s^τ:给注意力装上焦距旋钮 —— 一个可替代 softmax 的幂律归一化框架
用 TRAE SOLO 从零推导了一套可替代 softmax 的幂律注意力归一化框架 s^τ。在 Qwen3-1.7B 上零训练替换生成质量严格对齐,微调 PPL 一致、注意力更稀疏。全程数学推导 + CUDA 算子手写 + 多场景验证,踩坑无数,但也挖出了不少有意思的信号。
中职单招考试考完的假期总是无聊的,要在家里硬蹲整整4个月就非常的无聊,游戏呢不想玩视频不好刷,非常非常无聊。
我闲太无聊,再一次出门逛街时我突然想到,有没有一种可以替代softmax的方案,尝试从当前的大模型底层注意力机制下手,用了3周时间,手搓出来一个归一化函数框架(无聊到顶了)
用了两周时间我们推导并工程实现出了一套注意力,这个注意力很反直觉,在我们想出来归一化注入方式并投入实验查看推理生成质量时,这东西有力气!在ppl层面不仅微弱超过softmax,且模型本身的生成质量严格与softmax对齐,这是很反直觉的,一般情况下直接替换归一化是不可能保证这么好的生成质量的,但是他就这么出现了,对的,当时我和solo code交流排查很久,确定不是代码逻辑问题而是自带的属性。准确来说,是我们的余弦相似度工程和统计量工程,即
τ* = Cov(s, log φ(s)) / Var(log φ(s))
因为在一些情况,我们的归一化框架在概率分布上是与softmax近似等价的,也就是可以反向的推出模型每一个atth-hand的τ值。这个推出的hand-τ值可以作为零训练的模型归一化注入的初始值;也可以作为微调训练的τ初始化值。等等,貌似我们没说到重点。
重点在这,我们将这个归一化方法称为s^τ,对的,就是s^τ,核心公式即
a_i = φ(s_i)^τ / Σ_j φ(s_j)^τ
φ(s) = softplus(s) + ε
τ = softplus(log_τ) + 1
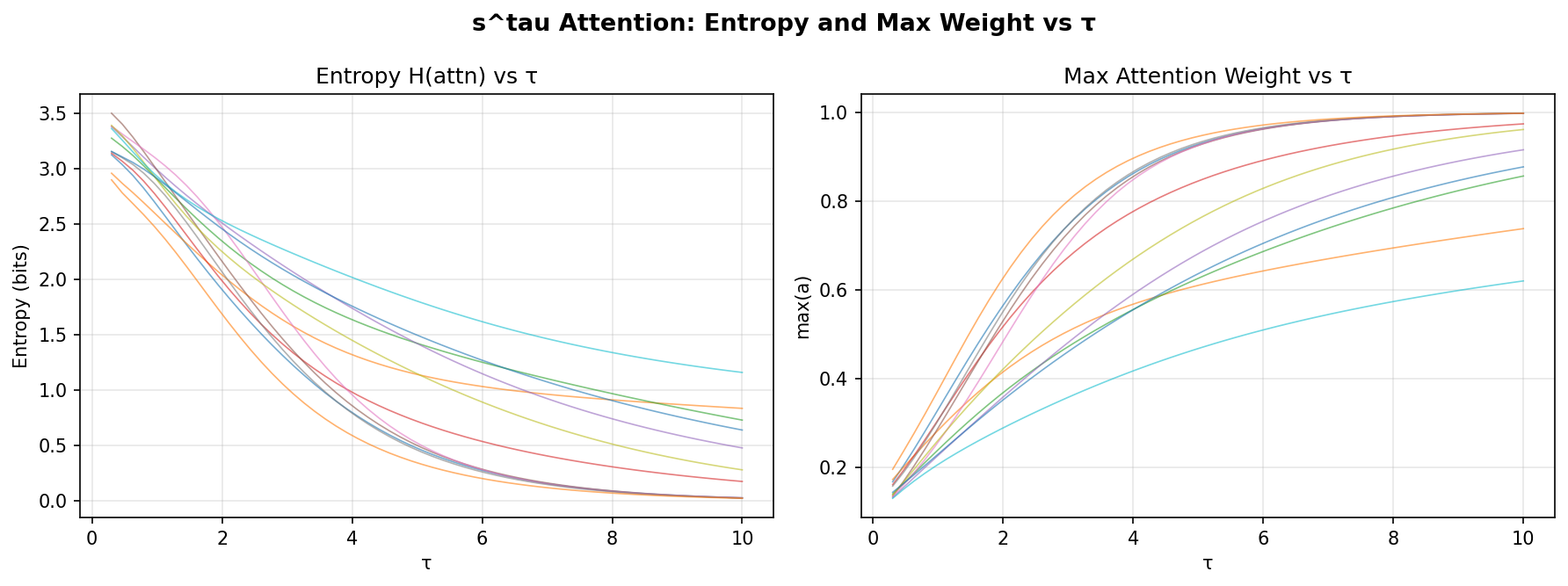
说白了就是给注意力分数套了个 softplus 再取 τ 次幂,代替原来的 softmax 归一化。τ 是一个每头可学习的参数,控制注意力的"锐度"——τ 越大注意力越聚焦,τ 越小越分散。
