【Code With SOLO】用 SOLO 从0开发一款 AI 小说写作工作台——用软件工程解决 AI 辅助网文创作的四大顽疾
一、摘要
我是一名产品经理,也是一位网络小说爱好者。在使用各种 AI 写作工具辅助创作时,我发现了一个普遍痛点:AI 能写文字,但无法理解你的整本书。人物会"失忆"、情节会"穿越"、上下文会"断裂"。为了从根本上解决这些问题,我用 TRAE SOLO 从零开发了一款桌面端 AI 小说写作工作台「春水桃花路」,用软件工程的手段——结构化数据管理、记忆检索系统、上下文工程——系统性地解决了 AI 辅助网文创作中的四大顽疾。目前已有可运行的桌面程序。
二、背景
我是谁:产品经理,日常工作中擅长需求分析和系统设计,业余时间是一位狂热的网络小说爱好者,自己也尝试创作过网络小说。
AI 辅助写作的四大顽疾:
在用 ChatGPT、DeepSeek 等 AI 工具辅助写小说时,我反复遇到以下问题:
- 上下文窗口不够用:一本网文动辄几十万字,AI 的上下文窗口根本塞不下,导致 AI 写到后面就忘了前面发生了什么
- 人物设定"崩塌":AI 不记得角色之间的关系变化,明明第10章已经表白了,第30章还在写"暗恋"
- 情节前后矛盾:角色已经获得的道具、已经学会的技能,AI 会反复"遗忘",导致逻辑漏洞
- 每次都要重复"喂"设定:每次开新对话都要重新粘贴大纲、人物卡、世界观,效率极低
我的思路:这些问题本质上是数据管理问题,不是 AI 模型的问题。如果能用软件工程的方式,把小说的结构化数据(大纲、人物、事件、记忆)管理好,在每次调用 AI 时自动组装精准的上下文,就能从根本上解决这些问题。
目标:开发一款专为网文创作设计的桌面应用,核心不是"让 AI 写小说",而是**“让 AI 理解你的小说”**。
三、实践过程
3.1 技术选型与架构设计
作为产品经理,我擅长做需求拆解和系统设计,但编码能力有限。TRAE SOLO 成了我的"技术合伙人",帮我完成了从架构设计到编码实现的全流程。
技术栈:
- 桌面壳:Electron 41(本地文件系统访问能力)
- 前端:Vue 3 + TypeScript + Element Plus
- 编辑器:Tiptap 富文本编辑器
- 状态管理:Pinia(按功能模块拆分 12 个 Store)
- AI 引擎:DeepSeek API(SSE 流式输出)
- 记忆检索:关键词匹配 + BM25 算法 + AI 摘要(三级检索)
核心架构——结构化项目目录:
小说项目/
├── 设定/
│ ├── 人物.json # 角色卡片(姓名/性格/状态/禁止行为)
│ ├── 世界观.md # 世界观设定
│ ├── 记忆库.md # AI 记忆(角色状态/关系进展/剧情线索/禁止重复行为)
│ ├── 事件日志.json # 章节事件记录
│ └── 项目.json # 结构参数配置
├── 正文/
│ └── 第一卷/
│ └── 第一章/
│ └── 第一节.md # 每个小节独立文件
├── 大纲.md # 卷→章→节 树形结构
├── .snapshots/ # 版本快照
└── .agent/
└── conversations.json # AI 对话持久化
