1.摘要
在本次1个月的黑客松中,作为一名职业填词人,我使用TRAE SOLO跨界开发了《CantoLyrics.ai》——一款解决粤语歌“0243”严苛协音痛点的全栈应用。针对早期暴力注入18,000 Token字典导致大模型300s超时崩溃的缺陷,我借助SOLO将底层重构为“粤拼映射(Jyutping Mapping)”算法。该重构彻底消灭了Timeout问题,支撑起AI长达4-5分钟的深度音律推演,成功将我创作一首商业广告歌/流行曲的周期,从痛苦的数周缩减至短短1小时内。
2.背景
-
职业角色: 职业填词人(为企业机构创作广告歌、为歌手及个人创作流行曲)
-
工作场景与挑战: 广东歌填词是音乐界的“带着镣铐跳舞”,必须极其严格地遵守“0243”声调规则(九声六调完美对应旋律音阶,否则就是“唱错音”)。过去,创作一首歌词不仅需要文学灵感,更像在做复杂的数理拼图,通常需要耗费我 2到3周的时间 。
我试图用大模型提效,但LLM对粤语底层语音学极度缺乏认知。最初我只能在Prompt中暴力硬塞高达18,000 Token的注音字典,导致大模型频繁超载并触发300s Timeout(超时),系统直接瘫痪,这让我意识到纯靠Prompt根本走不 通。
3.实践过程:用SOLO跨界开发的30天极限战役
作为一个职业填词人,我的强项是懂粤语的音韵学规则(Domain Knowledge),弱项是毫无底层工程经验。在这1个月内,我将TRAE SOLO视作我的“首席架构师”,通过它强大的多文件上下文感知(Workspace Context)与逻辑重构能力,我们共同打赢了三场硬 核战役:
战役一:数据清洗与降维——把“字典”变成“ 算法”
-
挑战: 早期为了让AI懂协音,我直接塞进去了18,000 Token的字典,不仅贵,而且大模型直接“脑容量超载”。我需要把庞大的汉字字典,转换成轻量级的“粤拼声调映射(Jyutping Mapping)” 规则。
-
用SOLO的操作 过程:
-
我把包含数万条粤拼数据的杂乱CSV文件直接拖入 TRAE。
-
