPI + WebSocket):
-
AgentRouter(统一协调)
-
LLMJobAdapterAgent(岗位适配 + 沟通辅助)
-
LLMTaskAgent(任务拆解 + 步骤导航)
-
降级 Agent(LLM 不可用时保底)
-
IP 限流中间件(防止滥用)