设计理念:每一份数据都以结构化方式存储,AI 调用时可以精准检索和组装,而不是每次都把所有内容塞进上下文。
3.2 用软件工程解决四大顽疾
顽疾一:上下文窗口不够用 → 结构化上下文组装系统
问题本质:AI 的上下文窗口有限(通常 8K-128K token),但一本小说可能有 50 万字。简单粗暴地把前文塞进去,要么塞不下,要么塞进去了但关键信息被淹没在大量无关文本中。
解决方案:不是把"所有前文"给 AI,而是智能组装"当前章节需要的上下文"。
AI 续写时的上下文组装流程:
1. 定位当前章节在大纲树中的位置
2. 提取前3个章节的摘要(不是全文,只是摘要)
3. 提取当前章节的标题、摘要、关键情节点
4. 提取后3个章节的摘要(让 AI 知道故事走向)
5. 提取上一节正文的最后150字(保持文风连贯)
6. 检索记忆库中与当前章节相关的内容
7. 组装成 System Prompt 发送给 AI
核心代码——叶子节点路径计算:
// outline.ts - 智能上下文提取
export function getLeafPath(nodes: ProjectNode[], targetId: string): LeafPathResult {
// 1. 遍历大纲树,找到所有叶子节点(实际写作单元)
// 2. 定位当前节点在叶子序列中的位置
// 3. 取前3个和后3个节点的摘要
// 4. 加载上一节正文的最后150字(保持文风衔接)
const prevLeaves = leaves.slice(Math.max(0, targetIndex - 3), targetIndex)
const nextLeaves = leaves.slice(targetIndex + 1, targetIndex + 4)
return { previous, next, prevChapterEnd, isFirst, isLast, leafIndex, totalLeaves }
}
效果:无论小说写多长,AI 每次收到的上下文都控制在合理范围内(约 2000-4000 字),且每一条信息都是与当前章节高度相关的。
顽疾二:人物设定"崩塌" → 事件驱动的记忆系统
问题本质:AI 没有跨章节的"记忆"。第5章角色A和B成了朋友,第15章AI又让他们像陌生人一样对话。这不是 AI 的问题,是没有人帮 AI “记笔记”。
解决方案:设计了一套事件驱动的记忆系统,自动追踪角色状态变化。
核心数据结构:
// types/index.ts - 章节事件定义
export interface ChapterEvent {
id: string
chapterId: string
description: string // 事件描述:"林小夏和苏北辰在天台交换了秘密"
affectedCharacters: string[] // 涉及的角色ID
type: 'relationship' | 'state_change' | 'milestone' // 事件类型
autoExtracted: boolean // 是否由AI自动提取