不抽象,其实很物理——想想就通了。softplus 保证输出 ≥ ε > 0(不会像 softmax 那样被 exp(-100) 直接压到零),然后 τ 作为幂次。τ 越大 → 指数越高 → 大值和小值之间的差距被指数级放大:
τ=1: 100¹=100, 10¹=10, 1¹=1 → 三者都活着
τ=5: 100⁵=10¹⁰, 10⁵=10⁵, 1⁵=1 → 中间的被压扁
τ=20: 100²⁰=10⁴⁰, 10²⁰=10²⁰, 1²⁰=1 → 只剩最大的那个
τ 上升 → 只有最大的那少数几个 score 在归一化后还活着 → 注意力更稀疏,只盯关键 token。
用大白话说:τ 是注意力焦点的"焦距旋钮"。τ=1 是广角镜,什么都能看到;τ=20 是长焦,只盯一个点。softmax 的 exp 天然就是某个固定焦距——约等于 τ≈2.5 时的 s^τ。s^τ 给了每个注意力头选择自己焦距的自由,softmax 只能所有人用一个固定焦距。
这也解释了为什么最优 τ 对每个头都不同:有些头需要广角(查语法结构、感知全局上下文),有些需要长焦(锁定具体实体、精确指代消解)。
为什么能无缝替换 softmax?
数学上最重要的发现是,s^τ 和 softmax 其实是双向等价的:
s^τ 的注意力权重 a_i = φ(s_i)^τ / Σ φ(s_j)^τ
能等价写成 softmax a_i = exp(σ_i) / Σ exp(σ_j)
其中 σ_i = τ · log φ(s_i) + C
反过来 softmax 也可以等价写成 s^τ,但 s^τ 多了一个 τ 可调。所以 s^τ 其实是 softmax 的超集,自由度更大。
那 τ 怎么取值才能让 s^τ 最接近 softmax?直接从等价性推导就出来了一个闭式解:
τ* = Cov(s, log φ(s)) / Var(log φ(s))
Cov/Var 就是协方差除以方差,一次前向传播拿到分数分布后,O(1) 就算出每个注意力头的最优 τ,不需要网格搜索。这就解释了为什么零训练替换也能对齐 softmax 的生成质量——因为 τ* 本身就是从等价性定理精准推导出来的。
踩过的坑
