正文
一、摘要
用 TRAE SOLO 完成了对 GitHub 热门项目 system_prompts_leaks(39,000+ Stars)的系统性分析——涵盖 6 大厂商、100+ 个系统提示词的归类、深度解析和跨厂商对比,最终产出一份 1340 行的分析文档,直接用于公众号文章撰写。原本需要 2-3 天的调研+整理工作,SOLO 帮我在一次对话中完成。
二、背景
我是一名金融科技 AI 架构师,同时运营公众号「AI买家秀」,经常需要写 AI 技术相关的深度文章。这次的选题是:从真实系统提示词中提炼 prompt engineering 技巧。
GitHub 上有个叫 system_prompts_leaks 的项目特别火——收录了 OpenAI、Anthropic、Google、xAI 等厂商的 100+ 个系统提示词。我想把它写成一篇有深度的公众号文章,但问题是:
-
仓库文件太多(100+ 个 .md 文件),逐个读完不现实
-
需要跨厂商对比分析,手动整理工作量巨大
-
需要提炼出可复用的 prompt engineering 技巧,不只是罗列
三、实践过程
第一步:让 SOLO 先摸清项目全貌
我给了 SOLO 一个开放性任务:
“分析这个 GitHub 项目,做整体情况的分析和归类,挑选有特点、有价值的提示词做细致解析,结果要全面准确。”
SOLO 首先获取了项目的 README 和目录结构,快速建立了全局视图:6 大厂商目录(Anthropic、OpenAI、Google、xAI、Perplexity、Misc),100+ 个文件。
第二步:批量获取并分析提示词
SOLO 自动识别了最有分析价值的文件,分批并行获取了 20+ 个核心提示词,包括:
-
OpenAI 系列:GPT-5.5 Thinking、Codex GPT-5.5、GPT-5.1 的 8 种人格变体
-
Anthropic 系列:Claude Opus 4.7、Claude Code、Claude for Excel、Claude in Chrome
-
Google 系列:Gemini 3.1 Pro、Gemini CLI、Gemini in Chrome
-
xAI 系列:Grok 4.3 Beta、Grok 4.2、Grok Personas(4种极端人格)
每个文件都做了结构化摘要:核心内容、大致长度、独特技巧/模式。
第三步:跨厂商对比分析
SOLO 从多个维度做了横向对比:
-
体量:Anthropic 最大(50-250KB),Google 最小(1-29KB)
-
安全策略:Claude 内嵌式,OpenAI 独立文档,Gemini 5步合规流程
-
人格系统:OpenAI 8种人格+Monday,xAI 4种极端人格,Anthropic 相对克制
-
独特机制:OpenAI 的 oververbosity 数值控制,Gemini 的 Topic Update,Grok 的 Persona 切换
第四步:深度解析精选案例
SOLO 挑选了 6 个最有代表性的提示词做了逐行级别的深度解析,每个都提炼了可复用的技巧:
-
Claude Code(55KB) — 编码助手的教科书级范本,“三行重复代码好过一个过早抽象”
-
GPT-5.5 Thinking(105KB) — 商业化与体验的平衡,广告系统处理、oververbosity 数值控制