关键Prompt: “作为填词人,我告诉你一个乐理规则:粤拼的第1、4声对应0243里的『0』,第2、5声对应『2』…请你读取这个CSV文件,帮我写一个TypeScript数据清洗脚本,剔除无效符号,并将这套乐理规则封装成一个本地的高效映射函数 get0243FromJyutpin g()。”
-
SOLO的高光表现: 它不仅秒写了数据处理脚本,还主动帮我加上了本地缓存机制(Memoization),让后续查词速度提升了百倍。这让我成功把18k Token的字典硬开销,压缩成了不到500 Token 的映射逻辑!
-
战役二:跨文件重构— —逆向拼音推演架构
-
挑战: 算法变了,意味着前后端的交互逻辑必须全盘推翻。从“发字求音”变成“ 按音填字”。
-
用SOL O的操作过程:
-
我圈选了前端 PromptBuilder.ts 和后端 gener ate.ts 两个文件。
-
关键Prompt: “现在字典方案已废弃。请根据我们刚刚写好的Jyutping Mapping逻辑,帮我重构这两个文件:前端现在先解析用户的旋律,计算出目标0243序列,然后组合进Prompt发给后端;后端接收大模型返回的拼音后,再通过本地算法层 逆向解析成汉字。”
-
SOLO的高光表现: 这类跨文件的重构最容易导致牵一发而动全身的Bug。但SOLO凭借极强的上下文记忆,完美衔接了前端状态管理与后端逻辑流转,一天内就帮我跑通了这条 原本需要写一周的新链路。
-
战役三:踩坑与抢修——解 300s超时挑战
-
挑战(长耗时连接断开): 这是最致命的痛点。大模型进行严苛的音律推演需要极长的时间(实测需要4-5分钟),传统的API请求超过300s就会被服务器强 行掐断(Timeout)。
- SOLO解法: Prompt:“现在模型推演需要5分钟,前端总是遇到504 Gateway Timeout。请帮我重构HTTP请求方式,绕过这个限制。” SOLO直接从底层架构入手,帮我把普通的REST API改写成了长轮询(Long Polling)与保活机制,彻底锁 死了连接的稳定性 。
4.成果展示:
呈现最终产出,支持图文、外链分享(完整报告、 代码仓库、Web应用、演示视频等)
https://cantol yrics-demo.zeabur.app/
https://drive.google.com/file/d/1-Tg5yNBlQ7zuISunxBQGTXu60Qq 9 QOwr/view?usp=d r ivesdk