不过这里有个坑,一开始我也以为一个 τ 就能通吃所有头,结果拿 τ=4.0 全局替换试了一下——生成直接崩了,问"光合作用"模型疯狂复读"光"字,30 个 token 全是光。后来才发现每个注意力头的 QK 分布差很多,浅层头和中层头的 τ 能差好几倍。所以要逐头算 τ*,不能偷懒。

这个闭式解也不是万能的。在小模型(64M 欠训练那种)上试过,stat τ* 的 PPL 直接飙到 1280,比 softmax 的 568 还差一倍。后来查明白了——公式假设 QK 分数分布是有结构的,充分训练的模型才有这个结构,欠训练模型的分数是乱的,线性假设不成立。
s^τ 的价值:等价,但多一个自由度
所以 s^τ 的价值到底在哪?不是"比 softmax 强",而是"等价但多一个自由度"。替换后 PPL 不变、生成质量不变、训练收敛路径不变——但注意力分布确实变稀疏了,而且手里多了 τ 这个旋钮可以调。这个自由度在长序列、模型诊断、注意力控制这些方向有没有用,目前还是开放问题,但框架已经搭好了。
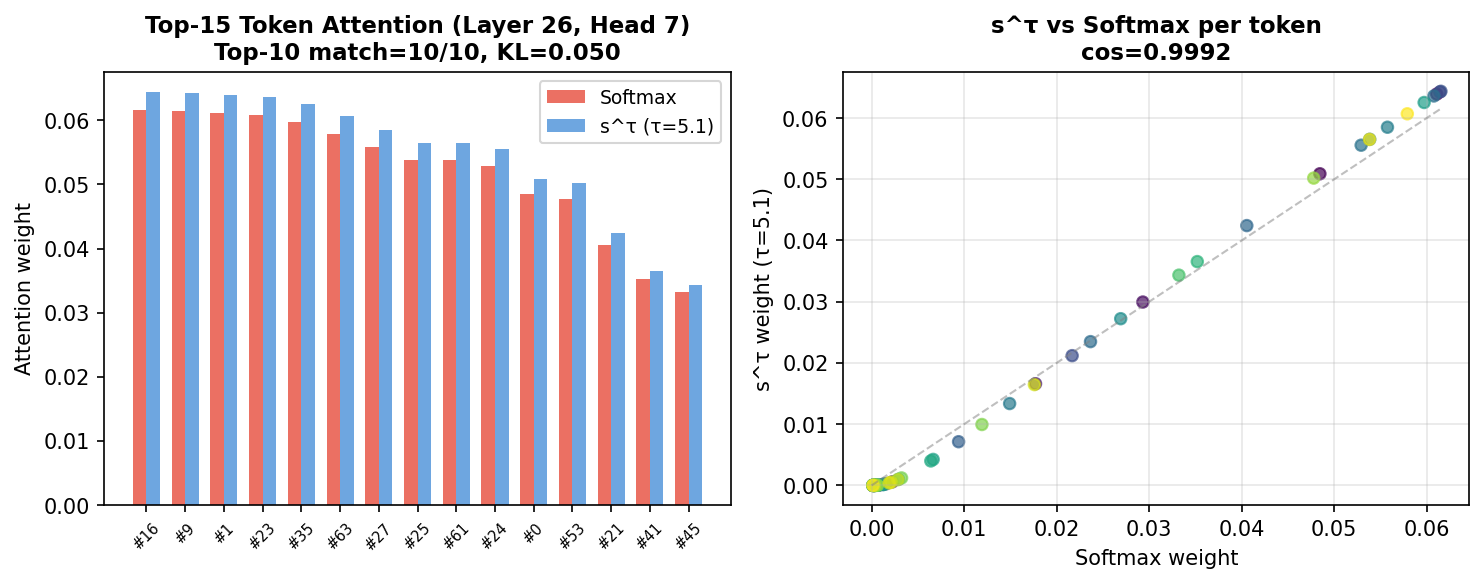
验证:Qwen3-1.7B 微调对比
为了验证这东西在实际微调中能不能用,我们在 Qwen3-1.7B 上跑了 2000 步微调。用统计 τ* 初始化,跟 softmax 同数据同超参对比:
-
最终 PPL:Softmax 1.127,s^τ 1.127(完全一致)
-
训练速度:Softmax 7.47 it/s,s^τ 7.58 it/s
-
显存:Softmax 11.0 GB,s^τ 11.0 GB
-
注意力稀疏度 (<1e-6):s^τ 比基线 +14%
-
top-10 集中度:s^τ 比基线 +2.7%
-
均值注意力权重:s^τ 比基线 -8.5%
PPL 完全一致,速度还快了一丁点。整个训练过程中 PPL 差异始终在 ±0.02 以内,收敛轨迹高度重合。而且 s^τ 这边 τ 是用闭式解直接算的,不参与梯度更新,零额外参数。
微调完后对比注意力分布,s^τ 的注意力比 softmax 稀疏了 14%,top-10 集中度高了 2.7%。PPL 一样,但注意力把钱花到了更少的 token 上——这个差异在更长序列里会不会放大,还没测,但值得关注。