confirmed: boolean // 是否已确认(写入记忆库)
}
// 角色状态追踪
export interface Character {
id: string
name: string
stateEntries: CharacterStateEntry[] // 角色状态变化记录
forbiddenActions: string[] // 禁止重复的行为
}
工作流程:
写作完成 → AI 自动提取章节事件 → 用户确认 →
├→ 更新角色状态(stateEntries)
├→ 推导禁止行为(forbiddenActions)
└→ 写入记忆库(记忆库.md)
禁止行为自动推导——这是我认为最有创意的部分:
// character.ts - 根据事件自动推导"禁止重复行为"
function deriveForbiddenActions(event: ChapterEvent): string[] {
const desc = event.description
const actions: string[] = []
if (event.type === 'relationship') {
if (/介绍|认识|得知|知道.*名字/.test(desc)) {
actions.push('不要再出现询问对方名字的对话')
}
if (/信任|成为.*朋友|结盟/.test(desc)) {
actions.push('不要再表现出对对方的不信任')
}
}
if (event.type === 'state_change') {
const woundMatch = desc.match(/包扎|处理|治疗(.{1,6}伤口|.{1,6}伤)/)
if (woundMatch) {
actions.push(`不要再出现${woundMatch[0]}的情节(伤口已处理)`)
}
const acquireMatch = desc.match(/获得|得到|学会|掌握(.+)/)
if (acquireMatch) {
actions.push(`不要再表现为没有${acquireMatch[1]}`)
}
}
return actions
}
举例:当你在第10章写"苏北辰帮林小夏包扎了手上的伤口"并确认事件后,系统会自动推导出禁止行为——“不要再出现包扎手上伤口的情节(伤口已处理)”。之后 AI 续写时,这个禁止行为会被注入到上下文中,从根本上杜绝逻辑矛盾。
顽疾三:情节前后矛盾 → 三级记忆检索引擎
问题本质:记忆库会越来越大,不可能全部塞进 AI 上下文。需要一种方式,在大量记忆中精准找到与当前章节相关的部分。
解决方案:实现了三级递进式记忆检索引擎。
// memorySearch.ts - 三级检索策略
export async function searchMemory(
memoryMd: string,
query: string,
budget: number,
mode: MemorySearchMode, // 'keyword' | 'bm25' | 'ai'
characterNames?: string[],
sendMessage?: Function
