【Code With SOLO】用 SOLO 开发中国象棋识别系统 V5.0,实现 PDF 批量转 FEN 棋谱自动化
![]() 正文内容
正文内容
-
摘要:
我开发了一款基于深度学习的中国象棋识别系统 V5.0,它能从图片或 PDF 文档中自动提取棋盘并生成标准 FEN 格式。通过集成 YOLOv5 算法与批量处理引擎,解决了传统手动录入棋谱耗时费力的问题,实现了从“看图”到“出谱”的全流程自动化。 -
背景:
我是一名象棋软件开发者,经常需要整理大量的古谱 PDF 和线上对局截图。原本手动在软件上摆盘、记录每一步棋需要数小时,且容易出错。为了提升效率,我希望利用 SOLO 构建一个能“看懂”棋盘的工具,特别是针对 PDF 文档的批量提取功能,以解放双手。 -
实践过程:
这是本项目的核心,我利用 SOLO 辅助完成了从算法优化到工程落地的全过程:
* 任务拆解与架构设计:我将任务分为“图像预处理”、“棋子识别”和“数据后处理”三个模块。利用 SOLO 梳理了从 PDF 提取图片到最终生成 PGN 的逻辑链路。
* 算法优化(SOLO 辅助编码):
* 棋盘检测增强:针对复杂背景,我让 SOLO 协助编写了动态内核大小的边缘检测算法,并加入了边框合并逻辑,解决了棋盘断线导致的分割失败问题。
* 置信度分级:引入了智能判断机制,当识别置信度低于 60% 时,系统会自动标记警告(),方便人工二次核对。
* 功能实现与交互:
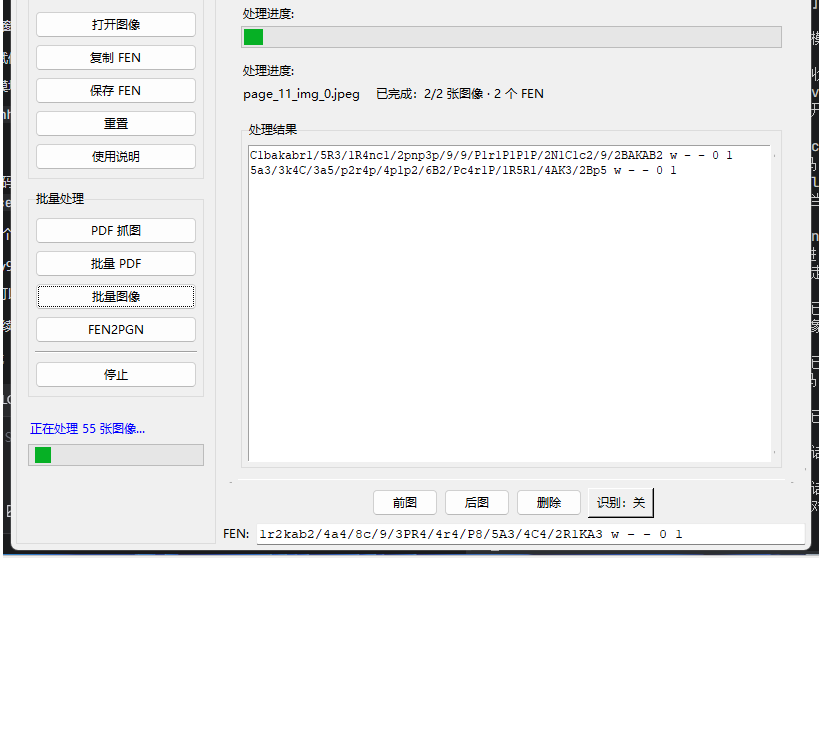