注意稀疏度提升什么意思呢?就是 s^τ 在做注意力加权的时候,更多权重集中在少数关键 token 上,大量不相关的 token 直接被忽略(注意力权重 < 1e-6)。这跟 softmax 那种"雨露均沾"的风格不太一样——softmax 的 exp 天然给每个 token 留了一份"面子分",而 s^τ 的幂函数在 τ 增大时把大值和小值的差距指数级放大,高分的越来越高、低分的直接压到接近零。
有什么用?注意力更稀疏意味着模型在做决策时更"果断",只盯着重要的 token 看。这对可解释性是好事——你更容易看出模型到底在关注什么。另外一个潜在信号是,稀疏注意力可能天然更适合长序列——token 多了以后,softmax 被迫把越来越小的权重分给越来越多的 token,而 s^τ 可以直接不看了。当然这只是猜测,还没验证。
还有一点要说清楚,2000 步远没跑到稀疏度的极限。当时远端卡快没钱了,将就跑了这一点就停了,这不是最优收敛点的数据。
SOLO 在这项目里到底干了什么
一个中职生单挑大模型底层架构,说没有 AI 帮忙是不可能的。以下几个关键环节都是 SOLO 陪我走的:
1. 数学推导与理论扩展
数学上面最硬的两块——等价性定理和闭式解 τ*——是 SOLO 帮我一步一步推出来的。等价性定理(s^τ ↔ softmax 双向解析映射)是我提方向,SOLO 做代数恒等变换验证。闭式解 τ* = Cov/Var 本质上是 OLS 线性回归解,这种推导对我来说完全抓瞎,SOLO 从等价性出发帮我理清了这个线性假设,最终推出来的公式在 Qwen3-1.7B 上跟网格搜索 250 点的相关系数 r=0.97。
后来发现 tempered softmax(把 τ 直接乘进 softmax 里,softmax(τ·s)) 在因果 mask 下产生 NaN 的时候,SOLO 帮我追溯到 IEEE 754 标准——a_i·s_i = 0·(-∞) = NaN,这是公式层面的死锁,FP64 也无解。相比 s^τ 用 softplus+clamp 制造了一个数值防火墙,-∞ 进去出来也是有限的 -18,不会爆 NaN。这个排查要是没有 SOLO 帮我看,我可能到现在还以为是自己代码写错了。
2. CUDA 算子从 v1 写到 v10
