很多 AI 项目不是死在模型上,而是死在“只有研发能看懂,现场人员根本用不起来”。
这次我做的项目,背景很典型:这是一个水处理项目,核心工艺是****混凝沉淀**。在混凝沉淀过程中,**矾花状态****是判断工艺运行是否正常的重要标准。矾花成形好不好、大小是否稳定、出水是否清澈,往往直接影响运行人员对工艺状态的判断。
问题在于,这件事长期依赖人工经验。人可以看,但不能 24 小时持续看;而且不同项目水质、设备、光照条件都不一样,算法往往需要****针对单个项目定制****。这就意味着两件事必须同时成立:
- 算法开发成本要可控
- 用户界面要简洁直白,方便运营人员快速查看
这个智能化项目,本质上就是把“工艺老师傅的经验判断”变成一个可持续运行的网页系统:利用图像识别在线监控矾花和出水状态,并把结果稳定地展示出来。
## 这个系统要做什么
需求并不花哨,但很完整。
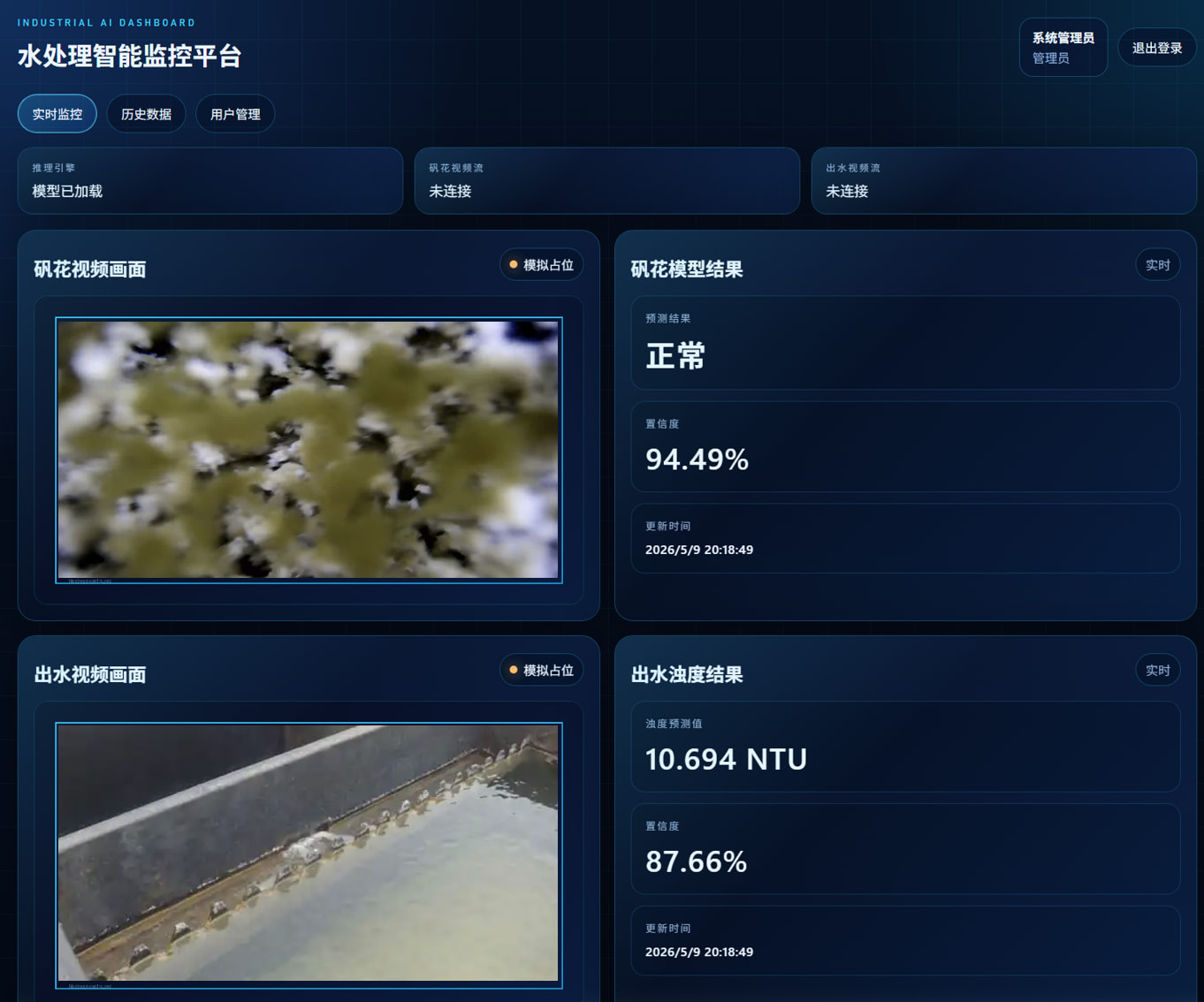
- 实时显示矾花和出水两个监控画面
- 展示矾花识别结果、出水浊度预测结果和对应置信度
- 保存最近 7 天历史数据,按 1 小时间隔留档
- 提供基础用户管理
- 最终部署到腾讯 Lighthouse Linux 服务器
页面结构也很明确,分成三个标签页:
- 实时监控
- 历史数据
- 用户管理
这类项目真正难的地方,不是“能不能做一个模型”,而是****怎么把模型、视频流、历史数据和用户系统拼成一个能上线的产品****。
## 为什么我没有上很重的前后端架构
如果直接上大前端、大数据库、复杂流媒体和一堆中间件,当然也能做,但项目会很快从“解决业务问题”变成“维护工程复杂度”。尤其是这种需要为单项目定制算法的场景,成本控制非常重要,工程方案必须务实。
所以我最后选的是一套偏轻量、但足够能打通交付链路的方案:
- 前端:Jinja 模板 + 原生 JavaScript
- 后端:FastAPI
- 推理:直接复用现有 TensorFlow 模型
- 视频:OpenCV 读取并输出 MJPEG