): Promise<string> {
switch (mode) {
case 'keyword': // 第一级:关键词匹配(快速、离线)
return keywordSearch(memoryMd, query, budget, characterNames)
case 'bm25': // 第二级:BM25 相关性排序(更精准)
return bm25Search(memoryMd, query, budget, characterNames)
case 'ai': // 第三级:AI 语义理解(最精准,需要额外API调用)
return aiSearch(memoryMd, query, budget, sendMessage)
}
}
三级检索的设计思路:
| 级别 | 算法 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|
| L1 关键词 | TF 匹配 | 速度快,零成本 | 不理解语义 | 快速写作时 |
| L2 BM25 | BM25 相关性排序 | 精准度较高,离线 | 需要分词 | 日常使用 |
| L3 AI | AI 语义提取 | 最精准,理解上下文 | 额外 API 调用 | 关键章节 |
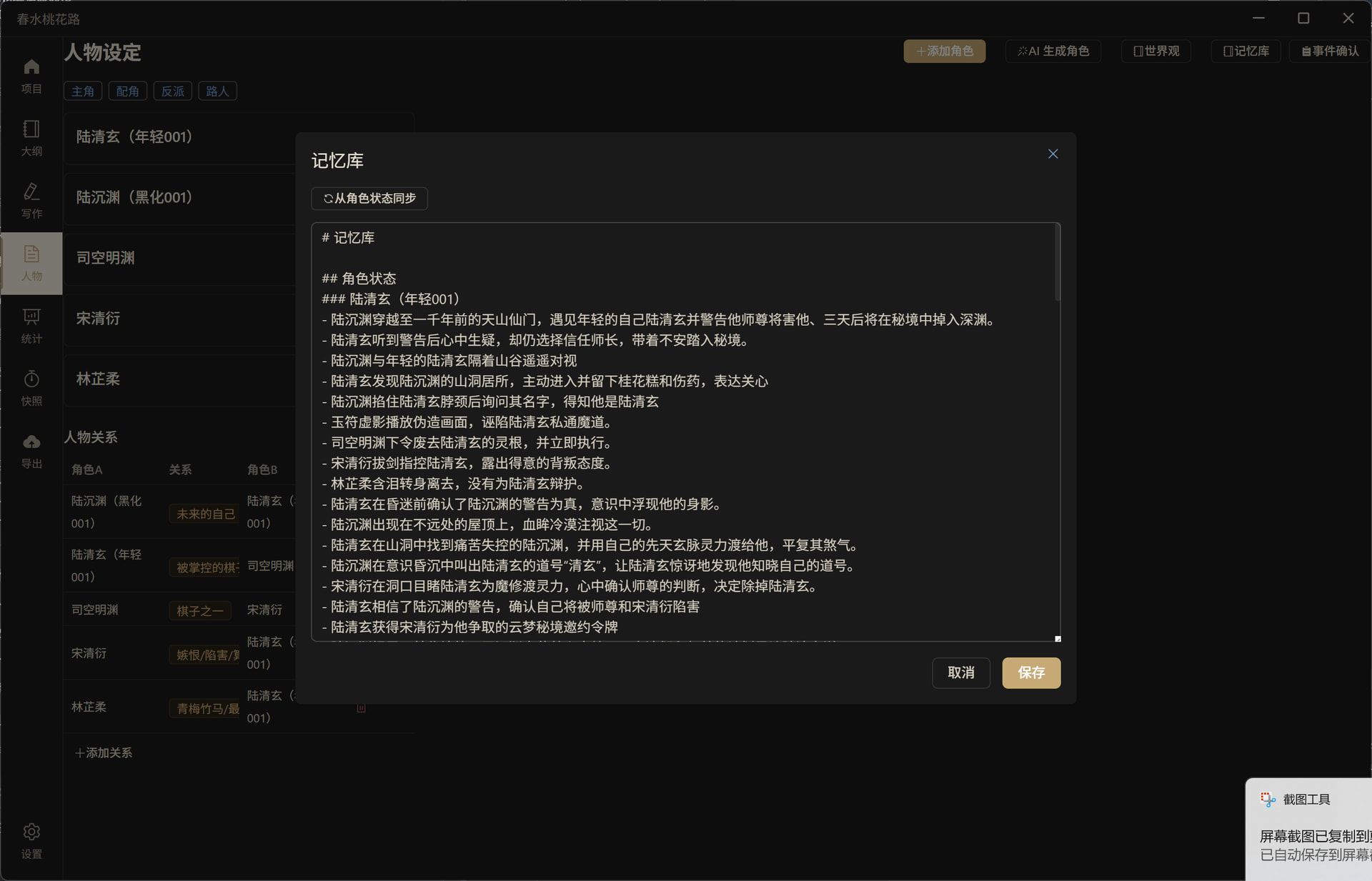
记忆库结构(Markdown 格式,人类可读可编辑):
# 记忆库
## 角色状态
### 林小夏
- 转学到青云中学(第一章 转学第一天)
- 与苏北辰成为同桌(第二章 意外的同桌)
### 苏北辰
- 在走廊帮林小夏捡起文具(第一章 转学第一天)
## 角色关系进展
- 林小夏、苏北辰:第一章 转学第一天 走廊初次相遇
## 剧情线索
- 图书馆发现夹着旧照片的书(第二章 意外的同桌,涉及林小夏)
## 禁止重复行为
- 不要再出现询问对方名字的对话
- 不要再表现为没有苏北辰的帮助
顽疾四:每次都要重复"喂"设定 → AI 引导式对话系统
问题本质:每次让 AI 生成大纲、创建角色、扩写章节时,都需要精心构造 Prompt,包括题材、目标读者、风格、现有大纲等。这个过程繁琐且容易遗漏。
解决方案:设计了 AI 引导式对话组件(AiGuidedDialog),让 AI 主动引导用户完成创作。
<!-- AiGuidedDialog.vue - AI 引导式对话 -->
<template>
<el-dialog v-model="visible" :title="title" width="800px">
<!-- 可编辑的系统提示词 -->
<el-form-item label="系统提示词(可修改)">
<el-input v-model="editablePrompt" type="textarea" :rows="4" />
</el-form-item>
<!-- 上下文信息(自动组装,可勾选) -->
<el-form-item label="上下文信息">
<el-checkbox v-for="opt in contextOptions" v-model="opt.enabled">