项目里最大量的工程活就是手写 CUDA kernel。SOLO 帮我写了前向+反向的 C++ 内联内核,包括 __half2 向量化、warp-shuffle 归约、mask/dropout 融合、causal mask 直接注入 kernel 里等等。效果怎么说呢——s^τ 计算比标准 softmax 多了 softplus+log+tau grad 三步数学,最终只慢了不到 20%,长序列(Lk≥1024)下融合版甚至反超 cuDNN:
-
L=128:cuDNN 0.34ms,s^τ 0.40ms(1.17×)
-
L=512:cuDNN 0.34ms,s^τ 0.41ms(1.21×)
-
L=1024:cuDNN 0.32ms,s^τ 0.41ms(1.28×)
-
L=2048:cuDNN 0.51ms,s^τ 0.56ms(1.10×)
-
L=4096:cuDNN 1.18ms,s^τ 1.24ms(1.05×)
长序列差距越来越小——框架是高质量的,纯粹是 softplus+log 那点数学开销。(没这少
3. 踩了一堆坑
说真从一开始踩到现在没停过。前面提的 tempered-softmax-NaN(公式已否决)、单 τ 全局替换失败("光光光"退化)、FP8 手写六连坑(最终证实纯 BF16 最优)、char-level 数据 τ 梯度过小导致不学(后来发现是 PPL 阈值定理 < 20 就学不动)……每一个坑都是 SOLO 跟我一起排查搞定的。
4. 多场景交叉验证
一个框架只在一种模型上跑一次是不敢拿出来说的。我们验证了这几个场景:
-
Qwen3-1.7B 零训练推理:stat τ* PPL=2.556 vs softmax 2.630,87.9% token match
-
Qwen3-1.7B 微调 2000 步:PPL 完全一致,注意力稀疏 +14%
-
SDXL(Illustrious-XL,2600 头):61.5% 的头天然 τ<1.3 —— UNet 的自注意力天生适合 pow
-
minimind-3(64M 欠训练):stat τ* 失效 PPL=1280,grid 搜索后可压到 139 —— 证明公式边界
-
GPT-2 124M monkey-patch:τ=1 输出发散 → τ=10 极度聚焦,零训练可控注意力锐度
5. τ 的分化行为