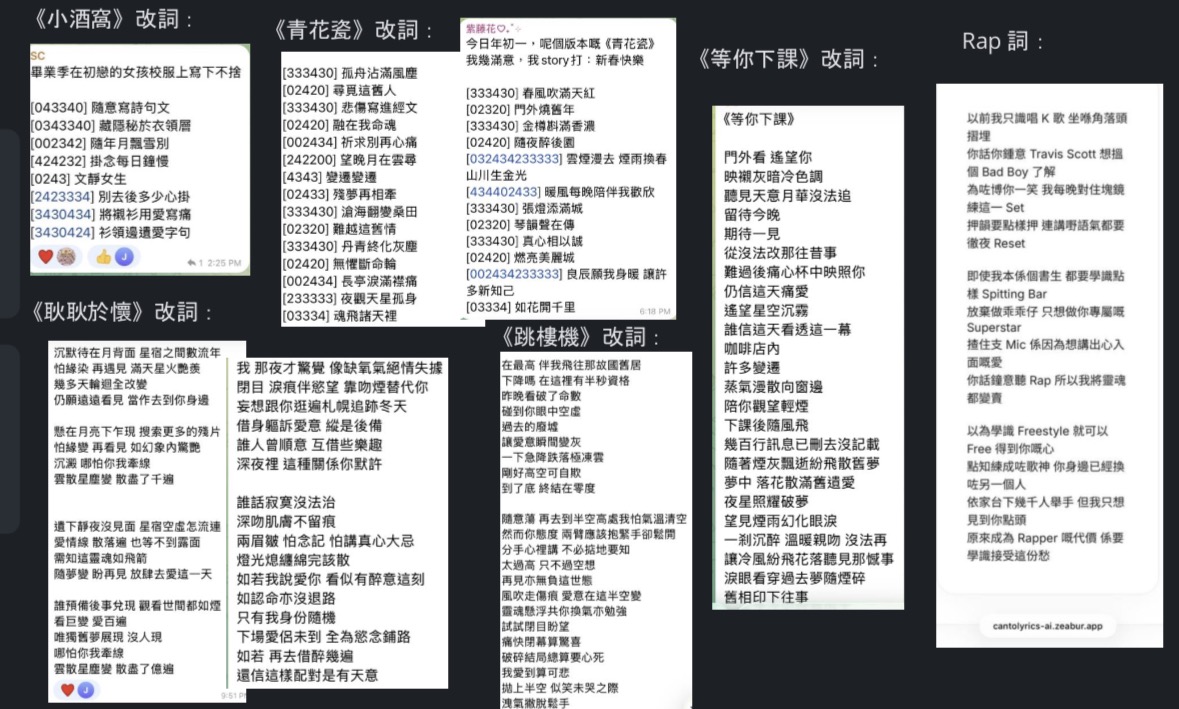
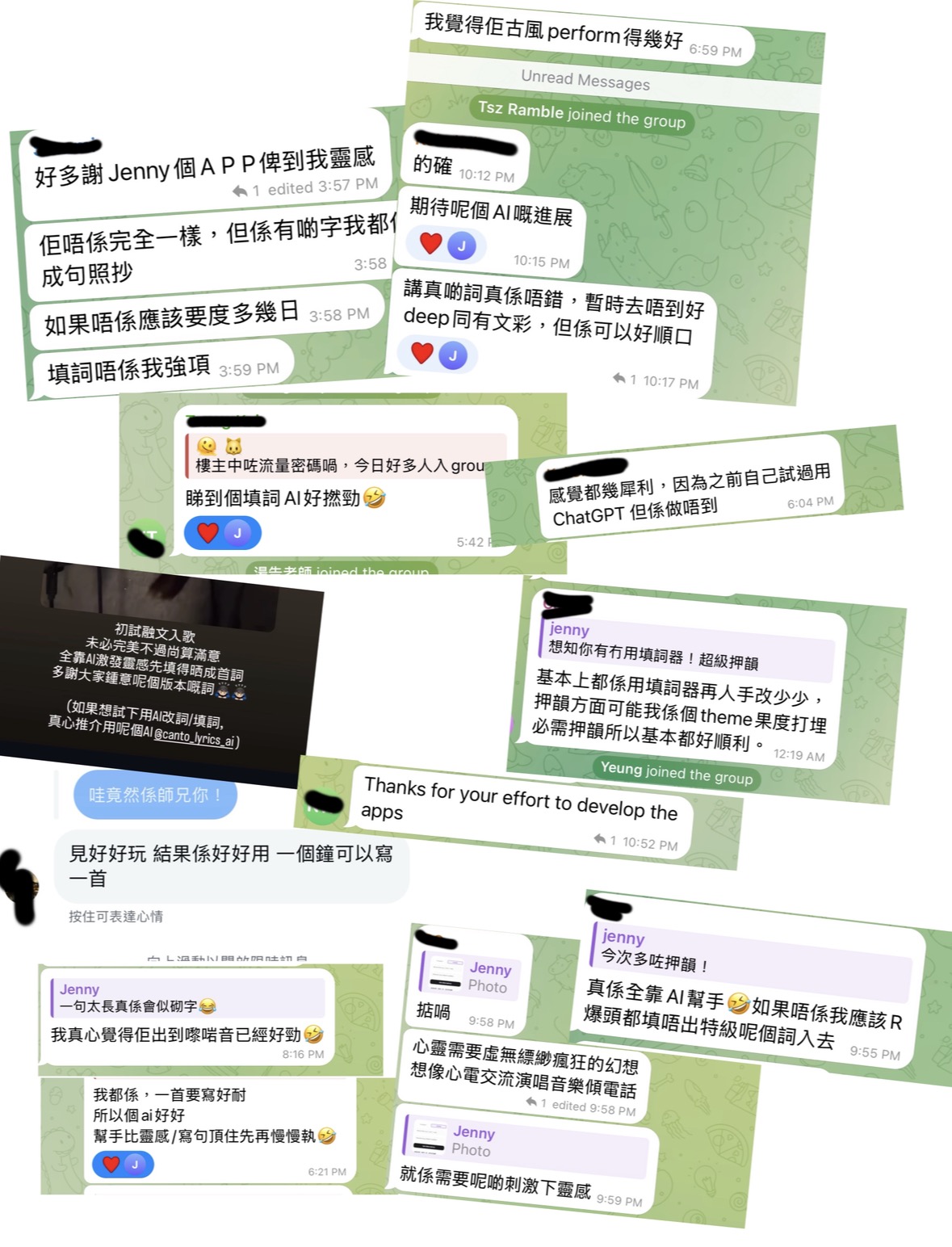
5.效果与总结
-
提效了多少(业务与技术双丰收)?
-
业务侧(颠覆性提效): 以前写一首歌词需要死磕2-3周,现在通过AI生成初稿+全文AI Rewrite(润色修饰),仅需1小时即可 产出高质量的商业级歌词。
-
技术侧: Token开销骤降90%以上。虽然大模型处理极其严苛的音律对位仍需4-5分钟的深度计算,但Timeout崩溃率降为0%,实现了长耗 时复杂任务下的绝对稳 定。
-
-
SOLO在流程中做了什么?
它打破了“创意工作者”与“硬核开发者”的壁垒。在处理枯燥的拼音映射规则、多音字正则,以及绕过服务器300s 限 制的底层架构时,SOLO 补足了我所有的工程短板 。
- 可复用的方法 论:
【用行业Domain Knowledge(领域知识)+工程中间层,给大模型减负】。遇到大模型认知盲区,不要用巨型Prompt暴力解决。用传统代码逻辑(如Jyutping Mapping)将任务从“巨型字典搜索”降级为 “规则推演”,是兼顾成 本 与系统稳定性的最 优解。
6. 验证方式与下一步
- 场景验证(真实商业 试用):
系统跑通后,我立即将其投入到我近期的两单“企业品牌广告歌”创作中。同时,我分享给了圈内的几位填词发烧友试用。大家的一致反馈是:虽然生成过程需要等待4-5分钟,但最终交付的歌词在“0243协音对位”上达到了令人震撼的精准度。 “用5分钟的等待,换取两三周的头发,这绝对是降 维打击。”
- 下一步计划:打通最后的护城河——「So lfege (唱名/简谱)转024 3引擎」
目前,填词人依然需要手动听旋律并推算0243序列,存在极高的音乐门槛。我的下一步计划是继续利用SOLO,开发一套乐理算法工具,将唱名(Solfege,如Do Re Mi)和简谱直接转化为0243声调音阶。这将彻底打通音乐旋律到语言声调的壁垒,实现真正的「曲谱进,歌词出 (Melody-to-Lyrics)」的端到端全自动化 工业级工作流。