{{ opt.label }}
</el-checkbox>
<el-input v-model="editableContext" type="textarea" :rows="4" />
<!-- 上下文字数统计 + AI 压缩按钮 -->
<span>{{ editableContext.length }} / {{ maxContextLen }}</span>
<el-button @click="handleCompressContext">AI 压缩上下文</el-button>
</el-form-item>
<!-- 多轮对话 + 建议选项 -->
<div class="chat-messages">
<div v-for="msg in messages" :class="['chat-msg', msg.role]">
<div class="msg-content" v-html="renderMarkdown(msg.content)" />
<!-- AI 给出的建议选项,用户一键选择 -->
<div v-if="msg.suggestions" class="msg-suggestions">
<el-button v-for="s in msg.suggestions" @click="pickSuggestion(s)">
{{ s }}
</el-button>
</div>
</div>
</div>
</el-dialog>
</template>
这套系统解决的场景:
| 场景 | 传统方式 | 引导式对话 |
|---|---|---|
| 生成大纲 | 手动写 Prompt 描述需求 | AI 问你:什么题材?几卷几章?目标读者? |
| 创建角色 | 手动粘贴大纲让 AI 生成 | 自动注入大纲上下文,AI 直接生成符合剧情的角色 |
| 扩写章节 | 手动粘贴前文+大纲+人物 | 自动组装上下文,一键生成 |
| 修改设定 | 重新描述需求 | 在已有基础上对话式调整 |
上下文预算控制——防止 Token 浪费:
// projectConfig.ts - 项目级配置
export interface ProjectConfig {
volumes: number // 卷数
chaptersPerVolume: number // 每卷章数
sectionsPerChapter: number // 每章节数
wordsPerSection: number // 每节目标字数
memorySearchMode: MemorySearchMode // 记忆检索模式
maxExtraAiCalls: number // 最大额外AI调用次数
memoryContextBudget: number // 记忆上下文预算(字数)
}
3.3 其他核心功能
结构化大纲编辑器
实现了卷→章→节三级树形大纲,每个节点包含标题、摘要、关键情节点、出场人物、续接提示。大纲与正文双向联动:
// 大纲 ↔ Markdown 双向序列化
export function outlineToMarkdown(nodes: ProjectNode[]): string { ... }