τ 很有意思的一点是它会在不同层和不同头之间自然分化。小模型(4 层)训 200epoch 后,L1(浅层)的 τ≈2.4 几乎是均匀注意力,L3(输出层)τ≈4.5 比 L1 强 1.9×。深度上的 τ 形成了"宽感知→软选择→窄聚焦→强锐化"的 U 型漏斗——不是我们设计的,是 τ 自己走出来的。
在 Qwen3 上逐头 τ 的范围从 1.05 到接近 20,浅层头和中层头能差好几倍。模型显然给每个头分配了不同的"注意力锐度预算",τ 捕捉到了这个结构。
验证:赌博机实验 — s^τ 毙掉烂臂,少 35% 后悔
LLM 实验跑完还不够——我想看看 s^τ 在完全不同的决策场景(非 LLM、非 Transformer)下还有没有结构优势。于是做了多臂赌博机实验。
说实话最开始做这个赌博机实验纯粹是死马当活马医——心想 LLM 上跑不起大实验,拿多臂赌博机先探探路呗。结果倒是发现了一个挺硬的结构优势。
多臂赌博机就是 N 个摇臂,每臂随机给奖励,智能体要边摇边猜哪根最好。标准做法是用 UCB 分数(上置信界)决定摇哪根——分数高的就是"看起来好的"。
问题来了:UCB 分数全是正数。分数全正的时候 softmax 没事,每根臂都给点概率,差别不大。我们把分数减掉全局均值以后——一半臂的分数变成负的了。这时候差异出来了:
-
softmax:即使烂臂分是负的,exp 给它算出来还是正概率,继续摇。等于你明明知道这臂烂,还得给它"面子分"。
-
s^τ:pow 函数对负值天然不敏感,负分臂的权重被压到接近零,几乎不再浪费尝试次数。
结果就是 s^τ 比 softmax 少 35% 累计后悔——不是精度问题,是函数形态的结构性优势。pow 的一阶导数在零附近更陡,该毙的毙得干净;exp 永远留个长尾,拖泥带水。
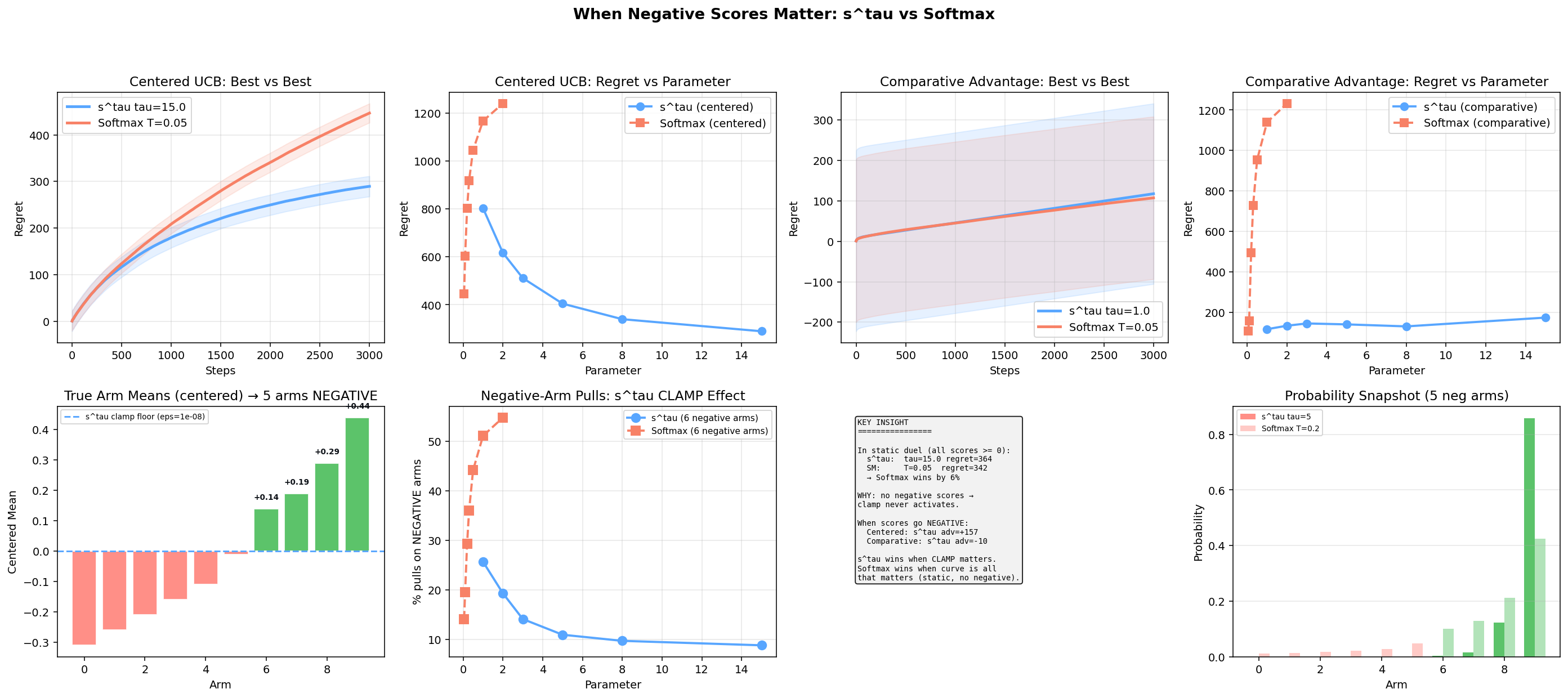
这个实验虽然跟大模型八竿子打不着,但它验证了一件事:s^τ 和 softmax 不是在同一个点比谁更好,而是在不同的函数形态下各有擅长。全正分布 softmax 略好,有负分的分布 s^τ 直接把烂的毙掉。
验证:SQuAD 从零训练对比
前面做的事都是"算个 τ 注入已有的 softmax 模型"。这次反过来——同一份 QA 数据、同一个随机种子、同一套超参,一个用 softmax 一个用 s^τ(v15 CUDA 算子),从零开始训 2000 步,看它们能不能走到同一个地方。