* 批量处理引擎:开发了预读取队列技术,让 CPU 在后台提前加载下一张图片,使批量处理速度提升了 1.5-2 倍。
* 快捷键映射:实现了 F1 帮助、左右方向键浏览等便捷操作,优化了用户体验。
* 踩坑与解决:在处理中文路径的 PDF 时曾遇到乱码问题,通过 SOLO 查找相关库的编码参数,最终实现了全路径的中文兼容。
- 成果展示:
中国象棋识别系统 V5.0 已正式发布
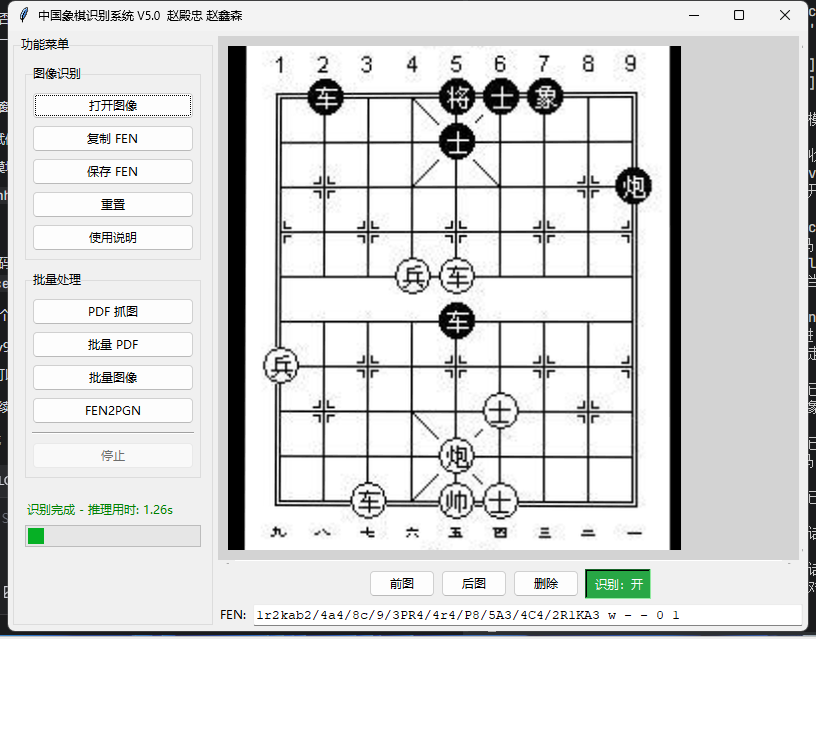
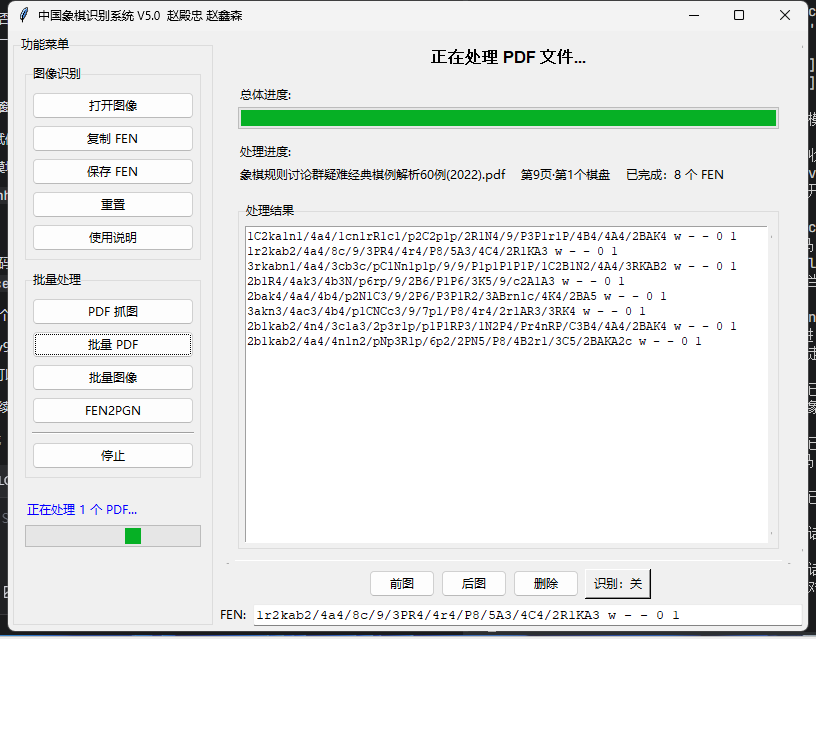
* 单图/批量识别:支持 JPG/PNG 及 PDF 批量转 FEN,结果自动保存至 output 文件夹。
* 智能报告:自动生成包含置信度的文本报告,低质量识别结果一目了然。
* FEN2PGN 转换:内置转换工具,直接将识别结果转为通用棋谱格式。
* 独立运行:基于 PyInstaller 打包,无需 Python 环境,双击即可运行。
[
]
- 效果与总结:
* 提效显著:原本整理一份包含 50 个残局的 PDF 文档需要 2 小时,现在仅需 5 分钟(含核对时间),效率提升约 20 倍。
* SOLO 的价值:SOLO 在编写 OpenCV 图像处理逻辑和调试 PyQt 界面交互时发挥了巨大作用,它帮我快速生成了大量样板代码,让我能专注于核心算法的调优。
* 可复用经验:这种“预读取队列 + 动态置信度阈值”的处理模式,完全可以复用到其他文档数字化(OCR)场景中。