export function parseOutlineMarkdown(md: string): ProjectNode[] { ... }
// 大纲节点与正文文件的路径映射
// 正文/第一卷/第一章/陌生的铃声.md
function buildChapterDir(nodes, node): string {
const volume = findVolumeAncestor(nodes, node)
const parent = findDirectParent(nodes, node.id)
return `正文/${volume.title}/${parent.title}`
}
游离章节检测
当大纲节点被删除或重命名后,对应的正文文件会变成"孤儿"。系统会自动检测并提示:
// 检测游离章节(大纲已删但正文还在的文件)
export interface OrphanChapter {
oldNodeId: string
title: string
volumePath: string
fileName: string
reason: 'deleted' | 'renamed' // 大纲已删除 / 标题已修改
}
写作统计与版本快照
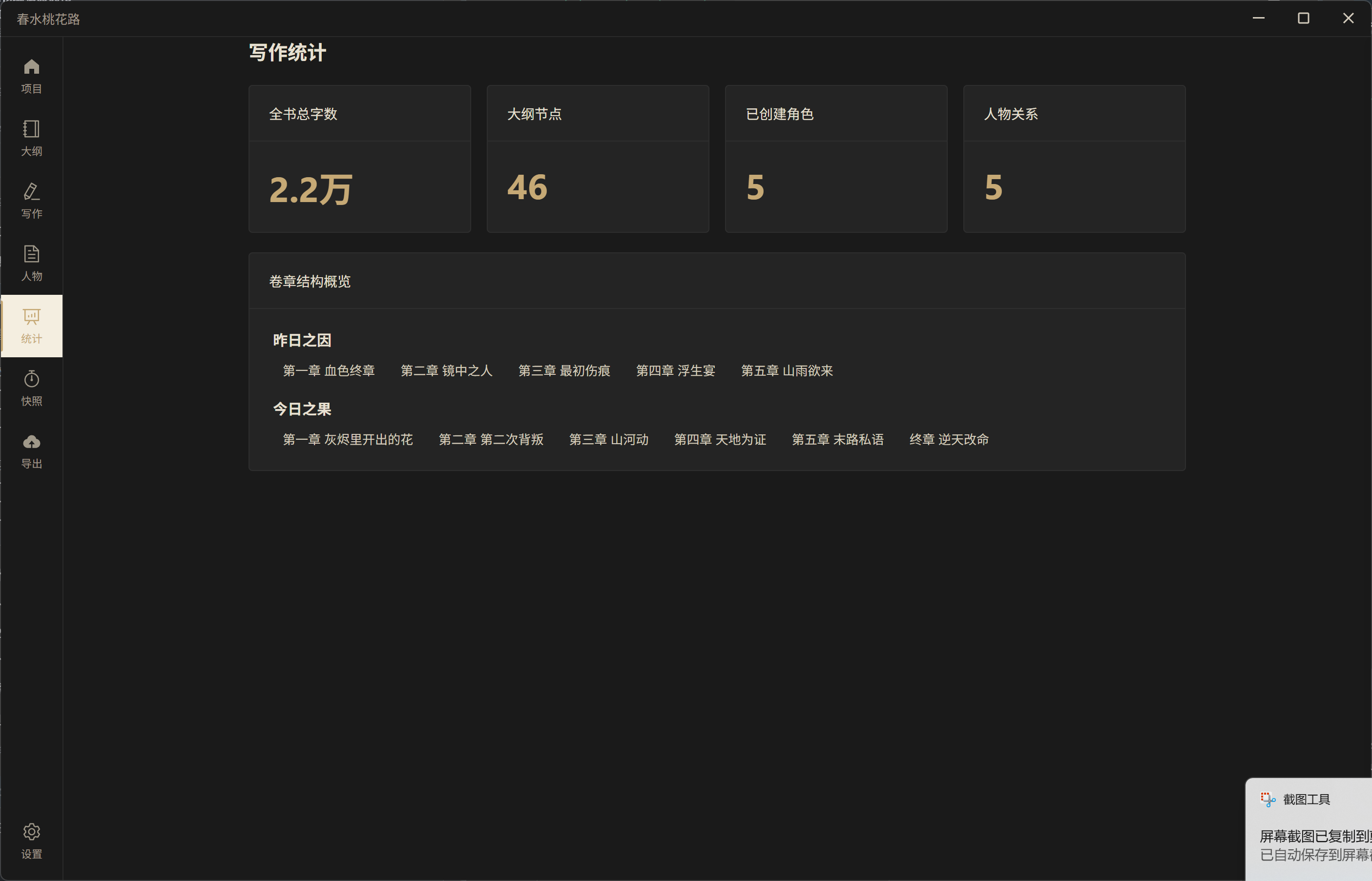
- 写作统计:全书总字数、大纲节点数、角色数、关系数,卷章结构概览
- 版本快照:手动创建章节快照,随时回溯到历史版本
3.4 开发过程中的 SOLO 协作
作为产品经理,我的编码能力有限,但 SOLO 让我能以"产品设计"的方式驱动开发:
| 阶段 | 我做什么 | SOLO 做什么 |
|---|---|---|
| 需求分析 | 描述痛点、定义功能 | 引导我梳理边界条件、设计数据结构 |
| 架构设计 | 画系统框图、定义模块关系 | 推荐技术栈、设计项目结构 |
| 编码实现 | Review 代码、调整交互细节 | 生成组件代码、状态管理、API 封装 |
| 调试优化 | 描述 Bug 现象 | 定位根因、提供修复方案 |
| 打包发布 | 测试功能 | 配置 electron-builder,一键生成 .exe |
SOLO 帮我踩过的坑:
- 大纲拖拽排序时状态混乱 → SOLO 建议改用唯一 ID 关联
- AI 流式输出时内存泄漏 → SOLO 帮我加了 AbortController 中断机制
- Markdown 序列化时格式丢失 → SOLO 设计了严格的双向转换规则
- 上下文去重效率低 → SOLO 建议用 BM25 替代简单的关键词匹配
四、成果展示
4.1 应用界面
![]() 首页 - 项目管理
首页 - 项目管理
创建和管理多个小说项目,支持古风仙侠、校园言情、无限流等多种题材。
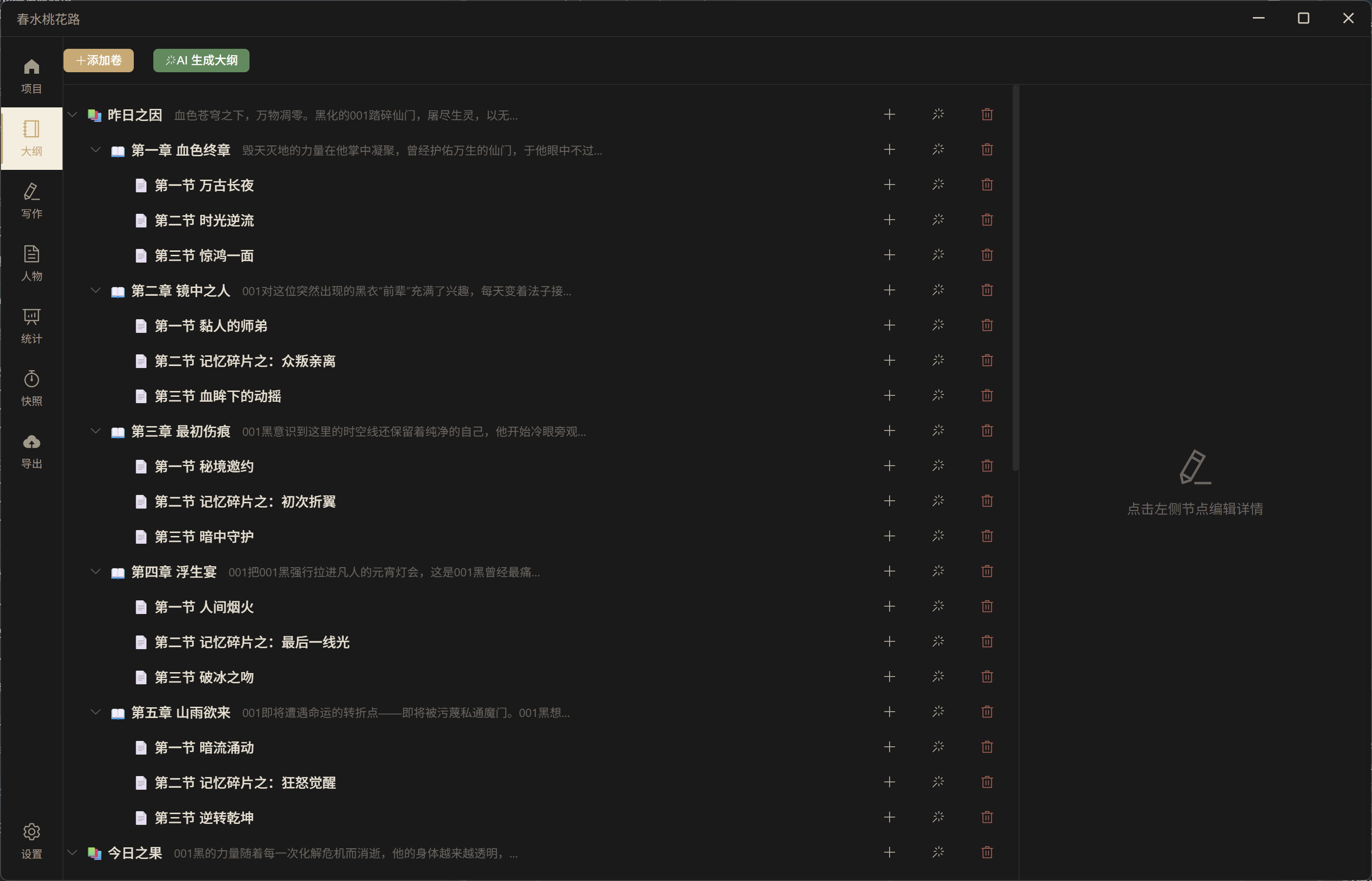
![]() 大纲编辑(AI 辅助生成/展开/修正)
大纲编辑(AI 辅助生成/展开/修正)
卷→章→节三级树形大纲,支持 AI 一键生成完整大纲结构,每个节点可独立进行 AI 展开和修正。
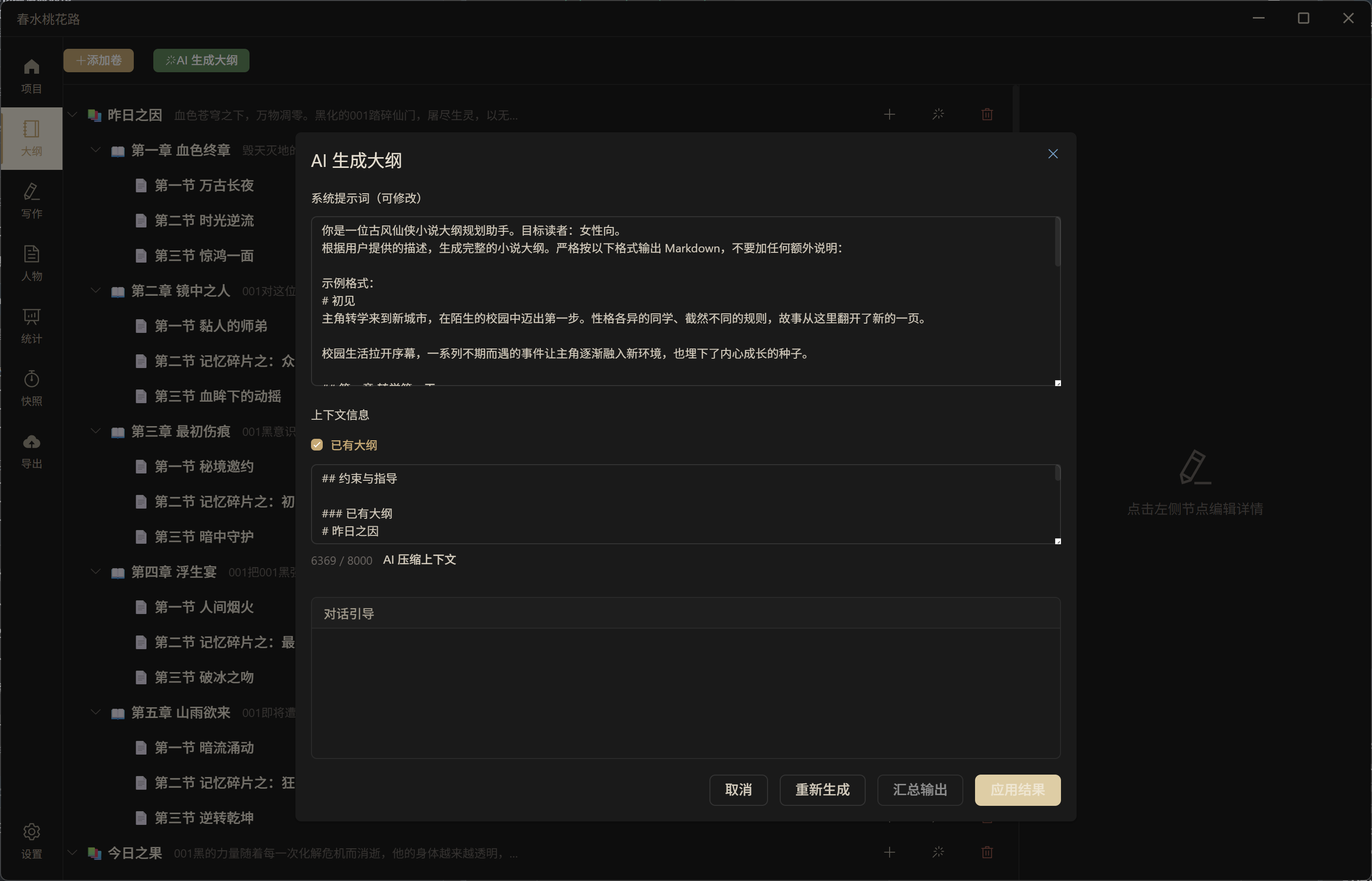