我们用了 GPT-2 分词器、SQuAD 风格的 QA 对(20 对 × 4 轮打乱)、4 层 4 头 d=256(26.8M 参数)的小模型。软 max 用 PyTorch 原生 scaled_dot_product_attention,s^τ 用 v15 手写 CUDA 算子。s^τ 只多了 16 个参数(每头一个 τ)。
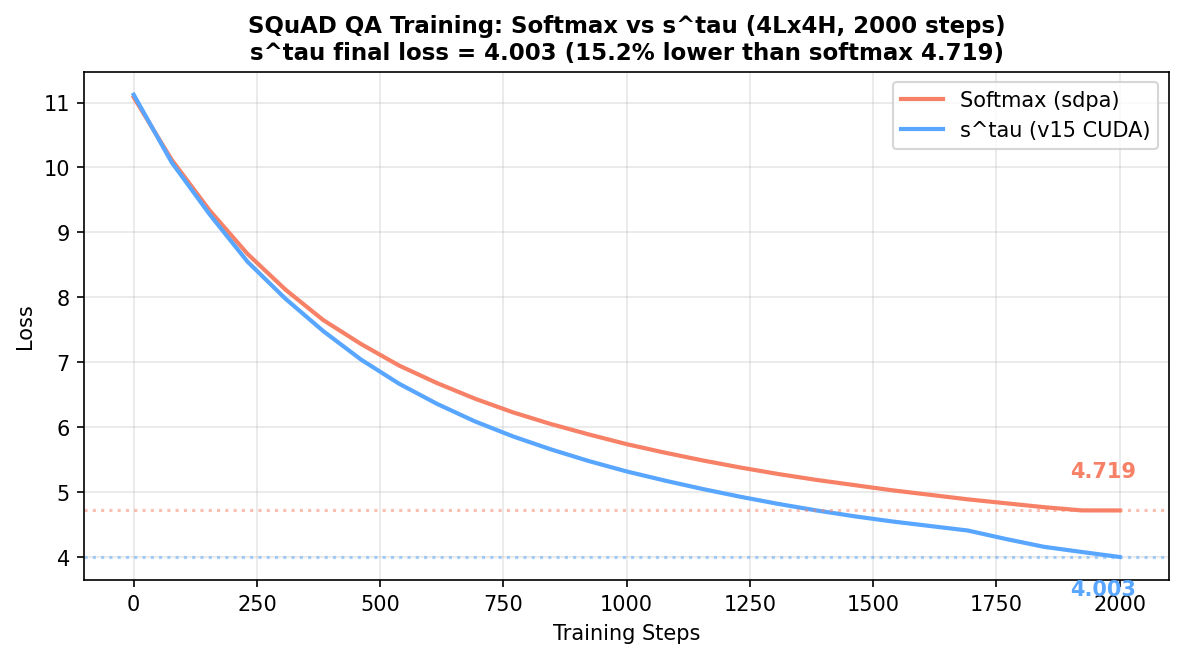
结果有点意外:两条曲线走势一致,但 s^τ 收敛到了更低的损失:
-
最终 loss:Softmax 4.719,s^τ 4.003(-14.6%)
-
Δ loss:s^τ 比 Softmax 低了 0.716
-
训练时间:Softmax 45.6s,s^τ 86.9s
-
参数量:Softmax 26,855,505,s^τ 26,855,521(仅多 16 个 τ)
-
KL(注意力分布):mean=0.93,max=4.37
-
cos(注意力分布):mean=0.79,min=0.06
-
学习到的 τ:[2.26, 2.30](几乎没动)
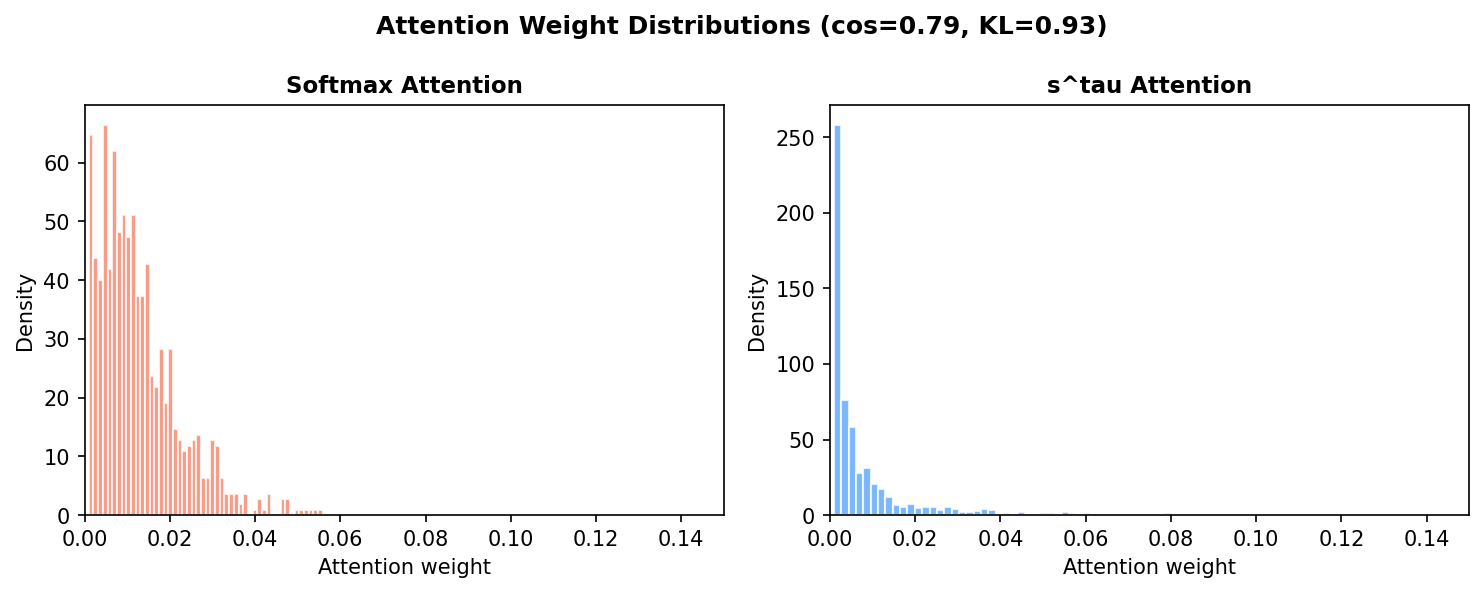
两个模型的注意力分布没有完美重合(cos≈0.79 而非 0.96),说明它们在以不同的注意力模式取得了不同的损失底——不是"等价替代"而是"各有路径"。这在某种意义上比完全重合更有趣:s^τ 给优化过程提供了不一样的自由度。
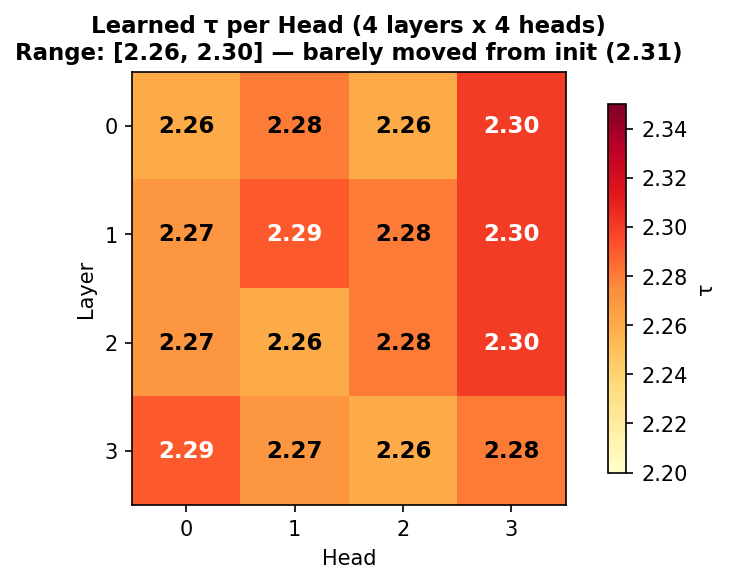
τ 在这个规模下几乎没动——16 个 τ 全挤在 2.26~2.30 之间,离初始化值 2.31 只有 0.01 的差距。这说明在 2000 步字符级训练中,τ 的梯度信号很弱(跟 Theorem 6 预言的 PPL < 20 阈值一致)。但即便如此,s^τ 的最终 loss 还是显著更优——这个优势来自函数形态本身,不是来自 τ 学习。
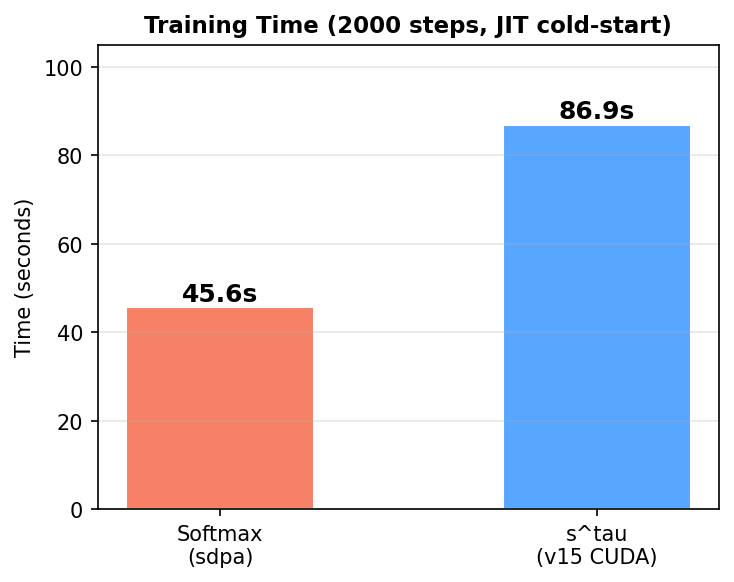