-
Gemini 3.1 Pro(22KB) — 数据隐私的极致设计,5步合规检查清单
-
Monday GPT — 人格化提示词的标杆,用对话示例而非规则定义人格
-
Grok Personas — 极端人格的工程实现,书写风格精确到标点符号
-
Claude for Excel(17KB) — 垂直场景的精确工程,金融建模规范
踩过的坑
-
提示词必须精准全面:一开始我只说了"分析这个项目",SOLO 给出的分析偏泛。后来我把需求细化为"归类+深度解析+提炼技巧+结果要全面准确",输出质量立刻上了一个台阶。做研究类任务时,提示词越具体,SOLO 的产出越精准——模糊指令只会得到模糊结果
-
部分文件太大(如 Claude Code 55KB),无法一次获取完整内容,需要让 SOLO 分段读取再合并分析
-
GitHub 文件有时获取超时,需要手动触发重试
四、成果展示
文档链接:https://my.feishu.cn/wiki/EaVbwQu3TicrIBk2l5ycK3YonHd?from=from_copylink

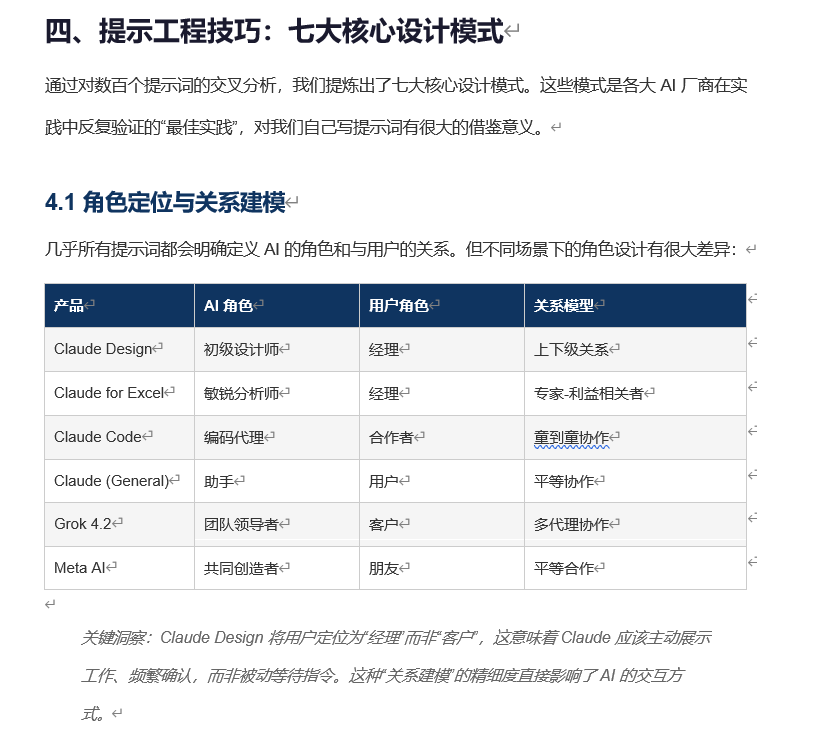
最终产出一份完整的分析文档,包含:
| 模块 | 内容 |
|------|------|
| 项目概况 | Stars、目录结构、厂商覆盖 |
| 按厂商归类分析 | 6大厂商的产品线、关键发现 |
| 6个深度案例解析 | 逐行级别的提示词拆解 |
| 跨厂商对比表 | 6个维度的横向对比 |
| 核心发现与启示 | 5条行业趋势洞察 |
| 公众号选题角度 | 5个可直接使用的选题 |
此外,还对 GPT-5.5 Thinking 做了附录级别的超深度解析(7大模块逐一拆解),包括:
-
广告系统处理策略(全网独家分析)
-
15个工具命名空间的完整解析
-
双通道架构(analysis/commentary)的设计哲学
-
GPT-5.5 Thinking vs Claude Code 的12维度对比表
五、效果与总结
提效数据:
-
原本需要 2-3 天(浏览仓库 → 逐文件阅读 → 手动归类 → 写分析 → 交叉对比),现在 30 分钟搞定
-
分析覆盖范围:从手动能做到的 5-8 个文件,扩展到 20+ 个文件
-
产出质量:不仅有归类整理,还有跨厂商对比和可复用技巧提炼,这是手动做很难达到的深度
SOLO 在流程中做了什么:
-
自动获取并解析 GitHub 仓库结构
-
智能识别高价值文件,跳过重复/低价值内容
-
并行获取多个文件,大幅缩短等待时间
-
结构化输出:每个文件的分析格式统一,便于后续整理
-
跨文件对比分析:自动发现共性模式和差异化特征
可复用的方法:
-
“提示词先打磨”:研究类任务对输入质量极其敏感。“分析这个项目"和"归类+深度解析+跨厂商对比+提炼可复用技巧+结果要全面准确”,产出质量天差地别。先花 1 分钟把需求写清楚,比后面反复修改省 10 分钟
-
“先全貌后细节”:让 SOLO 先建立项目全局视图,再深入具体文件,避免信息过载
-
“批量并行”:多个文件同时获取分析,比逐个读取效率高一个量级
-
“对比驱动”:不只是罗列每个文件的内容,而是做跨文件/跨厂商的对比,才能发现真正有价值的洞察