AI 生成大纲——通过引导式对话,AI 根据题材、目标读者、风格偏好自动生成结构化大纲:
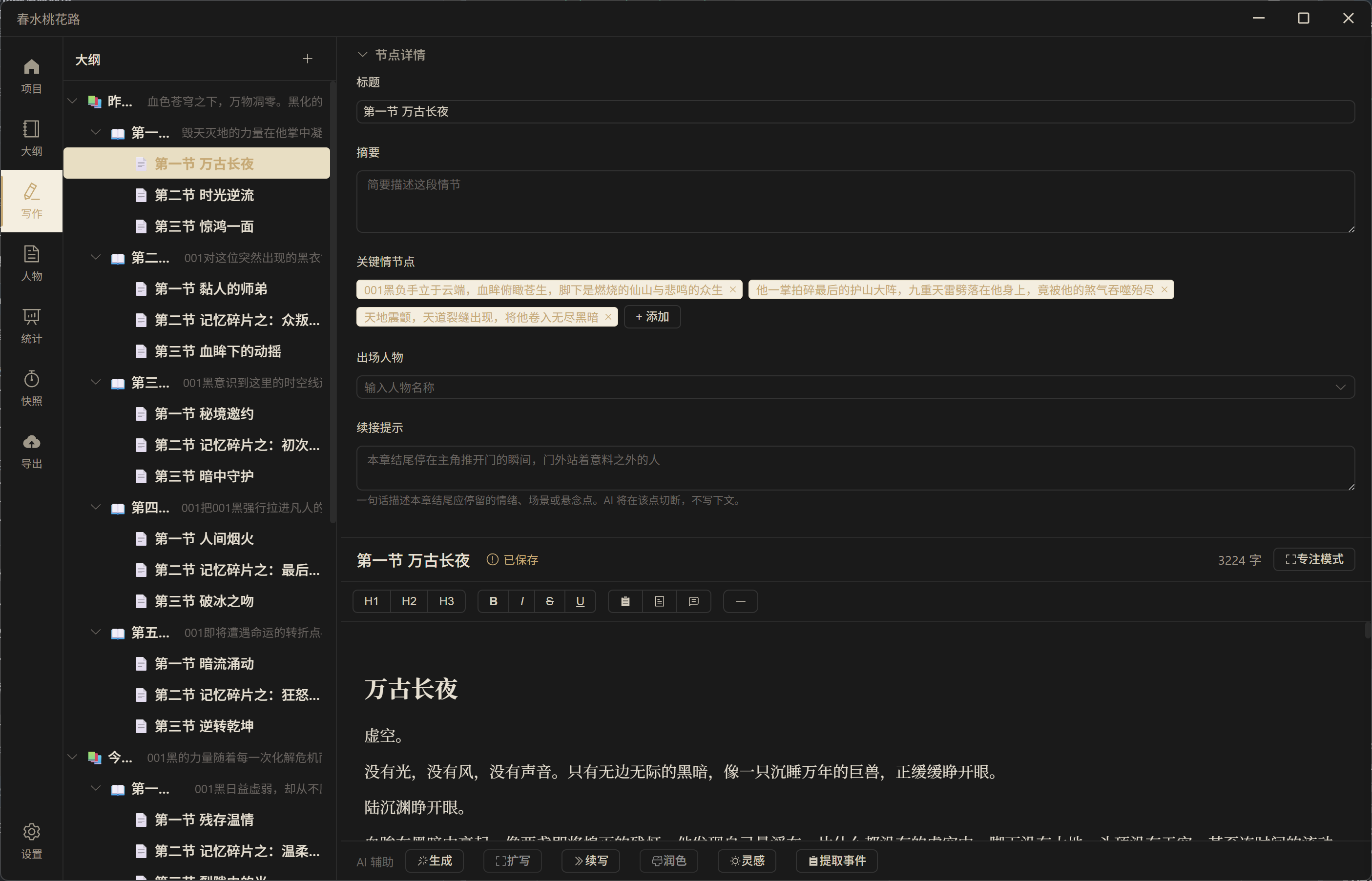
![]() 正文写作(左侧大纲 + 右侧编辑器 + 节点详情)
正文写作(左侧大纲 + 右侧编辑器 + 节点详情)
分屏布局:左侧大纲快速导航,右侧富文本编辑器,上方节点详情面板显示摘要、关键情节点、出场人物。底部 AI 工具栏支持一键续写、扩写、润色、灵感、提取事件。
AI 辅助生成——核心亮点:可编辑的系统提示词 + 上下文按需勾选(大纲/人物/世界观/记忆库/前情/后续等)+ Token 预算实时显示 + AI 压缩上下文功能:
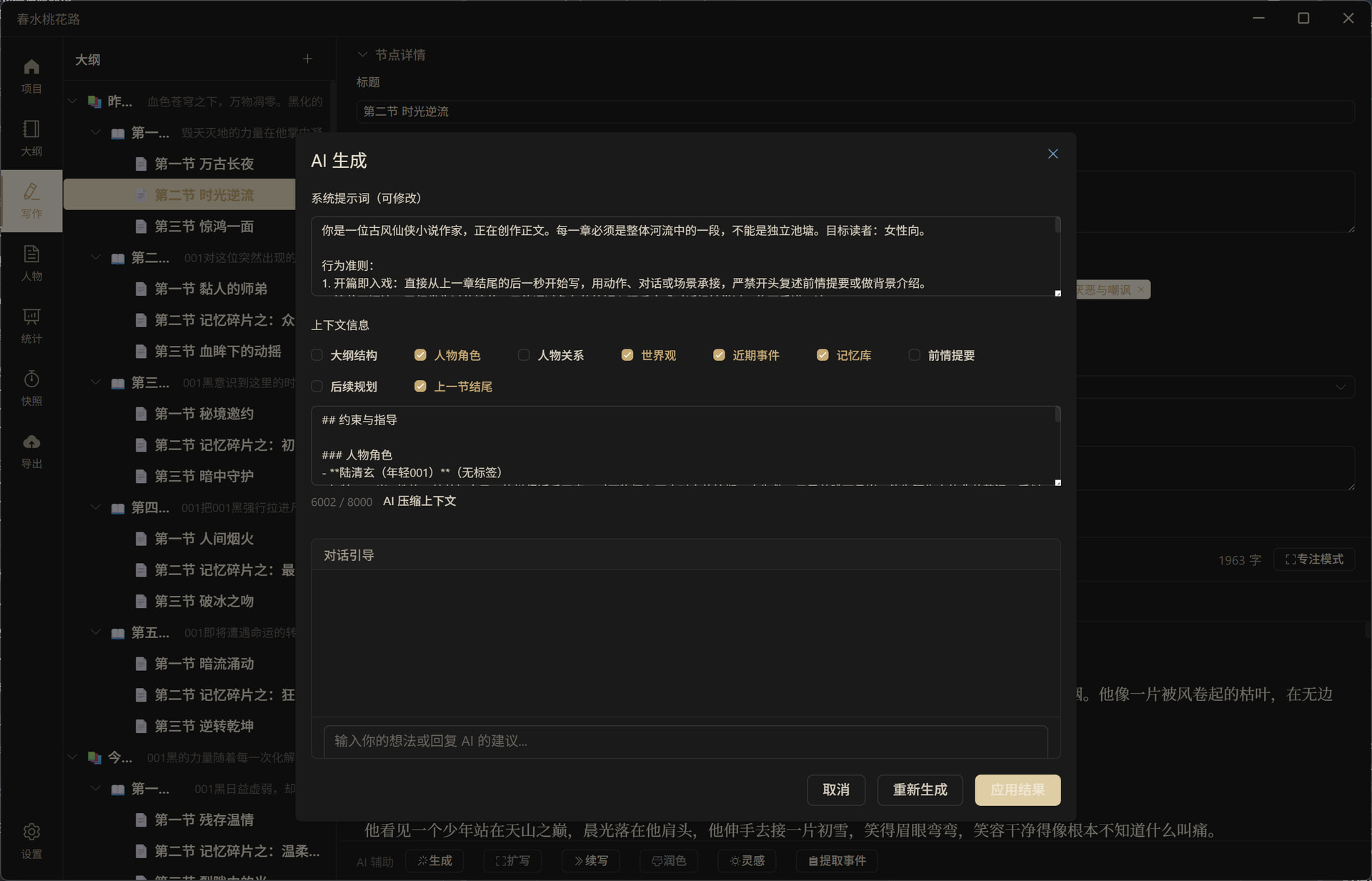
![]() 人物设定(角色卡片 + 关系图 + 状态追踪 + 禁止行为)
人物设定(角色卡片 + 关系图 + 状态追踪 + 禁止行为)
角色按主角/配角/反派/路人分类管理,支持 AI 一键生成符合剧情的角色设定。人物关系表清晰展示角色之间的复杂关系网络。
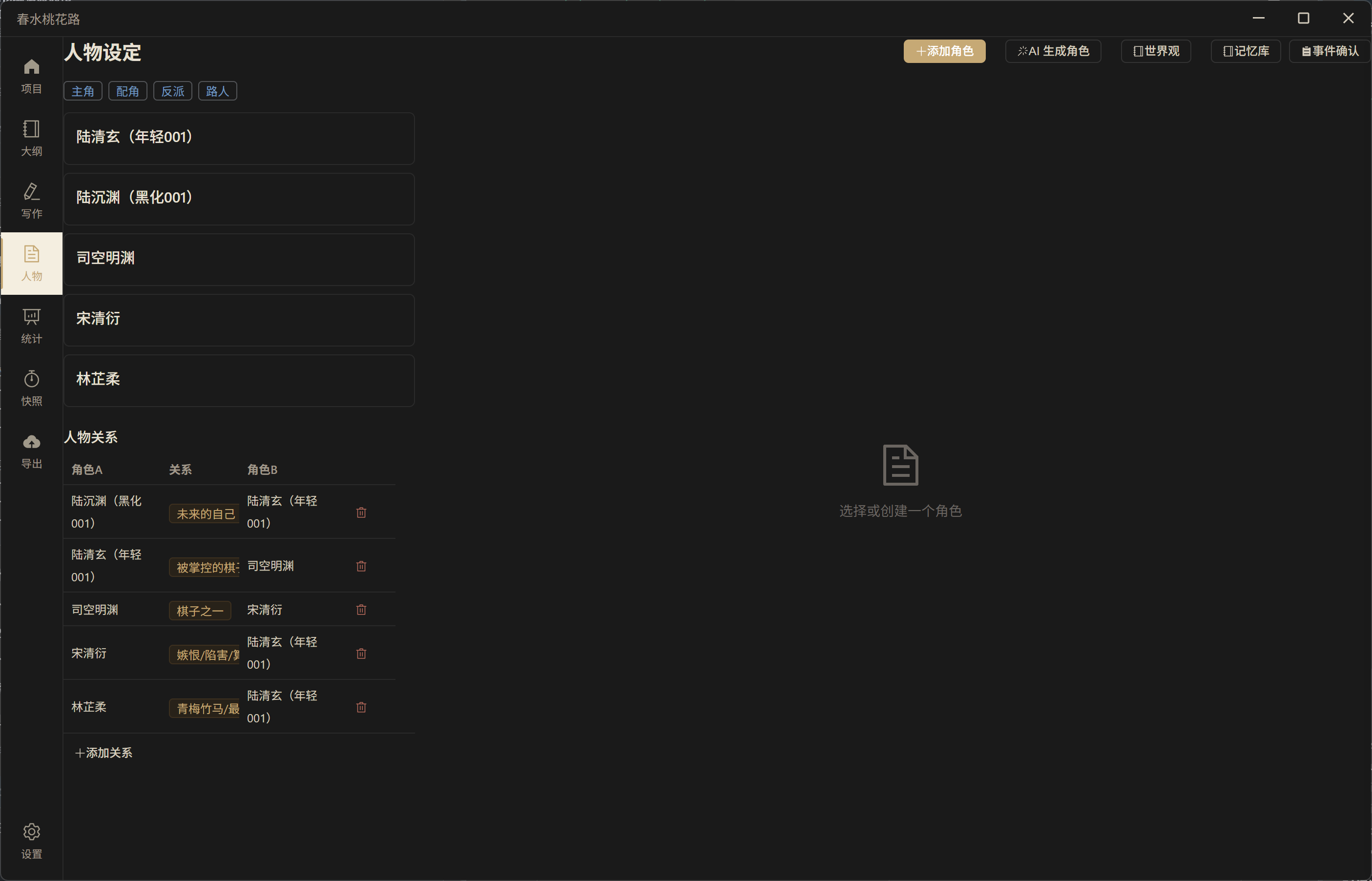
AI 生成角色——自动注入大纲上下文,生成与剧情高度契合的角色:
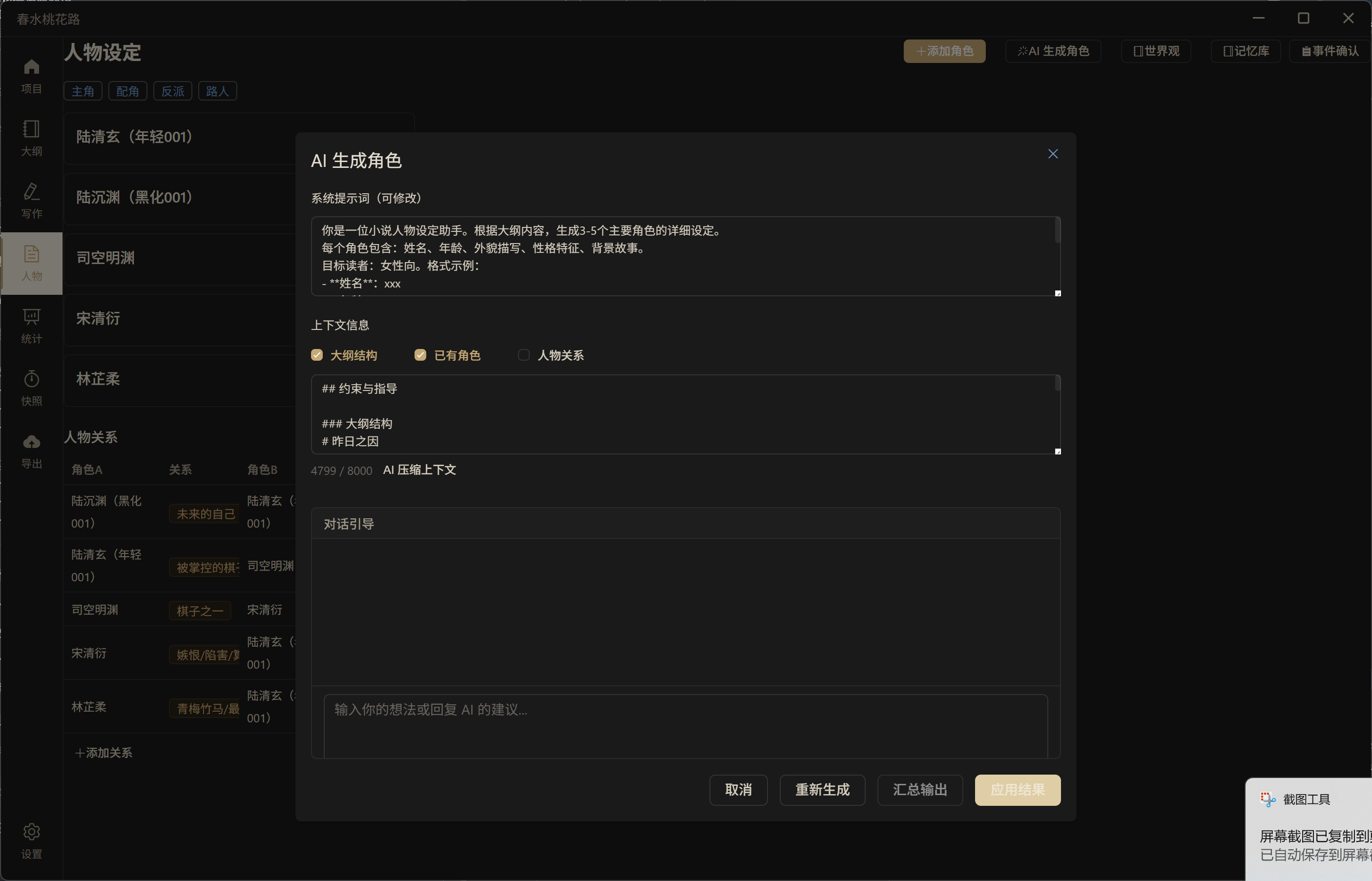
角色状态记录——追踪每个角色在各章节中的状态变化:
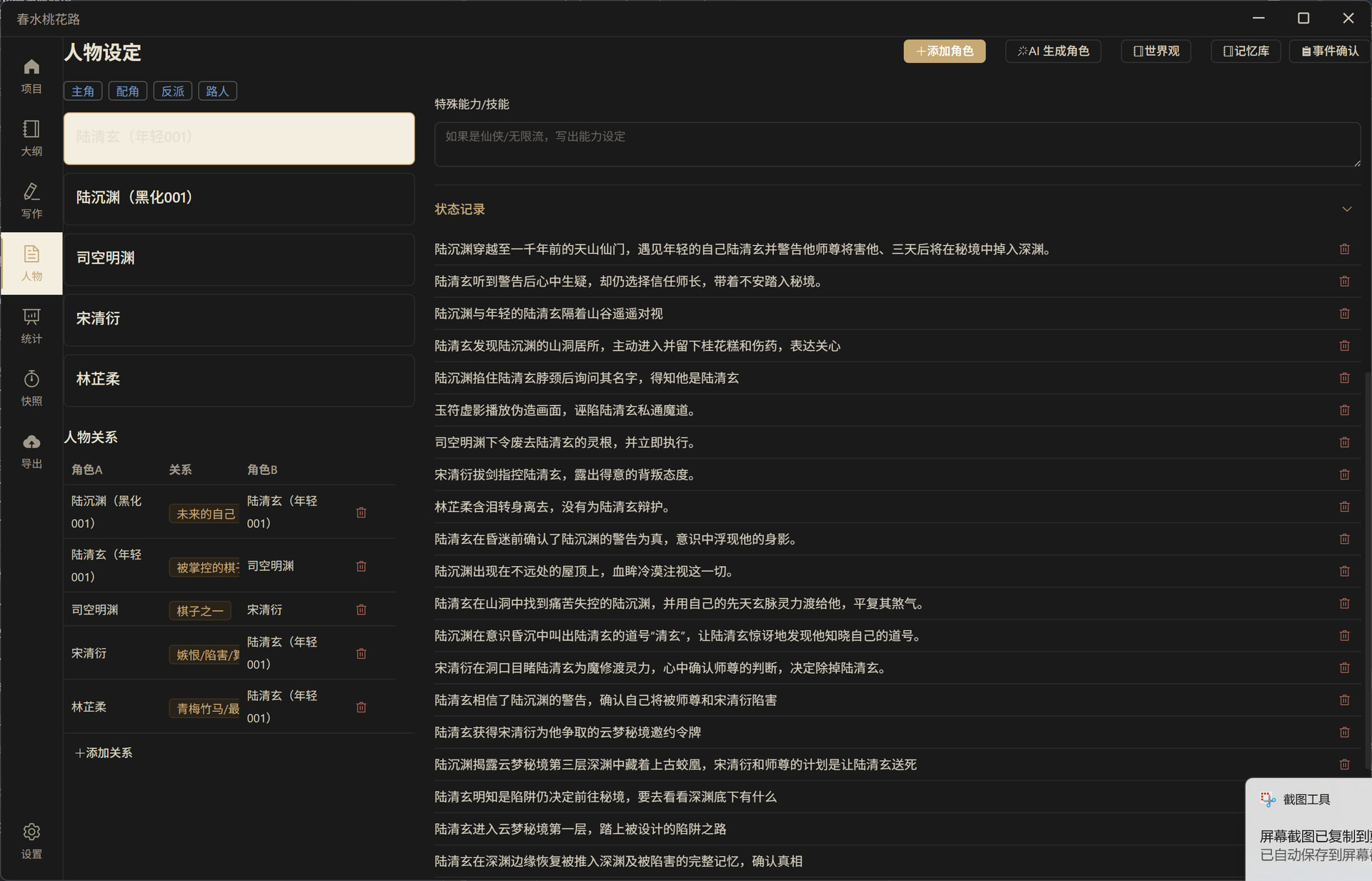
禁止重复行为——系统根据已确认事件自动推导"AI 不该再做什么",从根源上杜绝逻辑矛盾:
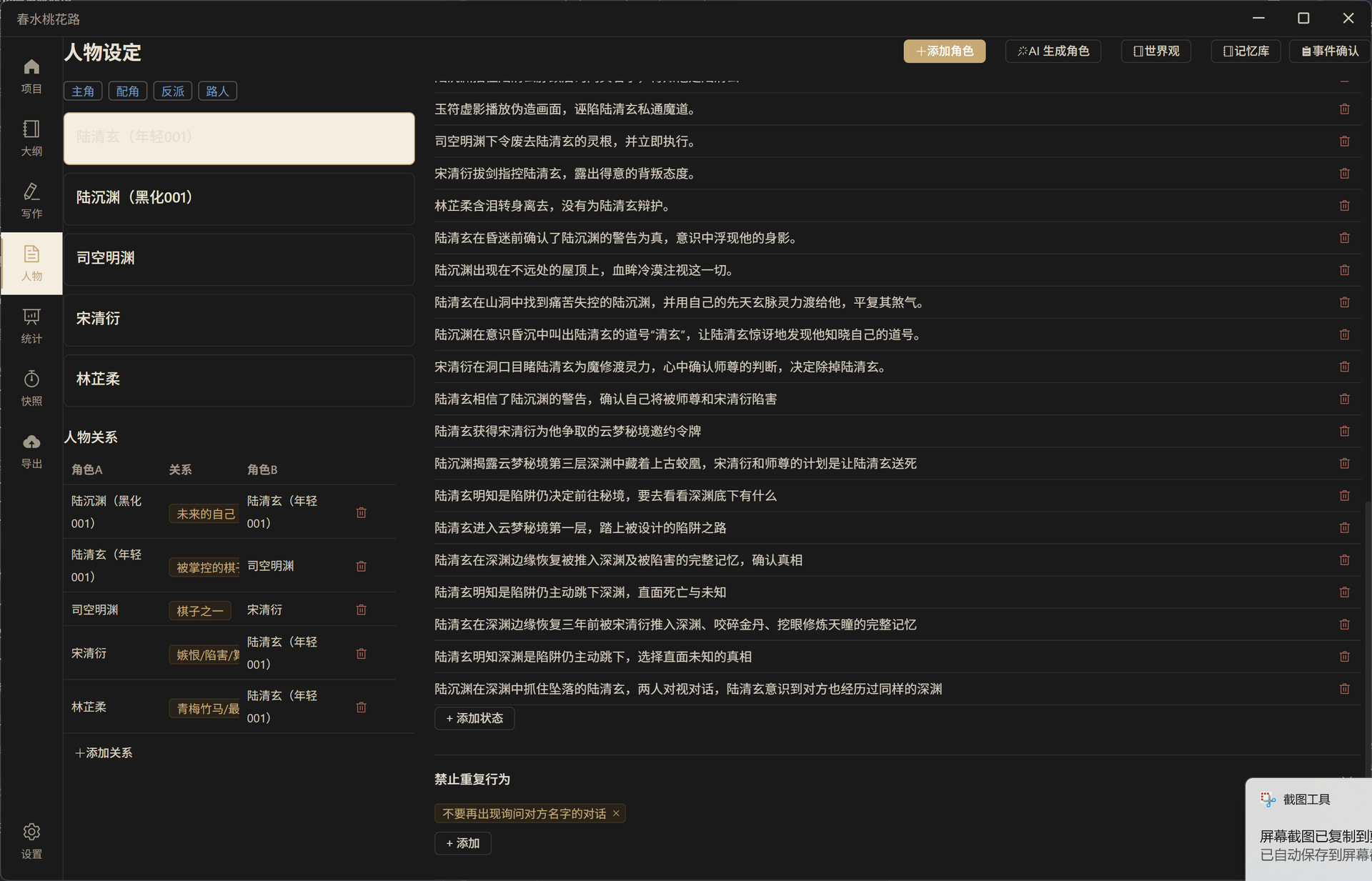
记忆库——结构化 Markdown 格式,记录角色状态、关系进展、剧情线索、禁止重复行为,人类可读可编辑:
![]() 写作统计
写作统计
全书总字数、大纲节点数、角色数、关系数一目了然,卷章结构概览清晰展示全书进度。
4.2 核心功能清单
| 功能模块 | 核心能力 | 解决的痛点 |
|---|---|---|
| 多项目管理 | 创建/切换多个小说项目,独立目录 | 一台电脑管理多本书 |
| 结构化大纲 | 卷→章→节三级树形,AI 辅助生成/展开/修正 | 大纲混乱、结构不清 |
| 富文本编辑 | Tiptap 编辑器,Markdown 双向转换 | 写作体验流畅 |
| AI 续写 | 基于智能上下文组装的精准续写 | AI “失忆”、文风不统一 |
| AI 灵感 | 根据大纲和人物生成情节建议 | 卡文、缺乏创意 |
| AI 润色 | 选中文本一键润色 | 文笔不够好 |
| 人物记忆系统 | 事件驱动 + 禁止行为自动推导 | 人物"崩设"、逻辑矛盾 |
| 三级记忆检索 | 关键词/BM25/AI 三级递进 | 记忆检索不精准 |
| AI 引导式对话 | 多轮对话 + 建议选项 + 上下文自动组装 | 每次手动写 Prompt |
| 上下文工程 | 预算控制 + AI 压缩 + 可编辑 Prompt | Token 浪费、上下文过长 |