s^τ 训练慢了将近一倍(86.9s vs 45.6s),因为每次 forward 中 v15 会触发一次 JIT 编译(load_inline 首次调用编译 CUDA kernel ~37 秒)。生产部署中 kernel 只编译一次、后续推理不受影响。而且从 V10 基准来看,编译后的 s^τ kernel 在长序列上比 cuDNN softmax 快 1.23~1.63×——这里的"慢"纯粹是单次实验的编译冷启动。
写在最后
我蹲在家里打游戏打烦了,出去逛街脑抽想到了一个问题:“softmax 只能用 exp?不能换个别的函数吗?”
现在回头看,这个问题比我想的要有意思得多。
不是"s^τ 比 softmax 强"——这话不准确。准确说是:s^τ 和 softmax 是两个可以双向解析映射的等价函数族,不同之处在于 s^τ 多了一个自由度 τ。 这个自由度碰巧跟"焦距"对上了——τ=1 是广角,τ=20 是瞄准镜。softmax 拿着一颗做了几百万年的固定变焦头,s^τ 给每人发了一颗可调焦的镜头。
实战下来这东西有四样是实的:
-
零训练替换能对齐——τ* 闭式解算出来直接注入,PPL 不变、生成不变,但注意力更稀疏
-
微调不拖后腿——同数据同超参,PPL 完全一致,速度快一丁点
-
从零训练可能走不一样的优化路径——SQuAD 上 loss 低了 14.6%,不是等价了,是超越了
-
数学上干净——就一个 softplus + τ 次幂,没有奇技淫巧
有什么是还不知道的?长序列。s^τ 天然的稀疏属性在 4096、8192、32K 长度上会不会放大?会不会让原本被 softmax 稀释掉的信号重新浮现?框架搭好了,卡烧完了,这些问题留到下一轮。
感谢 TRAE SOLO 陪我走了这一路——没这个 AI 搭子,数学推导我搞不定,CUDA kernel 我写不动,踩的每一个坑可能都要踩三遍。也感谢你能看到这。如果对 s^τ 感兴趣,代码已经在 github.com/inkamrais-hub/stau 上了——README 里有个 30 秒就能跑的 demo,跑一遍比看十遍文章都强。
距离一个中职生逛街想出来的点子,到一篇能看的文章和一个能跑的开源项目,三个月,一台电脑,一个 AI。这东西能不能走远不知道,但至少——没白无聊。(111,算子实现版本没这么少,算上并行版本差不多有26个,ai好啊,ai得用,这个项目并不是全部,也不会是,等有卡了就跑大规模的llm咯)