- 历史数据:SQLite
- 部署:systemd + nginx + 腾讯 Lighthouse
## 我具体做了什么
首先,将项目现场实际收集到的图像数据快速打标,使用VGG16搭建了图像识别模型。以往预处理数据、写代码、训练模型至少需要2~3天的时间,现在使用Trae SOLO一小时全部搞定。
接着把实时视频流拉进来,跑通实时预测。
最后,也是我作为一个环保工程师以前很难自己完成的步骤,将上述视频监控和后端模型做成网页,方便运营人员查看。
- 登录页和会话鉴权
- 实时监控页
- 历史数据页
- 用户管理页
- 后台推理与存储服务
实时监控部分,后端负责取视频帧、执行模型推理,再把最新状态通过接口返回给前端。历史数据部分,系统每小时保存一条记录,并保留最近 7 天。用户管理部分则提供管理员和观察员两种基础角色。
界面上,我按“深蓝色科技风”的方向去做,而是做成更接近工业监控台的视觉风格。因为这种系统面对的不是互联网用户,而是现场运营和工艺人员,界面必须一眼能看懂。
## 最后怎么把它准备成可上线状态
我不想让这个项目停留在“本地能跑”。所以后面又把云服务器的部署链路一并补齐了,包括:
- 依赖安装文件
- systemd 服务文件
- nginx 配置
- 环境变量模板
- 一键安装脚本
- 本地打包脚本
也就是说,这个项目现在不是一个单纯的 AI Demo,而是一套已经具备上线形态的应用原型。
下面这几张图,就是这次实际做出来的网页界面。
## 这个案例的价值不在“模型”,而在“交付”
我觉得这类 AI 项目最值得讲的地方,不是模型多复杂,而是它把一段原本分散的工艺经验,变成了一个可被现场人员使用的系统。
对于水处理这样的场景,这种价值非常实际:
- 帮助运行人员更稳定地观察矾花与出水状态
- 降低完全依赖人工盯守的压力
- 让算法交付成本保持在可控范围内
- 让“项目定制算法”有一个标准化落地界面
如果说模型解决的是“能不能识别”,那这个网页解决的就是“识别结果怎么真正被用起来”。
这也是我认为 AI 应用案例里,最值得被拿出来分享的部分。