| 写作统计 | 总字数/节点数/角色数/结构概览 | 进度不清晰 |
| 版本快照 | 手动创建/浏览/回溯章节快照 | 误删内容无法恢复 |
| 游离章节检测 | 自动检测大纲与正文的不一致 | 文件管理混乱 |
4.3 可运行程序
- 便携版:
春水桃花路-0.1.0-便携版.exe(已编译,可直接运行) - 技术栈:Electron 41 + Vue 3 + TypeScript + Element Plus + Tiptap + Pinia + DeepSeek API
五、效果与总结
5.1 这款应用的核心价值
市面上大多数 AI 写作工具的思路是:“给 AI 更大的上下文窗口”。
「春水桃花路」的思路是:“用软件工程的方式管理小说数据,让 AI 每次只看到它需要的信息”。
这两种思路的区别在于:
| 维度 | 塞更多上下文 | 结构化管理 + 精准检索 |
|---|---|---|
| 可扩展性 | 受限于上下文窗口 | 理论上无限(百万字级别) |
| 精准度 | 信息淹没,信噪比低 | 每条信息都高度相关 |
| 成本 | Token 消耗大 | 按需组装,成本可控 |
| 速度 | 上下文越长,响应越慢 | 上下文精简,响应快 |
5.2 SOLO 在我流程中的角色
作为一个产品经理,我能设计系统、定义需求,但如果没有 SOLO,这个项目永远只会停留在"想法"阶段。SOLO 在整个流程中的角色:
- 技术架构师:帮我选择合适的技术栈,设计项目结构和数据模型
- 主力程序员:生成了 80%+ 的代码,包括 12 个 Pinia Store、10 个 Vue 组件、完整的 IPC 通信层
- 算法顾问:帮我实现了 BM25 检索、事件驱动记忆、禁止行为推导等核心算法
- 调试专家:帮我定位和修复了数十个 Bug,从状态管理到异步流处理
- DevOps 工程师:配置了 electron-builder,一键打包生成 .exe
5.3 可复用的方法
- 产品驱动开发:先定义数据结构和交互流程,再让 SOLO 生成代码,效率最高
- Plan 驱动迭代:每个功能模块先写 Plan(项目中共产生了 25+ 个 Plan 文件),再按步骤实现
- 上下文工程思维:AI 应用的核心竞争力不在模型,在于如何管理和组装上下文
- 事件溯源模式:用事件日志驱动状态变更,天然支持审计和回溯
5.4 后续计划
- EPUB/PDF 电子书导出
- 写作日历热力图(ECharts)
- 云端同步备份
- 更多 AI 模型支持(Qwen\doubao 等)
- 协作写作功能
六、技术栈
- Electron 41 - 桌面应用框架(本地文件系统访问)
- Vue 3 + TypeScript - 前端框架
- Element Plus - UI 组件库
- Tiptap - 富文本编辑器
- Pinia - 状态管理(12 个 Store 按功能模块拆分)
- ECharts - 数据可视化
- DeepSeek API - AI 能力(SSE 流式输出)
- BM25 - 记忆检索算法
- Markdown-it - Markdown 渲染
感谢 TRAE SOLO,让一个产品经理也能从零做出一款完整的桌面应用!